An Embarrassingly Simple Graph Heuristic Reveals Shortcut-Solvable Benchmarks for Sequential Recommendation¶
- 作者:Haoyu Han, Li Ma, Hanbing Wang, Bingheng Li, Jiliang Tang(Michigan State University);Daochen Zha, Chun How Tan, Huiji Gao, Xin Liu, Stephanie Moyerman, Sanjeev Katariya, Hui Liu(Airbnb, Inc.)
- Arxiv:2605.07125(2026-05-08)
- 关键词:Sequential Recommendation; Benchmark Audit; Shortcut Learning; Graph Heuristic; Generative Recommendation
- 代码:https://github.com/haoyuhan1/GraphRec
研究动机与背景¶
序列推荐(Sequential Recommendation, SR)作为推荐系统的核心任务之一,近年研究重心已经显著转向生成式推荐器——TIGER、LETTER、CoFiRec、HSTU、ActionPiece 等模型把推荐重新表述为对离散 item ID、semantic ID 或文本表示的生成 / 检索任务,并大量依赖 item-side 的标题、类目、品牌、价格、评论等文本/语义信息来构造 item code、prompt 或预测目标。
但伴随这一方法论转向,评测实践却高度集中。作者对 2022–2026 年共 94 篇生成式推荐论文做了系统调研(附录 A),统计每个常用数据集被多少比例的论文使用:
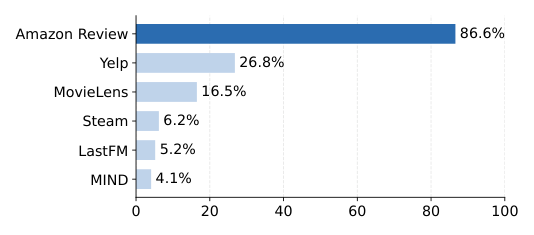
可以看到,Amazon Review 系列数据集主导了近 87% 的评测,其他数据集只占少数。这种过度集中产生一个尖锐的问题:
这些主导性 benchmark 到底在测什么?
研究者通常默认在 Amazon Review 上的高分意味着模型确实捕获了用户偏好、序列动态、语义结构、长程依赖或生成式推理能力,但这一解读建立在一个隐式假设上——benchmark 真的需要这些高级能力。如果同样的 benchmark 能被一个简单得多的方法解掉,那么所谓的"模型架构创新"对应的 performance gain 可能只是 dataset-specific shortcut,而非真实的建模能力推进。
本文做的事情是用一个故意设计得极简的诊断性图启发式(Transition-Graph Heuristic, TGH)来审计现有 SR benchmark。TGH 没有 sequence encoder、没有生成目标、没有 user representation、没有任何训练——它仅仅基于训练序列构造一张 item-to-item 的 transition graph,在 inference 时以最近 1–2 个 item 为锚点,从其几跳邻域里检索候选,再用 item 的文本特征相似度排序。如此简单的方法竟然在 Amazon Review 的 Beauty / Sports / Toys / CDs 上全面优于 LightGCN, SR-GNN, SASRec, HSTU, TIGER, LETTER, CoFiRec 等一众 SOTA——例如在 Sports 上 NDCG@10 相对最强 baseline 提升 38.10%,在 CDs 上提升 44.18%。
进一步的诊断分析揭示了三种使 next-item 预测变得意外简单的 shortcut 结构:(i)low-branching local transition structure(最近交互的局部转移邻居很少而仍能覆盖大量 ground truth);(ii)feature-smooth transitions(相邻 item 的文本特征高度相似);(iii)limited dependence on long user histories(仅用最近 1–2 步交互就能解释主要信号)。这三种 shortcut 不一定同时出现:在不同数据集上,往往只要某一种很强,TGH 就能保持竞争力;只有当三种都被削弱时,更复杂的模型才显现出价值。
作者将 TGH 推广到 14 个跨域 benchmark(Delicious、LastFM、MovieLens-1M、Yelp、MIND、GR-Comics、GR-Children、STEAM、H&M、Amazon-M2-UK 等)后发现:TGH 在 14 个数据集中的 10 个上仍然 best 或 second-best,证明 shortcut-solvable 现象不是 Amazon Review 的孤立特例,而是 SR 评测整体的系统性问题。
相关工作¶
序列推荐的演化。从 MF / Markov Chain(FPMC)→ RNN-based(GRU4Rec, Caser)→ self-attention(SASRec, BERT4Rec)→ graph-based(LightGCN, SR-GNN, GCE-GNN)→ 生成式 / LLM-based(TIGER, LETTER, CoFiRec, HSTU, ActionPiece, GenRec, LLMRec, P5)。生成式方向的兴起和 item-side 文本/语义信息的丰富紧密相关。
评测与 benchmark 审计。先前工作如 Krichene & Rendle(sampled metrics)、Meng et al.(data splitting)、Zhao et al.(top-N evaluation revisit)以及 Ferrari Dacrema et al. 系列("Are we really making much progress?")已经从评测协议层面对 SR/RS 论文是否进步提出过质疑,主要焦点是评测协议本身(采样、数据切分、超参、baseline 强度)是否公平。本文则切入一个新的失效模式——benchmark 本身的 shortcut solvability:不是协议不公平,而是 benchmark 数据本身奖励的信号过于浅显,导致简单启发式即可获得竞争性表现。
问题定义与诊断性启发式¶
问题定义¶
令 $\mathcal{U}$ 为用户集,$\mathcal{I}$ 为 item 集。每个用户 $u \in \mathcal{U}$ 有按时间排序的交互序列
$$ S_u = (i_1^u, i_2^u, \ldots, i_{T_u}^u), $$
其中 $i_t^u \in \mathcal{I}$ 是用户 $u$ 在 $t$ 时刻交互的 item。给定前缀序列
$$ S_{1:t}^u = (i_1^u, \ldots, i_t^u), $$
序列推荐的目标是对候选 item 排序,使下一个 item $i_{t+1}^u$ 排在尽量靠前的位置。
Transition-Graph Heuristic (TGH)¶
TGH 受两类基础推荐信号启发:来自 user-item 交互序列的协同结构,和来自 item-side 文本特征的语义相似性。它不是要提出新的推荐架构,而是希望测量"这两类基础信号在常用 benchmark 上能解到什么程度"。
1. 构图。给定全部训练序列,构造一张有向 item transition graph $G = (\mathcal{I}, \mathcal{E})$:节点是 item,对于每条训练序列里 $i \to j$ 的相邻共现,加一条有向边 $(i, j) \in \mathcal{E}$。设 $N_{i,j}$ 为序列中观察到的 $i \to j$ 转移次数,对每条边赋归一化权重
$$ w_{i,j} = \frac{\log(1 + N_{i,j})}{\max_{j': N_{i,j'} \gt 0} \log(1 + N_{i,j'})}, \tag{1} $$
使每个 item 出边的权重落在 $[0, 1]$ 区间。这一对数 + max 归一化的目的是抑制头部高频转移的支配作用。
2. 推断。给定测试时 prefix $S_{1:t}^u$,TGH 从最后一个 item $i_t^u$ 或最后两个 item $(i_{t-1}^u, i_t^u)$ 出发作为 anchor。对每个 anchor item $s$,在 transition graph 上取其几跳($\ell$-hop)邻域作为候选池。
3. 打分。设每个 item $i$ 有一份 L2 归一化的文本特征嵌入 $\hat{\mathbf{e}}_i$。对从 anchor $s$ 的 $\ell$-hop 邻域检索出的候选 $c$,定义打分
$$ \mathrm{score}_s(c) = \hat{\mathbf{e}}_s^\top \hat{\mathbf{e}}_c + \alpha \cdot \mathbb{1}[\ell = 1] \cdot w_{s,c}, \tag{2} $$
第一项是 anchor 与候选的余弦相似度(特征相似性主项),第二项是仅施加于 1-hop 邻居的归一化边权 bonus(直接转移频率的额外加分)。$\alpha$ 是 edge-bonus 的小权重,全局固定 $\alpha = 0.5$。对 $\ell \gt 1$ 的候选,打分退化为纯特征相似度。
4. 候选合并。每个 anchor、每个 hop 各保留若干 top-scoring 候选;同一 item 若被多个 anchor / hop 检索到,保留最高分;最终按分数降序得到推荐列表。
两个变体:
- TGH-1:只用最后 1 个 item 作 anchor,从 1-, 2-, 3-hop 邻域里分别取 top (7, 2, 1) 个候选。
- TGH-2:用最后 1 + 倒数第 2 个共两个 anchor。最近 item 取 1-hop top 5、2-hop top 1;倒数第 2 item 取 1-hop top 3、2-hop top 1。
所有数据集统一使用上述固定预算与 $\alpha = 0.5$,不针对单个数据集做超参 tuning,以排除"过拟合到某个 benchmark"的可能。
实验设置¶
- 协议:标准 leave-one-out next-item recommendation。每个用户最后一个 item 作 test,倒数第 2 个作 valid,其余作 train。
- 指标:Recall@K 与 NDCG@K,$K \in \{1, 5, 10\}$。
- 文本编码器:所有需要 item 文本的方法统一用
google/flan-t5-xl(含 SEM-NN, ID+SEM, LightGCN-with-text, TIGER, LETTER, CoFiRec, TGH 自身的文本特征),以保证只比较"如何用文本",不比较"用哪个文本编码器"。 - 训练规模:所有学习型 baseline 的 latent 维度设为 64(LETTER 32),ID-based 方法历史窗口 50,生成式方法历史窗口 20,单卡 H200。
主实验一:TGH 在 Amazon Review 上的惊人表现¶
Table 1:四个 Amazon Review 数据集上的 Recall@10 与 NDCG@10(百分数)。
| Method | Beauty R@10 | Beauty N@10 | Sports R@10 | Sports N@10 | Toys R@10 | Toys N@10 | CDs R@10 | CDs N@10 |
|---|---|---|---|---|---|---|---|---|
| LightGCN | 7.21 | 4.36 | 3.69 | 2.10 | 8.63 | 5.32 | 2.63 | 1.52 |
| SR-GNN | 5.43 | 3.13 | 2.61 | 1.33 | 3.77 | 2.32 | 0.63 | 0.35 |
| SASRec | 6.21 | 3.31 | 3.32 | 1.83 | 7.41 | 4.23 | 4.44 | 2.33 |
| HSTU | 5.73 | 3.00 | 2.48 | 1.25 | 6.40 | 3.56 | 5.62 | 2.91 |
| TIGER | 6.41 | 3.60 | 3.70 | 1.96 | 6.01 | 3.27 | 1.44 | 0.75 |
| LETTER | 4.96 | 2.62 | 2.18 | 1.11 | 3.07 | 1.60 | 4.50 | 2.44 |
| CoFiRec | 6.24 | 3.36 | 3.82 | 2.02 | 5.63 | 2.89 | 5.64 | 3.01 |
| TGH-1 | 7.66 | 5.01 | 4.27 | 2.76 | 9.13 | 6.12 | 6.21 | 4.13 |
| TGH-2 | 7.85 | 5.07 | 4.66 | 2.90 | 9.44 | 6.25 | 6.89 | 4.34 |
| Rel. Improv. | +8.88% | +16.28% | +21.99% | +38.10% | +9.39% | +17.48% | +22.16% | +44.18% |
最末行是 TGH-2 相对最强 baseline 的 NDCG@10 / Recall@10 相对提升。TGH-2 在 4 个数据集 8 个指标上全部夺冠,Sports/CDs 相对提升超过 38%。Recall@1 与 Recall@5 / NDCG@1 / NDCG@5 的细粒度结果见附录 E(Tables 6–9),TGH-1/2 在所有 K 上都是 best 或 second-best。
之所以"令人惊讶",是因为 TGH 仅在 anchor 的局部转移图邻域里检索一小撮候选,并用 item 文本相似度排序,完全不学习用户表示,也不做任何序列建模,却能横扫 LightGCN / SR-GNN / SASRec / HSTU / TIGER / LETTER / CoFiRec。考虑到 Amazon Review 占 87% 的近期生成式推荐论文评测份额,这个结果直接挑战了"在 Amazon Review 上的高分能作为高级模型能力的证据"这一隐式假设。
主实验二:哪些信号让 TGH 起作用?¶
要解释 TGH 为何如此有效,作者引入数据集级别的图统计量与一组诊断性 baseline。
数据集与 transition graph 统计¶
Table 2:Amazon Review benchmark 的 transition graph 统计。Cov@$k$ 表示 ground-truth target 落在 last item $k$-hop 邻域内的比例。
| Dataset | #Users | #Items | #Edges | Avg. Seq. Len. | Avg. Out-Deg. | Avg. Edge W. | Cov@1 | Cov@2 | Cov@3 |
|---|---|---|---|---|---|---|---|---|---|
| Beauty | 22,363 | 12,101 | 114,582 | 8.15 | 9.47 | 1.15 | 8.61% | 24.85% | 56.64% |
| Sports | 35,598 | 18,357 | 180,610 | 7.96 | 9.84 | 1.05 | 5.13% | 20.26% | 58.16% |
| Toys | 19,412 | 11,924 | 102,268 | 7.97 | 8.58 | 1.07 | 8.06% | 20.16% | 47.16% |
| CDs | 75,258 | 64,347 | 810,347 | 14.58 | 12.57 | 1.08 | 9.07% | 28.06% | 61.44% |
关键观察:item universe 有 1–6 万级 items,但 1-hop out-degree 只有 8–13;这意味着每个 item 的"可能下一个 item"被局部转移图收窄到非常小的候选空间。更重要的是 Cov@3 普遍超过 47%,很多测试 target 在 3 跳内即可被覆盖。
诊断 baseline¶
为了拆解究竟哪种简单信号在主导预测,作者构造 3 个受控 baseline:
- ID-LAST:仅基于 last item ID 的可学习 embedding,用 BPR 损失训练 item-to-item 协同过滤。衡量"ID 转移信号"上限。
- SEM-NN:完全免训练。给定 last item,用其文本嵌入与全部 item 的文本嵌入做余弦相似度,取最相近的若干个推荐。衡量"全局特征相似性"信号上限。
- ID+SEM:把 ID-LAST 与 SEM-NN 的分数 late fusion,衡量两类信号的互补性。
并对 SASRec / HSTU 做 history-window ablation——把历史窗口从原长截到 1(仅看最近一个 item),称 LAST-1 变体。
Table 3:诊断 baseline 在 Amazon Review 上的结果。
| Method | Beauty R@10 | Beauty N@10 | Sports R@10 | Sports N@10 | Toys R@10 | Toys N@10 | CDs R@10 | CDs N@10 |
|---|---|---|---|---|---|---|---|---|
| ID-LAST | 6.16 | 3.74 | 2.70 | 1.63 | 6.81 | 4.22 | 3.86 | 2.31 |
| SEM-NN | 5.32 | 3.30 | 2.68 | 1.55 | 8.04 | 5.01 | 1.20 | 0.75 |
| ID+SEM | 6.66 | 4.08 | 3.18 | 1.91 | 8.53 | 5.37 | 4.00 | 2.41 |
| SASRec | 6.21 | 3.31 | 3.23 | 1.83 | 7.41 | 4.23 | 4.44 | 2.33 |
| -Last-1 | 5.98 | 3.33 | 3.05 | 1.66 | 6.59 | 3.89 | 3.77 | 1.94 |
| HSTU | 5.73 | 3.00 | 2.48 | 1.25 | 6.40 | 3.56 | 5.62 | 2.91 |
| -Last-1 | 5.39 | 2.92 | 2.61 | 1.37 | 6.20 | 3.42 | 4.38 | 2.26 |
| TGH-1 | 7.66 | 5.01 | 4.27 | 2.76 | 9.13 | 6.12 | 6.21 | 4.13 |
三种 shortcut 结构¶
基于 Table 2/3 的对比,作者归纳出 3 个shortcut 结构假设,每一个都能让 next-item 预测的本质难度被显著压缩:
Shortcut 1:Low-branching local transition structure(低分叉局部转移结构)
虽然 item universe 上万,但 transition graph 平均 out-degree 仅 8–13,每个 item 的"可能跟随 item"被局部图天然窄化。结合 Cov@1 ≈ 5–9%、Cov@3 ≈ 47–61% 的覆盖率,意味着只要把检索范围限定到 last item 的 3-hop 邻域,绝大多数正确答案就已经在小池中。TGH 的"先用图缩候选 → 再用文本相似度排序"两阶段框架精确地利用了这一点。
Shortcut 2:Feature-smooth transitions(特征平滑的转移)
SEM-NN 完全没用任何转移信息,仅靠文本嵌入相似度,就在 Beauty / Sports / Toys 上接近甚至超过 SASRec 的水平。这说明在用户序列中相邻 item 的文本特征极其相似——例如同一品牌、同一类目、同一价格段;只要 item 文本质量好,最近邻特征即可作为强 next-item 检索信号。但这条 shortcut 在 CDs 上明显减弱(SEM-NN 1.20 vs SASRec 4.44),因为 CDs 数据集 item 文本更分散。
Shortcut 3:Limited dependence on long user histories(对长程历史依赖有限)
ID-LAST 只看最后一个 item 的 ID,就能与 SASRec 平分秋色(Beauty 6.16 vs 6.21)。SASRec / HSTU 的 LAST-1 变体(强行只让模型条件化于最近 1 个 item)相对全历史变体只损失 4–10%。这意味着长程 user history 在这些 benchmark 上提供的额外预测力非常有限,仅最近一两步交互就基本足够。
注意三种 shortcut 不一定同时出现。比如 CDs 数据集 SEM-NN 表现差,说明全局文本相似度信号不强;但 transition graph 的 low-branching 与 short-history 仍然成立,因此 TGH 仍占优。换言之,只要任意一两条 shortcut 信号足够强,benchmark 就能被简单方法解到接近天花板。
主实验三:超越 Amazon Review—10 个数据集的 shortcut 普适性¶
为了测试"shortcut-solvable 是不是 Amazon Review 独有问题",作者把同一套 baseline + TGH 推广到 10 个新 benchmark:Delicious、LastFM、MovieLens-1M、Yelp、MIND、GR-Comics、GR-Children、STEAM、H&M、Amazon-M2-UK,覆盖电商、新闻、音乐、电影、阅读、游戏多种 domain。
Table 4:10 个新 benchmark 的 transition graph 统计。
| Dataset | #Users | #Items | #Edges | Avg. Seq. Len. | Avg. Out-Deg. | Avg. Edge W. | Cov@1 | Cov@2 | Cov@3 |
|---|---|---|---|---|---|---|---|---|---|
| Delicious | 718 | 1,200 | 4,016 | 9.13 | 3.35 | 1.1 | 9.33 | 11.98 | 18.38 |
| LastFM | 1,090 | 3,646 | 30,372 | 34.02 | 8.33 | 1.11 | 5.69 | 21.93 | 53.58 |
| MovieLens-1M | 6,040 | 3,416 | 268,867 | 74.06 | 78.71 | 1.6 | 48.11 | 96.79 | 99.93 |
| Yelp | 30,431 | 20,033 | 219,632 | 10.4 | 10.96 | 1.02 | 5.75 | 27.86 | 73.57 |
| MIND | 48,577 | 39,757 | 824,397 | 28.16 | 20.74 | 1.48 | 40.13 | 89.19 | 96.73 |
| Goodreads-Comics | 89,186 | 48,623 | 1,282,693 | 33.78 | 26.38 | 2.14 | 49.67 | 84.36 | 97.25 |
| Goodreads-Children | 163,143 | 55,221 | 1,622,817 | 24.26 | 29.39 | 2.14 | 57.04 | 88.57 | 98.13 |
| STEAM | 334,728 | 13,047 | 1,524,022 | 12.59 | 116.81 | 2.11 | 59.44 | 97.99 | 99.8 |
| H&M | 1,077,045 | 104,468 | 19,487,762 | 26.01 | 186.54 | 1.27 | 34.32 | 95.28 | 99.72 |
| Amazon-M2-UK | 1,182,181 | 494,409 | 1,500,196 | 5.12 | 3.03 | 1.67 | 30.35 | 43.69 | 52.94 |
数据集多样性显著增加:从 Delicious 的 718 用户、avg out-degree 3.35,到 H&M 的百万用户、out-degree 186.54。
Table 5:NDCG@10 (%) 跨 10 个数据集的对比。
| Method | Delicious | LastFM | ML-1M | Yelp | MIND | GR-Comics | GR-Children | STEAM | H&M | Amazon-UK |
|---|---|---|---|---|---|---|---|---|---|---|
| ID-LAST | 6.64 | 2.11 | 6.86 | 0.94 | 5.72 | 18.70 | 9.39 | 13.40 | 0.79 | 25.38 |
| SEM-NN | 2.62 | 2.66 | 2.99 | 0.03 | 0.14 | 8.30 | 1.91 | 13.40 | 3.33 | 21.76 |
| ID+SEM | 6.68 | 2.60 | 7.09 | 0.65 | 5.46 | 13.59 | 7.00 | 13.59 | 3.77 | 26.16 |
| LightGCN | 4.37 | 2.22 | 4.32 | 0.40 | 2.78 | 19.62 | 8.03 | 1.98 | 2.93 | 28.78 |
| SR-GNN | 4.78 | 1.56 | 8.48 | 1.48 | 13.87 | 9.26 | 9.37 | 14.93 | 3.54 | 9.12 |
| SASRec | 7.57 | 3.32 | 14.21 | 1.33 | 12.67 | 16.08 | 12.10 | 4.49 | 3.68 | 14.10 |
| HSTU | 4.35 | 2.01 | 12.15 | 1.08 | 7.49 | 16.57 | 11.50 | 4.32 | 3.45 | 19.10 |
| TIGER | 5.10 | 1.45 | 9.98 | 1.05 | 2.19 | 16.02 | 10.48 | 14.24 | 4.10 | 6.37 |
| LETTER | 2.08 | 1.79 | 12.08 | 1.76 | 2.70 | 20.90 | 14.39 | 15.70 | 6.64 | 8.10 |
| TGH-1 | 7.06 | 3.07 | 9.25 | 0.90 | 5.51 | 23.12 | 12.23 | 14.85 | 8.06 | 24.87 |
| TGH-2 | 7.54 | 2.87 | 9.39 | 0.98 | 5.32 | 23.66 | 12.46 | 14.95 | 8.70 | 25.13 |
TGH 在 14 个数据集中的 10 个上是 best 或 second-best,在 Amazon-M2-UK 上接近 best。这佐证 shortcut-solvability 不是 Amazon Review 的孤立现象。但 TGH 也不是普适最强:在 MovieLens-1M、Yelp、MIND 上明显弱于 SASRec / SR-GNN 等学习型方法,这正好说明这些数据集的 shortcut 信号被削弱后,复杂模型的优势会显现。
结合 Table 4,作者用三种 shortcut 解释 TGH 成败的具体模式:
- Shortcut 1 vs MovieLens-1M:ML-1M 平均 out-degree 高达 78.71(远超 Amazon Review 的 ~10),低分叉假设失效;候选池太大使固定预算的局部检索无效,TGH 不敌 SASRec / HSTU。
- Shortcut 2 vs Yelp:Yelp out-degree 仅 10.96,低分叉假设成立,但 SEM-NN 在 Yelp 上表现极差(NDCG@10 仅 0.03),说明 Yelp 的 item 文本相似度信号薄弱。只有 low-branching 不够,feature-smooth 必须配合。
- Shortcut 3 vs MovieLens-1M / MIND:Figure 2 显示 SASRec 与 HSTU 的 Full-history vs LAST-1 在 ML-1M 与 MIND 上的差距可达 20%+,说明这两个 benchmark 真的依赖长程历史;TGH 只用最近 1–2 个 anchor,因此结构性弱势。
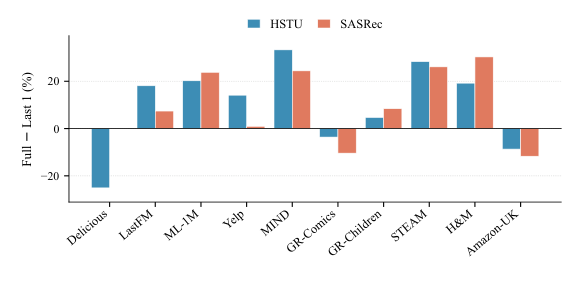
这些数据集级别的 diagnostic 提供了一种"benchmark 选用 checklist"——当作者声称模型具备长程依赖建模能力时,应该在 ML-1M / MIND 这类 long-history shortcut 弱的数据集上评测;当作者声称模型擅长语义建模时,应该选 Yelp 这类 feature-smooth shortcut 弱的数据集。
主实验四:TGH 与学习型模型的预测层差异¶
宏观分数差异不一定意味着两类方法捕获了同样的预测模式。作者从两个角度做预测层分析:
4.4.1 Jaccard overlap¶
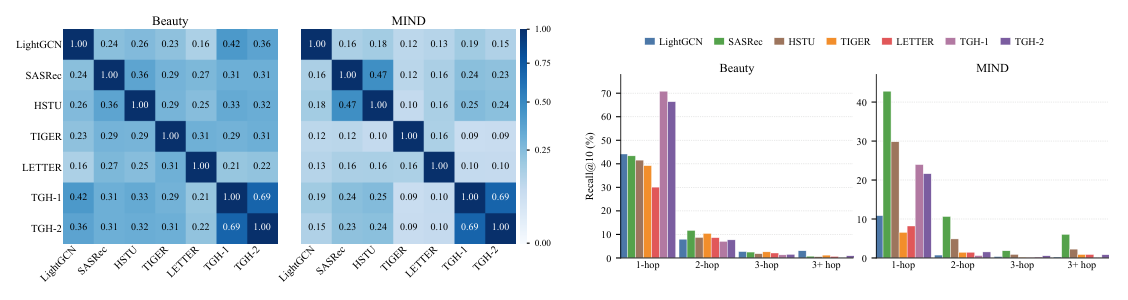
Figure 3(a) 计算各方法正确预测集(test 用户里被正确预测的子集)之间的 Jaccard 相似度。结果是 TGH 与学习型模型的重叠普遍较低(多在 0.10–0.30),说明它们解决的样本不同。换言之,TGH 在整体指标上具竞争力,但学习型模型确实捕获了 TGH 没有捕获的额外信号——这部分信号未被聚合 metric 充分体现。
4.4.2 按 hop 距离分组的 Recall¶
Figure 3(b) 把 test target 按"distance(last item, target) in hop"分桶,分别计算每个桶内的 Recall@10:
- Hop ≤ 3:TGH 表现最好。这正是 TGH 局部检索的舒适区。
- Hop > 3:学习型模型(特别是 SASRec / HSTU)显著优于 TGH。这表明它们能利用更长的用户历史与更复杂的转移规律去解决"远距离 target"。
结论:当前 SR baselines 并不弱——而是当前主流 benchmark 中"远距离 target"的占比太低,学习型模型擅长的部分被 shortcut 占据的部分淹没。TGH 在主指标上获胜,是因为 benchmark 的整体结构倾向 shortcut,而非学习型模型本质上无效。
核心贡献总结¶
- 首次在 SR 评测中提出 "shortcut-solvable benchmark" 这一新失效模式:与之前关注"评测协议公平性"(采样、splitting、超参、baseline 强度)的 audit 工作不同,本文质疑 benchmark 数据本身奖励的信号是否过浅。
- TGH 启发式:极简、无训练、却足够强——专门作为诊断探针使用,不是要做新模型;其在 Amazon Review 上 NDCG@10 比最强 baseline 高 17–44%,在 14/10 数据集上 best/second-best。
- 3 种 shortcut 结构 + 数据集级 diagnostic:low-branching local transition structure、feature-smooth transitions、limited dependence on long user histories;伴随 transition graph 的 average out-degree、Cov@k、SEM-NN 表现、Full vs LAST-1 gap 等可量化指标。
- prediction-level 分析揭示 metric 噪声:聚合分数掩盖了 TGH 与学习型模型解决不同样本子集的事实;学习型模型仅在 hop > 3 的 target 上显著领先,但这类样本占比小,因此被 shortcut 主导的 metric 淹没。
- 对社区的可执行建议:模型设计者应在能力对应的数据集上评测;benchmark 创建者应同时报告 transition branching、feature-smoothness、history-dependence 等 diagnostic。
与已归档相关工作的对比¶
Pay Attention to Sequence Split: Uncovering the Impacts of Sub-Sequence Splitting SSS Audit: Pay Attention to Sequence Split (Northeastern / Tianjin / SUTD, 2026-04-07)¶
关系:独立并发(本文未引用 SSS audit 论文,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇 2026 年的论文都对"过去几年 SR 模型 SOTA 进步是否真实"提出系统性质疑。它们都认为:当前 SR 评测中"模型架构创新"被过度归因,简单基线 / 简单数据处理 / 简单启发式可以解释大半 reported gain。
- 失效模式不同(这是关键差异):SSS audit 攻击的是训练管线层面的隐式 confound——10/17 的 SR 论文在代码中静默启用 Sub-Sequence Splitting 数据增强,对比的 baseline 没有用 SSS,导致 baseline 被人为压低;移除 SSS 后这些"SOTA"模型回退 40%,多数输给 2018 年的 SASRec。本文 (TGH) 攻击的是数据集本身的 shortcut——即便所有方法用同样的训练管线,benchmark 数据就奖励"看最近一两个 item + 文本相似度"这种浅层信号。SSS 是 training-side audit,TGH 是 dataset-side audit。
- 方法学相似:两者都遵循"挑选既定 baseline / 启发式 → 严格控制 confound → 系统跨数据集复现 → 给社区提建议"的 audit-paper 范式。SSS 论文用 SASRec 作为 reference baseline 进行对比,TGH 用一个 untrained 图启发式作为诊断探针——精神高度一致:用一个故意简单的对照物把研究社区奖励的虚假提升暴露出来。
- 诊断维度不同:SSS 论文从 target distribution 与 input-target joint distribution 解释 SSS 为何"显得有效";TGH 从 transition graph 的 out-degree、Cov@k、特征相似度信号、history-window ablation 解释为何 benchmark "显得难"。两者形成互补的"评测信任度"工具箱。
- 社区建议方向一致:两篇都呼吁更严格的实验披露与 benchmark transparency。SSS 强调代码与 paper 的一致性、统一 DA 管线;TGH 强调 benchmark 创建者发布 dataset-level diagnostic(branching / smoothness / history-dependence)。
- 对未来工作的启示:当下任何 SR 论文要 claim 进步,至少要做两层对照——(i)确认与 baseline 用了同样的 SSS 配置(来自 SSS audit);(ii)确认 benchmark 不是 shortcut-solvable,模型在能力对应的数据集上有差距(来自本文)。两者结合实际上重新定义了"如何让 SR 论文的 progress claim 站得住"。
讨论与局限性¶
值得借鉴的设计
- 故意简单的探针:TGH 不是"提一个新模型",而是"提一个最低实力对照物"。这种思路在一个研究社区高度依赖少数 benchmark 时极其有用——简单方法的强表现暴露 benchmark 的结构性问题,比另一个复杂模型的强表现说服力大得多。
- 多种 shortcut 解耦:作者刻意把 low-branching、feature-smooth、history-dependence 三种 shortcut 拆开,并用统计量(out-degree、Cov@k、SEM-NN R@10、Full-vs-LAST-1 gap)量化。这给后续 benchmark 创建者和审稿人提供了可操作的 checklist。
- 跨 14 数据集的 generalization:单一数据集的"shortcut 现象"很容易被反驳为 outlier,作者在 14 个跨 domain benchmark 上做对照才把"shortcut-solvability is widespread"立成了通用性观察。
局限性
- shortcut 列表不全:作者明确指出 popularity bias、temporal regularity、repeated consumption pattern、preprocessing artifact 等其他 shortcut 未涵盖。
- 方法不普适:TGH 在 ML-1M / MIND / Yelp 上明显弱于学习型 SR 模型;它本身不是要替代 baseline,而是诊断工具。读者切勿误读为"复杂模型无意义"。
- 生成式推荐 baseline 选择有限:TIGER / LETTER / CoFiRec / HSTU 是当前主流,但更大型的 LLM-based generator(如 P5、LC-Rec、HLLM)未纳入对比。
- 文本编码器单一:所有文本侧信息统一用 flan-t5-xl。不同 encoder(OpenAI text-embedding-3, BGE 等)下的 SEM-NN / TGH 表现可能有变化,结论的稳健性未被充分检验。
- 超参未做 dataset-specific tune:TGH 的固定预算 (7,2,1) / (5,1)+(3,1) 与 $\alpha = 0.5$ 是"故意不调"的设计,避免被指责"为某 benchmark 调到爆"。但这也意味着对个别数据集 TGH 可能并未充分发挥;不调超参既是 feature 也是局限。
- 未提替代 benchmark:作者只批评现状,未提出"哪些数据集应该成为新的 SR canonical benchmark"。读者得到的是一份 audit 报告 + 检查清单,而不是替代方案。
学术意义
这是一篇典型的"清理地基"论文——它和 SSS audit (2604.05309) 一道,构成了 2026 年 SR 评测自我修正的代表作。两者揭示了一个共同的隐忧:当一个研究方向高度依赖几个固定 benchmark 时,研究奖励机制会逐步偏离研究本意。这类 audit 论文产出新模型 / 新指标少,但对社区的健康度极重要。对任何在做 SR / 生成式推荐研究的人来说,本文应作为评测设计的强制阅读。
结论¶
本文用一个故意设计得极简的 transition-graph heuristic (TGH) 审计现有序列推荐 benchmark。TGH 完全免训练,仅依赖 last 1–2 个 item 的局部转移图邻域 + item 文本相似度,却在 87% 的近期生成式推荐论文使用的 Amazon Review 数据集上 NDCG@10 相对最强 baseline 提升 17–44%,并在 14 个数据集中的 10 个上保持 best/second-best。作者归纳出三种解释这一现象的 shortcut 结构:低分叉局部转移结构、特征平滑的转移、对长程历史依赖有限。三者不必同时存在——只要任一足够强,简单启发式就能击败 SOTA;只有当三者都被削弱时,先进模型才能展现真正价值。本文呼吁 SR 社区采用 capability-aware evaluation:模型作者应在能力对应的数据集上评测,benchmark 作者应同时报告 dataset-level diagnostic,避免把 shortcut-solvable 表现误读为真实建模能力的进步。