Block-Sphere Vector Quantization¶
Heesang Ann, Joongkyu Lee, Min-hwan Oh (Seoul National University) arXiv:2605.19972 · 2026-05-19
研究动机与背景¶
向量量化(Vector Quantization, VQ) 是现代大规模机器学习系统的基础原语:在 billion-scale 相似度检索、分布式/联邦学习的梯度压缩、以及长上下文 LLM 推理中的 KV-cache 存储里,都需要把高维 embedding 用尽可能少的 bit 表示,同时保留下游任务所需的几何信息(重构误差和内积估计)。在 LLM 推理场景,KV-cache 的显存占用会随 batch size 与 context length 线性膨胀,常常成为吞吐瓶颈,因此 KV-cache 量化已经成为压低推理成本的核心技术之一。
近年提出的几种 rotation-based quantizer(先施加随机正交旋转再做编码)—— EDEN、RabitQ、TurboQuant —— 在 low-bit 区间都达到了很强的实证表现,并各自给出了不同的理论保证:
TurboQuant同时分析了重构 MSE 与内积估计误差,给出 expected distortion 的上界;RabitQ通过 high-probability 分析给出 bit-complexity 保证;EDEN提供EDEN_UB的 MSE 上界,但对内积或高概率行为没有显式结论。
这些保证彼此基于不同的失真准则 (criterion)、概率假设、实现细节,导致很难直接比较"谁更强"。最近又冒出 EDEN 的 inner-product 变体、RabitQ 的 reconstruction 变体(见 Ben-Basat et al., 2026a),更让"哪种方法在哪种场景更适用"变得难以判断。
本文做两件事:
- 统一理论比较:把
EDEN/RabitQ/TurboQuant放进同一个 rotation-based quantizer 框架,分别在重构 MSE (D_MSE)、期望内积失真 (D_IP)、high-probability bit-complexity 三个准则下计算它们的精确常数和高维渐近上界。结论是没有任何一个方法在所有准则上都最优:EDEN_BSM/TurboQuant_MSE在 MSE 上最好;EDEN_UB在期望内积失真上最好;RabitQ在 high-probability bit-complexity 上最好。 - 提出 BlockQuant:受到上述分析驱动,作者提出 Block-Sphere Quantization —— 不再对每个坐标独立做标量量化,而是把旋转后的坐标分成大小为 $p$ 的块,对每个块利用球面诱导的精确块边缘分布(block marginal distribution on the unit sphere)构造 $2^{bp}$ 个 centroid。它和 product quantization (PQ) 形式上相似,但 codebook 不是从数据学出来的,而是直接由"随机旋转 + 单位球"这个分布解析推导出来的。理论上证明 BlockQuant 在两个 expected distortion 准则下都严格优于上面三种基线,并且当 $p=d$ 时其 MSE 上界与作者重新推导的 Shannon 下界在阶和领先常数上都匹配。
总体定位:本文是 rotation-based VQ 这条线(DRIVE → EDEN → TurboQuant → RabitQ)的理论收敛和扩展工作,把"做不做 block + 块上用什么分布"这个设计变量打到底,得到了既贴近理论下界又能在 KV-cache 量化等实际负载上验证的一个新算法。
预备知识¶
记号与问题设定¶
记单位球面与单位球为 $\mathbb{S}^{d-1}, \mathbb{B}^d$。一个随机量化器 $\mathcal{Q}$ 包含编码 $Q: \mathbb{R}^d \to \{0,1\}^{b\cdot d}$ 和解码 $Q^{-1}: \{0,1\}^{b\cdot d} \to \mathbb{R}^d$,平均每维 $b$ bit。$Q$ 的随机性来自随机旋转 $R$ 或随机投影矩阵。由于 vector norm 可以单独存储,本文只关注单位向量 $\mathbf{x} \in \mathbb{S}^{d-1}$ 的量化。
定义两个 worst-case 期望失真度量:
$$ \mathcal{D}_{MSE}(\mathcal{Q}) := \max_{\mathbf{x} \in \mathbb{S}^{d-1}} \mathbb{E}_Q\!\left[\,\|\mathbf{x} - Q^{-1}(Q(\mathbf{x}))\|_2^2\,\right] \tag{1} $$
$$ \mathcal{D}_{IP}(\mathcal{Q}) := \max_{\mathbf{x},\mathbf{y} \in \mathbb{S}^{d-1}} \mathbb{E}_Q\!\left[\,\bigl(\langle \mathbf{y}, Q^{-1}(Q(\mathbf{x}))\rangle - \langle \mathbf{y}, \mathbf{x}\rangle\bigr)^2\,\right] \tag{2} $$
前者衡量重构质量,后者直接对应"用量化向量做近邻相似度估计"时的精度,是检索/匹配任务的核心指标。
Rotation-based quantizer 的统一形式¶
令 $R$ 是 Haar 分布的 $d \times d$ 正交矩阵。对单位向量 $\mathbf{x}$,旋转后 $R\mathbf{x}$ 仍然均匀分布在 $\mathbb{S}^{d-1}$ 上。一个 rotation-based quantizer 通过下面三步编码:
$$ \mathbf{x} \;\xrightarrow{R}\; R\mathbf{x} \;\xrightarrow{P_{\text{code}}}\; \text{idx} \;\xrightarrow{P_{\text{decode}}}\; \bar{\mathbf{z}} \;\xrightarrow{R^\top}\; \bar{\mathbf{x}} \tag{3} $$
其中 $\mathcal{C}$ 是固定 codebook,$P_{\text{code}}: \mathbb{S}^{d-1} \to \mathcal{C}$ 是最近邻编码器,$P_{\text{decode}}$ 把 index 映射回 centroid。最终输出 $S \cdot \bar{\mathbf{x}}$ 可能还会带一个标量重缩放 $S$,依任务(MSE 重构 vs 无偏内积估计)而定。本文把"codebook 是什么样"和"$S$ 怎么选"分离开来看,是后续统一比较的基础。
三个现有方法的速览¶
EDEN:对旋转后的 $R\mathbf{x}$ 先除以 $\eta_q = \sqrt{d}$(因为高维下 $R\mathbf{x}$ 的每个坐标近似 $N(0, 1/d)$),再用 Lloyd–Max 标量码本 $\mathcal{C}_{\text{EDEN}}$(基于标准正态分布优化的 1D centroid)逐坐标量化。解码时按目标重缩放:$\eta = \langle\mathbf{x}, \bar{\mathbf{x}}\rangle/\|\bar{\mathbf{x}}\|_2^2$ 给出 best-scalar MSE 变体 EDEN_BSM;$\eta = 1/\langle\mathbf{x},\bar{\mathbf{x}}\rangle$ 给出 unbiased 内积变体 EDEN_UB。
RabitQ:用单位 grid $\{-1, 0, 1\}^d$ 投影到 $\mathbb{S}^{d-1}$ 得到球面码本 $\mathcal{C}_{\text{RabitQ}}$。最近邻编码后乘上一个 scalar correction,可以等价地写成两个变体:RabitQ_BSM(最小二乘 best-scalar 重构)使用 $\langle\mathbf{x},\bar{\mathbf{x}}\rangle\bar{\mathbf{x}}$,RabitQ_UB(无偏内积)使用 $\bar{\mathbf{x}}/\langle\mathbf{x},\bar{\mathbf{x}}\rangle$。
TurboQuant:和 EDEN 一样是 coordinate-wise 标量量化,但 Lloyd–Max 码本是基于球面上点的精确坐标边缘分布(高维下与高斯近似几乎相同),并取 $\eta_q = 1$。它有两个变体:TurboQuant_MSE 直接做重构;TurboQuant_PROD 先用 $(b-1)$ bit 做 TurboQuant_MSE 得到 $\bar{\mathbf{x}}$,再用 1 bit 配合 QJL 算法对残差 $\mathbf{x} - \bar{\mathbf{x}}$ 做无偏校正,得到 unbiased 内积估计。
关键观察:
EDEN和TurboQuant的 codebook 都是 coordinate-wise 1D 的;RabitQ的 codebook 虽然在球面上,但其元素来源是 $\{-1,0,1\}^d$ 投影到球,相当于 $2^d$ 个固定方向的子集。两者都没有真正利用"高维球面"的更丰富几何结构 —— 正是 BlockQuant 想要改进的地方。
新的理论保证:统一对比 EDEN / RabitQ / TurboQuant¶
作者在 Section 3 把三种方法放在同一坐标系下做精确比较。Table 1 总结了所有结果(数字来自本文重新计算):
| Quantizer (for MSE) | $b{=}1$ | $b{=}2$ | $b{=}3$ | $b{=}4$ | Large-$b$ 渐近 |
|---|---|---|---|---|---|
EDEN_BSM |
0.363 | 0.117 | 0.0345 | 0.0095 | $2.721 \cdot 4^{-b}$ |
RabitQ_BSM |
0.363 | 0.119 | 0.0374 | 0.0115 | — |
TurboQuant_MSE |
0.36† | 0.117† | 0.03† | 0.009† | $2.721 \cdot 4^{-b\,\dagger}$ |
BlockQuant_BSM $(p=2)$ |
0.363 | 0.108 | 0.0297 | 0.0078 | $2.015 \cdot 4^{-b}$ |
BlockQuant_BSM $(p=3)$ |
0.357 | 0.101 | 0.0271 | 0.0071 | $\mathbf{1.770 \cdot 4^{-b}}$ |
| Quantizer (for IP) | $b{=}1$ | $b{=}2$ | $b{=}3$ | $b{=}4$ | Large-$b$ 渐近 |
|---|---|---|---|---|---|
EDEN_UB |
$\tfrac{0.571}{d-1}$ | $\tfrac{0.133}{d-1}$ | $\tfrac{0.0358}{d-1}$ | $\tfrac{0.0096}{d-1}$ | $\tfrac{2.721}{d-1}\cdot 4^{-b}$ |
RabitQ_UB |
$\tfrac{0.571}{d-1}$ | $\tfrac{0.135}{d-1}$ | $\tfrac{0.0389}{d-1}$ | $\tfrac{0.0117}{d-1}$ | — |
TurboQuant_PROD |
$\tfrac{1.57}{d}\dagger$ | $\tfrac{0.56}{d}\dagger$ | $\tfrac{0.18}{d}\dagger$ | $\tfrac{0.047}{d}\dagger$ | $\tfrac{17.09}{d}\cdot 4^{-b\,\dagger}$ |
BlockQuant_UB $(p=2)$ |
$\tfrac{0.571}{d-1}$ | $\tfrac{0.120}{d-1}$ | $\tfrac{0.0306}{d-1}$ | $\tfrac{0.0078}{d-1}$ | $\tfrac{2.015}{d-1}\cdot 4^{-b}$ |
BlockQuant_UB $(p=3)$ |
$\tfrac{\mathbf{0.553}}{d-1}$ | $\tfrac{\mathbf{0.113}}{d-1}$ | $\tfrac{\mathbf{0.0279}}{d-1}$ | $\tfrac{\mathbf{0.071}}{d-1}$ | $\tfrac{\mathbf{1.770}}{d-1}\cdot 4^{-b}$ |
(†标注的来自 Zandieh et al. 2025a;其它由本文计算。)
下面分别看三个准则。
MSE 比较¶
Proposition 1(EDEN_BSM 的 MSE):高维下,
$$ \mathcal{D}_{MSE}(\texttt{EDEN}_{BSM}) \approx 0.363,\ 0.117,\ 0.0345,\ 0.0095 \quad \text{for } b=1,2,3,4 \tag{4} $$
并且大 $b$ 区间满足 $\mathcal{D}_{MSE}(\texttt{EDEN}_{BSM}) \leq 2.721 \cdot 4^{-b}$。
Proposition 2(RabitQ_BSM 的 MSE):令 $\mathbf{z} = (z_1, \dots, z_d)$ 是随机旋转后的输入单位向量,$R_j = \sqrt{d}\, z_j$ 是其缩放坐标。定义 $Q_b(u) = \mathrm{sgn}(u)\min\bigl(\lfloor |u|\rfloor + \tfrac{1}{2},\ 2^{b-1} - \tfrac{1}{2}\bigr)$。则 RabitQ_BSM 的 MSE 为:
$$ \mathcal{D}_{MSE}(\texttt{RabitQ}_{BSM}) = \mathbb{E}\!\left[\min_{\alpha \gt 0} \frac{1}{d}\sum_{j=1}^d \bigl(R_j - \alpha Q_b(R_j/\alpha)\bigr)^2\right] \tag{5} $$
在大 $d$ 下用高斯近似得到数值结果约 $0.363, 0.119, 0.037, 0.0115$。
Remark 1(TurboQuant_MSE 的 MSE):把 Zandieh et al. (2025a) 的数值在本文记号下统一重算后,得到 $0.363, 0.117, 0.0345, 0.0095$,与 EDEN_BSM 几乎相同。
讨论:高维下 EDEN_BSM 和 TurboQuant_MSE 是 MSE 最优的(两者构造都基于"Lloyd–Max 坐标质心 + 球面/高斯坐标边缘"),RabitQ_BSM 接近但随 $b$ 增大略差。$1/4$ 这个领先系数的差距已经接近 high-rate 量化理论的常数极限,但仍不是真正的下界 —— 这就为 BlockQuant 留下空间。
Inner-product 失真比较¶
Theorem 1(ratio quantizer 的一般界):设 $\mathbf{x}, \mathbf{y} \in \mathbb{S}^{d-1}$,$\eta := \langle \mathbf{x},\mathbf{y}\rangle$。对所谓的 ratio quantizer $\widehat{\eta}_{\text{ratio}} := \big\langle \tfrac{\bar{\mathbf{x}}}{\langle \mathbf{x},\bar{\mathbf{x}}\rangle}, \mathbf{y} \big\rangle$,其平方误差为:
$$ \mathbb{E}\!\left[\bigl(\widehat{\eta}_{\text{ratio}} - \eta\bigr)^2\right] = \frac{1 - \eta^2}{d-1}\,\mathbb{E}\!\left[\frac{\|\bar{\mathbf{x}}\|_2^2 - \langle \bar{\mathbf{x}},\mathbf{x}\rangle^2}{\langle \bar{\mathbf{x}}, \mathbf{x}\rangle^2}\right] \tag{6} $$
EDEN_UB 和 RabitQ_UB 都是 ratio quantizer,所以这个公式给出统一框架。
Corollary 1(EDEN_UB 的 IP 误差):高维近似 $\mathcal{D}_{IP}(\texttt{EDEN}_{UB}) \approx \tfrac{0.571}{d-1}, \tfrac{0.133}{d-1}, \tfrac{0.0358}{d-1}, \tfrac{0.0096}{d-1}$,且大 $b$ 渐近 $\leq \tfrac{2.721}{d-1}\cdot 4^{-b}(1+o(1))$。
Corollary 2(RabitQ_UB 的 IP 误差):高维近似 $\approx \tfrac{0.571}{d-1}, \tfrac{0.135}{d-1}, \tfrac{0.0389}{d-1}, \tfrac{0.0117}{d-1}$。
讨论:EDEN_UB 给出最强的 IP 期望失真保证,RabitQ_UB 在 $b \geq 2$ 时只差一点。TurboQuant_PROD 的 IP 失真约比 EDEN_UB 大 4 倍($\tfrac{17.09}{d}\cdot 4^{-b}$ vs $\tfrac{2.721}{d-1}\cdot 4^{-b}$),原因是 TurboQuant_PROD 牺牲 1 bit 给 QJL 偏差校正,剩余 $(b-1)$ bit 做重构 —— bit 分配方式导致大约一倍 $4^{-1}=1/4$ 的损失,而 EDEN_UB/RabitQ_UB 全 $b$ bit 都用于重构 + 标量校正,因此更有效。
高概率 bit-complexity¶
RabitQ 的特别之处是给出 high-probability bit-complexity 保证;EDEN 和 TurboQuant 此前只有期望分析。本文证明:
Theorem 2(informal):设输入维度 $d$,$\epsilon, \delta \in (0,1)$。若 $\tfrac{1}{\epsilon}\log(\tfrac{1}{\delta}) \lesssim d$,则对 EDEN_UB 和 TurboQuant_PROD,每维 $b = \Theta\bigl(\log\bigl(\tfrac{1}{d\epsilon^2}\log\tfrac{1}{\delta}\bigr)\bigr)$ bit 就足以让 inner-product 估计误差不超过 $\epsilon$、失败概率不超过 $\delta$。
这达到了 Alon–Klartag (2017) 的最优 bit complexity,但只在 low-accuracy 区间($\tfrac{1}{\epsilon}\log\tfrac{1}{\delta} \lesssim d$)。在 high-accuracy 区间($d \lesssim \tfrac{1}{\epsilon^2}\log\tfrac{1}{\delta}$),RabitQ 仍然更优 —— 这反映了 EDEN/TurboQuant 的 MSE-optimized 设计虽然能有效压低期望失真,但残差分布的尾部控制不如 RabitQ 的 high-probability-driven 设计。
三准则总结:
EDEN_BSM/TurboQuant_MSE在 MSE 最优;EDEN_UB在期望 IP 最优;RabitQ在 high-probability bit-complexity 最优。没有任何一个 baseline 在所有准则上 dominate。
提出方法:Block-Sphere Quantization (BlockQuant)¶
直觉¶
EDEN 和 TurboQuant 都是 coordinate-wise 的 Lloyd–Max 量化,等价于把码本设为 $\mathcal{C} = \mathcal{C}_{1D}^d$ 的笛卡尔积。这意味着 $2^{bd}$ 个 codeword 中很多落在远离单位球的位置(如 $(\pm s, \pm s, \dots)$ 这类对角点的范数远超 1),bit budget 没有完全花在与"单位球"几何对齐的方向上。RabitQ 用 grid 投影到球面,但 grid 的选择是固定的($\{-1, 0, 1\}^d$ 投影),没有用上分布信息。
BlockQuant 的核心思路:把旋转后的 $\mathbf{z} = R\mathbf{x}$ 切成 $m = d/p$ 个块 $\mathbf{z}_j \in \mathbb{B}^p$,对每块单独找 $2^{bp}$ 个 centroid。但这些 centroid 不是从数据学的,也不是 PQ 那种 k-means clustering 学的,而是从"$\mathbf{x}$ 在球面均匀分布"诱导出来的精确块边缘分布上做 K-means 优化。当 $p=1$ 时它退化成 coordinate-wise(与 TurboQuant 同形态);$p$ 越大,码本越能捕获球面真实结构。
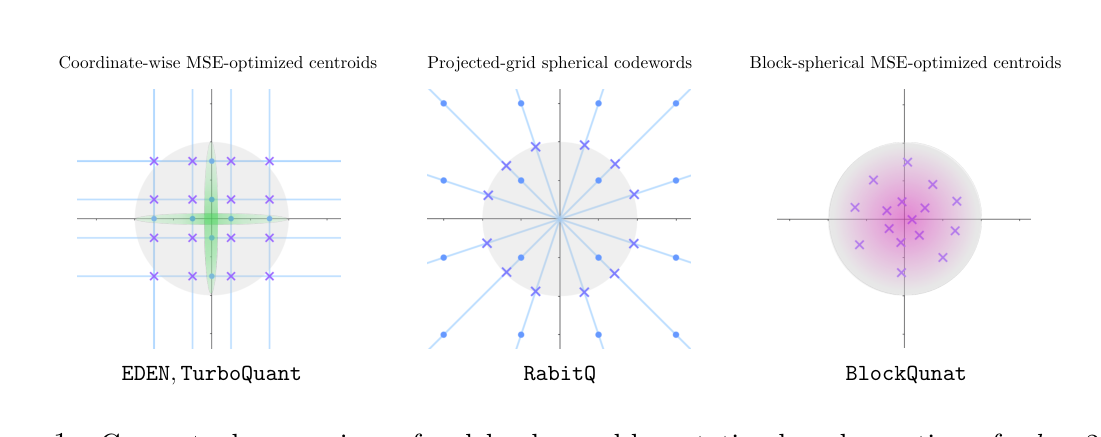
块边缘分布¶
Lemma 1(uniform 球面向量的块边缘分布):设 $d = mp$,$\mathbf{x} \sim \mathrm{Unif}(\mathbb{S}^{d-1})$,把 $\mathbf{x}$ 拆成 $\mathbf{x} = [\mathbf{z}_1, \dots, \mathbf{z}_m]$,每块 $\mathbf{z}_j \in \mathbb{B}^p$。则每块的密度为:
$$ f_{p,d}(\mathbf{z}_j) = \frac{\Gamma(d/2)}{\pi^{p/2}\,\Gamma((d-p)/2)}\bigl(1 - \|\mathbf{z}_j\|_2^2\bigr)^{(d-p-2)/2} \tag{7} $$
等价地可以分解 $\mathbf{z}_j = r_j \boldsymbol{\theta}_j$,其中半径 $r_j \in [0,1]$ 与方向 $\boldsymbol{\theta}_j \in \mathbb{S}^{p-1}$ 独立,且:
$$ r_j^2 \sim \mathrm{Beta}\!\left(\tfrac{p}{2},\tfrac{d-p}{2}\right),\quad \boldsymbol{\theta}_j \sim \mathrm{Unif}(\mathbb{S}^{p-1}) \tag{8} $$
这意味着每个块的方向是 $p$ 维球面均匀分布,半径服从一个尖锐的 Beta 分布(高维下集中在 $\sqrt{p/d}$ 附近)—— 这就是 BlockQuant 优化 codebook 时使用的精确分布。
Block K-means optimization¶
给定块大小 $p$ 与 bit 数 $b$,BlockQuant 在 $\mathbb{B}^p$ 上找 $K = 2^{bp}$ 个 centroid $\{\mathbf{o}_i\}_{i=1}^K$ 来最小化期望失真:
$$ \text{Distortion cost} = \int_{\mathbb{B}_p} \min_{i \in [2^{bp}]} \|\mathbf{z} - \mathbf{o}_i\|_2^2\,f_{p,d}(\mathbf{z})\,\mathrm{d}\mathbf{z} \tag{9} $$
和 TurboQuant 一样,码本只在量化开始前离线构建一次,之后所有向量共用。
Algorithm 1(完整流程)¶
Setup(离线一次性):
1. 采样 Haar 旋转矩阵 R ∈ R^{d×d}
2. 解 (9) 得到 {o_1, ..., o_{2^{bp}}} ⊂ B^p
QUANT(x):
3. z = R x,切成 (z_1, ..., z_m),m = d/p
4. idx_j = argmin_{i ∈ [2^{bp}]} ||z_j - o_i|| for j = 1,...,m
5. 保存 alignment ρ = <z, z̄> (z̄ 为 codeword 拼接)
6. return idx = [idx_1, ..., idx_m] (bp-bit integers)
DEQUANT(idx):
7. z̄ = [c_{idx_1}, ..., c_{idx_m}]
8. x̃ = R^T z̄
9. 重缩放系数:
S = ρ / ||x̄||² for BlockQuant_BSM (最小 MSE)
S = 1 / ρ for BlockQuant_UB (无偏内积)
S = 1 for BlockQuant_MSE (raw 重构,不存 ρ)
10. return S · x̃
三个变体对应三个不同任务:BSM 用 best scalar 给出最小 MSE 重构,UB 给出无偏内积估计(与 EDEN_UB/RabitQ_UB 配对比较),MSE 是 raw 重构(与 TurboQuant_MSE 同形态,跳过 alignment 存储以省 bit)。
理论保证¶
Theorem 3(BlockQuant 的 MSE 上界):高维下,对 $\mathcal{Q} \in \{\texttt{BlockQuant}_{MSE}, \texttt{BlockQuant}_{BSM}\}$:
$$ \mathcal{D}_{MSE}\bigl(\mathcal{Q}_{(p=2)}\bigr) \approx 0.363,\ 0.108,\ 0.0297,\ 0.0078 \quad b=1,2,3,4 \tag{10} $$
$$ \mathcal{D}_{MSE}\bigl(\mathcal{Q}_{(p=3)}\bigr) \approx 0.357,\ 0.101,\ 0.0271,\ 0.0071 \quad b=1,2,3,4 \tag{11} $$
并且大 $b$ 渐近上界:
$$ \mathcal{D}_{MSE}\bigl(\mathcal{Q}_{(p=2)}\bigr) \leq 2.015 \cdot 4^{-b}(1 + o(1)) \tag{12} $$
$$ \mathcal{D}_{MSE}\bigl(\mathcal{Q}_{(p=3)}\bigr) \leq 1.770 \cdot 4^{-b}(1 + o(1)) \tag{13} $$
$$ \mathcal{D}_{MSE}\bigl(\mathcal{Q}_{(p=d)}\bigr) \leq C_d \cdot \left(\tfrac{1}{4}\right)^{\tfrac{bd}{d-1}}(1 + o(1)) \tag{14} $$
其中 $C_d := \Gamma\bigl(1 + \tfrac{2}{d-1}\bigr)\Bigl[\tfrac{2\sqrt{\pi}\,\Gamma((d+1)/2)}{\Gamma(d/2)}\Bigr]^{\tfrac{2}{d-1}} \approx 1.055, 1.008, 1.001$ 分别对应 $d = 100, 1000, 10000$。
讨论:$p=2$ 已经把领先常数从 EDEN_BSM 的 $2.721$ 压到 $2.015$(25% 改进),$p=3$ 进一步到 $1.770$(35% 改进)。理想情形 $p = d$ 时常数趋于 1,正好与下一节的 Shannon 下界匹配,说明 block-spherical 是接近最优的路径。
Corollary 3(BlockQuant_UB 的 IP 误差):
$$ \mathcal{D}_{IP}\bigl(\texttt{BlockQuant}_{UB(p=2)}\bigr) \approx \tfrac{0.571}{d-1}, \tfrac{0.120}{d-1}, \tfrac{0.0306}{d-1}, \tfrac{0.0078}{d-1} \tag{15} $$
$$ \mathcal{D}_{IP}\bigl(\texttt{BlockQuant}_{UB(p=3)}\bigr) \approx \tfrac{0.553}{d-1}, \tfrac{0.113}{d-1}, \tfrac{0.0279}{d-1}, \tfrac{0.071}{d-1} \tag{16} $$
并且 $\mathcal{D}_{IP}(\texttt{BlockQuant}_{UB(p=2)}) \leq \tfrac{2.015}{d-1} \cdot 4^{-b}(1+o(1))$、$\mathcal{D}_{IP}(\texttt{BlockQuant}_{UB(p=3)}) \leq \tfrac{1.770}{d-1} \cdot 4^{-b}(1+o(1))$。
相比 EDEN_UB 的 $\tfrac{2.721}{d-1}\cdot 4^{-b}$,BlockQuant_UB(p=3) 几乎严格更优。
更紧的 MSE 下界¶
作者发现 Zandieh et al. (2025a) 之前用过 Shannon 下界论证,但其推导直接套用了 $\mathbf{x}$ 在 $\mathbb{R}^d$ 的微分熵 —— 由于 $\mathbb{S}^{d-1}$ 在 $\mathbb{R}^d$ 中是零测度集,这个熵其实是无穷大或不存在,所以原推导不严密。
Theorem 4(Shannon 失真下界):把 Shannon 下界应用到 $\mathbf{x}$ 在 $\mathbb{B}^{d-1}$(即前 $d-1$ 个坐标,分布绝对连续)上的密度。对任意 $b \geq 0$ 和任意 $bd$-bit 的量化映射 $Q$:
$$ \mathbb{E}_\mathbf{x}\!\left[\|\mathbf{x} - Q^{-1}(Q(\mathbf{x}))\|_2^2\right] \geq c_d \left(\tfrac{1}{4}\right)^{\tfrac{bd}{d-1}} \tag{17} $$
其中 $c_d := \tfrac{d-1}{2\pi e}\Bigl[\tfrac{\pi^{d/2}}{\Gamma(d/2)}\Bigr]^{2/(d-1)}\exp\!\bigl(\tfrac{\psi(1/2) - \psi(d/2)}{d-1}\bigr) \approx 0.936, 0.991, 0.999$ 对应 $d = 100, 1000, 10000$。
关键点:指数是 $\tfrac{bd}{d-1}$ 而不是 $b$,反映了球面的内在维度是 $d-1$ 而非 $d$。把 Theorem 3 中 $p=d$ 的情况和 Theorem 4 对比:领先常数 $C_d$ 与 $c_d$ 在 $d \to \infty$ 时都趋于 1,指数都是 $\tfrac{bd}{d-1}\log_2(1/4)$,两者在阶和常数上都匹配。这意味着 BlockQuant 在 $p \to d$ 极限下就是球面量化的渐近最优算法。
实验¶
实验设定包含三个部分:(i) DBpedia embedding 上的纯量化精度,(ii) 检索任务上的近邻召回,(iii) Llama-3.1-8B-Instruct 的 KV-cache 量化对 long-context 任务的影响。除特别说明外块大小 $p=3$。
实现细节:近邻搜索的近似¶
精确最近 centroid 需要把每个 block 与全部 $K = 2^{bp}$ 个 centroid 比较,当 $p=3, b=4$ 时 $K = 4096$,开销不可忽略。作者用一个 lookup-table 近似:把 $\mathbb{B}^p$ 切成 Cartesian grid,对每个 grid cell 预计算一组候选 centroid,在线时只在候选集内做 nearest-centroid 搜索。这保留了 codebook 构造与解码不变,只压低 assignment cost。后续标 approx 的实验都用这个近似版本。
量化精度¶
Reconstruction MSE:在 DBpedia Entities (1536-dim) 上采 100k 数据库向量,归一化到单位球。每个向量量化后计算 $e_i = \|\widehat{\mathbf{x}}_i - \mathbf{x}_i\|_2^2$。
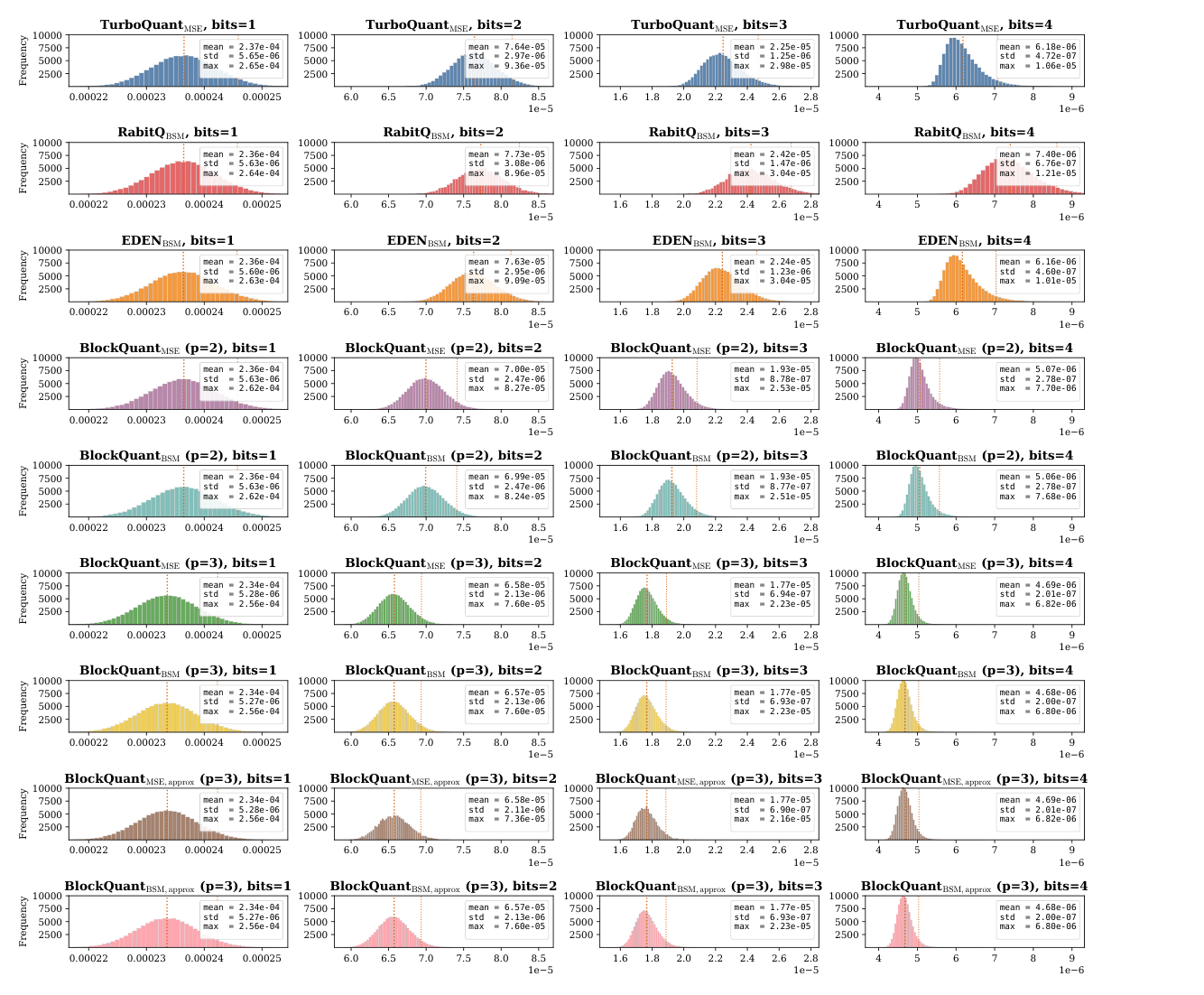
BlockQuant_MSE 和 BlockQuant_BSM ($p=3$) 在所有 $b$ 上都取得最小 MSE,approx 近似版本也几乎无损。
Inner product error:同样数据集,100k DB + 1k query,只对 DB 量化,对每对 $(\mathbf{x}_i, \mathbf{y}_j)$ 测 $e_{ij} = \langle\widehat{\mathbf{x}}_i, \mathbf{y}_j\rangle - \langle\mathbf{x}_i, \mathbf{y}_j\rangle$。
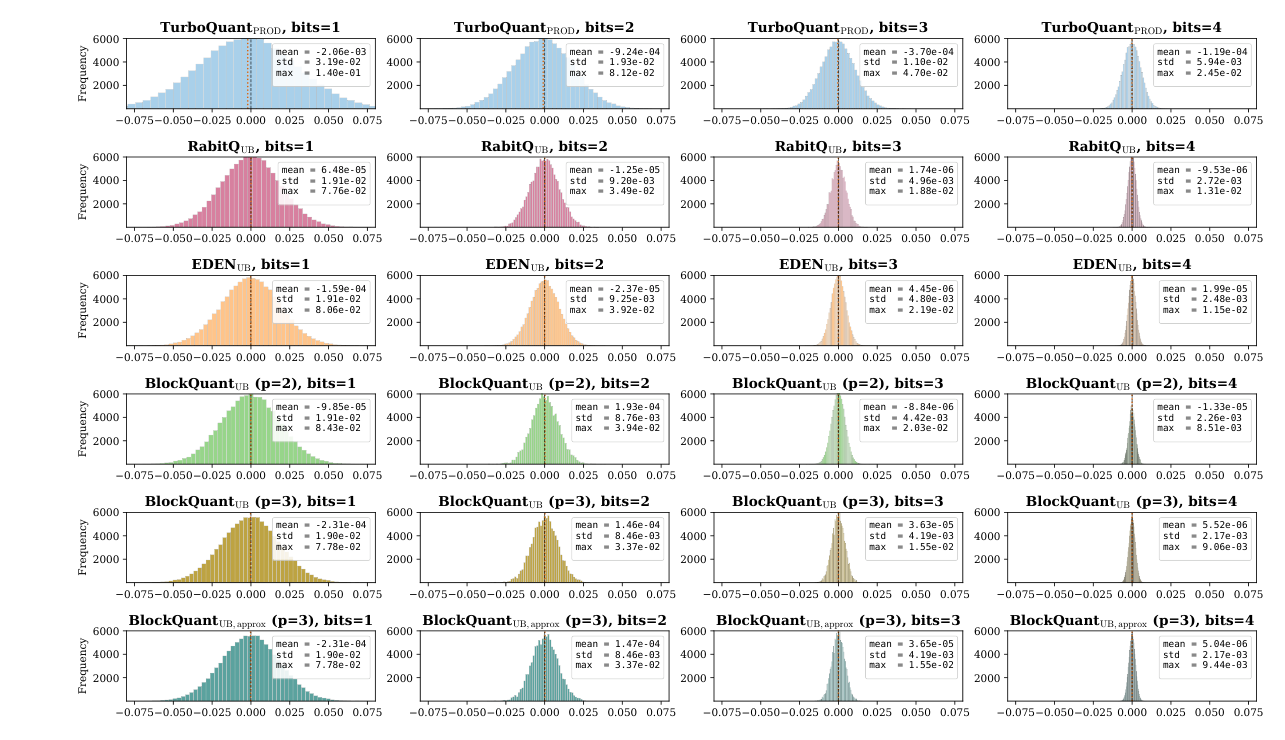
BlockQuant_UB 的误差分布在中等 bit-width 区间显著比 coordinate-wise baseline 更集中,与 Corollary 3 一致。
最近邻检索¶
用 Recall@1@k 衡量:
$$ \mathrm{Recall@1@k} = \frac{1}{|\mathcal{Q}|}\sum_{\mathbf{q} \in \mathcal{Q}} \mathbf{1}\{g(\mathbf{q}) \in \mathcal{A}_k(\mathbf{q})\} \tag{18} $$
其中 $g(\mathbf{q})$ 是 full-precision 下的真实 top-1 邻居,$\mathcal{A}_k(\mathbf{q})$ 是用量化内积估计返回的 top-$k$。
数据集:GloVe ($d=200$)、OpenAI3/DBpedia ($d=1536, 3072$)。bit-width: 4-bit (Figure 4) 与 2-bit (Figure 5)。
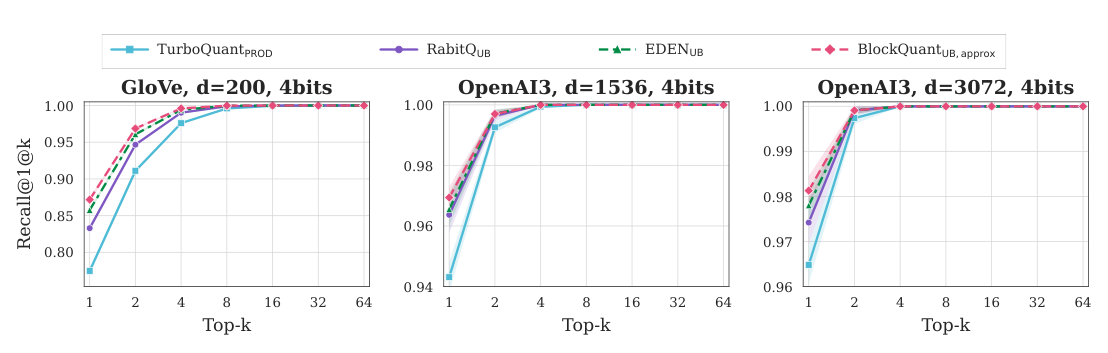
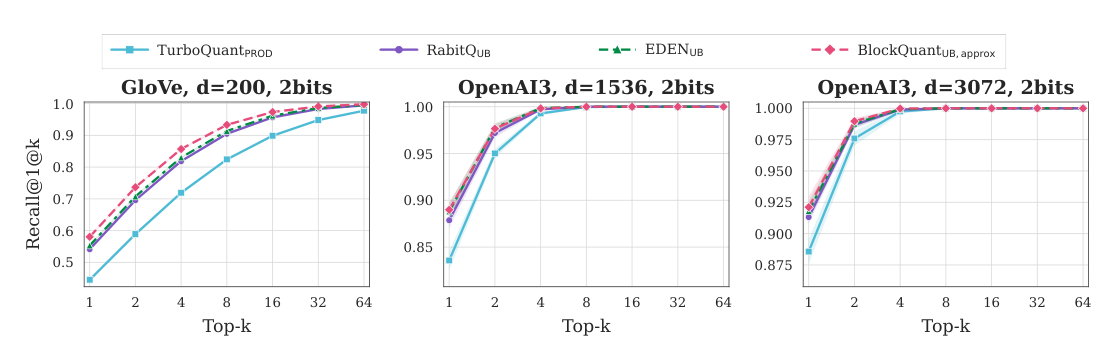
BlockQuant_UB(approx) 在小 $k$ 区间提升最大 —— 这正是排序最敏感的区间,小的内积估计扰动就能改变 top 名次。整体 IP 失真的优势确实转化为了检索召回的优势。
KV-cache 量化(Llama-3.1-8B-Instruct)¶
设定:query state 保留 full precision,key/value cache 量化。Outlier-aware key cache:head dim $d_h = 128$,每个 head 取 L2 norm 最大的 32 channel 作为 outlier 用 4-bit、剩余 96 channel 用 3-bit、再加 2 个 float16 scaling,整体每维有效 bit-width $\tfrac{32\cdot 4 + 96\cdot 3 + 2\cdot 16}{128} = 3.5$。value cache 全维度 2-bit 均匀量化。其他模块(weight、MLP、embedding、output projection)均不量化。
所有方法 5 个随机种子,报告 mean ± std。
Needle-In-A-Haystack¶

BlockQuant 几乎完美保住 Needle 检索能力(仅比 full 差 0.003),而 TurboQuant 损失 0.032。在 long-context 场景下小的量化噪声会跨 token 累积,所以 KV-cache 的失真质量对最终任务表现尤其敏感。
LongBench-E¶
| Method | SingleQA | MultiQA | Summ | Few-shot | Synthetic | Code | Average |
|---|---|---|---|---|---|---|---|
| RabitQ | 19.12 (0.54) | 15.88 (0.26) | 29.40 (0.11) | 68.23 (0.10) | 55.75 (0.35) | 60.35 (0.13) | 43.52 (0.15) |
| TurboQuant | 18.60 (0.39) | 15.79 (0.15) | 29.11 (0.11) | 68.19 (0.10) | 55.31 (0.81) | 59.72 (0.49) | 43.20 (0.20) |
| EDEN | 19.02 (0.27) | 16.30 (0.26) | 29.42 (0.17) | 68.46 (0.12) | 56.29 (0.22) | 61.41 (0.21) | 43.87 (0.07) |
| BlockQuant | 19.55 (0.46) | 16.31 (0.15) | 29.72 (0.14) | 68.49 (0.16) | 56.48 (0.57) | 61.42 (0.34) | 44.03 (0.10) |
| Full Cache (16-bit) | 19.53 | 16.54 | 30.28 | 68.41 | 56.41 | 61.60 | 44.15 |
BlockQuant 在 6 个任务组上全部第一,平均 44.03(vs Full Cache 44.15,gap 仅 0.12)。EDEN 43.87 第二,RabitQ 43.52 第三,TurboQuant 43.20 最差 —— 这个相对顺序与 Section 3 的 IP 失真理论排序一致。注意 TurboQuant 在 LongBench 上明显落后,对应理论预测中其 IP 失真 $\sim$4 倍于 EDEN/RabitQ。
注:作者用 LongBench-E 的官方
result.json评估,而不是 TurboQuant 原文那种"取首行/首 token 截断后评分"的后处理,避免 truncation artifact 影响公平比较。
与已归档相关工作的对比¶
Step 2.5: no semantically twin papers found in archive. 文档库中 80+ 篇精读论文里,使用量化的工作(RQ-VAE 家族:TIGER/QuaSID/CapsID/AsymRec/CARD/VarLenRec、KV-cache 压缩 KSA、weight quantization RecoGEM、MoE 球面 k-means AIR-MoE)都把量化作为应用工具用于推荐/路由/推理加速,使用数据驱动的 learned codebook;BlockQuant 是纯量化理论论文,研究 rotation-based VQ 在球面几何上的失真极限,使用从分布解析推导的 codebook。问题层("item ID assignment for rec" vs "general unit-vector compression")和解法层("learned codebook from data" vs "derived codebook from spherical block marginal")都不双同构,不构成 semantic twin。如果需要在文档库中找最接近 BlockQuant 思路的工作,AIR-MoE 的 adaptive spherical k-means + nearest-centroid shortlisting 是最近的方法 —— 但 AIR-MoE 优化的是 MoE expert 路由(IVF-style 候选集),而非向量重构本身,问题面差异显著。
核心贡献总结¶
- 统一比较框架:第一次把 EDEN/RabitQ/TurboQuant 三个 rotation-based 量化器在 reconstruction MSE、expected inner-product distortion、high-probability bit-complexity 三个准则下做精确常数级比较,明确指出 no quantizer dominates across all criteria。
- Block-Sphere Quantization:提出从精确球面块边缘分布构造 codebook 的新算法 BlockQuant,理论上严格优于三个 baseline,并随 $p \to d$ 趋于球面量化的理论极限。
- 更紧的 Shannon 下界:纠正之前 lower bound 推导对 $\mathbb{S}^{d-1}$ 零测度问题的忽略,得到含 $\tfrac{bd}{d-1}$ 指数和精确常数 $c_d$ 的紧下界,并证明 BlockQuant ($p=d$) 在阶和领先常数上都达到该下界。
- 实证验证:在 DBpedia/GloVe/OpenAI3 检索和 Llama-3.1-8B KV-cache 量化(Needle-In-A-Haystack + LongBench-E)上一致验证理论改进,LongBench-E 上 BlockQuant 平均 44.03 已经把 full-cache (44.15) 与最差量化器 (TurboQuant 43.20) 之间的 95% 差距弥补。
讨论与局限性¶
值得借鉴的设计:
- 把"做不做 block"作为一个独立设计变量提出来。BlockQuant 不学 codebook,而是用分布解析推导,这种"理论 codebook"的思路在数据稀缺或追求理论保证的场景很有用。
- bit allocation 的分析(TurboQuant_PROD 用 1 bit 做 QJL 偏差校正反而损失 IP 精度)提醒:unbiased estimator 不是免费的,重构 + scalar correction 是更高效的 IP 估计路径。
- 将 inner-product distortion 和 reconstruction MSE 分开作为独立准则比较,避免"一指标取胜就声称 dominate"的陷阱。
与已有工作的差异:
- 相比 product quantization (PQ) / Optimized PQ (OPQ):BlockQuant codebook 不是从数据学的,避免 catastrophic forgetting 和 distribution-specific overfitting,但也丧失了数据自适应能力。
- 相比 KIVI / 经典 KV-cache 量化:BlockQuant 是数据无关的 rotation-based 方法,适合通用 LLM 推理;KIVI 等利用了 channel 维度的统计特性做 asymmetric quantization。两者可以正交叠加(实验里的 outlier-aware 分通道就是借鉴了 KIVI 风格)。
局限: 1. 块大小的工程开销:codebook size 是 $2^{bp}$,$p=3, b=4$ 时 4096 个 centroid 每块需要精确搜索,online 开销随 $b$ 和 $p$ 指数增长。作者用 lookup-table 近似缓解,但近似搜索的精度损失需要更细的研究。 2. 只针对单位向量:所有理论分析都假设 $\mathbf{x} \in \mathbb{S}^{d-1}$,对一般向量需要额外存储 norm(如 KV cache 的 outlier-aware 设计就是把 norm 信息折进 channel-wise scale)。 3. 不利用数据特性:理论 codebook 在 worst-case (uniform on sphere) 下最优,但真实 embedding 分布往往不是各向同性的,data-driven codebook 在特定数据集上可能反而更好。论文没有对比 BlockQuant 与 PQ/OPQ 这类 learned codebook 方法在实际 embedding 上的差距。 4. High-probability guarantee 仍弱于 RabitQ:在 high-accuracy 区间 BlockQuant 的 bit complexity 与 EDEN/TurboQuant 一样未达 RabitQ 水平。若 KV-cache 场景需要 worst-case 个体保证(如 outlier token 不能被严重破坏),可能仍需考虑 RabitQ 风格的设计。 5. 工业部署成本未论证:codebook 离线构造对 $p = 3, b = 4$ 已经需要 2D K-means 收敛,更高 $p$(如 $p = 8$)时构造时间和内存都会成为瓶颈。论文未给出 codebook construction 的实际墙钟时间。
与本档案库的关联价值:虽然 BlockQuant 本身不是推荐系统论文,但它在 KV-cache 量化方向给出的 SOTA 是个直接可用的组件 —— OneRec / RankMixer 等大模型化的推荐系统未来若需要进一步压低 KV-cache 显存,BlockQuant 是比 EDEN/RabitQ/TurboQuant 都更值得集成的方案。同时它对"rotation-based + spherical-aware codebook"这条线的理论闭环也为后续推荐系统中的 semantic ID tokenization(RQ-VAE 家族)提供了一个 worst-case 分布上的对照参考。