CCD-Level and Load-Aware Thread Orchestration for In-Memory Vector ANNS on Multi-Core CPUs¶
Yuchen Huang, Baiteng Ma, Yiping Sun, Yang Shi, Xiao Chen, Xiaocheng Zhong, Zhiyong Wang, Yao Hu, Chuliang Weng (East China Normal University & Xiaohongshu/RedNote)。arXiv 2605.10090,2026-05-11。
研究动机与背景¶
工业向量检索对 CPU 多核架构的依赖¶
向量近似最近邻搜索(ANNS)支撑了 RedNote(小红书)的搜索引擎、推荐系统和广告业务。在亿级月活、毫秒级延迟 SLA 的工业场景中,每秒需承载千万级 QPS。虽然 GPU 在索引构建上更快 [6,7],但内存型 ANNS(HNSW、Vamana、IVF)部署在 CPU 上仍是低延迟在线服务最具性价比的选择。
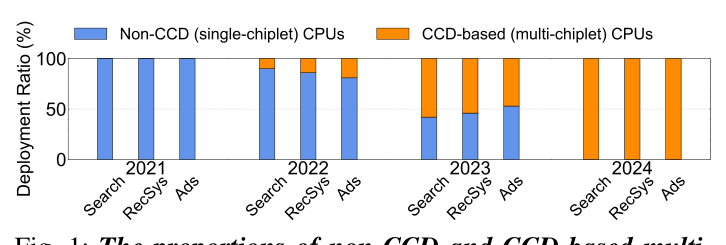
硬件趋势:随着工艺缩放和良率成本上升,服务器 CPU 不再走单 die 增多核的路线,而是转向多 CCD(Core-Complex Die,核心复合 die)+ chiplet 的多片设计——AMD EPYC(Rome、Milan、Genoa、Turin)和 Intel 下一代 Sapphire Rapids 都采用 CCD 架构。和"加 socket 形成 NUMA 节点"不同,CCD 让单 socket 内的核数翻倍(intra-socket scaling)。RedNote 服务集群中 CCD-based CPU 的占比逐年上升,2024 年已基本完全取代单片 CPU。
但作者在生产环境中观察到的关键问题是:简单加核(直接给在线 ANNS 服务分配更多 CPU 核)并不会带来对应的吞吐提升。论文用真实工作负载和硬件 trace 揭示了三类原因:
- 短时间窗口内的强搜索局部性:同一 vector table 上的连续查询会探测高度重叠的节点子集,造成显著的内存访问局部性;
- CCD 的私有 LLC 隔离:不同 CCD 拥有相互独立的 last-level cache(L3),不合理的 chiplet 间任务派发会触发 cache pollution 和 affinity 断裂;
- 跨 vector table / cluster 的搜索开销严重 skew:朴素的轮询调度对 skew 不敏感,反而被 cross-chiplet steal 进一步放大 cache 浪费。
索引结构与生产部署¶
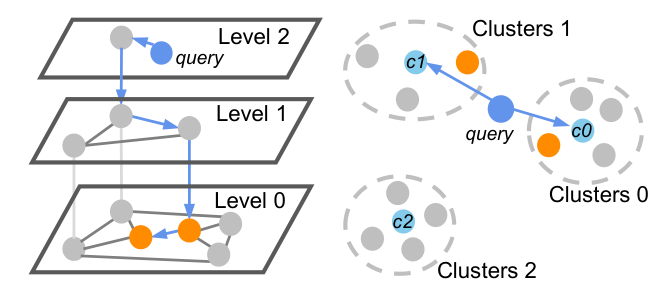
论文聚焦工业实践中最主流的两类索引:
Graph-based HNSW(refs. [8]):每个向量在层级图中按几何分布随机抽样一个最大层,逐层加入。查询从顶层入口贪心下降,最终在 Level 0 用大小为 efSearch 的候选队列做 best-first 搜索,返回 top-k。
Clustering-based IVF(refs. [10],FAISS):向量先经 k-means 划分为 nlist 个簇,存入倒排链;查询时先计算到所有 centroid 的距离,选 nprobe 个最近簇,再扫描这些簇的倒排链算距离排序。
部署选择上:
- HNSW 单次距离评估少,单核即可达毫秒级延迟,但构建/更新成本高(1–100M 规模需要几分钟到几小时,频繁全量重建对刷新性高的工作负载不友好);
- IVF 用 k-means 粗划分,构建/更新可在几分钟到几秒完成,适合高刷新部署,但查询需要并行扫多条链才能到毫秒级(FAISS 通过 OpenMP
#pragma omp parallel for schedule(dynamic)实现 intra-query 并行)。
RedNote 因此采用混合部署:HNSW 单表绑核(inter-query 并行,多 HNSW 表 co-locate),IVF 单查询跨核(intra-query 并行)。
CCD-Based CPU 架构¶
CCD 架构的核心差异:L3 不再是全局共享的单块结构,而是每个 CCD 拥有独占的本地 LLC(local L3),仅对本 chiplet 内的核心可见且低延迟。AMD 4th Gen EPYC 96-core 9654 有 12 CCD × 8 核,每 CCD 32MB L3;AMD 2nd Gen EPYC 48-core 7K62 有 12 CCD × 4 核,每 CCD 16MB L3。单 socket 内"加 CCD"等于"加私有 LLC + 一组核"。
朴素扩核的低效¶
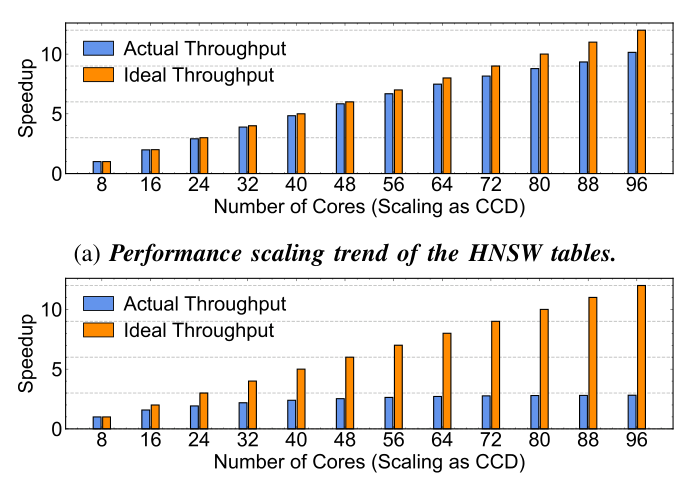
作者用线上 trace 衡量了"加核不加性能"的程度:
- HNSW:朴素 inter-query round-robin 从 16 核到 96 核仅 9.9× 加速,96 核只到 ideal 吞吐的 ~82%;
- IVF:FAISS 的 OpenMP 实现 在少于 32 核时仍有明显增益,超过 32 核后边际收益跌至几乎为零,2–12 CCDs 总加速比仅 1.6×–2.8×。
这是显著的硬件-软件失配空间,也是论文要打开的优化口。
工作负载特征化¶
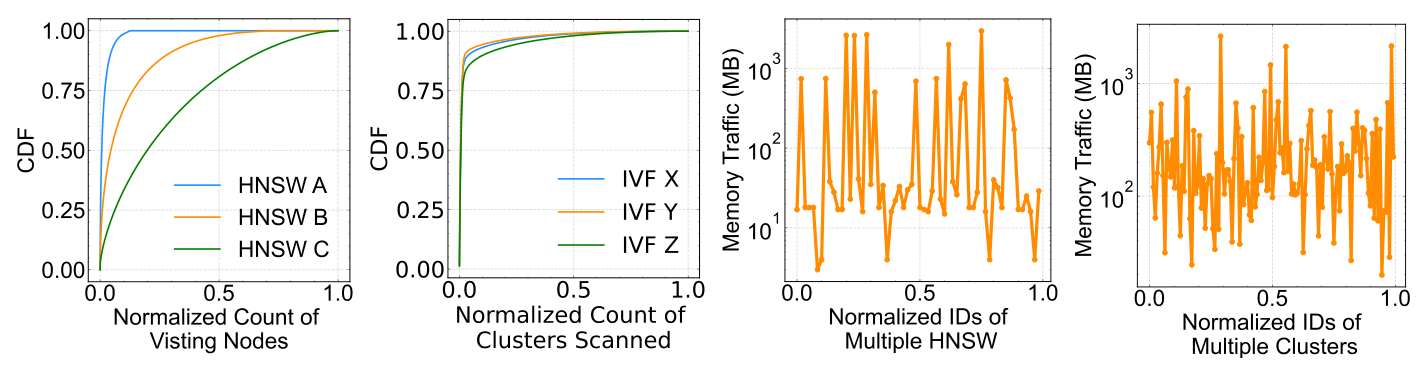
第一组观察来自 6 张代表性线上表(3 HNSW + 3 IVF):每条 query 短时窗内访问的图节点 / 倒排链的 CDF 在 0 附近陡升——少量 hot 节点 / 簇承担大部分访问。这指向短时强局部性:连续查询大概率反复 touch 同一组节点。
第二组是逐表/逐簇的总字节流量(reads+writes),同样高度长尾,单表/单簇可达另一个 1–3 个量级——即少量 hot table / hot cluster 的内存流量占主导。
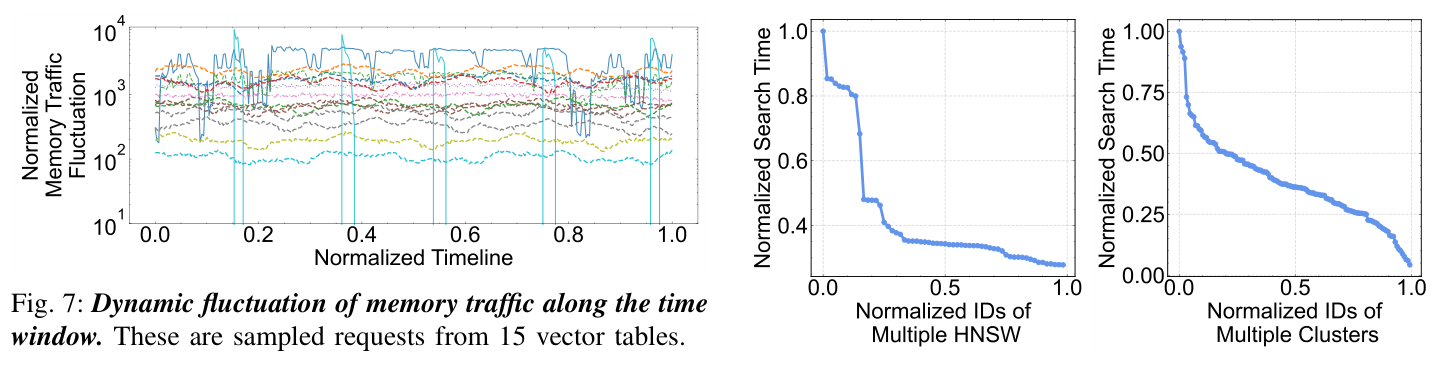
第三组是 Figure 7:hot 与 cold 角色随时间窗口在不断切换。这意味着 CCD 映射不能是静态的,必须在线感知并随时间调整。
第四组观察:每张表 / 每个 cluster 的平均单次搜索时间也呈陡头长尾,跨度数倍于中位数。即使均匀派发任务也会因 per-item 时间方差产生严重的负载不均,再叠加 round-robin 派发 → cross-CCD 偷任务 → cache pollution。
三大设计挑战¶
作者把工业落地诉求归纳为三条:
- 兼容性与最小侵入性:需要统一的 thread-orchestration 接口,对 HNSW(inter-query)和 IVF(intra-query)都透明,不重写索引;
- CCD-friendly 任务派发 + 动态自适应:因 LLC 跨 CCD 独立,naive spread 会引发跨 CCD 的 cache pollution,需要把任务映射到合适的 CCD 并动态调节;
- 拓扑感知的负载均衡:HNSW 表 / IVF 簇的搜索开销 skew,需要在线协调 cores、利用 locality-aware stealing 既保 cache 复用又保利用率。
与已有工作的位置¶
论文罕见地从 thread orchestration 的角度切入 ANNS——既有工作多聚焦搜索过程加速 [18–21]、距离评估优化 [22,23]、参数调优 [22,24]、量化压缩 [25,26]。作者声称是首个针对 in-memory ANNS 在多核 CCD CPU 上做 thread orchestration 优化的工作。最相关的工业前驱是 [54] Jain et al., ASPLOS'25「Load and MLP-Aware Thread Orchestration for Recommendation Systems Inference on CPUs」,但其关注 DLRM 推理而非 ANNS。
核心方法 / 模型架构¶
整体框架¶
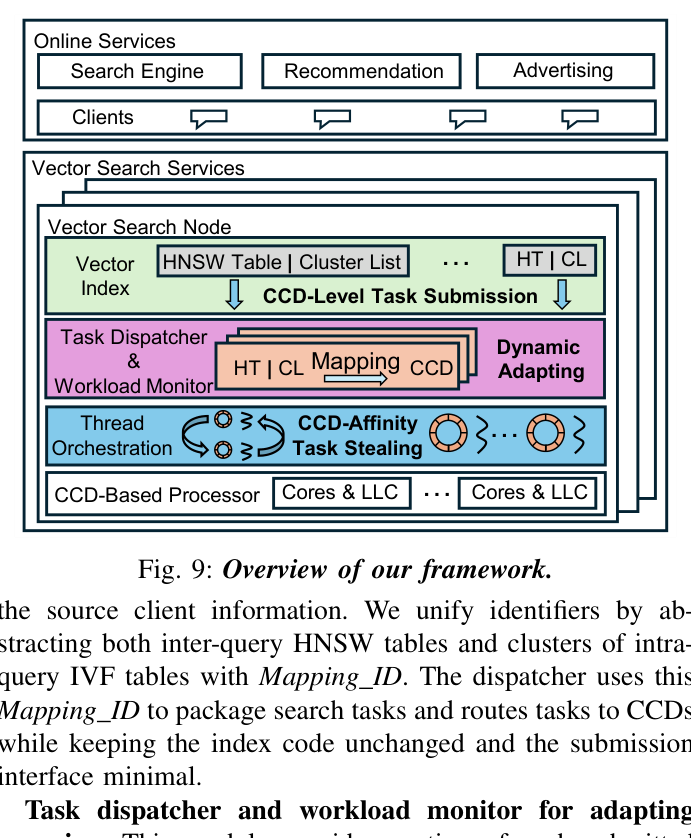
整体框架由三个紧耦合组件构成(图 9):
- CCD-Level Task Submission——drop-in 兼容接口,向上对接 HNSW / IVF 各自的搜索代码,向下统一封装 query;
- Task Dispatcher & Workload Monitor——维护
Mapping_ID → CCD的运行时映射,监控 per-table / per-cluster 流量并周期重映射; - Thread Orchestration with CCD-Affinity Task Stealing——每个核绑定一个 worker,从本地 ring 队列消费任务,pop 不到时按"intra-CCD 偷 → cross-CCD 偷"的两级优先级抢任务。
CCD-Level 任务提交¶
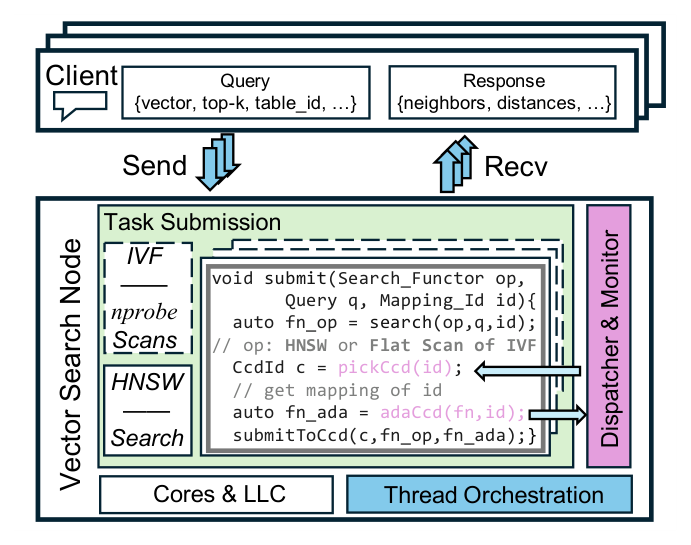
为了让 HNSW(inter-query)与 IVF(intra-query)共用同一框架,作者引入了 uniform submission API:
void submit(Search_Functor op,
Query q,
Mapping_Id id);
search_functor是可插拔回调,可绑定到 HNSW 单表遍历或 IVF 单链扫描;query封装请求元数据(top-k、原始向量、过滤器、客户端信息);Mapping_ID抽象索引身份——HNSW 用table_id,IVF 用table_cluster_id(同一 IVF 表内每条 cluster 一个 ID)。
调度核心两步:
pickCcd(id):dispatcher 根据当前 mapping 查Mapping_ID应去的 CCD,把任务推入该 CCD 内核心的环形队列;adaCcd(fn_op, id):在提交前注册回调,由 monitor 在执行完成后获取测量值(请求频率、touched nodes、scanned vectors),驱动后续 mapping 适配。
与 HNSW 集成:每个 HNSW 请求是单一任务,dispatcher 把它发给一个 CCD 的一个核,由该核完成全表搜索,结果直接返回 client。inter-query 并行来自不同表的多任务并发。
与 IVF 集成:框架把一条 query 拆为 nprobe 个 per-list scan task,每个任务带不同 table_cluster_id,分派到多核多 CCD;所有局部 top-k 收集后做 k-way merge,返回聚合 top-k。intra-query 并行通过对单 query 的多任务分散实现。
这条接口让框架可以无痛替换之前服务的 thread-orchestration,不修改索引实现。
Task Dispatcher 与 Workload Monitor¶
流量 skew 与 hot-cold co-location¶
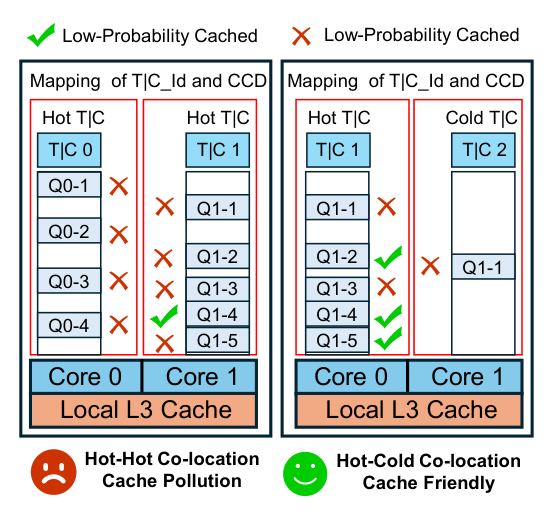
per-CCD L3 只对本 CCD 核可见,cache affinity 在 CCD 粒度天然成立——同一 hot table/cluster 的任务派到同 CCD 能复用其工作集。但若两张 hot 表撞到同 CCD,它们的工作集互相挤占 L3,触发 reciprocal eviction、连续 cache miss(hot-hot)。把一张 hot 表配上一张 cold 表(hot-cold)时 cold 仅有少量请求,对 L3 占用极小,hot 表的工作集得以驻留——这就是作者的核心 mapping 设计原则。
设计规则¶
pickCcd(id) 在 dispatcher 内部维护的 load-aware mapping 上查询,遵循两条原则:
- 黏性(stickiness):同一
Mapping_ID的重复提交回到同一 CCD,以复用 memory locality; - 反 hot-hot、亲 hot-cold:避免两个 hot item 同 CCD,优先 hot-cold 配对,减少 cache pollution。
内存流量估计¶
由于 HNSW 和 IVF 都不暴露真实的搜索内存流量,作者推导了轻量在线估计公式:
记 (D) 为维度、(s_v) 为单元字节(FP32 为 4)、(B_v = D \cdot s_v) 为向量负载字节、(s_{\text{id}}) 为 ID 字宽(典型 UINT32 → 4 字节)。
HNSW:搜索宽度 efSearch 平均触达 (N) 个节点(runtime 报告确切计数),每访问一个节点要读其向量与邻接表(最大出度 (M)):
$$T_{\text{HNSW}} \approx N \cdot (B_v + M \cdot s_{\text{id}}) + \delta_{\text{meta}} \tag{1}$$
其中 (\delta_{\text{meta}}) 包含 top-k heap 维护、visited list 等小写读(通常 < 1%),可忽略。
IVF:路由到 nprobe 个 cluster 后按 per probed list 统计(而非整 query)。链 (\mathcal{L}_i) 扫 (S_i = |\mathcal{L}_i|) 个向量,流量:
$$T_{\text{IVF}}(\mathcal{L}_i) \approx S_i \cdot B_v \tag{2}$$
只读向量值即可,不需要 ID(cluster 内已经按 ID 组织)。
算法 1:Balanced Hot-Cold Pairing for Mapping¶
设 (m) 个 CCD、(n) 个 item,按估计的 traffic 数组 (\hat T[1..n]) 做 hot-cold 配对:
输入:流量数组 T̂[1..n],CCD 数 m
1: μ ← ΣT̂[j]/m // 每 CCD 目标负载
2: 按 T̂ 降序排序 → A[1..n]
3: 初始化 L[1..m] ← 0;i ← 1;j ← n // 两端扫描
4: while i ≤ j do
5: r* ← argmin_r L[r] // 当前最轻 CCD
6: t ← A[i]; i ← i + 1 // 取最热剩余 item
7: cap ← max(0, μ − L[r*] − T̂[t]) // 剩余容量
8: if i ≤ j and T̂[A[j]] ≤ cap then
9: p ← A[j]; j ← j − 1
10: 映射 {t, p} 到 r*;L[r*] ← L[r*] + T̂[t] + T̂[p]
11: else
12: 映射 t 到 r*;L[r*] ← L[r*] + T̂[t]
13: end if
14: end while
15: return Mapping {items → CCD}
算法语义:始终把最热残余 item 放到当前最轻CCD(push 极性向均值收敛),若残留容量能塞下最冷残余 item,就一起配进同一 CCD(鼓励 hot-cold 共存)。一遍 sweep (O(n \log n))(仅排序),实际开销可忽略。
Windowed Re-mapping with Snapshot Swap¶
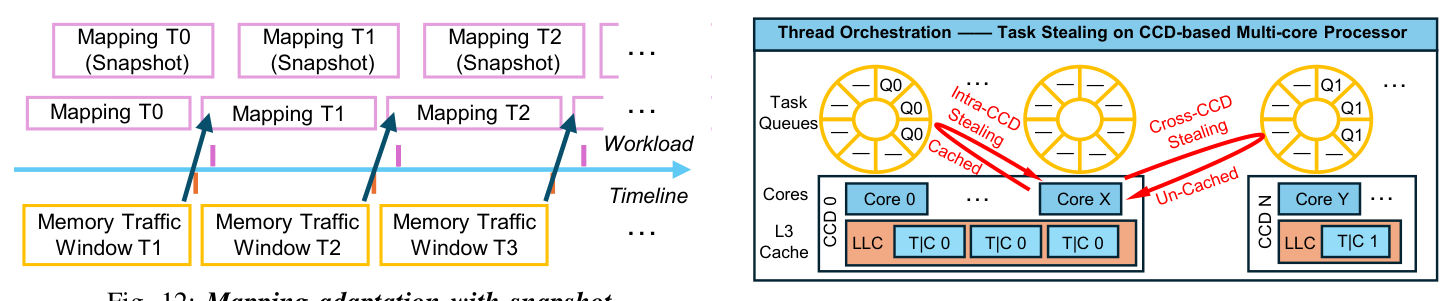
实时调度路径上若强行替换 mapping,会出现新旧任务争抢同一 entry 的 race。作者用 epoch 化的 snapshot 切换:
- 当前 snapshot:dispatcher 服务期 mapping;
- next-map:monitor 在后台用上一窗口(典型分钟级,电商场景)的流量聚合构建;
- 一旦 next-map 就绪,atomic publish 为新 snapshot:新请求用新 map,已在飞任务继续用老 map 直到 retire;
- 老 map 所有任务 retire 后才丢弃。
这种 snapshot-based handover 让 reconfiguration 在不打断在线服务的前提下完成。
CCD-Affinity 任务窃取¶
单 CCD 内偷 vs 跨 CCD 偷¶
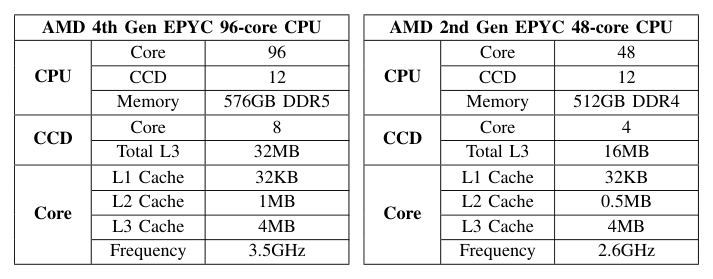
work-stealing 的传统假设是所有核共享一致的 cache,CCD 架构下不成立:
- intra-CCD steal:受害者就在同一 LLC 域,工作集已被 warmed,偷过来基本不增 miss;
- cross-CCD steal:受害任务的工作集驻留在另一 CCD 的 L3,偷过来要重 warm 当前 CCD 的 L3,既增加 cache miss 又污染目标 CCD 的 cache。
算法 2:CCD-Topology Friendly Task Stealing Workloop¶
线程绑核后,作者初始化时物化 CPU 拓扑:对每个 core (i),记录 intra-CCD 邻居核集 (\mathcal{S}{\text{in}}(i))(同 CCD 其他核)与 cross-CCD 邻居核集 (\mathcal{S}(i))(其他 CCD 核)。worker 主循环:}
1: while true do
2: t ← PopLocal(Q_i) // 1) 优先消费自己队列
3: if t ≠ null then Execute(t); continue end if
4: t ← TrySteal(S_in(i)) // 2) intra-CCD 偷(保 cache)
5: if t ≠ null then Execute(t); continue end if
6: t ← TrySteal(S_cross(i)) // 3) 全 CCD idle 时才跨 CCD 偷
7: if t ≠ null then Execute(t); continue end if
8: end while
三级优先级保证:
- own-queue first:保最高 locality;
- intra-CCD steal:跨核但同 LLC,cache residency 几乎不变;
- cross-CCD steal:仅作最后兜底,且仅在该 CCD 全核 idle 才触发。
这套抽象让 work stealing 在尊重 CPU 拓扑的同时保持高利用率,与 dispatcher 的 hot-cold mapping 形成互补:mapping 控制初始放置(locality 起点),stealing 控制余量分担(locality 兜底)。
实验设置¶
硬件配置¶
论文用两代 AMD EPYC 评测,二者都是 CCD 架构:
| Platform | AMD 4th Gen EPYC 96-core (Genoa 9654) | AMD 2nd Gen EPYC 48-core (Rome 7K62) |
|---|---|---|
| Core / CCD / Memory | 96 / 12 / 576GB DDR5 | 48 / 12 / 512GB DDR4 |
| Cores per CCD | 8 | 4 |
| Total L3 per CCD | 32MB | 16MB |
| L1 / L2 / L3 per Core | 32KB / 1MB / 4MB | 32KB / 0.5MB / 4MB |
| Frequency | 3.5 GHz | 2.6 GHz |
操作系统 CentOS 8 / Linux 5.10。所有 C++ 实现,GCC 11.4 -O3 编译。距离评估走 AVX 指令;HNSW 与 IVF 实现分别参考 hnswlib [8] 与 FAISS [10]。
工作负载¶
来自 RedNote 生产推荐 / 广告服务的真实 trace:
- HNSW 部署(inter-query parallel):一节点上 60 张 HNSW 表,每张 1M–10M 行;
- IVF 部署(intra-query parallel):一节点 15 张 IVF 表,每张 10K–15M 行;
- 维度 64–256,top-k 100–500;
- HNSW 配置 (M=32)、
efConstruction=500,efSearch调到 recall ≥ 99%; - IVF
nlist∈ [128, 8192](保分钟级构建期),nprobe调到 recall ≥ 95%; - 总查询量:HNSW ~1M、IVF ~1.1M。
Baselines¶
- V0 (RR / FAISS):朴素 round-robin(HNSW)/ 默认 FAISS OpenMP intra-query 并行(IVF);
- V1 (bthread):不感知 CCD 拓扑的线程框架 + work stealing(参考 bthread 实现 [34],是 RedNote 生产部署的主流方案);
- V2 (CCD):本文方案。
主要实验结果¶
饱和吞吐:跨代 CPU 的 scaling¶
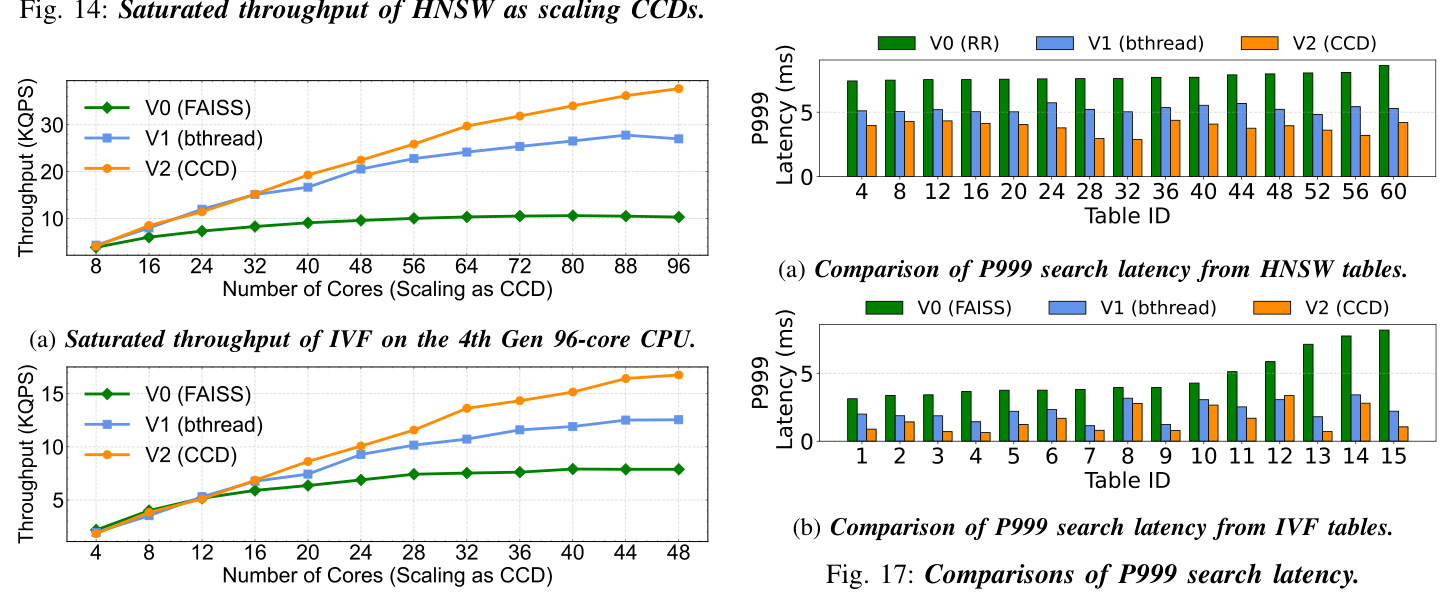
- HNSW:在 Genoa 96 核上 V2 达到 100+ KQPS,相对 V1 / V0 拉开稳定差距,吞吐基本线性扩展;
- IVF:在 Genoa 96 核上 V2 35 KQPS、V1 25 KQPS、V0 仅 10 KQPS——V0(FAISS) 的扩展曲线在 32 核以上几乎平坦,验证了 OpenMP 在 chiplet 架构上的 scaling 退化。
结论:V2 不靠改 ANNS 算法、不靠加机器,仅靠 thread orchestration 就让 saturated throughput 比 V0 提升 1.4×–3.7×。
延迟分布:P50 与 P999¶
- 对 V0/V1:V2 在 HNSW 与 IVF 上均观察到 P50 与 P999 同向下降 30–90%——thread orchestration 同时治好了均值与长尾,原因是 cache-friendly 派发减少均值 miss,topology-aware stealing 收敛长尾抖动。
Cache miss 与 CPU stall 的微观证据¶


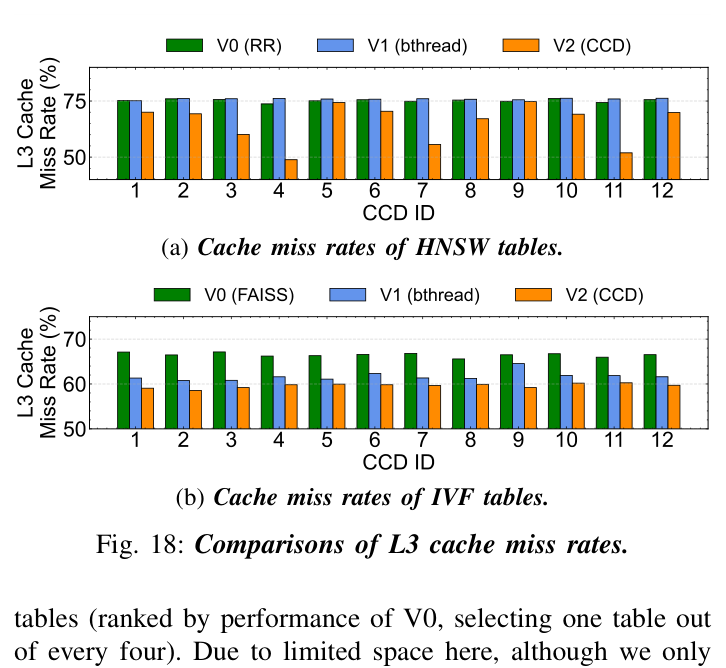
三项硬件计数(AMD uProf 采集)给出"为什么":
- L3 cache miss rate(图 18):V2 在所有 12 CCD 上一致低于 V1/V0,HNSW 与 IVF 都呈现 6–30% 的相对下降;
- CPU stall(图 19a):等待长延迟内存访存、指令 fetch、线程切换的周期数被 V2 降至最低,总 stall 减少 20–80%——直接对应吞吐与 P99 的双向改善;
- Cross-CCD steal ratio(图 19b):V1 在 HNSW 上 ~75% 的 steal 都跨 CCD,IVF 上更甚 ~80%;V2 把这两个比例分别压到 < 10% 与 ~5%——即 stealing 在 V2 下 95%+ 都是 intra-CCD,保住了 cache 局部性。
在线 serving 表现¶
- HNSW 上 V1 频繁有瞬时 spike,V2 全程平坦;
- IVF 上 V1 与 V2 都稳定,V2 持续低于 V1;
- 重映射间隔取 10s 时,重映射对延迟无可察觉冲击——snapshot swap 是 low-overhead、harmless 的。
消融与分析¶
虽然论文未给出标准的"逐组件消融表",但通过三段对比展开了等价分析:
- V1 vs V2(去掉 CCD-aware 映射 + 不带 CCD-affinity stealing):cache miss、CPU stall、cross-CCD steal 比例的三段证据集中地把改进归因到 CCD 感知层。仅有 work stealing(V1 = bthread)相对 round-robin/FAISS(V0)有部分提升,但远未达到 V2 水平;
- V0 vs V1(仅引入工作偷取,不改派发):作者反复指出 IVF 上 V0(FAISS) → V1(bthread) 的 stall 降幅可观,但 V1 在 HNSW 上几乎与 V0 持平 —— 印证了"光靠 stealing 不感知拓扑收益有限";
- CCD-affinity stealing 的独立贡献:图 19b 把 cross-CCD steal 从 ~75% 压到 < 10%,且伴随 cache miss 下降而不是吞吐回退——证明 intra-CCD 偷优先策略并非以牺牲利用率为代价。
讨论与局限性¶
核心贡献¶
- 新视角:首次从 thread orchestration 视角切入 in-memory vector ANNS 的 CCD CPU 优化,把"加核不出活"的工业现象归因于 cache affinity 与 load skew 的双重失配;
- 统一接口:用
submit(search_functor, query, Mapping_ID)兼容 inter-query HNSW 与 intra-query IVF,索引代码不变,迁移成本极低; - 算法-硬件 co-design:hot-cold balanced pairing(Algorithm 1)+ topology-aware two-tier stealing(Algorithm 2)+ snapshot-swap remap 构成一套自洽的运行时;
- 强工业证据:在 RedNote 真实 trace 与生产部署上验证 1.4×–3.7× 吞吐提升、30–90% P50/P999 改善、6–30% miss 降幅、20–80% stall 降幅,且证明 remap 本身 harmless。
值得借鉴的设计¶
- "item → CCD" 的两级缓存等效抽象:把 HNSW 表与 IVF cluster 都映射成
Mapping_ID,让派发器看到的就是带 traffic 的对象,不必绑定到具体索引语义; - hot-cold 配对:和 OS 调度器经常做的"按 fairness 均摊"思路相反——故意把"重负载"和"轻负载"放一起,反而能给 L3 cache 留出"热集驻留 + 冷项无害"的良性结构;
- snapshot swap:避免 lock-free 改写运行时表的复杂性,老 epoch 自然 retire;
- 三级偷取层次:把 cache topology 编码进 stealing decision,对所有未来 chiplet-based 多核服务程序都有参考价值。
局限性¶
- 业务/索引覆盖窄:论文聚焦 HNSW(inter-query)与 IVF(intra-query),未触及 graph-based 与 IVF-quantized 混合(如 DiskANN、SPANN、Starling [47–49]);
- Mapping_ID 假定:要求一个稳定的 item-粒度标识——HNSW 一表一 ID、IVF 一簇一 ID 是清晰的,但若索引采用动态分片或频繁 split/merge,
Mapping_ID的语义稳定性会被打破; - 流量估计仅模拟:(1) 式忽略
δ_meta、(2) 式忽略 ID 读取,工业上够用,但在不同 dimensionality / 不同 efSearch 区间可能产生偏差; - 重映射间隔取定:默认分钟级(电商场景),论文未提对突发流量是否需要 sub-second 级 remap,亦未讨论 reactive vs predictive 调度的对比;
- 缺少 quantization / 压缩协同:作者在 Related Works 中提到 RaBitQ [25]、PQ/SQ [26] 等量化方法可以减少向量负载,但本文未与之联动评估——给出未来工作方向;
- 跨 vendor 验证缺失:实验全部在 AMD EPYC(CCD)上做,Intel Sapphire Rapids 的 Modular Tile 架构未涵盖,结论可外推性需要进一步评估。
工业落地价值¶
论文是高度工程化的工业报告:
- 产品集成层级:framework 是 drop-in 替换 RedNote 现有的 bthread orchestration,不修改索引代码;
- 观测口子完整:CPU stall、cache miss、cross-CCD steal 全程上报,便于线上 dashboard;
- 运维友好:snapshot swap 对在线服务无停机;重映射开销极低、harmless;
- 直接收益:搜索 / 推荐 / 广告核心链路吞吐提升 1.4–3.7×,P50/P999 降 30–90%;按 RedNote 日 QPS 量级,可估算每节点每秒省下数十-百毫秒级延迟和数百万 USD/年量级 OPEX。
与已归档相关工作的对比¶
HLEM HLEM — One Pool, Two Caches: Adaptive HBM Partitioning for Accelerating Generative Recommender Serving (HKBU & Alibaba, 2026-05-06)¶
关系:独立并发(本文未引用 HLEM,HLEM 发表在本文前 5 天)· 已加载对方精读
- 共同关注的问题:硬件上有限的局部缓存被多种竞争性工作负载共享,且热度结构在时间维上漂移——直接均匀分配会丢失 cache 局部性、跌入 stall 主导的退化区。HLEM 关心的是 GPU HBM 在 EMB cache 与 KV cache 之间的分配,本文关心 CPU 多 CCD 之间的 task→L3 映射;前者是"垂直划分",后者是"水平派发",但root cause 一致:动态 workload skew 下的局部缓存资源管理。
- 相近的技术骨架:两者都采用 (1) 在线流量监测 + 工作负载特征化;(2) 批量重配置而非逐请求决策;(3) 快照式切换避免抖动——HLEM 用 5s decision epoch,本文用分钟级(可调)的 windowed remap;(4) 结合 metric 反馈与调度策略组合(HLEM 用 PPO + Online Adapter + Recovery Controller 三层;本文用 traffic 估计 + 两端 sweep 配对算法 + 拓扑感知 stealing);(5) 关心 P50 与 P999 的双向改善而不仅吞吐。
- 本文的差异与推进:HLEM 解决一块物理资源(HBM)内部按比例切两份的连续优化问题,用 RL 拟合多因子非线性;本文解决离散的"任务 ↔ CCD"组合优化问题,用确定性的 hot-cold pairing 与拓扑感知 stealing。本文不需要 PPO 训练或离线 trace;HLEM 也不能套用——两者技术工具不可互换。
- 可比的方法 / 实验差异:两文都报告了产线 trace + 1000s 级在线 serving 平稳性;HLEM 报 12–30% P99 改善与 9–22% throughput 提升,本文报 30–90% latency 与 1.4–3.7× throughput 提升——比例上本文更高,因 CPU CCD 上的初始 baseline(FAISS OpenMP / bthread)效率离最优更远;两文的"snapshot swap"思路异常一致,是设计层面值得交叉对照的范例。
核心贡献总结¶
本文是工业向量 ANNS 服务在 chiplet 时代的"运行时层"系统贡献:明确指出"加核不出活"的实质是 CCD 私有 LLC 与 workload skew 的双失配,并用一套 drop-in 框架(uniform submission API + hot-cold balanced pairing + CCD-affinity stealing + snapshot remap)解决之。在 RedNote 真实 trace 与多代 AMD EPYC 平台上展现了 1.4–3.7× 吞吐 / 30–90% P50-P999 / 6–30% miss / 20–80% stall 的综合改善——是把"硬件感知"和"运行时调度"协同到位的优秀工业系统论文,对所有需要在 chiplet CPU 上做高 QPS / 低 SLA 在线服务(搜索、推荐、广告、向量数据库)都有立刻可参考的设计模式。