ComeIR 精读¶
1 研究动机与背景¶
1.1 生成式推荐流水线的三段式结构¶
生成式推荐(Generative Recommendation, GR)将检索建模为自回归地生成下一个物品的语义 ID(Semantic ID, SID)。作者把整个 GR 流水线明确拆为三段(见 Figure 1):
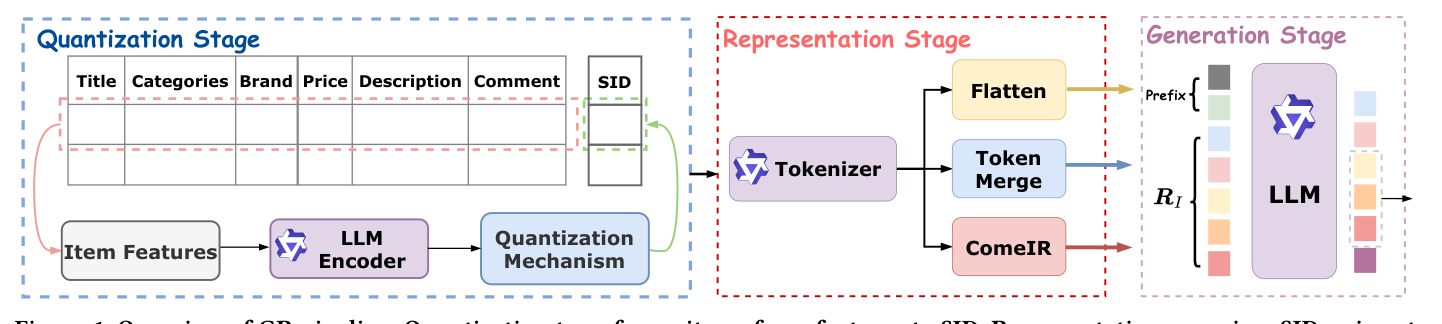
- Quantization Stage:把物品的多模态特征(标题、类目、价格、描述、评论等)通过 LLM Encoder 编码后,再用 RQ-VAE 或 RQ-KMeans 等残差量化器映射成 $L$ 位的 SID $\boldsymbol{c}_n = (c_n^1, c_n^2, \ldots, c_n^L)$;
- Representation Stage:将每个物品的 SID code 序列转成 LLM 的输入表征;
- Generation Stage:LLM 自回归地预测下一个物品的 SID 序列。
绝大多数 GR 研究(TIGER、LSIG、QuaSID、Eager、CXL 等)都聚焦在第一段量化或第三段生成——例如改进 codebook 训练、缓解 SID collision、加速解码或对齐用户偏好。而中间这段表征构造(Representation Stage)几乎是被冷落的。作者将其称为"the bridge between quantization and generation",并指出这条桥决定了 quantized semantic 在进入生成端之前能保留多少结构信号。
1.2 现有表征构造的两条路线¶
目前的表征构造可以归为两条路线:
- Flatten(典型代表:TIGER [32]):把所有物品的 SID code embedding 直接按时间顺序 flatten 成一条长度 $L \times N$ 的 token 序列喂给 LLM。
- Token Merge(典型代表:GenRec 的 TM [51]):通过一层线性投影将每个物品的 $L$ 个 code embedding 压缩为一个 latent 向量,序列长度从 $L \times N$ 降到 $N$,但 LLM 看到的就是一个"打了包"的 item 向量。
或者使用external-input-based方法(如 OneRec-Trans [45]、OneRec [49]):把用户行为信号或多模态特征通过额外的 context compressor 编码进 item-level 表征。
1.3 两个未被解决的痛点¶
作者从这些路线中提炼出两个尚未同时解决的"结构性"问题:
(i) Identity-Structure Preservation Conflict(身份-结构保持冲突)。 有用的 item-level 表征既要保留物品身份信息,又要保留 SID 内部的离散证据(哪个 code 表示了哪一层语义、code 之间如何组合)。但是:
- 直接 merge SID token(线性投影)虽然紧凑,但会放大量化造成的信息损失和 ID 碰撞 [9, 15, 16, 19],并掩盖 SID 携带的码间结构 [15, 33];
- External-input 方法可以注入多模态/行为信号来强化物品语义,但这些信号不是按 SID 结构组织的,因此无法可靠地保留 SID-based 生成所需要的离散证据。
(ii) Input-Output Granularity Mismatch(输入-输出粒度错配)。 已有 item-level constructor 输给 LLM 的是"一坨"item-level vector,但生成端依旧要逐 code 输出细粒度的 SID(fine-grained item retrieval [51]),这导致输入侧是 item 粒度,输出侧是 token 粒度。解码器只能从已被压缩或旁路掉的表征里反推 SID 证据,相当于在"压缩-再恢复"两次绕路。
这两个痛点呼唤一种既是 item-aware(紧凑、保留身份)、又是 structure-preserving(保留 SID 内部码组合)、又能在解码时被 token 级生成头复用的表征构造方法。
1.4 本文贡献¶
作者提出 ComeIR(Conditional memory Enhanced Item Representation),一个 plug-and-play 的 GR 表征构造框架,要点:
- MM-guided Token Scoring(MM-Scoring):用 quantizer 自带的多模态 item embedding 作为身份 query,通过 cross-attention 给每个 SID code 打分,强调 identity-relevant 的码,弱化噪音码——解决 identity 保持问题。
- Dual-level Engram Memory:分别用两块稀疏哈希记忆建模 SID 的两种结构——
- Intra-item Engram:记忆 SID 内部码组合模式(如 $(c_n^1, c_n^2)$ 如何被 $c_n^3$ 细化);
- Inter-item Engram:记忆跨物品的偏好转移模式(不同长度的 SID 前缀序列)。
- Memory-conditioned Token Merge:用 sigmoid-门控残差把 MM-scored embedding 和两块 memory evidence 融合到 item-level 表征 $\boldsymbol{r}_n^I$。
- Memory-restoring Prediction Head:解码每一位 code 时,重新读出与上面同一套的 intra/inter memory,把 token-level SID 证据"还回"prediction head——直接桥接输入-输出粒度错配。
ComeIR 是 plug-and-play 的:可以叠在 normal GR 或 NEZHA 解码器之上,可以配 RQ-VAE 或 RQ-KMeans 量化器,可以换 Qwen3-0.6B 或 LLaMA3-1B 主干。在 Yelp / Amazon Industrial / Amazon Instrument 三个公开数据集上,ComeIR 比"+TM"(GenRec 的 Token Merging baseline)平均提升 7.91%–8.06%(H@5),同时通过把输入长度从 $L \times N$ 缩到 $N$ 实现 2.5× 的推理吞吐。Scaling 实验还观察到 intra/inter Engram 容量与 H@5 的清晰对数线性律。
2 问题定义与符号¶
设用户集 $\mathcal{U}$、物品集 $\mathcal{I}$。每个用户 $u$ 有历史交互按时间排:
$$\mathcal{S}_u = (v_1, \ldots, v_n, \ldots, v_N), \quad v_n \in \mathcal{I}, \quad n = 1, \ldots, N \tag{1}$$
量化阶段将每个 $v_n$ 编码为长度为 $L$ 的 SID $\boldsymbol{c}_n = (c_n^1, c_n^2, \ldots, c_n^L)$。表征阶段把第 $\ell$ 位 code $c_n^\ell$ 通过冻结的 codebook embedding 和可学习 token embedding 联合表示:
$$\boldsymbol{e}_{c_n^\ell} = \boldsymbol{W}_E \left[ \boldsymbol{e}_{c_n^\ell}^B; \boldsymbol{e}_{c_n^\ell}^T \right] \tag{2}$$
其中 $\boldsymbol{e}_{c_n^\ell}^B$ 是冻结 codebook embedding(来自量化器),$\boldsymbol{e}_{c_n^\ell}^T$ 是可学习 token embedding,$\boldsymbol{W}_E$ 是投影到 LLM 隐空间的投影矩阵。整 item 的 SID-level 表示记为 $\boldsymbol{R}_n^S = [\boldsymbol{e}_{c_n^1}; \ldots; \boldsymbol{e}_{c_n^L}]$。
表征构造的一般形式可以写作:
$$\boldsymbol{r}_n^I = f(\boldsymbol{R}_n^S, \boldsymbol{b}_n)$$
最终 GR 输入是 $\boldsymbol{R}^I = [\boldsymbol{r}_1^I, \ldots, \boldsymbol{r}_N^I]$,$\boldsymbol{b}_n$ 是可选的额外输入。当 $\boldsymbol{b}_n$ 不存在且 $f(\cdot)$ 是简单拼接时退化成 Flatten;$f(\cdot)$ 是线性层时退化成 Token Merge。ComeIR 也省略 $\boldsymbol{b}_n$ 而用 quantizer 已有的多模态 embedding 和 conditional memory 做增强。
生成阶段在给定 $\boldsymbol{R}^I$ 下自回归生成下一物品 SID:
$$P(\boldsymbol{c}_{N+1} \mid \boldsymbol{R}^I; \Theta) = \prod_{\ell=1}^{L} P\!\left(c_{N+1}^\ell \mid \boldsymbol{R}^I, c_{N+1}^{\lt \ell}; \Theta\right) \tag{3}$$
3 方法¶
3.1 框架总览¶
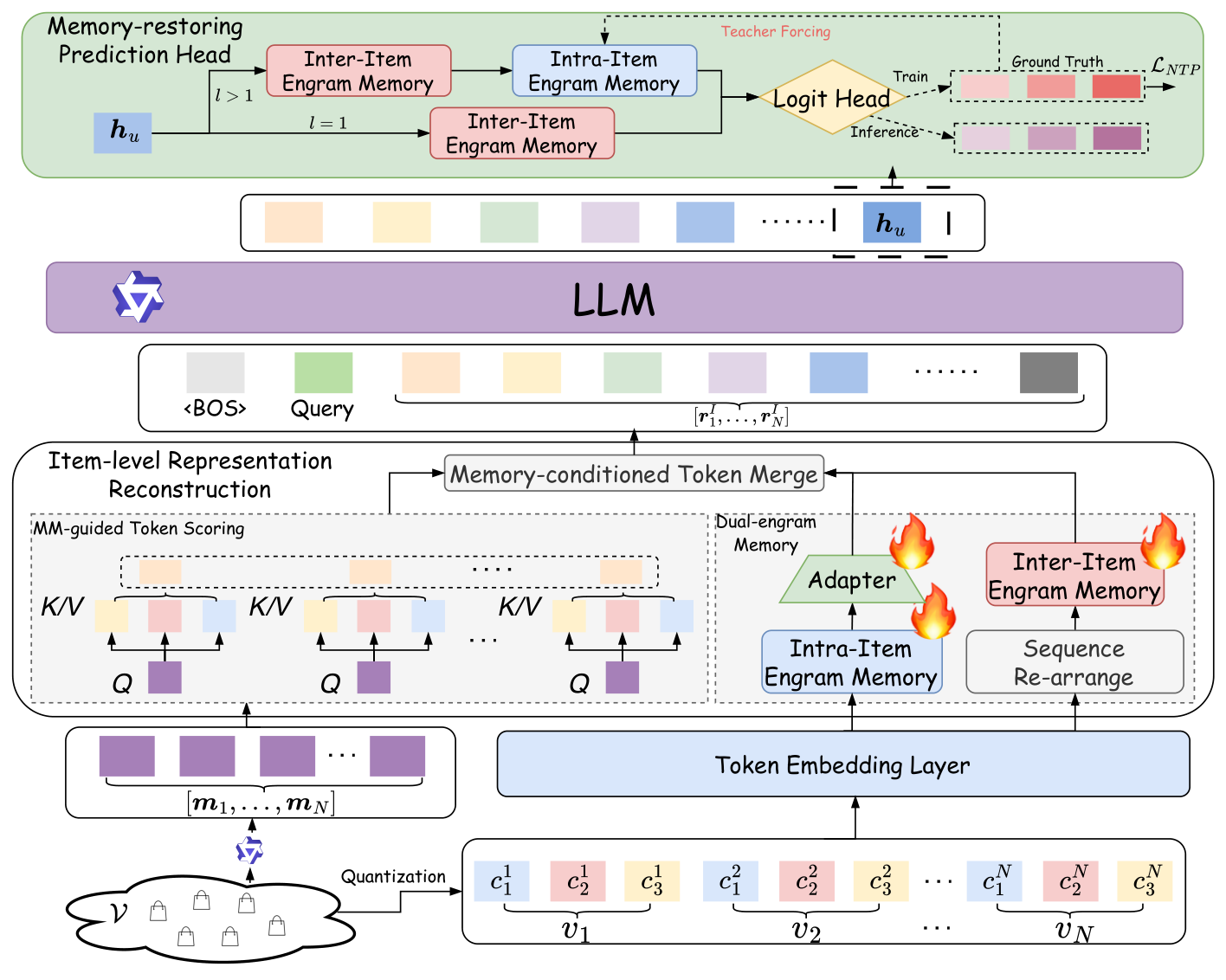
ComeIR 给原本"暗箱式"的表征构造换上了三个新模块:MM-guided Token Scoring 负责打 identity 分数(解决身份保持),Dual-level Engram Memory 负责检索 SID 结构证据(解决结构保持),Memory-conditioned Token Merge 把它们融合成 item-level 输入 $\boldsymbol{R}^I$。生成端再用 Memory-restoring Prediction Head 把同样的两块记忆"取回",为逐 code 的预测提供 token-level 证据,从而打通输入-输出粒度错配。
形式上,整个表征构造分为三步:
- Identity 强调:MM-scoring 用多模态 item embedding $\boldsymbol{m}_n$ 作为 query,对 $L$ 个 code embedding 做加权得到 $\boldsymbol{s}_n^0$;
- Structure 检索:Dual-level Engram 在两类离散模式(intra-item code 组合 / inter-item 前缀转移)上做稀疏哈希查找,得到 $\boldsymbol{\eta}_{n,\ell}^S$(intra 证据)和 $\boldsymbol{\eta}_{n,\ell}^T$(inter 证据);
- Memory-conditioned 融合:从 $\boldsymbol{s}_n^0$ 出发,按 SID 层级逐层把 $\boldsymbol{\eta}_{n,\ell}^S, \boldsymbol{\eta}_{n,\ell}^T$ 通过 gated residual 注入,最终得到 $\boldsymbol{r}_n^I$。
下面逐节展开。
3.2 MM-guided Token Scoring:用多模态身份当 query¶
动机。 直接平均 $L$ 个 code embedding 等价于默认所有码对 identity 同等重要,而实际上 RQ-VAE 顶层码通常代表粗粒度类别("鞋类"),低层码代表精细修饰("红色 / 高帮 / 复古"),不同码对"这件物品是哪件物品"的贡献是不均匀的。作者用同一份quantizer 编码 SID 时已经用过的多模态 embedding $\boldsymbol{m}_n \in \mathbb{R}^{d_{mm}}$作为身份 query,让它来打分——也就是说 identity 信号没有从外部"再灌入",而是从 quantization 旁路重新挂回到 representation 上。
实现。 先把 $\boldsymbol{m}_n$ 投影到 SID embedding 空间:
$$\boldsymbol{q}_n = \boldsymbol{W}_{mm} \boldsymbol{m}_n, \quad \boldsymbol{W}_{mm} \in \mathbb{R}^{d \times d_{mm}}$$
然后做 cross-attention 打分:
$$\alpha_n^\ell = \frac{\exp\!\left( \boldsymbol{q}_n^\top \boldsymbol{e}_{c_n^\ell} / \sqrt{d} \right)}{\sum_{r=1}^{L} \exp\!\left( \boldsymbol{q}_n^\top \boldsymbol{e}_{c_n^r} / \sqrt{d} \right)}, \quad \boldsymbol{s}_n^0 = \sum_{\ell=1}^{L} \alpha_n^\ell \boldsymbol{e}_{c_n^\ell} \tag{4}$$
$\boldsymbol{s}_n^0$ 就是物品 $v_n$ 的 MM-guided context(也是后面层级 memory 注入的初始 summary)。这一步既扮演了 identity query 的角色(强调"哪些码代表了这件物品的身份"),也提供了一个"summary 起点",供后续 dual-level memory 在它上面做层级残差更新。
3.3 Dual-level Engram Memory:把 SID 结构挂在两块稀疏哈希表里¶
3.3.1 General Engram¶
ComeIR 的核心创新是把 Engram(一种基于 N-gram + multi-head hashing + context-aware gating 的稀疏静态记忆 [6])从原本的 Transformer block 内部搬到 representation 接口上,作为表征构造的一部分。这里"static memory"的意思是:内容只通过参数学习(不在 forward 中重写),但通过离散 N-gram 模式做精确寻址,相当于把 SID 模式映射到一个可学习、可扩容、可分布式存储的哈希表条目。
General Engram 的读出操作 $\mathcal{R}_\ell(\boldsymbol{q}, \boldsymbol{p})$ 接收两个输入:
- 离散模式 $\boldsymbol{p} = (p_1, \ldots, p_T)$:决定 what to look up;
- 上下文 query $\boldsymbol{q}$:决定 what evidence should be trusted。
整个过程分两步:
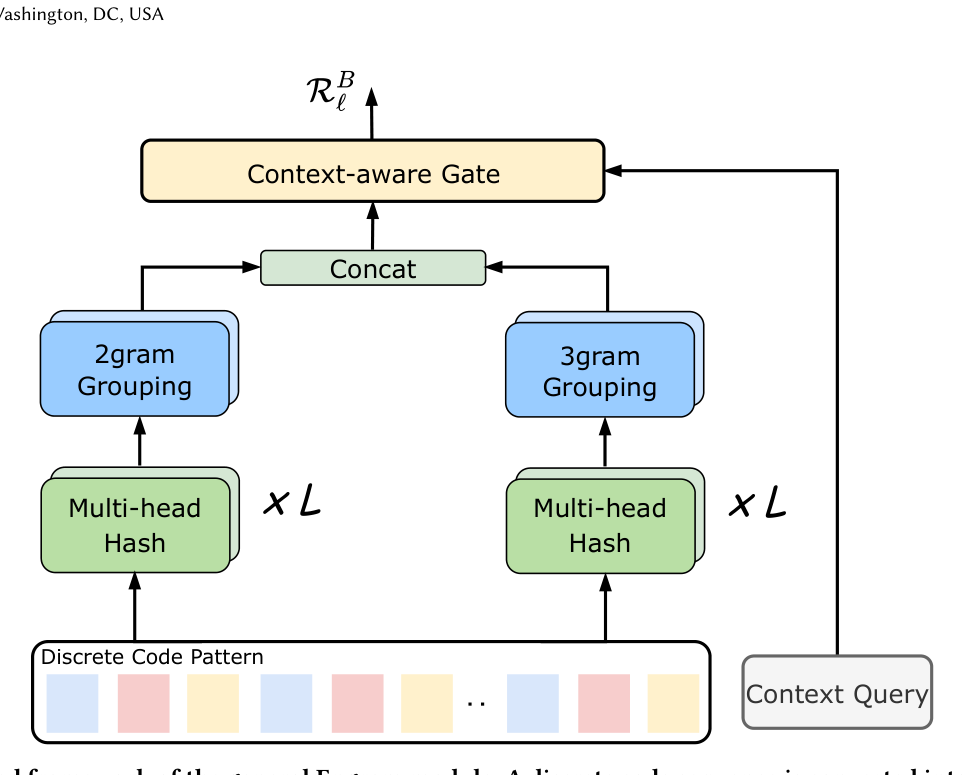
Step 1 — Hashed N-gram Lookup(稀疏哈希查表)。 从 $\boldsymbol{p}$ 提出"末尾 N-gram keys",一个 order-$o$ key 是 $(p_{T-o+1}, \ldots, p_T)$,每个 key 描述一种 N-gram 模式。第 $\ell$ 层使用一个N-gram 阶集合 $O_\ell$。每个 key 经过 $K$ 个独立确定性 hash function(基于 ngram2vec 的多头哈希 [34])映射到 $K$ 张稀疏 embedding table 的特定 slot,取出 $K$ 个 $\mathbb{R}^{d_m/K}$ 维向量,拼接成 address:
$$\boldsymbol{a}_{\ell,o}(\boldsymbol{p}) = \big\Vert_{k=1}^{K} \boldsymbol{M}_{\ell,o,k}\!\left[\phi_{\ell,o,k}(g_o(\boldsymbol{p}))\right], \quad g_o(\boldsymbol{p}) = (p_{\max(1, T-o+1)}, \ldots, p_T) \tag{13, 14}$$
其中 $\boldsymbol{M}_{\ell,o,k}$ 是稀疏哈希表,$H_{\ell,o,k}$ 是 bucket 数;多头独立哈希让两个不同模式偶然撞到同一 bucket 的概率从 $1/H$ 降到 $1/H^K$,所以这是"sparse 但 low-collision"的 lookup。重要的是,同一个模式在不同训练样本里被确定性地映射到同一组 bucket,所以查询到的向量就是这个 N-gram 模式的可学习"语义身份"——可以理解成"为每一种 SID N-gram pattern 单独训一份 embedding"。
Step 2 — Context-aware Gating。 静态查表本身缺乏上下文适应性,且会因 hash collision 引入噪音 [6, 47]。所以再用 $\boldsymbol{q}$ 算一个标量门 $\lambda_{\ell,o} \in (0, 1)$ 来过滤每个 order 的贡献:
$$\lambda_{\ell,o} = \sigma\!\left( \frac{ \left(\boldsymbol{W}_{Q,\ell} \boldsymbol{q} \right)^\top \left(\boldsymbol{W}_{K,\ell,o} \boldsymbol{a}_{\ell,o}(\boldsymbol{p})\right) }{\sqrt{d}} \right) \tag{15}$$
最终 Engram 读出为各 order 经门控加权再投影、归一:
$$\mathcal{R}_\ell(\boldsymbol{q}, \boldsymbol{p}) = \mathrm{LN}\!\left( \sum_{o \in O_\ell} \lambda_{\ell,o} \boldsymbol{W}_{V,\ell,o} \boldsymbol{a}_{\ell,o}(\boldsymbol{p}) \right) \tag{5, 16}$$
ComeIR 把 General Engram 实例化两次:一次用于 SID 内部码组合(Intra-item Engram),一次用于 SID 前缀转移(Inter-item Engram)。两个实例参数完全独立,但读出接口一致,下游融合也用同一套 gated residual。
3.3.2 Intra-item Engram:记忆 SID 内部码组合¶
离散模式定义。 在单个 SID $(c_n^1, \ldots, c_n^L)$ 内,后面的 code 在残差量化语义下相当于"在前面 code 已经定下的语义簇里"做更精细的细分。所以第 $\ell$ 位 code 的"前缀模式"就是 $(c_n^1, \ldots, c_n^{\ell-1})$,模式末尾刚好"指向" $c_n^\ell$。形式化:
$$\boldsymbol{c}_n^{\lt \ell} = (c_n^1, \ldots, c_n^{\ell-1}), \quad \boldsymbol{c}_n^{\leq \ell} = (c_n^1, \ldots, c_n^\ell)$$
由于第一码无前缀,intra-item Engram 从 $\ell = 2$ 起:模式为 $\boldsymbol{p}_{n,\ell}^S = (\boldsymbol{c}_n^{\lt \ell}, c_n^\ell)$,长度为 $\ell$。
读出与聚合。 用 MM-scored summary $\boldsymbol{s}_n^0$ 作为 query,在同一 SID 层级 $\ell$ 累积读出再做 adapter 压缩:
$$\boldsymbol{z}_{n,\ell}^S = \mathcal{R}_\ell\!\left(\boldsymbol{s}_n^0, \boldsymbol{p}_{n,\ell}^S\right), \quad \boldsymbol{\eta}_{n,\ell}^S = \boldsymbol{W}_{C,\ell}^S \left[\boldsymbol{z}_{n,2}^S; \ldots; \boldsymbol{z}_{n,\ell}^S\right] + \boldsymbol{b}_{C,\ell}^S, \quad \ell = 2, \ldots, L \tag{6}$$
Adapter $(\boldsymbol{W}_{C,\ell}^S, \boldsymbol{b}_{C,\ell}^S)$ 把"从第 2 层到当前层的所有读出"拼成一个紧凑的 SID-组合证据 $\boldsymbol{\eta}_{n,\ell}^S$,供后面 Token Merge 使用。
实现细节(来自 Appendix B.2.2)。
- 第 $\ell$ 层 intra 模式的离散单元域是 $C^\ell$($C$ 是 codebook size,本文 $C = 128$)。
- intra 阶集合 $O_\ell^S = \{1, \ldots, O_\ell^S\}$,$O_\ell^S = \min(C^\ell, 3)$;即低层最多用 3 阶 N-gram。
- 每个哈希头用一个 unique prime bucket size $H_{\ell,o,k}^S$,从未使用过的素数池中选——这样不同 head 的模数不同,进一步降低碰撞。
- 整个 intra 的稀疏参数量是 $P_S(s_S) = \frac{d_m}{K_S} \sum_{\ell=1}^{L} \sum_{o \in O_\ell^S} \sum_{k=1}^{K_S} H_{\ell,o,k}^S$,由 intra 缩放因子 $s_S$ 控制。
3.3.3 Inter-item Engram:记忆跨物品的前缀转移¶
离散模式定义。 Inter-item Engram 用来捕捉跨用户-物品交互之间的偏好转移模式,它的"单元"不是单个 code,而是整段SID 前缀——这个细节非常关键。具体地,对每一层 $\ell$,把所有历史物品的 $\ell$ 级前缀按时间排成一个序列:
$$C^{\leq \ell} = (\boldsymbol{c}_1^{\leq \ell}, \ldots, \boldsymbol{c}_N^{\leq \ell}), \quad \ell = 1, \ldots, L \tag{18}$$
每个元素是一个 SID prefix($\ell = 1$ 时只是一个 code,$\ell = L$ 时就是整段 SID)。浅前缀($\ell$ 小)抓粗粒度兴趣漂移(不同 category),深前缀($\ell$ 大)抓精细物品偏好(向某个具体物品收敛)。
序列重排只改"单元"是什么,时间顺序不变。然后取最近 $\tau_\ell \geq \max O_\ell^T$ 个前缀作为离散模式:
$$\boldsymbol{p}_{n,\ell}^T = \mathrm{Suffix}_{\tau_\ell}(C^{\leq \ell}, n), \quad \mathrm{Suffix}_w(\boldsymbol{x}, t) = (x_{\max(1, t-w+1)}, \ldots, x_t) \tag{19, 20}$$
也就是说 $\boldsymbol{p}_{n,\ell}^T$ 是包含位置 $n$ 及之前 $w-1$ 个物品的级别-$\ell$ 前缀转移模式。
Context query 构造。 因为转移依赖于"当前用户最近看了什么",所以单个物品的 context 还不够,作者从一个局部窗口 $\mathcal{H}_n = \{a \mid \max(1, n - w + 1) \leq a \leq n\}$ 的 MM-scored item context 中聚合:
$$\boldsymbol{q}_{n,\ell}^T = \sum_{a \in \mathcal{H}_n} \pi_{a,\ell} \boldsymbol{s}_a^0, \quad \pi_{a,\ell} = \mathrm{softmax}_{a \in \mathcal{H}_n}\!\left( \frac{(\boldsymbol{W}_{Q,\ell}^P \boldsymbol{s}_n^0)^\top (\boldsymbol{W}_{K,\ell}^P \boldsymbol{s}_a^0)}{\sqrt{d}} \right) \tag{21}$$
这是一段 "transition-aware query"——以当前 $\boldsymbol{s}_n^0$ 为 attention query,聚合最近 $w$ 个物品的 summary 作为 context。
读出。
$$\boldsymbol{\eta}_{n,\ell}^T = \mathcal{R}_\ell\!\left(\boldsymbol{q}_{n,\ell}^T, \boldsymbol{p}_{n,\ell}^T\right) \tag{见正文 Eq. 6 共享}$$
实现细节(来自 Appendix B.2.2)。
- 第 $\ell$ 层 inter 模式的离散单元域是 $C^\ell$(一个 prefix 整体被编码成一个 unit)。
- 每层 base 16,缩放因子 $s_T$ 让 base 变成 $(16 s_T)^\ell$,例如默认 $s_T = 2.0$ 时三层 base 是 32 / 1024 / 32768。
- 默认 $K_T = 4$ 个哈希头,head dim $d_m/K_T = 64$。
- inter 阶集合 $\{O_1^T, O_2^T, O_3^T\} = (3, 2, 1)$——浅前缀允许更长的转移上下文(3-gram),深前缀只允许 1-gram。理由是浅层粗粒度的 category 漂移有更多可用统计,深层细粒度的物品-物品转移本身就稀疏。
3.4 Memory-conditioned Token Merge:层级门控融合¶
光把 memory 检索出来还不够——naive 地直接相加会"把所有 code embedding 一次性压扁,破坏 item identity 和 SID 结构"。所以作者设计了一个层级 gated residual,在每层 $\ell$ 选择性地接收 $\boldsymbol{\eta}_{n,\ell}^S$ 和 $\boldsymbol{\eta}_{n,\ell}^T$。
把两块 memory 在每层 stack 成 $\boldsymbol{u}_{n,\ell} = [\boldsymbol{\eta}_{n,\ell}^S; \boldsymbol{\eta}_{n,\ell}^T]$($\ell = 1$ 时 $\boldsymbol{\eta}_{n,1}^S = 0$,因为第一码没有 intra 模式),定义层级 summary 更新:
$$\omega_{n,\ell} = \sigma\!\left( \left( \boldsymbol{W}_Q^M \boldsymbol{s}_n^{\ell - 1} \right)^\top \left( \boldsymbol{W}_{K,\ell}^M \boldsymbol{u}_{n,\ell} \right) + b_\ell^M \right), \quad \boldsymbol{s}_n^\ell = \boldsymbol{s}_n^{\ell - 1} + \omega_{n,\ell} \boldsymbol{W}_{V,\ell}^M \boldsymbol{u}_{n,\ell} \tag{7}$$
$\omega_{n,\ell}$ 在 0 到 1 之间,相当于在询问"当前 summary $\boldsymbol{s}_n^{\ell - 1}$ 和 memory $\boldsymbol{u}_{n,\ell}$ 兼容吗?兼容就吸收"。最后 $L$ 层走完做一次 LayerNorm 得到 item-level 表示:
$$\boldsymbol{r}_n^I = \mathrm{LN}(\boldsymbol{s}_n^L), \quad \boldsymbol{R}^I = [\boldsymbol{r}_1^I, \ldots, \boldsymbol{r}_N^I]$$
注意 ComeIR 的序列长度直接从 $L \times N$ 压到 $N$,与 GenRec 的 Token Merging 同一级别;区别是 ComeIR 在压缩过程中沿途从两块 memory "买"了 SID 结构证据。
3.5 Memory-restoring Prediction Head:解码端把记忆"还回去"¶
至此输入侧已经是 item-level $\boldsymbol{R}^I$,但生成端依旧要逐 code 预测——典型的 Input-Output Granularity Mismatch。作者的关键 insight 是:Engram 是个静态查表,输入端用过的同一份 memory 在解码端可以再次复用,因为 hashing 是确定性的,只要重新用候选 code 拼出对应的离散模式,就能拿回 SID-token 级证据。
逐层 candidate-specific memory。 预测第 $\ell$ 位 code 时,已经生成的前缀是 $c_{N+1}^{\lt \ell}$,candidate code 是 $x$:
-
Intra-item evidence。若 $\ell = 1$,没有前缀,置 $\boldsymbol{\eta}_{N+1,1}^S(x) = 0$;若 $\ell \geq 2$: $$\boldsymbol{c}_{N+1}^{\leq \ell}(x) = (c_{N+1}^1, \ldots, c_{N+1}^{\ell - 1}, x), \quad \boldsymbol{\eta}_{N+1,\ell}^S(x) = \mathcal{R}_\ell\!\left( \zeta_\ell, \boldsymbol{c}_{N+1}^{\leq \ell}(x) \right) \tag{23}$$ 其中 $\zeta_\ell$ 是 architecture-specific decoder state(normal GR 中 $\zeta_\ell = \boldsymbol{h}_u$,NEZHA 中是 layer-specific state $\xi_\ell$)。
-
Inter-item evidence。把 candidate prefix 拼到历史前缀序列之后: $$C_+^{\leq \ell}(x) = [C^{\leq \ell}; \boldsymbol{c}_{N+1}^{\leq \ell}(x)], \quad \boldsymbol{p}_{N+1,\ell}^T(x) = \mathrm{Suffix}_{\tau_\ell}(C_+^{\leq \ell}(x), N+1) \tag{24}$$ $$\boldsymbol{\eta}_{N+1,\ell}^T(x) = \mathcal{R}_\ell\!\left( \boldsymbol{q}_{u,\ell}^D, \boldsymbol{p}_{N+1,\ell}^T(x) \right) \tag{26}$$ $\boldsymbol{q}_{u,\ell}^D$ 是 architecture-specific 的 decoding query(详见 Appendix Eq 25)。
Memory Fusion 与 candidate scoring。 第 $\ell$ 位预测的 memory term:
$$\mu_\ell(x) = \begin{cases} \boldsymbol{W}_{T,\ell} \boldsymbol{\eta}_{N+1,\ell}^T(x) & \ell = 1 \\ \boldsymbol{W}_{S,\ell} \boldsymbol{\eta}_{N+1,\ell}^S(x) + \boldsymbol{W}_{T,\ell} \boldsymbol{\eta}_{N+1,\ell}^T(x) & \ell \gt 1 \end{cases} \tag{8, 9, 27}$$
最终 logit 把"用户状态 $\boldsymbol{h}_u$ + candidate embedding $\boldsymbol{e}_x$ + memory $\mu_\ell(x)$"三路融合:
$$\boldsymbol{d}_\ell(x) = \mathrm{LN}\!\left( \boldsymbol{W}_{u,\ell} \boldsymbol{h}_u + \boldsymbol{W}_{C,\ell} \boldsymbol{e}_x + \mu_\ell(x) \right), \quad \psi_\ell(x) = \boldsymbol{w}_\ell^\top \boldsymbol{d}_\ell(x) \tag{10}$$
$$P\!\left(c_{N+1}^\ell = x \mid \boldsymbol{R}^I, c_{N+1}^{\lt \ell}; \Theta \right) = \frac{\exp(\psi_\ell(x))}{\sum_{y \in \mathcal{V}_\ell(c_{N+1}^{\lt \ell})} \exp(\psi_\ell(y))} \tag{11}$$
Catalog-valid prefix decoding。 在分母上用 $\mathcal{V}_\ell(c_{N+1}^{\lt \ell})$ 限制候选——它来自一棵由 catalog 中所有合法 SID 构成的 prefix tree。这保证 beam search 只走向真实存在的物品 SID,避免"幻觉 SID 组合"。当多个候选 SID 因碰撞映射到同一物品时,用最高分作为该物品的最终得分。
3.6 训练与推理¶
训练目标。 Teacher-forcing 下逐层 cross-entropy:
$$\mathcal{L}_{\text{rec}} = -\sum_{u \in \mathcal{U}} \sum_{\ell=1}^{L} \log P\!\left(c_{N+1}^\ell \mid \boldsymbol{R}^I, c_{N+1}^{\lt \ell}; \Theta \right) \tag{12}$$
每一层预测都在 valid prefix 下进行,迫使 prediction head 学会在 prefix-conditioned memory 证据下选下一码。
推理流程(Algorithm 2):
- 构造 $\boldsymbol{R}^I$(量化 → MM-scoring → Memory 读出 → Token Merge);
- 从 backbone 取 $\boldsymbol{h}_u$,按 prefix tree 做 beam search;
- 每个候选用同一套 Engram 重新读出 memory,按 Eq. (11) 算 token 级 logit;
- 累计 log-prob 排序,beam-width $B_{\text{beam}}$ 保留 top-K,最后映回 catalog item。
3.7 训练流程伪代码(Algorithm 1)¶
简要复述训练步骤以方便复现:
- 按 Eq. (2) 构造 SID-token embedding;
- MM-guided Token Scoring 得 $\boldsymbol{s}_n^0$;
- 按 Eq. (6) 读出 intra/inter memory $\boldsymbol{\eta}_{n,\ell}^S, \boldsymbol{\eta}_{n,\ell}^T$;
- 第 1 层 intra 置 0,从第 2 层起填实;
- 按 Eq. (7) 把 memory 融合进 item-level 输入 $\boldsymbol{R}^I$;
- backbone 编码(normal GR 直接喂 $\boldsymbol{R}^I$,NEZHA 在历史后追加 $L$ 个 placeholder token,编码后用 placeholder 隐状态作 layer-specific state $\xi_\ell$ 并配合 GRU 在 layer 间传播 ground-truth code 信息——Eq. 41, 42);
- 对每个 SID 层 $\ell$,用 ground-truth prefix $c_{N+1}^{\lt \ell}$ 取 candidate-specific memory,算 Eq. (11) 的 valid-prefix 概率;
- 优化 token-level CE Eq. (12)。
NEZHA 风格的 placeholder 机制额外让每个 SID 层有独立的 $\boldsymbol{h}_u^\ell$,并通过 GRU 把已生成 code 的信息累积进 recurrent state。这是为了缓解 normal GR 中所有 SID 层共享同一 $\boldsymbol{h}_u$ 的"信息冷冻"问题,但 ComeIR 的两种架构变体都按同一套 Memory-restoring Head 工作,只是 $\zeta_\ell$ 的提供方式不同。
4 实验设置¶
4.1 数据集¶
| 数据集 | # Users | # Items | Sparsity | Avg.length |
|---|---|---|---|---|
| Yelp | 15,720 | 11,383 | 99.89% | 12.23 |
| Amazon Industrial | 27,190 | 28,461 | 99.92% | 6.56 |
| Amazon Instrument | 40,644 | 30,676 | 99.97% | 8.01 |
预处理沿用 [13, 32] 的 sequential / generative retrieval 标准协议。注意 Yelp 是平均序列最长的(12.23)、稀疏度最低的,所以 memory scaling 实验也放在 Yelp 上做。
4.2 Baselines、Backbones 与架构¶
量化器:RQ-VAE [19]、RQ-KMeans [16]。 LLM Backbone:Qwen3-0.6B、LLaMA3-1B。 架构:Normal GR(单状态 $\boldsymbol{h}_u$)、NEZHA [39](layer-wise state,零牺牲解码)。 表征基线:
- Normal GR:flatten(直接拼接 $L \times N$ 个 token);
- +TM:Token Merging(GenRec [51] 的 naive 线性 merger);
- +ComeIR(本文)。
4.3 评估指标¶
- Hit Rate H@K($K \in \{5, 10\}$):是否命中真实 next item;
- NDCG@K(N@K):排序质量;
- Latency LT(毫秒/batch):推理延迟,batch=32、beam=20。
4.4 超参数¶
- SID 长度 $L = 3$,每层 codebook size $C = 128$(共三层 $128^3 \approx 2.1M$ 个理论 SID);
- Intra base 128(每层),inter base 16,缩放因子 $s_S = 1.0, s_T = 2.0$(默认);
- $H_{\max} = 20{,}000{,}000$ 是每张 hash table 的 bucket 数上限;
- $d_m = 256$,$K_S = 2$ 头(head dim 128),$K_T = 4$ 头(head dim 64);
- 训练:bfloat16,lr $1 \times 10^{-5}$,weight decay $1 \times 10^{-4}$,per-device batch 64,grad accum 2,max steps 100,000,每 100 步评估,三个 seed (42, 43, 44) 取均值;
- 硬件:AMD EPYC 9745 + 2× NVIDIA RTX PRO 6000 (Blackwell, 96GB)。
5 主要实验结果¶
5.1 总体效果(Table 1)¶
ComeIR 在所有 (量化器, 主干, 架构) 组合下都显著超过 Flatten 和 +TM。以 Qwen3-0.6B + RQ-VAE 为例(Normal GR 行):
| Dataset | Method | H@5 | H@10 | N@5 | N@10 |
|---|---|---|---|---|---|
| Yelp | Normal GR | 0.0296 | 0.0474 | 0.0181 | 0.0243 |
| Yelp | + TM | 0.0292 | 0.0470 | 0.0177 | 0.0239 |
| Yelp | + ComeIR | 0.0305 | 0.0524 | 0.0198 | 0.0266 |
| Industrial | Normal GR | 0.0979 | 0.1275 | 0.0745 | 0.0844 |
| Industrial | + TM | 0.0976 | 0.1271 | 0.0742 | 0.0841 |
| Industrial | + ComeIR | 0.1031 | 0.1321 | 0.0792 | 0.0883 |
| Instrument | Normal GR | 0.0804 | 0.0982 | 0.0688 | 0.0735 |
| Instrument | + TM | 0.0788 | 0.0966 | 0.0672 | 0.0719 |
| Instrument | + ComeIR | 0.0834 | 0.1021 | 0.0709 | 0.0772 |
关键观察:
- +TM 通常略弱于 Flatten:例如 Yelp + RQ-VAE + Normal GR 上 H@5 从 0.0296 跌到 0.0292,Instrument 从 0.0804 跌到 0.0788。说明单纯把 SID embedding 线性压平会丢失结构证据——这就是作者要重点解决的 Identity-Structure Preservation Conflict 的实证版本。
- +ComeIR 同时取得长度压缩和效果提升:在和 +TM 同样的序列长度($N$ 而非 $L \times N$)下,ComeIR 比 Flatten 还要好 3%–6%。
- 不同 backbone 增益比例不同:Qwen3-0.6B 上平均 H@5 提升 8.06%,LLaMA3-1B 上 7.91%(按文中 "8.06% for Qwen3-0.6B and 7.91% for LLaMA3-1B" 报告);增益在 Yelp 这种小数据集上最显著(更小的 memory table 也能撑起更多统计量)。
- 量化器无关:RQ-VAE 和 RQ-KMeans 上 ComeIR 提升幅度类似,验证 plug-and-play 性。
- 架构无关:Normal GR 和 NEZHA 上都能获得稳定增益,说明 ComeIR 对 decoding 端的耦合很弱。
LLaMA3-1B 的绝对指标普遍低于 Qwen3-0.6B(H@5 ~0.022 vs 0.030 on Yelp),这一现象有点反直觉——更大的主干本应更强。可能解释是 LLaMA3-1B 没经过 SID 词表预训练,相比 Qwen3 在中文/小词表上更陌生;这也间接说明 ComeIR 的增益与主干预训练分布解耦。
5.2 消融实验(Table 2, 5, 6)¶
Yelp 上的消融(Table 2,Qwen3-0.6B + RQ-VAE):
| Variant | H@5 | H@10 | N@5 | N@10 |
|---|---|---|---|---|
| ComeIR | 0.0305 | 0.0524 | 0.0198 | 0.0266 |
| w/o MM-scoring | 0.0294 | 0.0517 | 0.0190 | 0.0254 |
| w/o D-intra | 0.0294 | 0.0501 | 0.0193 | 0.0257 |
| w/o D-inter | 0.0291 | 0.0505 | 0.0188 | 0.0251 |
| w/o Mem. Merge | 0.0298 | 0.0512 | 0.0193 | 0.0259 |
| w/o E-intra | 0.0297 | 0.0509 | 0.0194 | 0.0244 |
| w/o E-inter | 0.0293 | 0.0516 | 0.0185 | 0.0249 |
逐项分析:
- w/o MM-scoring:H@5 ↓ 3.61%,N@5 ↓ 4.04%。验证不同 code 对 item identity 的贡献是不均匀的,naive 平均会稀释关键码。
- w/o D-intra / D-inter:分别 ↓ 3.38% / 5.64%(N@10)。这两个是移除 decoding 端的 memory 复用,相当于把 Memory-restoring Prediction Head 关掉,只在 encoding 端用 memory。inter 比 intra 更关键,说明 token-level 解码时 inter-item 转移证据最不可缺。
- w/o Mem. Merge:把 Memory-conditioned Token Merge 换成简单线性层。下降幅度小于 D-intra/D-inter——也就是说"encoding 端注入 memory"和"decoding 端复用 memory"两者中,decoding 端复用对效果更重要。
- w/o E-intra / E-inter:移除 encoding 端的 intra/inter memory,分别 ↓ 2.62% / 3.93%(H@5)。
整体结论:encoding 端的 memory 注入和 decoding 端的 memory 复用是两条独立的、不可互相替代的贡献通道,前者重在"item 表征 informative",后者重在"token 级解码有 SID 证据"。这正好对应 1.3 节提出的两个痛点:identity-structure 冲突由 encoding 端 (MM-scoring + Mem. Merge + E-intra/inter) 负责,输入-输出粒度错配由 decoding 端 (D-intra/inter) 负责。Instrument 和 Industrial 上的消融(Table 5, 6)给出一致的方向——D-intra 下降 ~2-3%,D-inter 下降 ~5%。
5.3 Scaling 分析(Figure 3, Appendix C.2)¶
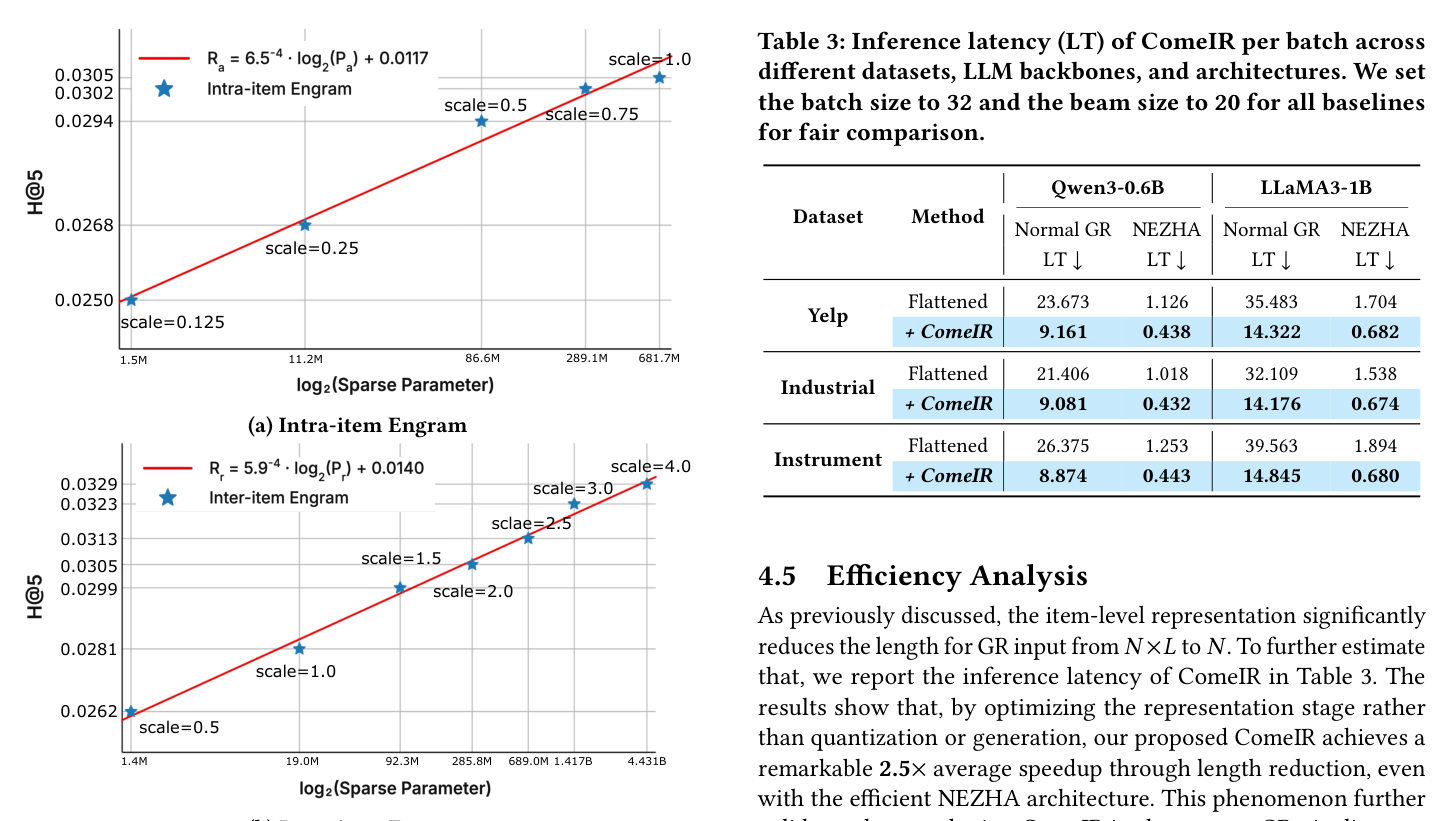
把 intra/inter memory 容量分别放大或缩小,固定另一个为默认值:
- Intra:拟合 $R_e = 6.5^{-4} \cdot \log_2(P_S) + 0.0117$。$s_S \in \{0.125, 0.25, 0.5, 0.75, 1.0\}$ 对应稀疏参数 1.5M–681.7M,H@5 从 0.0250 增到 0.0305 后饱和——因为单 SID 内的 code 组合空间被 $C^L = 128^3 \approx 2.1M$ 限死,到一定容量后多余 bucket 都"闲置"。
- Inter:拟合 $R_e = 5.9^{-4} \cdot \log_2(P_T) + 0.0140$。$s_T \in \{0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0\}$ 对应稀疏参数 1.4M–4.43B,H@5 从 0.0262 单调升到 0.0329。
关键结论:
- Inter 比 Intra 更"scalable":inter 的 pattern 空间 $C^{L \cdot \tau_\ell}$ 远大于 intra 的 $C^L$,所以 inter table 即便扩到 4.43B sparse 参数还在拿增益——已经远超 Qwen3-0.6B 主干本身。
- 过度扩容反伤效果:当 $s_T \geq 5.0$ 时 H@5 反而下降。原因是 sparse over-allocation——bucket 太多导致绝大多数槽位训练样本太少、梯度不稳定。这与 Engram 原论文 [6] 报告的 U 型 sparsity-allocation 现象一致。
- 稀疏参数远比主干参数高效:4.43B inter 参数和 4.43B 稠密参数完全不可比——sparse table 每次只激活极少数 bucket,FLOPs 和 latency 影响微乎其微,但每个 bucket 都直接对应一种 SID 模式,可以理解成"非参数化记忆"。
5.4 推理效率(Table 3)¶
| Dataset | Method | Qwen3-0.6B Normal GR LT | Qwen3-0.6B NEZHA LT | LLaMA3-1B Normal GR LT | LLaMA3-1B NEZHA LT |
|---|---|---|---|---|---|
| Yelp | Flatten | 23.673 | 1.126 | 35.483 | 1.704 |
| Yelp | + ComeIR | 9.161 | 0.438 | 14.322 | 0.682 |
| Industrial | Flatten | 21.406 | 1.018 | 32.109 | 1.538 |
| Industrial | + ComeIR | 9.081 | 0.432 | 14.176 | 0.674 |
| Instrument | Flatten | 26.375 | 1.253 | 39.563 | 1.894 |
| Instrument | + ComeIR | 8.874 | 0.443 | 14.845 | 0.680 |
平均 2.5× 速度提升,不论是 Normal GR(约 60% 延迟下降)还是 NEZHA(约 60% 延迟下降)都成立。原因很直接:item-level 输入把长度从 $L \times N$ 压到 $N$,prefill 阶段 attention 复杂度从 $O((LN)^2)$ 降到 $O(N^2)$,对 $L = 3$ 来说理论加速 9×,实际由于 memory lookup 和 head 计算的少量开销,达到 ~2.5–3×。
值得注意:ComeIR 是 GR 流水线里第一次把"效果提升"和"延迟下降"在表征构造阶段同时拿到。GenRec 的 TM 也压缩了输入但效果略降;Flatten 不压缩;ComeIR 既压缩又靠 memory 把损失补回来还要多。
6 核心贡献总结¶
- 首次将 representation construction 标记为 GR 流水线的关键瓶颈,明确两个痛点:Identity-Structure Preservation Conflict、Input-Output Granularity Mismatch。
- 首次把 Engram 静态稀疏记忆从 Transformer 内部搬到表征构造接口:用 dual-level(intra-item 码组合 / inter-item 前缀转移)建模 SID 自带的两类离散结构,作为 SID-token embedding 之上的"非参数记忆"。
- MM-guided Token Scoring:复用 quantizer 已经用过的多模态 embedding 作 identity query,零额外信息源;
- Memory-restoring Prediction Head:在解码端复用同一套 memory,直接把 token-level SID 证据"还给"逐 code 预测,从源头解决输入-输出粒度错配。
- Plug-and-play:跨 RQ-VAE/RQ-KMeans、Qwen3/LLaMA3、Normal GR/NEZHA 全部稳定生效,三个公开数据集 H@5 平均 +8% 同时推理速度 +2.5×。
7 与已归档相关工作的对比¶
GenRec GenRec: A Preference-Oriented Generative Framework (JD.com, 2026-04-16)¶
关系:显式引用为基线 TM;原文 Table 1 已通过 "+TM" 行充分对比 · 未加载对方精读
ComeIR 在 Table 1 的所有行里都把 "+TM"(GenRec 的 Token Merger)当作直接对照,并在 §1.2 / §5.1 强调"naive 线性 merge 会丢失 SID 结构"。GenRec 的 TM 是 ComeIR 这一类 item-level constructor 的最 minimal 实现——只有一层 $\mathrm{Linear}(\mathrm{Concat}([\boldsymbol{e}(s^1); \ldots; \boldsymbol{e}(s^L)]))$,没有 identity query、没有 memory、没有 decoding 端复用。
两者的方法骨架完全不同:
- GenRec 的 TM:非对称设计(输入压缩、输出不动),目的是为了降 prefill 延迟,效果方面与 Flatten 持平甚至略降(消融显示 HR@10 从 0.4467 降到 0.4456)。
- ComeIR:同样压缩到 item-level,但加上 dual-level Engram 主动"补回"SID 结构,外加 Memory-restoring Head 在 decoding 端反向把记忆复用回去——同时拿到了延迟下降 + 效果提升。
直接可比的数据点(Yelp + Qwen3-0.6B + RQ-VAE + Normal GR):H@5 / N@10 上 Normal GR = 0.0296 / 0.0243,+TM = 0.0292 / 0.0239(略降),+ComeIR = 0.0305 / 0.0266(双升)。GenRec 把 TM 作为效果中性的延迟优化,ComeIR 揭示了"原来的延迟优化其实丢了东西,把丢的东西显式建模就能既快又好"。这是一个非常干净的"先发现 baseline 的隐性 trade-off,再设计一个去 trade-off 的新方法"叙事。
8 讨论与局限性¶
核心 insight:GR 流水线被普遍当作"量化 → 生成"的两段式,但作者把中间的 representation construction 明确为第三段独立段,并展示它本身就是一个独立的 design space——量化已经做完、生成端不动的前提下,只改这一段就能拿到 +8% 同时 ×2.5 加速。这种"找到一个被忽视的 design layer"的工作通常具有较高的可复制价值。
Engram 的迁移:Engram 原本是 LLM 内部的 token-level 静态 memory(Pei et al. 2026 [6]),ComeIR 是首次把它外置到 representation 接口,并按 SID 的两种自然结构(intra-item / inter-item)做实例化。这条迁移路径意味着 Engram 不止是 transformer block 内部的工具,任何"输入是离散模式、希望长期记忆某种 N-gram 统计"的场景都可能用类似设计——例如多模态推荐里的 cross-modal token 模式、生成式广告里的 bid-token 模式等。
值得借鉴的设计点:
- 解码端复用同一套 memory:Memory-restoring Prediction Head 是非常优雅的 mismatch 桥——既然 memory 是确定性哈希查表,输入用过的 entry 在输出端依然可达,免去训练两个独立 memory 的成本。
- 不引入新信息源:MM-scoring 直接复用 quantizer 已经计算的 $\boldsymbol{m}_n$,这种"挂回旁路信号"的做法比"再训一个额外 encoder"更工业友好。
- 架构无关性:不论 Normal GR 还是 NEZHA、不论 Qwen3 还是 LLaMA3,ComeIR 都能稳定地以 plug-and-play 形式增益——这意味着它可以叠加到 GenRec、OneRec-Think、LASAR 等已有工作上而不冲突。
局限性与争议:
- 数据规模有限:三个公开数据集(Yelp / Amazon Industrial / Instrument)的物品数都在 1-3 万量级,与工业 catalog 的 $\sim 10^8 - 10^9$ 差很多。在大规模 catalog 上,每层 SID codebook 会更深,intra/inter 模式空间膨胀,Engram 的 bucket 分配策略(特别是 prime hashing)能否保持线性 scaling 还是 open question。
- 没有在线 A/B:与 GenRec/UxSID/GR4AD 等工业论文不同,ComeIR 只报了三个学术数据集结果。real-world 流量下的稳定性、冷启动表现、负样本曝光等都未验证。
- Inter Engram 容量过大的 U 型问题没有给解决方案:作者注意到 $s_T \geq 5$ 时 H@5 反伤,但没有给"如何在大 catalog 下选最优 $s_T$"的实用指南,部署时需要逐场景调参。
- Memory-restoring Head 增加了每 candidate 的额外 lookup:beam search 每步对每个候选都要重新做 dual memory 读出,理论上 candidate-level latency 会被放大。文中 Table 3 报告的端到端 latency 仍 ×2.5 优于 flatten,说明哈希查表本身极轻,但对 beam-width 极大(>100)的场景需要进一步评估。
- 未来方向:能否把"static memory"扩展为"adaptive memory"(例如 RL 阶段在线更新 hash entry),是否能用 Engram 把更高阶语义(用户群体、跨 session 偏好)也挂上来——这些都是论文埋下的延伸。