DADF: A Distribution-Aware Debiasing Framework for Watch-Time Regression in Recommender Systems¶
1. 研究动机与背景¶
1.1 任务设定与场景¶
在短视频推荐系统中,watch-time(观看时长) 是衡量用户兴趣的核心连续型反馈信号。相对于点击、点赞这类二值信号,watch-time 提供更细粒度的"消费深度"度量,能反映用户在短期内的注意力分配以及长期留存倾向。因此在工业排序系统中,watch-time 预测既被用于离线回归质量的衡量,也直接影响在线曝光分配与下游排序(如多目标融合公式中的 watch-time 项)。
然而 watch-time 这个目标存在两个结构性难题:
- 标签长尾且多模态:绝大部分曝光对应短观看 / 快速划走,只有很小一部分对应深度消费。整体分布既长尾(heavy-tailed)又多峰(multi-modal)。
- 首阶段预测器的局部校准偏差(local calibration bias):在这种分布下,模型可以在 全局聚合层面 看起来"标定良好"(observed/predicted ratio ≈ 1.0),但同时在不同 watch-time 区间内系统性地高估短观看、低估长观看——这两类相反方向的误差在聚合统计中互相抵消。论文将这一现象命名为 pseudo-balance(伪标定)。
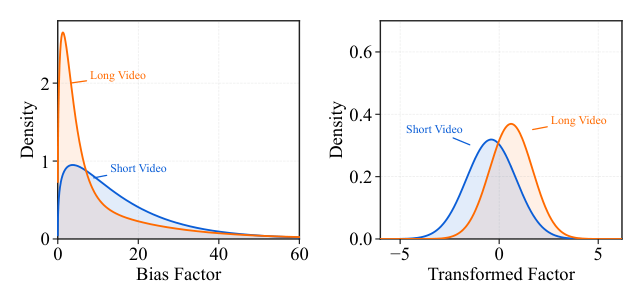
Figure 1(a) 直接展示了这一现象:横轴是按观察到的 watch-time 分桶,纵轴是平均 watch-time,蓝色(observed)和绿色(predicted)两条曲线在低 watch-time 桶(短视频)位置预测值高于观测值(高估),而在高 watch-time 桶位置则系统性低估,宏观聚合掩盖了局部错配。
1.2 现有方法的局限¶
文献中有两条主线尝试解决 watch-time 偏差:
- 第一条线 —— 改进首阶段预测器:包括离散化方法(TPM [19]、CREAD [35])、duration-aware 方法(D2Q [47]、D2CO [49])、以及分布建模方法(EGMN [50])。但它们都需要替换部署的预测器,工业系统中替换首阶段模型通常意味着大量工程改造和在线验证成本。
- 第二条线 —— 事后修正(post-hoc correction):以 TranSUN [46] 为最近代表,在变换空间中学一个全局乘性校正因子。但 TranSUN 对所有样本应用同一个全局变换 / 同一个全局校正函数,无法刻画 不同 debias-factor regime(不同 duration 段) 下显著不同的残差分布。
1.3 本文的研究问题¶
论文聚焦的实际场景是:首阶段 watch-time 预测器已经训练好并部署在线,不可替换;目标是在其上学一个 轻量的、即插即用的二阶残差修正模块,专门去除"伪标定"留下来的系统性局部偏差。具体技术挑战有三:
- 直接对乘性校正因子 $b = y / \hat{y}_0$ 做回归不稳定——这个比值本身继承了 $y$ 的长尾特性(论文在附录 A.1 中给出了严格证明);
- 不同 video duration 段下,残差分布的偏度(skewness)、方差、模式都不同,单一全局变换无法适配;
- 推理时观测不到 $y$,只能依赖推理时可见的特征(duration、首阶段输出 $\hat{y}_0$、辅助任务 logits 等)来估计校正因子。
2. 核心方法:DADF 框架¶
2.1 整体架构¶
DADF(Distribution-Aware Debiasing Framework)保持首阶段预测器 $\hat{y}_0$ 冻结不变,在其后接一个二阶校正网络,由三个互补模块构成:
- Dynamic Distribution-aware Module:把长尾的乘性校正标签通过 group-specific Box–Cox 变换映射到一个更紧凑、更接近对称的目标空间,让回归学习更稳定;
- Debias-Factor-aware Module:按 video duration 把样本划分为 $K$ 个 debias-factor 组(duration group),每组训练一个独立的专家网络(hard routing),刻画不同 regime 下的残差分布;
- Multi-label-aware Module:复用首阶段 engagement 辅助任务头(completion、effective-view、long-view、negative-feedback 等)的 logits 和 tower 表征作为推理时可见的语义信号,丰富校正网络的输入特征。
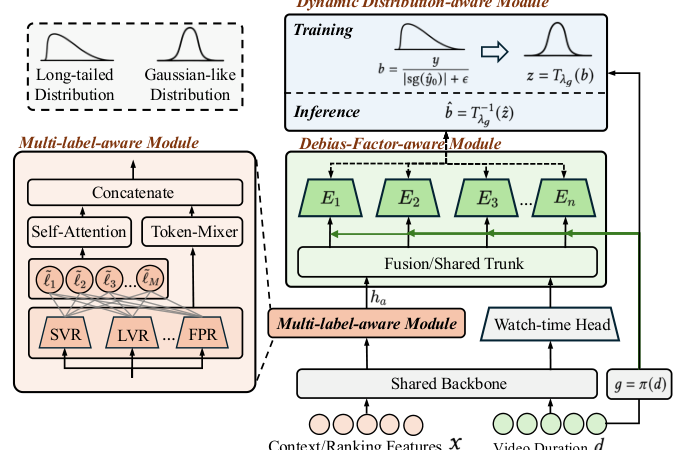
最终推理时 DADF 给出修正后的 watch-time 预测:
$$ \hat{y} = \hat{y}_0 \cdot \hat{b}, \quad \hat{b} = T^{-1}_{\lambda_{\pi(d)}}\left( F_\theta(x, \ell_0, \pi(d), h_a) \right) \tag{1} $$
其中 $\hat{y}_0$ 是首阶段冻结预测,$\hat{b}$ 是预测出的乘性校正因子,$T^{-1}_{\lambda_g}$ 是对应 duration group $g = \pi(d)$ 的逆 Box–Cox 变换。
2.2 问题形式化¶
对于每条曝光样本,记:
- $\hat{y}_0 \in \mathbb{R}_+$:首阶段冻结预测;
- $y \in \mathbb{R}_+$:真实 watch-time(训练时可见);
- $s = (x, d, \ell_0, a)$:推理时可见信号,包含排序特征 $x$、video duration $d$、首阶段原始 watch-time 输出 $\ell_0$(最后输出映射前的 logit)、来自相关 engagement 头的辅助表征 $a$。
目标是学一个校正函数 $c_\theta(s) \in \mathbb{R}_+$,得到:
$$ \hat{b} = c_\theta(s), \quad \hat{y} = \hat{y}_0 \cdot \hat{b} \tag{2} $$
训练时的乘性校正标签定义为:
$$ b = \frac{y}{\operatorname{sg}(\hat{y}_0) + \epsilon} \tag{3} $$
其中 $\operatorname{sg}(\cdot)$ 是 stop-gradient(保证不会反传到首阶段),$\epsilon \gt 0$ 防止 $\hat{y}_0$ 接近 0 时数值不稳。这种"训练时知道 $y$ 因此能造出 ratio 标签,推理时只能用 $s$ 估计 ratio"的设定就是 TranSUN 范式的核心。
2.3 Dynamic Distribution-aware Module(动态分布感知模块)¶
2.3.1 为什么需要变换¶
附录 A.1 给出的"长尾继承"定理大意是:当真实 watch-time 的条件生存函数属于长尾族 $\mathcal{L}$(满足 $\lim_{t \to \infty} \bar{F}_{Y|X}(t+a|x)/\bar{F}_{Y|X}(t|x) = 1$ 对任意 $a$)时,比值型校正因子 $R = Y / g(X)$ 在条件 $X=x$ 下也继承同样的长尾性质(其中 $g(x)$ 是 stopped-gradient 的首阶段预测)。这意味着即使首阶段预测器接近无偏,乘性校正因子依然保有右偏、重尾的结构 —— 直接对它做回归会受到极值主导,优化不稳定。
Figure 6(附录)经验性地展示了 Kwai 上 8 个 duration 桶里原始乘性校正因子的密度:所有桶都呈现强烈的右偏、长尾、绝大多数样本挤在小值附近、一小撮极值拖出长尾。这正是为什么需要变换。
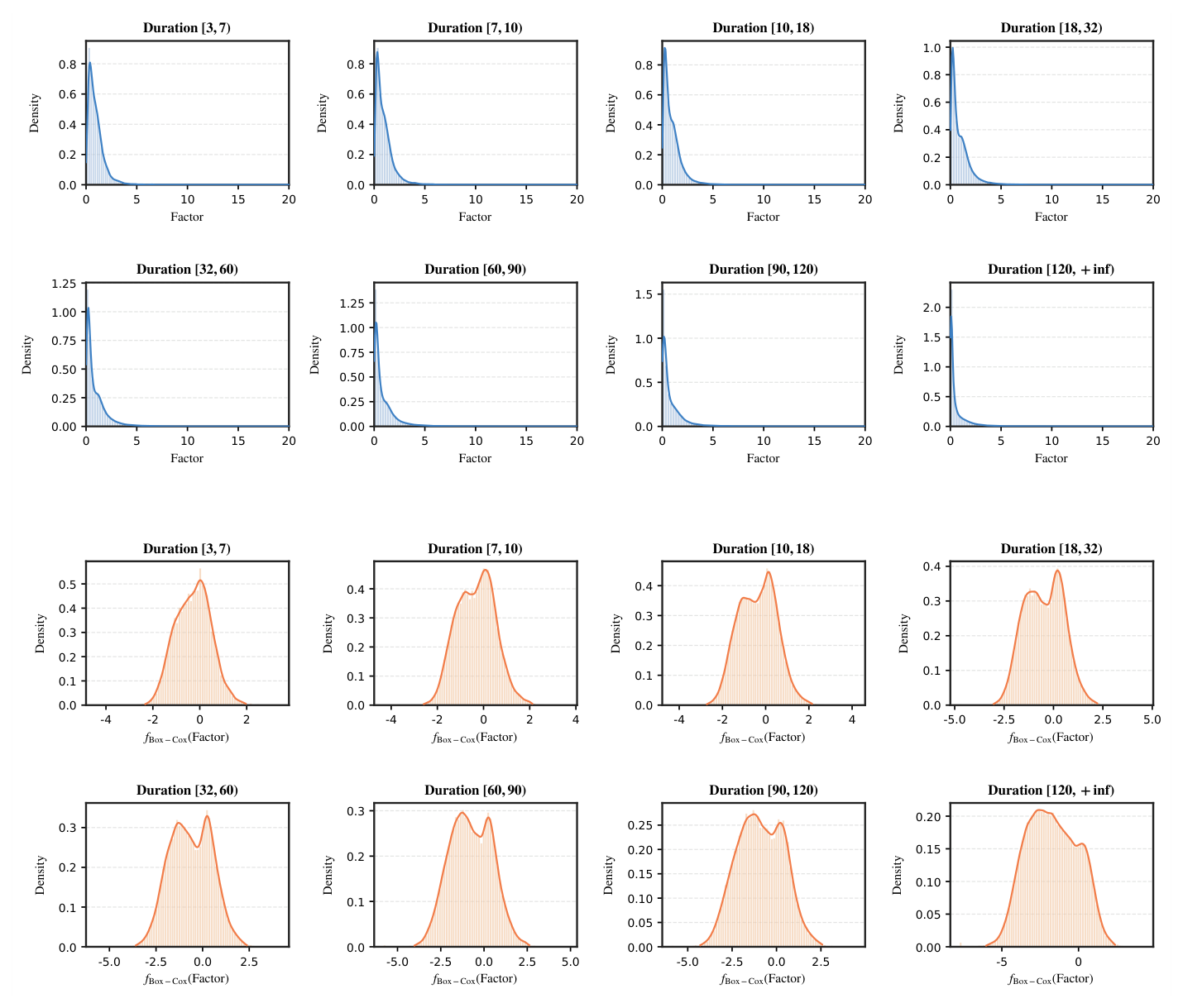
变换后(图的下半部分),每个 duration 桶的目标分布都变得更紧凑、接近对称——但变换参数本身需要跨桶不同。
2.3.2 Group-specific Box–Cox 变换¶
DADF 用 video duration 把样本分到 duration group $g = \pi(d)$($\pi$ 是分桶函数)。每组学一个独立的 Box–Cox 风格变换:
$$ T_{\lambda_g}(b) = \begin{cases} \dfrac{(b + \epsilon)^{\lambda_g} - 1}{\lambda_g}, & \lambda_g \neq 0 \\[4pt] \log(b + \epsilon), & \lambda_g = 0 \end{cases} \tag{4} $$
其中 $\epsilon$ 是小的正数保证数值稳定,$\lambda_g$ 是 group-specific 的可学习参数,与校正网络联合优化。
预测时的逆变换是:
$$ T^{-1}_{\lambda_g}(z) = \begin{cases} (\lambda_g z + 1)^{1/\lambda_g} - \epsilon, & \lambda_g \neq 0 \\[4pt] \exp(z) - \epsilon, & \lambda_g = 0 \end{cases} \tag{5} $$
这一变换的两个关键性质:
- 整体把右偏重尾分布拉成接近对称的紧凑分布,让回归优化更稳定;
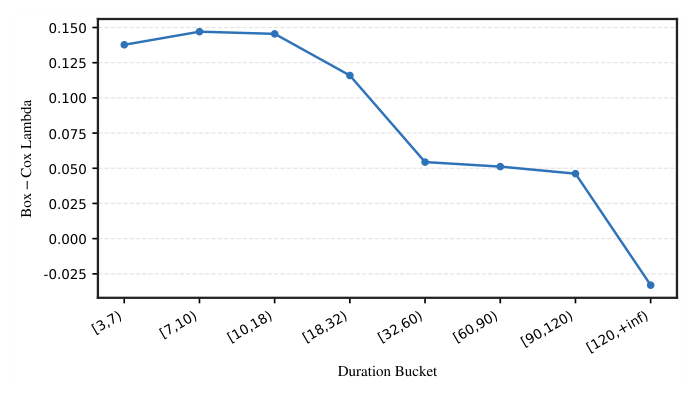
- 每个 duration group 一个 $\lambda_g$,自适应不同 regime 下的偏度强度。Figure 7(附录)展示了 Kwai 上学到的 $\lambda_g$:随 duration 增长整体下降,最长 duration 桶甚至落到 0 以下,说明 一刀切的全局 Box–Cox 不够,必须 group-specific。
2.4 Debias-Factor-aware Module(debias-factor 感知模块)¶
2.4.1 融合层¶
在 duration-adaptive 的变换空间里,DADF 通过融合网络把推理时可见信号拼成校正预测的统一表征:
$$ h = \operatorname{Fusion}(x, \ell_0, h_a) \tag{6} $$
其中 $x$ 是排序特征,$\ell_0$ 是首阶段原始 watch-time 输出,$h_a$ 是来自 Multi-label-aware 模块(见 §2.5)的辅助行为表征。$\operatorname{Fusion}(\cdot)$ 是可学的特征融合网络。
2.4.2 Oracle-Risk 理由:为什么按 duration group 切分¶
论文用一个 group-conditioned oracle risk 分析(附录 A.2)来说明 duration grouping 的合理性。设 $U$ 是要学习的校正目标,$G$ 是 duration group 变量,由全方差分解:
$$ \operatorname{Var}(U) = \mathbb{E}[\operatorname{Var}(U \mid G)] + \operatorname{Var}(\mathbb{E}[U \mid G]) \tag{7} $$
因此在平方损失下,按 group 条件化后的 oracle optimal risk 满足:
$$ \mathcal{R}_G^\star = \mathbb{E}[\operatorname{Var}(U \mid G)] \le \operatorname{Var}(U) = \mathcal{R}_0^\star \tag{8} $$
含义:只要 duration group 能捕捉到任何 group-wise 条件均值的差异(也就是 $\operatorname{Var}(\mathbb{E}[U|G]) \gt 0$),按 group 条件化的预测器在 oracle 意义上一定优于不区分 group 的全局预测器。这就为"按 duration 引专家分支"提供了一个紧的不增风险论证。
2.4.3 Hard Routing 与专家网络¶
DADF 采用 hard routing:每个样本根据其 duration group $g$ 选择对应专家 $E_g$,专家给出变换空间下的预测:
$$ \hat{z} = E_g(h) \tag{9} $$
每个专家专注于自己 group 的残差分布,避免不同 regime 强制共享一个校正函数带来的 cross-group 干扰。
2.5 Multi-label-aware Module(多标签感知模块)¶
2.5.1 动机:复用首阶段 engagement 头¶
工业首阶段排序模型常常是多任务的:除了 watch-time 头之外还有 completion、effective-view、long-view、negative-feedback、thresholded watch labels 等若干 engagement 头。这些辅助头的 观测标签 在推理时不可见(和 watch-time 一样),但它们的 logits 和 tower 表征 在推理时是可用的。DADF 利用这些来给残差修正提供额外的语义信号。
2.5.2 三个分支¶
模块构造三条信息支路:
- Branch 1 — playtime-related auxiliary 与公共排序特征联合:
$$ h_c = \operatorname{MLP}([\ell_{\text{play}}, x_c]) \tag{10} $$
其中 $\ell_{\text{play}}$ 是 playtime 相关辅助任务的 logit(区别于原始 watch-time 输出 $\ell_0$),$x_c$ 是首阶段辅助头共享的公共特征表示。
- Branch 2 — 跨任务 logit 自注意力:先用 task-specific 非线性投影避免量纲差异:
$$ \tilde{\ell}_m = \Phi_m(\ell_m), \quad m = 1, \ldots, M \tag{11} $$
其中 $\ell_m$ 是第 $m$ 个辅助任务的 logit,$\Phi_m$ 是 task-specific 投影。投影后的 logits 输入到 self-attention 建模跨任务相关性:
$$ h_t = \operatorname{SelfAttention}(\tilde{\ell}_1, \tilde{\ell}_2, \ldots, \tilde{\ell}_M) \tag{12} $$
- Branch 3 — Tower 表征作为语义 token:把每个辅助任务的 tower 表征 $r_m$ 当作语义 token 输入 TokenMixer:
$$ h_r = \operatorname{TokenMixer}(r_1, r_2, \ldots, r_M) \tag{13} $$
Tower 表征保留了 logits 之外更丰富的中间语义。
三条支路最后拼接经 MLP 得到多标签感知表征:
$$ h_a = \operatorname{MLP}([h_c, h_t, h_r]) \tag{14} $$
$h_a$ 喂给 §2.4 的 Debias-Factor-aware 模块作为辅助行为信息。论文强调"显式同时利用 logits 和 tower 表征"比只用单独的辅助 logits 信号更鲁棒,特别是在 engagement 反馈稀疏时。
2.6 训练目标¶
首阶段 $\hat{y}_0$ 冻结后,DADF 在变换空间和原始 watch-time 空间同时优化二阶校正模块。给定样本属于 duration group $g = \pi(d)$,校正网络在变换空间预测:
$$ \hat{z} = F_\theta(x, \ell_0, g, h_a) \tag{15} $$
预测的变换空间校正经逆变换映射到乘性因子空间:
$$ \hat{b} = T^{-1}_{\lambda_g}(\hat{z}), \quad \hat{y} = \hat{y}_0 \cdot \hat{b} \tag{16} $$
主监督施加在 变换空间:
$$ \mathcal{L}_{\text{trans}} = \ell(z, \hat{z}) \tag{17} $$
其中 $z = T_{\lambda_g}(b)$ 是 group-specific 变换后的校正标签,$\ell(\cdot, \cdot)$ 是回归损失(如 MSE)。变换空间损失能让学习集中在更紧凑、长尾性更弱的空间。
为了对齐原始 watch-time 目标,引入 absolute-space Huber 损失:
$$ \mathcal{L}_{\text{abs}} = \ell_{\text{Huber}}(y, \hat{y}) \tag{18} $$
它直接约束了"经过逆变换 + 乘性修正后"的最终预测。
Group 内分布稳定化正则¶
为了进一步稳定变换空间,DADF 对每个 duration group 内变换后目标的 mini-batch 矩做正则:
$$ \mathcal{L}_{\text{reg}} = \frac{1}{|\mathcal{G}|} \sum_{g \in \mathcal{G}} \left( w_\mu \mu_g^2 + w_\sigma (\sigma_g^2 - 1)^2 + w_s |\operatorname{Skew}_g| \right) \tag{19} $$
其中 $\mu_g, \sigma_g^2, \operatorname{Skew}_g$ 分别是 group $g$ 内变换标签 $z = T_{\lambda_g}(b)$ 的 mini-batch 均值、方差、偏度;$w_\mu, w_\sigma, w_s$ 是对应权重。这个正则鼓励每组变换标签居中、归一化、低偏度,避免不稳定的矩估计,并间接约束 $\lambda_g$ 朝合理方向移动。样本数不足的 group 会被 mask 掉避免噪声估计。
最终损失:
$$ \mathcal{L}_{\text{DADF}} = \alpha \mathcal{L}_{\text{trans}} + \beta \mathcal{L}_{\text{abs}} + \eta \mathcal{L}_{\text{reg}} \tag{20} $$
推理时不依赖任何观测标签或训练专用项,给定 $\hat{y}_0$ 和 $x, d, \ell_0, h_a$,输出最终修正预测:
$$ \hat{y} = \hat{y}_0 \cdot T^{-1}_{\lambda_{\pi(d)}}\left( F_\theta(x, \ell_0, \pi(d), h_a) \right) \tag{21} $$
3. 实验设置¶
3.1 数据集¶
- KuaiRec [12]:Kuaishou 公开数据集,"完全观察"密集交互(用户-视频矩阵接近全密集),12,530,806 条曝光、7,176 用户、10,728 视频。适合在 降低曝光选择偏差 的前提下评估 watch-time 预测。
- WeChat21:WeChat Big Data Challenge 2021 数据集,7,310,108 条交互、20,000 用户、96,418 视频。相对 KuaiRec 更大更稀疏,用于测试 DADF 在长尾稀疏条件下的鲁棒性。
3.2 Baselines¶
两类基线 7 个:
首阶段 watch-time 预测器(i):
- VR:直接 pointwise 回归预测 watch-time;
- WLR [8]:weighted logistic regression,YouTube 风格,把 watch-time 作为正样本权重;
- TPM [19]:tree-based progressive regression;
- D2Q [47]:duration-aware debiasing,在 duration-aware treatment 下做反事实 watch-time;
- CREAD [35]:classification-restoration framework,离散化 + 还原;
- D²CO [49]:从有偏带噪 watch-time 中学习用户兴趣;
- EGMN [50]:exponential-Gaussian mixture network 建模 watch-time 分布。
二阶乘性校正基线(ii):
- TranSUN [46]:单一全局乘性校正应用到变换回归输出之上。
对每个 backbone,DADF 都给出"backbone itself / backbone + TranSUN / backbone + DADF"三组实验,控制变量。
3.3 指标¶
- MAE:pointwise 回归绝对误差,越低越好。
$$ \operatorname{MAE} = \frac{1}{N}\sum_{i=1}^{N} |\hat{y}_i - y_i| \tag{22} $$
- XAUC [47]:基于成对比较的排序一致性,越高越好。
$$ \operatorname{XAUC} = \frac{1}{|\Omega|} \sum_{(i,j) \in \Omega} \mathbf{1}[(\hat{y}_i - \hat{y}_j)(y_i - y_j) \gt 0] \tag{23} $$
其中 $\Omega = \{(i,j) : y_i \neq y_j\}$ 是可比样本对集合。
线上 Kwai 实验同时报告 watch-time、video plays、retention、completion 等多种 user-level engagement 指标。
3.4 实现细节¶
- 训练/验证/测试 8:1:1 随机切分;
- 所有 backbone 用同一套特征预处理与可比模型容量(16-d 稀疏 embedding,MLP 隐藏 256/128/64);
- backbone 训完后冻结,二阶模块共享 backbone 预测,仅二阶模块是 backbone-DADF / backbone-TranSUN 的区别;
- DADF 离线用 equal-frequency duration 桶,KuaiRec $K=4$,WeChat21 $K=3$;线上 Kwai 部署用 4 个 fixed-duration 桶(基于历史流量统计与生产经验确定边界,不依赖数据流分布动态变化);
- 损失权重 $\alpha = 1.0$,$\beta = 0.8$,$\eta = 0.10$;其余超参在验证集上选,避免 test-set tuning。
4. 主要实验结果¶
4.1 RQ1:DADF 是不是一个通用插件?¶
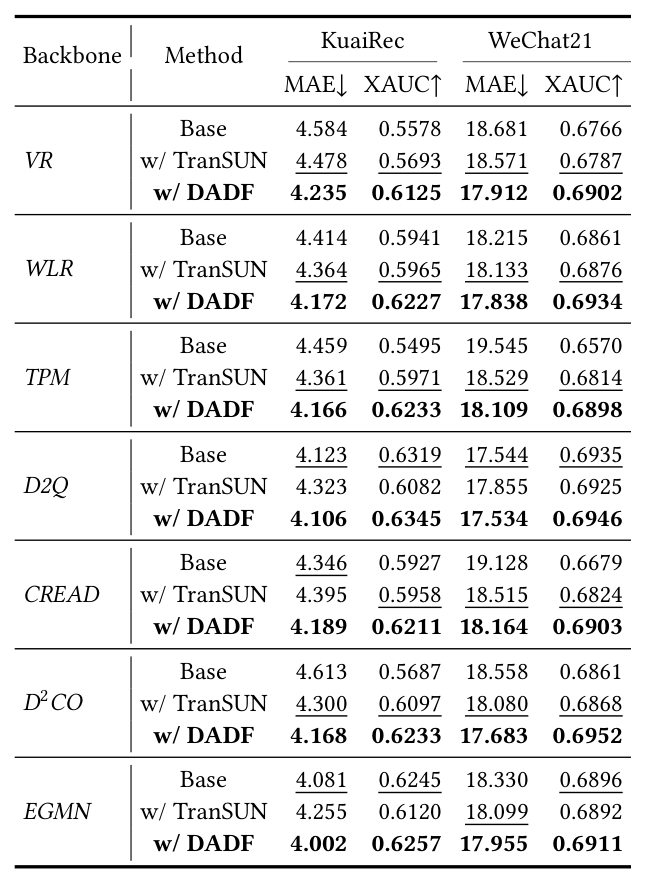
Table 1 在 7 个 backbone × 2 数据集 = 14 个组合上,对比"Base / +TranSUN / +DADF"三档:
| Backbone | Method | KuaiRec MAE↓ | KuaiRec XAUC↑ | WeChat21 MAE↓ | WeChat21 XAUC↑ |
|---|---|---|---|---|---|
| VR | Base | 4.584 | 0.5578 | 18.681 | 0.6766 |
| VR | w/ TranSUN | 4.478 | 0.5693 | 18.571 | 0.6787 |
| VR | w/ DADF | 4.235 | 0.6125 | 17.912 | 0.6902 |
| WLR | Base | 4.414 | 0.5941 | 18.215 | 0.6861 |
| WLR | w/ TranSUN | 4.364 | 0.5965 | 18.133 | 0.6876 |
| WLR | w/ DADF | 4.172 | 0.6227 | 17.838 | 0.6934 |
| TPM | Base | 4.459 | 0.5495 | 19.545 | 0.6570 |
| TPM | w/ TranSUN | 4.361 | 0.5971 | 18.529 | 0.6814 |
| TPM | w/ DADF | 4.166 | 0.6233 | 18.109 | 0.6898 |
| D2Q | Base | 4.123 | 0.6319 | 17.544 | 0.6935 |
| D2Q | w/ TranSUN | 4.323 | 0.6082 | 17.855 | 0.6925 |
| D2Q | w/ DADF | 4.106 | 0.6345 | 17.534 | 0.6946 |
| CREAD | Base | 4.346 | 0.5927 | 19.128 | 0.6679 |
| CREAD | w/ TranSUN | 4.395 | 0.5958 | 18.515 | 0.6824 |
| CREAD | w/ DADF | 4.189 | 0.6211 | 18.164 | 0.6903 |
| D²CO | Base | 4.613 | 0.5687 | 18.558 | 0.6861 |
| D²CO | w/ TranSUN | 4.300 | 0.6097 | 18.080 | 0.6868 |
| D²CO | w/ DADF | 4.168 | 0.6233 | 17.663 | 0.6952 |
| EGMN | Base | 4.081 | 0.6245 | 18.330 | 0.6896 |
| EGMN | w/ TranSUN | 4.255 | 0.6120 | 18.099 | 0.6892 |
| EGMN | w/ DADF | 4.002 | 0.6257 | 17.955 | 0.6911 |
关键结论:
- 跨 backbone 普适增益:DADF 在 7 个 backbone × 2 数据集 = 14 个组合上同时拿下最好 MAE 和最好 XAUC($t$-test $p\lt 0.05$)。平均 MAE 降低 4.33%,XAUC 提升 4.01%。
- TranSUN 不稳定:D2Q 和 EGMN 已经是较强的 backbone,TranSUN 在它们上反而出现负向(如 EGMN 上 MAE 从 4.081 升到 4.255),说明 单一全局校正会破坏已经校准良好的预测;DADF 在两个 backbone 上仍能稳定改进。
- 越是"裸"的 backbone 收益越大:VR、TPM、D²CO 这类残差较大的基础回归器,DADF 提升幅度最显著(VR MAE 从 4.584 → 4.235,TPM XAUC 从 0.5495 → 0.6233)。这证实了 分布感知的二阶校正对未充分标定的首阶段模型最有价值。
4.2 RQ2:线上 A/B 实验¶
DADF 已在 Kuaishou Kwai App(国际版)的 watch-time 预测器上做了 7 天线上实验:control 是基于 WLR 的生产 baseline,treatment 是在同样 WLR 之上加 DADF 作为事后修正,最终输出再进入排序公式。
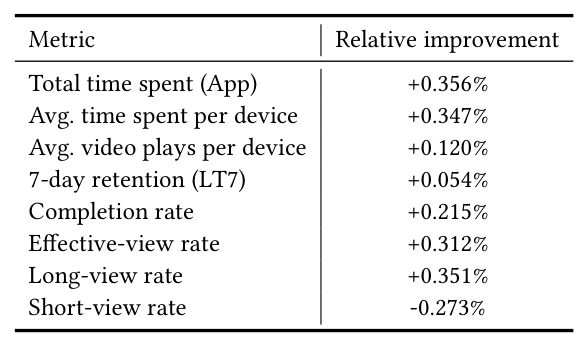
| Metric | Relative improvement |
|---|---|
| Total time spent (App) | +0.356% |
| Avg. time spent per device | +0.347% |
| Avg. video plays per device | +0.120% |
| 7-day retention (LT7) | +0.054% |
| Completion rate | +0.215% |
| Effective-view rate | +0.351% |
| Long-view rate | +0.351% |
| Short-view rate | −0.273% |
所有指标 $p\lt 0.05$。亮点:
- 核心 watch-time 指标:avg time spent per device +0.347%,total time spent +0.356%。
- 消费质量整体上移:completion、effective-view、long-view 全部正向,short-view 显著下降 0.273%。说明 DADF 的修正不是简单全局放大,而是把分配从快速划走(pseudo-balance 中被高估的部分)挪到深度消费(被低估的部分),下游排序就更倾向于推会被多看的内容。
- 长期留存:7-day retention +0.054%,统计显著且正向,说明短期 watch-time 的更好标定也能转化为长期用户粘性。
在上线前的 streaming production logs 离线评估,DADF 相对 WLR 生产 baseline 也给出 WUAUC +1.88 个百分点、MAE −12.57% 的离线收益,与线上一致。
4.3 RQ3:消融¶
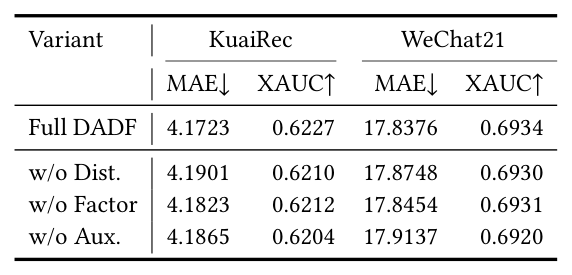
在 WLR backbone 上,逐项移除三个模块:
| Variant | KuaiRec MAE↓ | KuaiRec XAUC↑ | WeChat21 MAE↓ | WeChat21 XAUC↑ |
|---|---|---|---|---|
| Full DADF | 4.1723 | 0.6227 | 17.8376 | 0.6934 |
| w/o Dist. (去掉 Box–Cox 变换) | 4.1901 | 0.6210 | 17.8748 | 0.6930 |
| w/o Factor (去掉 duration group + 专家) | 4.1823 | 0.6212 | 17.8454 | 0.6931 |
| w/o Aux. (去掉多标签辅助头) | 4.1865 | 0.6204 | 17.9137 | 0.6920 |
逐项解读:
- w/o Dist.:在 KuaiRec 上 MAE 涨幅最大(4.1723 → 4.1901),WeChat21 类似。这印证了 distribution-aware 变换是稳定长尾标签学习的关键——去掉它就意味着回归直接面对原始 ratio 标签的右偏重尾,优化随机性增大。
- w/o Factor:在 WeChat21 上 MAE/XAUC 都退化,符合预期:少了 duration-group 分专家,模型被迫用一个共享头拟合所有 regime。MAE 退化比 w/o Dist 略小一些,说明 duration-group conditioning 在 oracle 风险中所减少的 cross-group 干扰是中等水平。
- w/o Aux.:XAUC 下降幅度最大(KuaiRec 0.6227 → 0.6204,WeChat21 0.6934 → 0.6920)。这是符合直觉的:辅助 engagement 信号最直接传达用户消费 排序质量,去掉就最伤排序一致性。
三者之间互补:Dist. 主导 MAE / 长尾稳定性、Aux. 主导 XAUC / 排序质量、Factor 在两类指标上都给中等增益。
4.4 RQ4:Bias-Oriented Analysis(细粒度偏差分析)¶
4.4.1 Duration-wise / Watch-time-wise 误差降低¶
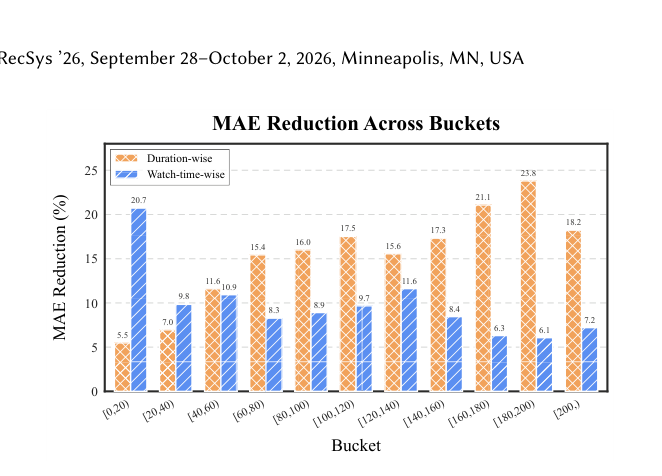
DADF 在所有 duration 桶上 MAE 都正向降低。两个视角:
- Duration-wise:短 duration 桶([0, 20], [20, 40])改进相对温和(5.5%, 7.0%);中长 duration 桶里全面超过 15%,[180, 200] 桶峰值 23.8%,[200, +) 仍有 18.2%。
- Watch-time-wise:在 [0, 20] watch-time 桶降幅最大 20.7%,对应 Figure 1 中显示的"短视频高估"区域。
两条视角互补:watch-time-wise 告诉你 在什么消费层级偏差被纠正了,duration-wise 告诉你 在哪种类型的视频上修正最划算。长 duration 视频包含大量短播样本,base model 系统性低估,DADF 的细粒度修正在这些"长视频内的短播"上效果尤其显著。
4.4.2 长 duration 尾部切片¶
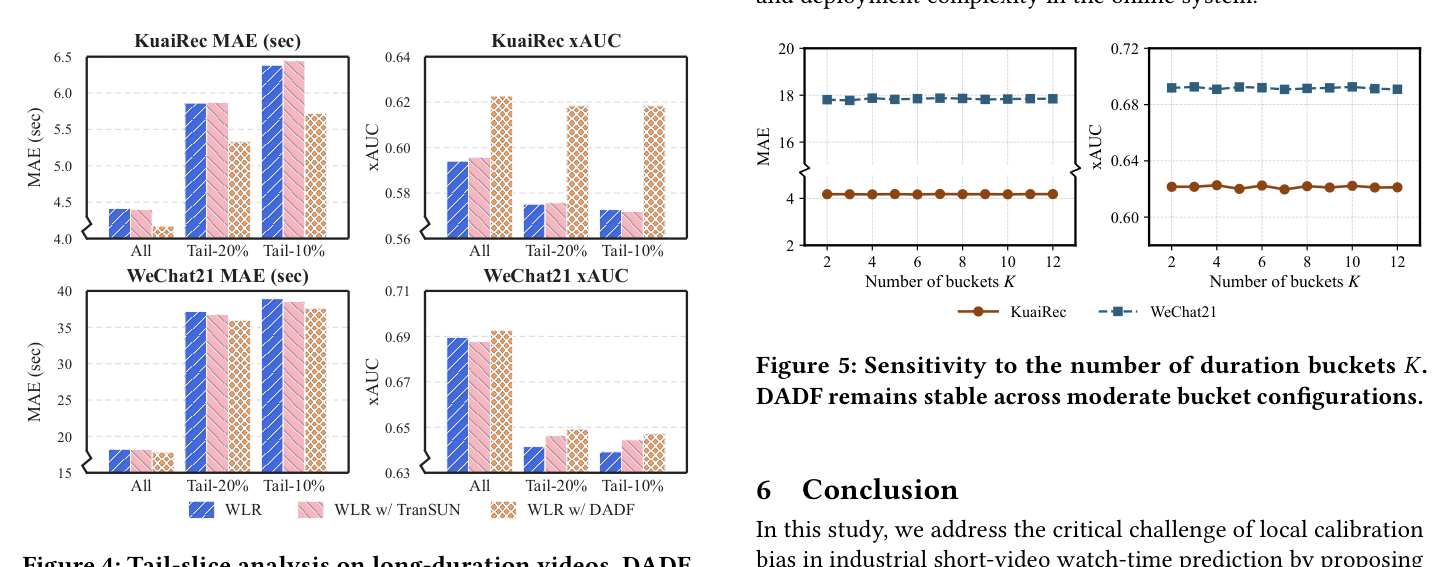
在 KuaiRec 和 WeChat21 上分别评估 Tail-20% 和 Tail-10% 长 duration 切片:
- KuaiRec:MAE 降低从 All 样本的 5.48% 增到 Tail-20% 的 9.10%、Tail-10% 的 10.43%;XAUC lift 从 4.82% → 7.52% → 7.98%。
- WeChat21:MAE 降低从 2.26% → 3.21% → 3.35%;XAUC lift 从 0.45% → 1.21% → 1.24%。
结论:样本越稀疏、duration 越长,DADF 收益越大——这正是 base model 系统性偏差最严重、传统全局校正最难处理的 regime。
4.4.3 Duration 桶数 $K$ 的敏感性¶
DADF 在 $K \in \{2, 3, \ldots, 12\}$ 上的 MAE / XAUC 都平稳,没有大的波动。这说明:
- 框架不依赖一个精细调过的分桶;
- 在线部署时桶边界可以按历史流量稳定地切,无需频繁重训;
- 提升的来源主要是 duration-group conditioning 本身,而非某个特定的分桶细节。
5. 核心贡献总结¶
- 问题诊断:明确提出 pseudo-balance 概念——全局校准看上去合格但局部高低估互相抵消,并实证了它在工业 watch-time 模型上的普遍性。
- 框架贡献:提出 DADF 作为一个 不替换首阶段、不重训 backbone 的二阶残差修正插件,三个互补模块各自解决长尾标签、跨 regime 异质、推理时信号有限三个核心难题。
- 理论支撑:附录给出"长尾继承定理"和"group-conditioned oracle risk 不增"两个分析,分别为分布变换和 duration grouping 提供严格依据。
- 离线 + 在线全面验证:7 个 backbone × 2 数据集证明 DADF 的通用插件性;Kuaishou Kwai 线上 A/B 拿到全方向正向,特别是 +0.347% avg time spent per device、+0.054% LT7 retention。
- 工程友好:首阶段不动、二阶模块轻量、duration 分桶可以用静态边界,对在线 serving 改造很小,因此可以作为工业系统的低风险增量优化。
6. 讨论与局限性¶
6.1 与已有工作的差异¶
- 与 TranSUN [46]:DADF 把变换从 标签 应用到 残差因子,并引入 group-specific 而非全局变换;引入多标签辅助信号;用 duration grouping 显式建模异质性。这是从"单一全局校正"到"分布感知分 regime 校正"的关键转向。
- 与 D2Q / D²CO [47, 49] 等 duration-aware debiasing:它们改 first-stage 的训练;DADF 把 duration 当作 post-hoc 校正信号,与之正交。Table 1 也显示在 D2Q 之上叠加 DADF 仍有正向。
- 与分布建模方法 (EGMN [50]、TPM [19]):它们建模 watch-time 的边缘 / 条件分布;DADF 不替换它们,而是修正它们留下的残差偏差,这是 EGMN backbone 上 +DADF 仍能提升的原因。
6.2 可借鉴的设计¶
- 分布感知 + group-specific transformation 这一组合可推广到任何 长尾连续目标 + regime 异质 的回归场景(如 conversion lift、dwell-time、bid 估计等);
- 训练时构造 ratio 标签 + stop-gradient + 复用辅助头 logits 做 inference-time 信号填充 是 industrial debiasing 的通用范式;
- 变换空间损失 + 原空间 Huber 损失 + 矩正则 的三项组合损失在长尾回归里值得借鉴;
- 静态 duration 桶 + 不敏感于 $K$ 让框架不引入复杂运维负担。
6.3 局限与未来工作¶
- 论文当前只研究 watch-time;其他连续 engagement 信号(dwell-time、scroll depth、purchase intent 等)是否能同样受益需要验证;
- duration 是天然的 debias factor,但其它场景下(如商品 CVR、广告竞价)选择哪个变量做 grouping 不明显,需要场景化设计;
- 三项损失权重 $\alpha, \beta, \eta$ 是手工调的,未给自适应方案;
- 论文方法在 backbone 已经强分布建模时(D2Q、EGMN)增益相对小(仍正向但绝对幅度较低)——意味着如果首阶段做得足够好,二阶 DADF 增益的天花板存在。
6.4 工业落地价值¶
DADF 把"二阶残差校正"做成一个工程开销极低的插件:
- 首阶段冻结,无需重训生产模型;
- 推理时只增加一次小 MLP / Box–Cox 的前向;
- duration 分桶可以用历史流量统计离线确定;
- 在 Kwai 国际版生产 7 天 A/B 中拿到所有 user-level 指标全部正向 + retention 正向,是少数能把"watch-time 标定偏差"直接转化为 retention 收益的工作之一。
对于已经部署 watch-time 预测器、不能轻易换 backbone、希望以最小工程改动获得用户消费指标提升的工业团队,DADF 提供了一个高 ROI 的优化路径。