Discrimination Is Generation: Unifying Ranking and Retrieval from a Tokenizer Perspective¶
研究动机与背景¶
生成式推荐(Generative Recommendation, GR)通过把 item 量化为离散的 Semantic ID(SID)序列,并经由 beam search 在 token 空间实现 full-corpus argmax 检索,从架构上打破了传统检索漏斗中复杂度与目录规模耦合的瓶颈。沿着 TIGER 开创的 "SID + NTP" 双阶段范式,后续工作主要在 tokenizer 上做文章:从 LETTER、DAS、DOS 的对比学习 / 双塔对齐,到 CoFiRec、CoST 的端到端联训,再到 Differentiable SID 的可微量化。然而生成式检索在工业指标上始终落后于判别式排序。
作者把根因归结为架构层面的结构性缺陷:
现有 SID 严重欠个性化 (existing SIDs are severely under-personalized)。
具体表现:
- 检索目标的固有局限:reconstruction / contrastive 损失只要求"相似 item 在 embedding 空间接近",并不强制要求细粒度个性化判别;
- 判别梯度从未流回 codebook:tokenizer 与下游生成模型两阶段串行训练,判别信号无法进入量化过程;
- u2i cross feature 完全缺席:用户-物品历史交互特征 $\mathbf{c}_{u,v}$(per-category/brand CTR、impression counts、purchase counts 等)正是判别式排序的核心 personalization 信号,从未参与过 codebook 构造。
- 同一 item 对所有用户分到同一个 SID——无论用户与该 item 是高度匹配还是完全错配。
这导致 codebook 边界反映的是 内容相似度等高线 而非 推荐决策边界。已有的 ETEGRec、ReSID、MTGRec 等沿用 NTP loss 调整 SID 仍困在 retrieval 范式内;STORE、TRM、UIST 等把 semantic token 引入判别式排序,但 tokenizer 训练目标仍独立于排序目标。
由此引出本文的根本问题:
Can the objective of discriminative ranking directly drive SID codebook construction, enabling the same token set to serve both generative retrieval and discriminative ranking?
作者的回答基于一个本质洞察——排序与检索是同一优化问题在不同粒度上的两面:
| 范式 | 目标 | 空间 |
|---|---|---|
| 判别式排序 | $\arg\max_{v \in \mathcal{V}} f(u, v)$ | item 空间 |
| 生成式检索 | $\arg\max_{(s_1, \dots, s_L)} g(u, s_1, \dots, s_L)$ | token 空间 |
SID 恰好坐落在两个空间的交点上——不只是预处理步骤,而是 判别与生成之间的桥梁。若 SID 构造直接由判别目标驱动,同一 token 表示就能同时承载排序的判别性 (discriminability) 和检索的生成性 (generativity):生成式检索能力不需要独立生成模型,它已经潜伏在判别式排序器内部,tokenizer 的作用是把它释放出来。
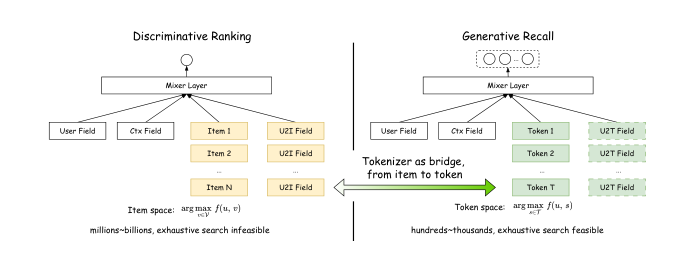
基于此本文提出 DIG (Discrimination Is Generation):把 tokenizer 嵌入到判别式排序器内部,端到端联训——排序器自然成为检索器,一次训练得到两个模型。整套方法围绕 feature assignment taxonomy(特征分配分类法)这一中央设计轴展开,系统化解决三类特征在训练与推理两侧的处理问题。
核心方法 / 模型架构¶
3.1 问题形式化与 DIG 框架¶
记号。设 $\mathcal{V}$ 为 item 集合、$\mathcal{U}$ 为用户集合。每个 item $v \in \mathcal{V}$ 拥有静态内容特征 $\mathbf{x}_v^s$(类目、品牌、地域、场景等);每个用户 $u \in \mathcal{U}$ 拥有用户特征 $\mathbf{x}_u$(画像、行为历史)以及上下文 $\mathbf{ctx}$(时间、定位、场景)。对每个 user-item 对 $(u, v)$,存在 u2i 交叉特征 $\mathbf{c}_{u, v}$(用户对该 item 的历史 CTR/CVR),承载了排序所依赖的核心信息。
在检索时 $\mathbf{c}_{u, v}$ 不可用(目标 item 未知);DIG 引入 u2t $\triangleq \mathbf{u2t}^{(l)}$,即同一 bucket $s_l$ 内 $\mathbf{c}_{u, v}$ 的 token 级聚合作为检索时的近似。"u2i" (user-to-item) 与 "u2t" (user-to-token) 的命名反映从 item 粒度向 token 粒度的粗化。
Semantic ID (SID)。SID 是一个 item-到-token-序列的映射 $\phi: \mathcal{V} \to \mathcal{T}^L$,其中 $\mathcal{T} = \{1, \ldots, K\}$ 是 codebook 词表、$L$ 是量化层数。Item $v$ 的 SID 写作 $\phi(v) = (s_1^v, \ldots, s_L^v)$。
核心洞察。判别式排序求 $\arg\max_{v \in \mathcal{V}} f(u, v)$ 在 item 空间;生成式检索求 $\arg\max_{(s_1, \ldots, s_L)} g(u, s_1, \ldots, s_L)$ 在 token 空间。两者解同一优化问题、只是粒度不同。tokenizer $\phi$ 正坐在两个空间的交点:若 SID 由判别式目标驱动,同一 token 表示既承载排序判别性、又承载检索生成性。生成式检索能力不需要独立生成模型,它已经潜伏在判别式排序器内部——tokenizer 的角色就是释放它。
特征分配分类法。统一范式的中央挑战是处理那些"排序有、检索没有"的特征——尤其是 u2i 交叉特征 $\mathbf{c}_{u, v}$。这些特征无法静态编码到 SID(同一 item 对不同用户产生不同 $\mathbf{c}_{u, v}$),但又必须以某种方式保留,否则会严重损害检索质量。Table 1 总结了 DIG 把所有特征划分成三类:
Table 1: Feature assignment taxonomy in DIG.
| Type | Symbols | In SID? | Training-side handling | Inference-side handling |
|---|---|---|---|---|
| Type-I item-side | $\mathbf{x}_v^s$ | ✓ | VQ 编码器输入 → $\mathbf{e}_v \to \mathbf{e}_{\mathrm{sid}}^{(1:L)}$ | 离线 SID lookup 表 |
| Type-II request-level | $\mathbf{x}_u, \mathbf{ctx}$ | × | 排序损失条件项 | Beam search decoder 条件项 |
| Type-III struct lossy | $\mathbf{c}_{u, v}$ | × | 通过 batch $\mathbf{u2t}^{(1:L)}$ 隐式塑形 codebook | $\mathrm{MLP}_{\mathrm{u2t}}$ 蒸馏 → $\hat{\mathbf{u2t}}^{(1:L)}$ |
这张分类表是 tokenizer 设计 (§3.2)、统一训练 (§3.3)、统一推理 (§3.4) 共同遵循的组织原则。
3.2 Unified Tokenizer:SID 构造与稳定性¶
VQ 编码器。VQ 编码器只接收 item-side 静态特征 $\mathbf{x}_v^s$,输出连续 item 嵌入:
$$\mathbf{e}_v = \mathrm{Enc}(\mathbf{x}_v^s) \tag{1}$$
只用 time-invariant 特征保证 SID 稳定性:同一 item 在模型版本之间永远映射到同一 token 序列,保留 SID-到-item 倒排索引的稳定性。
残差量化与 prefix 累积。DIG 对 $\mathbf{e}_v$ 应用 $L$ 层 residual quantization (RQ):
$$s_l^v = \arg\min_k \|\mathbf{r}_{l-1} - \mathbf{c}_{l, k}\|_2 \tag{2}$$
$$\hat{\mathbf{e}}_v^{(l)} = \mathbf{c}_{l, s_l^v}, \quad \mathbf{r}_l = \mathbf{r}_{l-1} - \hat{\mathbf{e}}_v^{(l)} \tag{3}$$
$$\hat{\mathbf{e}}_v^{(1:L)} = \sum_{i=1}^L \hat{\mathbf{e}}_v^{(i)} \tag{4}$$
其中 $\mathbf{r}_0 = \mathbf{e}_v$ 为初始残差,$s_l^v \in \mathcal{T}$ 是第 $l$ 层分配的码字,$\mathbf{c}_{l, k}$ 是第 $l$ 层的第 $k$ 个 codebook 向量,$\hat{\mathbf{e}}_v^{(1:L)}$ 是用作 item 粗细近似的 prefix 累积量化表示。Codebook 向量经 EMA 更新:$\mathbf{c}_{l, k} \leftarrow \alpha \mathbf{c}_{l, k} + (1 - \alpha) \hat{\mathbf{e}}_{l, k}$。残差结构构造了一个粗-到-细的层次:$\hat{\mathbf{e}}_v^{(1:l)}$ 以随 $l$ 单调递减的误差近似完整表示——这正是 layer-wise beam search 的结构基础。
SID–embedding 解耦。已有方法直接把 codebook 向量 $\mathbf{c}_{l, s_l^v}$ 当作 item 表示,把 SID 的 寻址 (addressing) 角色与 语义表达 (semantic expression) 角色耦合到同一组 codebook 向量上。这种耦合带来根本权衡:精细分区改进寻址精度但阻止 token 之间共享语义,粗分区允许共享但降低判别性。此外,由于 codebook 向量基于不可微 argmin 赋值,依赖它们打分的方法必须使用 STE / Gumbel-Softmax 近似梯度。
DIG 把两个角色解耦为两套独立参数:
- Codebook 向量 $\mathbf{c}_{l, k}$:只负责寻址(公式 2-3),通过 EMA 更新,不参与打分;
- SID embedding $\mathbf{e}_{l, k}^{\mathrm{sid}}$:负责语义表达,由判别 loss 端到端更新,不影响 SID 分配。
SID embedding prefix 为:
$$\mathbf{e}_{\mathrm{sid}}^{(1:l)} = \sum_{i=1}^l \mathbf{e}_{i, s_i^v}^{\mathrm{sid}} \tag{5}$$
其中 $\mathbf{e}_{l, k}^{\mathrm{sid}}$ 是第 $l$ 层第 $k$ 个码字的可学习 embedding,由判别 loss 直接驱动。因为 SID embedding 不参与 argmin 量化,判别梯度可以直接穿过——不需要 STE 近似。这同时解决了"寻址-共享"权衡:SID 分区可以任意细以实现零碰撞寻址,SID embedding 自由学习跨 token 语义共享。
关键地,每个 SID embedding $\mathbf{e}_{l, k}^{\mathrm{sid}}$ 按特征 field 定义、与排序 item 特征 embedding 同维度,因此 $\mathbf{e}_{\mathrm{sid}}^{(1:L)}$ 是 $\mathbf{e}_v$ 在排序 MLP 中的即插即用替换,无需任何结构改动。Codebook 几何与 SID embedding 之间的空间对齐通过 $\mathcal{L}_{\mathrm{sem}}$ 维护(要求 codebook 向量累积 $\hat{\mathbf{e}}_v^{(1:L)}$ 重建编码器输出 $\mathbf{e}_v$)。
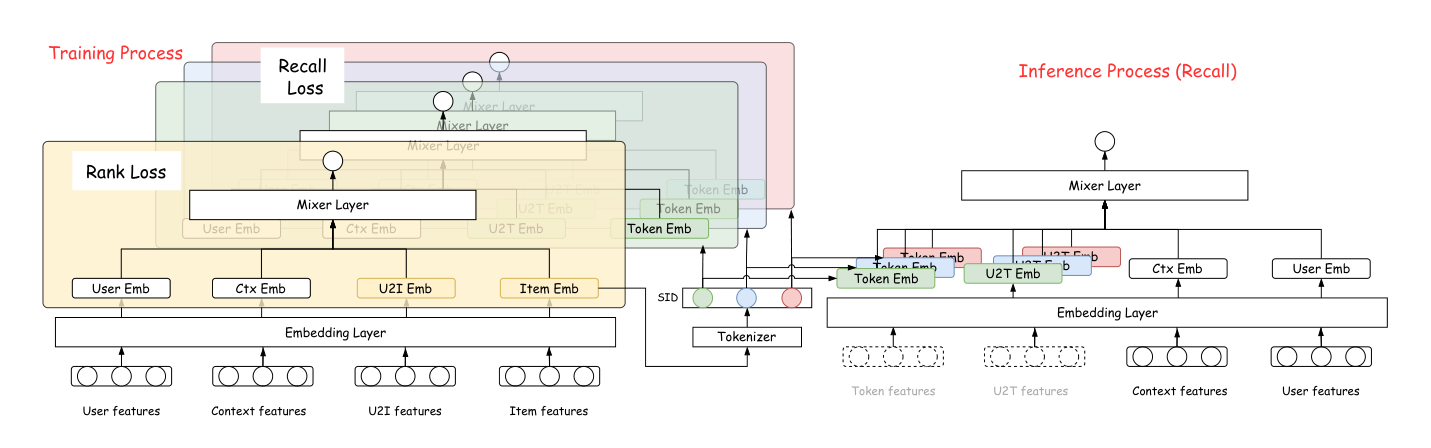
排序与检索共享同一个 Mixer(涵盖所有与目标 item / token 表示交互的模块,包括 scoring MLP、Target-Attention、MoE),$\mathbf{e}_u$ 经共享 BN 处理,其余输入经 feature-specific BN:
$$\hat{y}_{\mathrm{rank}} = \sigma\Big(\mathrm{Mixer}\big([\mathrm{BN}_u(\mathbf{e}_u);\, \mathrm{BN}_v(\mathbf{e}_v);\, \mathrm{BN}_{\mathbf{c}}(\mathbf{c}_{u, v})]\big)\Big) \tag{6}$$
$$\hat{y}_{\mathrm{recall}}^{(l)} = \sigma\Big(\mathrm{Mixer}\big([\mathrm{BN}_u(\mathbf{e}_u);\, \mathrm{BN}_{\mathrm{sid}}(\mathbf{e}_{\mathrm{sid}}^{(1:l)});\, \mathrm{BN}_{\mathrm{u2t}}(\mathbf{u2t}^{(1:l)})]\big)\Big) \tag{7}$$
其中 $\mathrm{BN}_u$ 跨两路共享;$\mathrm{BN}_v, \mathrm{BN}_{\mathrm{sid}}, \mathrm{BN}_{\mathbf{c}}, \mathrm{BN}_{\mathrm{u2t}}$ 是 feature-specific BN,对各 feature 做归一化。
低碰撞设计。SID 端到端更新时严格的离线零碰撞保证不再适用。DIG 通过两种互补机制控制碰撞率:(1) 零碰撞初始化:codebook 通过一棵 offline Balanced K-Means 树初始化,把 item 划入零初始碰撞的等大小簇,提供稳定的端到端联训起点;(2) 大 SID 空间:$L = 4, K = 256$ 时 SID 空间支持 $256^4 \approx 4\mathrm{B}$ 唯一四元组,远大于任何实际目录规模——训练后碰撞实践中可忽略。
3.3 Unified Training:联合损失¶
DIG 在标准 DIN+DCNv2+MoE 排序器的 item embedding 层之后插入 RQ 量化器;所有其他结构不变。Mixer 接收三类输入:item-side embedding $\mathbf{e}_v$、用户表示 $\mathbf{e}_u$、u2i 交叉特征 $\mathbf{c}_{u, v}$。
统一训练目标。五项 loss 全部端到端联合优化:
$$\mathcal{L} = \mathcal{L}_{\mathrm{rank}} + \mathcal{L}_{\mathrm{recall}} + \lambda_1 \mathcal{L}_{\mathrm{commit}} + \lambda_2 \mathcal{L}_{\mathrm{sem}} + \lambda_3 \mathcal{L}_{\mathrm{u2t}} \tag{8}$$
- $\mathcal{L}_{\mathrm{rank}}$ 为标准排序 BCE loss,驱动整个系统对齐推荐目标:
$$\mathcal{L}_{\mathrm{rank}} = \mathrm{BCE}(\hat{y}_{\mathrm{rank}}, y) \tag{9}$$
- $\mathcal{L}_{\mathrm{recall}}$ 为对齐 beam search 展开的逐层监督:
$$\mathcal{L}_{\mathrm{recall}} = \frac{1}{L} \sum_{l=1}^L \mathrm{BCE}(\hat{y}_{\mathrm{recall}}^{(l)}, y) \tag{10}$$
- $\mathcal{L}_{\mathrm{commit}}$ 防止编码器输出从 codebook entry 漂离:
$$\mathcal{L}_{\mathrm{commit}} = \sum_{l=1}^L \|\mathrm{sg}[\mathbf{c}_{l, s_l^v}] - \mathbf{r}_{l-1}\|_2^2 \tag{11}$$
其中 $\mathrm{sg}[\cdot]$ 是 stop-gradient 算子、$\mathbf{r}_{l-1}$ 为进入第 $l$ 层的残差。
- $\mathcal{L}_{\mathrm{sem}}$ 从量化表示重建 $\mathbf{e}_v$,防止 codebook collapse:
$$\mathcal{L}_{\mathrm{sem}} = \|\mathbf{e}_v - \hat{\mathbf{e}}_v^{(1:L)}\|_2^2 \tag{12}$$
其中 $\hat{\mathbf{e}}_v^{(1:L)}$ 是 codebook 向量的全深度 prefix 累积。
- $\mathcal{L}_{\mathrm{u2t}}$ 是下面定义的 MLP$_{\mathrm{u2t}}$ 蒸馏 loss。
Codebook 隐式 u2i 塑形 (Type-III, 训练)。虽然 $\mathbf{c}_{u, v}$ 无法静态编码到 SID,但可以间接驱动 codebook 边界向推荐决策边界靠拢——通过 mini-batch 内的聚合。每个训练 step,落到同一 bucket $s_l$ 内的 item(在当前 mini-batch $\mathcal{B}$ 中)把它们的 u2i 特征聚合为 token 级统计:
$$\mathbf{u2t}^{(l)} = \frac{1}{|\mathcal{V}_{s_l}^{(l), \mathcal{B}}|} \sum_{v' \in \mathcal{V}_{s_l}^{(l), \mathcal{B}}} \mathbf{c}_{u, v'} \tag{13}$$
其中 $\mathcal{V}_{s_l}^{(l), \mathcal{B}}$ 是当前 mini-batch 中第 $l$ 层落入 bucket $s_l$ 的 item 集合,$\mathbf{c}_{u, v'}$ 是用户 $u$ 对 item $v'$ 的 u2i 特征。经由 $\mathcal{L}_{\mathrm{recall}}$,量化器被隐式奖励为:把 u2i 信号相似的 item 聚到同一 bucket。SID 边界因此反映推荐决策边界而非纯内容相似度。
MLP$_{\mathrm{u2t}}$ 蒸馏 (Type-III, 训练)。Bucket 平均 $\mathbf{u2t}^{(l)}$ 损失了 within-bucket 个性化。MLP$_{\mathrm{u2t}}$ 通过学习 user-conditioned 近似来恢复它,以 batch 统计 $\mathbf{u2t}^{(l)}(u)$ 为 teacher signal:
$$\hat{\mathbf{u2t}}^{(l)}(u) = \mathrm{MLP}_{\mathrm{u2t}}^{(l)}\big([\mathbf{e}_u;\, \mathbf{e}_{\mathrm{sid}}^{(1:l)}]\big) \tag{14}$$
$$\mathcal{L}_{\mathrm{u2t}} = \frac{1}{L} \sum_{l=1}^L \|\hat{\mathbf{u2t}}^{(l)}(u) - \mathrm{sg}[\mathbf{u2t}^{(l)}(u)]\|_2^2 \tag{15}$$
其中 $\hat{\mathbf{u2t}}^{(l)}(u)$ 是 MLP$_{\mathrm{u2t}}^{(l)}$ 给出的个性化 u2t 预测(每层一个轻量 MLP)、$\mathbf{u2t}^{(l)}(u)$ 是 batch 均值 u2t 统计、$\mathrm{sg}[\cdot]$ 停止 batch 统计向 MLP 的梯度。输入 $\mathbf{e}_u$ 与 $\mathbf{e}_{\mathrm{sid}}^{(1:l)}$ 在线上推理时都可用——MLP$_{\mathrm{u2t}}$ 无需离线 feature table。输出维度等于 $\mathbf{c}_{u, v}$ 的维度 $d_c$,因此 $\hat{\mathbf{u2t}}^{(1:L)}$ 在线检索时可直接替换共享 MLP 中的 $\mathbf{c}_{u, v}$。
3.4 Unified Inference:特征对齐与 Beam Search¶
Online retrieval (beam search)。每一步 $l$,第 $l$ 层所有 $K$ 个 token 都被共享 Mixer 评分,用在线 MLP$_{\mathrm{u2t}}$ 输出替换 $\mathbf{c}_{u, v}$:
$$\hat{y}_{\mathrm{recall}}^{(l)} = \sigma\Big(\mathrm{Mixer}\big([\mathrm{BN}_u(\mathbf{e}_u);\, \mathrm{BN}_{\mathrm{sid}}(\mathbf{e}_{\mathrm{sid}}^{(1:l)});\, \mathrm{BN}_{\mathrm{u2t}}(\hat{\mathbf{u2t}}^{(1:l)}(u))]\big)\Big) \tag{16}$$
经过 $L$ 步后,候选从离线构建的 SID-到-item 倒排索引恢复。
Online ranking。检索出的候选进入排序时具备完整 u2i 特征:
$$\hat{y}_{\mathrm{rank}} = \sigma\Big(\mathrm{Mixer}\big([\mathrm{BN}_u(\mathbf{e}_u);\, \mathrm{BN}_v(\mathbf{e}_v);\, \mathrm{BN}_{\mathrm{u2i}}(\mathbf{c}_{u, v})]\big)\Big) \tag{17}$$
训练-推理对称性。检索与排序两条路径共享同一 Mixer——唯一差异是 item-side 表示粒度(检索 $\mathbf{e}_{\mathrm{sid}}^{(1:L)}$ vs 排序 $\mathbf{e}_v$)和交叉特征粒度(检索 $\hat{\mathbf{u2t}}^{(1:L)}$ vs 排序 $\mathbf{c}_{u, v}$)。这一对称性从根本上消除了传统双系统流水线的语义鸿沟:检索搜索目标本身就严格对齐排序优化目标。
实验设置¶
4.1 数据集¶
DIG 在 5 个数据集上评估,覆盖极端的稀疏度范围:
| 数据集 | 用户 | item | 交互 | 密度 | u2i 完备性 |
|---|---|---|---|---|---|
| KuaiRec-Small | 1,411 | 3,327 | — | 99.6% | Full(完整交互矩阵) |
| KuaiRec-Big | 7,176 | 10,728 | — | 16.3% | Sparse |
| Taobao Ad | — | — | ~26.6M ranking 样本 | ~0.003% | 来自排序日志(曝光) |
| Meituan-Large | ~20M | ~500K | ~7.5M | ~0.0008% | Full(含丰富 u2i) |
| Meituan-Small | ~12K | ~40K | ~1.5M | ~0.31% | Full |
样本按时间严格划分:每用户最后一次点击作测试、倒数第二次作 valid、其余作训练。
- Ranking 样本:每条曝光记录 $(\mathbf{x}_u, \mathrm{hist}, \mathbf{x}_v^s, \mathbf{c}_{u, v}, y)$,u2i 用 prefix 累积统计避免泄漏;
- Retrieval 样本:仅 positive ($y = 1$),full-corpus 随机负采样,beam search 在全 item 语料评估,记作 Recall@$K$ / NDCG@$K$。
KuaiRec 提供更严格的 retrieval-native benchmark(完整交互矩阵)——测试 target 可能从未被用户曝光过;Taobao 与 Meituan 来自排序曝光日志,候选池上游已被预过滤。
u2i 特征。Taobao:per-category/brand CTR、impression count、purchase count(6 维)。KuaiRec:per-user watch_ratio、like_rate。Taobao/Meituan(曝光日志)每条训练样本都有有意义的 u2i;KuaiRec-Big(完整矩阵)83.7% 的 pair 无先前交互,u2i 对这些 pair 为零或退化。
4.2 实现细节¶
- Backbone:DIN + DCNv2 + MoE 排序器。DIN 通过 attention 建模用户历史、DCNv2 捕获高阶特征交互、MoE 提供多专家容量。tokenizer 作为插件组件落在 item embedding 层之后,所有 backbone 结构保持不变;
- Baselines(5 个有代表性的生成式检索方法,使用相同 NTP 生成模型公平对比):(1) TIGER(RQ-VAE 重建 loss + NTP)、(2) LETTER(双塔对比学习量化对齐)、(3) DAS、(4) DOS(协同信号驱动量化)、(5) ETEGRec(端到端 tokenizer-generator 联训);
- VQ 编码器:4 层 Transformer on item-side 静态特征;
- RQ 量化器:$L = 4$ 层,$K = 256$ codebook entries per layer,embedding dim $d = 64$;
- MLP$_{\mathrm{u2t}}$:每层一个 2 层 MLP,hidden dim 64,输出维度等于 u2i 特征维度;
- 训练:batch size 2048、Adam 优化器、lr $= 1 \times 10^{-3}$、$\lambda_1 = 0.25$、$\lambda_2 = 0.1$、$\lambda_3 = 0.1$;
- L=4, K=256:第 1 层有 ~180 个活跃 bucket(~1M items/bucket),第 2-4 层渐次变窄,但累积 prefix u2t$^{(1:l)}$ 跨所有前序层聚合,因此深层浅 bucket 也获得有意义信号;
- 全部实验运行在 8×A100 GPU。
主要实验结果¶
4.2 检索性能 (RQ1)¶
RQ1:DIG 能否超越生成式检索 baseline?
Table 2: Main retrieval results (Recall@10 / NDCG@10). 加粗为最优。
| Method | Taobao | KuaiRec-S | KuaiRec-B | MT-Large | MT-Small | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| R@10 | N@10 | R@10 | N@10 | R@10 | N@10 | R@10 | N@10 | R@10 | N@10 | |
| TIGER | 0.0001 | 0.0020 | 0.0052 | 0.0081 | 0.0030 | 0.0045 | 0.0018 | 0.0041 | 0.0015 | 0.0033 |
| LETTER | 0.0001 | 0.0027 | 0.0063 | 0.0109 | 0.0059 | 0.0060 | 0.0023 | 0.0051 | 0.0018 | 0.0039 |
| DAS | 0.0003 | 0.0054 | 0.0116 | 0.0216 | 0.0102 | 0.0119 | 0.0029 | 0.0063 | 0.0021 | 0.0054 |
| DOS | 0.0005 | 0.0106 | 0.0213 | 0.0426 | 0.0121 | 0.0234 | 0.0037 | 0.0082 | 0.0031 | 0.0067 |
| ETEGRec | 0.0007 | 0.0126 | 0.0275 | 0.0504 | 0.0153 | 0.0277 | 0.0041 | 0.0089 | 0.0035 | 0.0074 |
| DIG (ours) | 0.0019 | 0.0341 | 0.0418 | 0.1189 | 0.0254 | 0.0463 | 0.0097 | 0.0213 | 0.0112 | 0.0248 |
| Improv. | +171% | +171% | +52.0% | +136.1% | +66.0% | +67.1% | +136.6% | +139.3% | +220% | +235.1% |
DIG 在全部 5 个数据集、全部指标上都取得最佳检索质量。三点观察:
(1) 跨 SID 构造策略的一致优势。已有 tokenizer——无论是 semantic reconstruction (TIGER) 还是 retrieval-aligned contrastive loss (LETTER, DAS, DOS)——都只编码静态 item 属性。DIG 的判别式 SID 通过端到端 BCE loss 把 codebook 边界对齐用户偏好决策边界;beam search 因此探索的是反映实际推荐效用而非内容相似度的 token 空间,闭合了 NTP-based 方法所困扰的语义鸿沟。
(2) 不同密度区间 gains 一致、underlying 来源不同。在 KuaiRec-Small(99.6% 密度)上,NTP baseline 已经有强用户历史可用,但 DIG 仍取得 +52.0% R@10——gain 来自 u2i 特征机制与端到端判别训练:即便稠密场景下,u2i 信号 $\mathbf{c}_{u, v}$ 也把 codebook 边界推向推荐决策边界,MLP$_{\mathrm{u2t}}$ 提供 token 级个性化近似(NTP 模型从根本上缺乏)。在 Taobao(~0.003%)上,NTP baseline 因序列匮乏(Taobao 平均点击历史 < 5)受额外退化,在弱 baseline(如 TIGER R@10 = 0.0001)上几近崩溃。Taobao(+171% over ETEGRec)和 Meituan-Small(+220%)的相对 gains 部分反映 baseline 在稀疏场景的弱表现,但绝对 gains over best baseline(+0.0101 和 +0.0077)依然确认了一致提升。DIG 的判别信号来源于排序侧曝光样本,独立于 SID 点击序列长度,本质上对短序列和冷启动用户鲁棒。
(3) 结合稀疏 + 丰富 u2i 的工业数据集 gains 最大。Meituan-Small 表现出极度交互稀疏(~0.016% positive rate)但又有来自工业排序流水线的丰富 u2i 特征。这一组合在 +220% R@10 上 deliver 最大 gain:稀疏让 NTP baseline 最脆弱(短序列、差泛化)、丰富 u2i 让 DIG 判别信号质量最大——两效应相互放大。
4.3 排序性能 (RQ2)¶
RQ2:端到端联训是否伤害排序?
把 tokenizer 嵌入排序器引入检索-路径梯度,可能干扰排序目标。作者通过比较 DIG 与 rank-only 模型 (recall_loss_weight=0)——它有 tokenizer 但 disable 检索-路径梯度。
Table 3: Ranking AUC comparison. $\Delta$ = DIG - Base. Base 为 rank-only 模型 (recall_loss_weight=0)。
| Method | Taobao | KuaiRec-S | KuaiRec-B | MT-Large | MT-Small |
|---|---|---|---|---|---|
| Base | 0.6225 | 0.8428 | 0.8240 | 0.9058 | 0.6521 |
| DIG | 0.6402 | 0.8565 | 0.8304 | 0.9071 | 0.6726 |
| $\Delta$ | +0.0177 | +0.0137 | +0.0064 | +0.0013 | +0.0205 |
端到端联训在所有 5 个数据集上一致提升排序质量。
Finding 1: DIG 在所有数据集上都改进排序。增益范围 +0.0013 (Meituan-Large) 到 +0.0205 (Meituan-Small)。Taobao +0.0177、KuaiRec-S +0.0137、KuaiRec-B +0.0064。这些 gains 是 SID embedding 参数共享机制的副产品:u2i 驱动的 codebook 边界把用户偏好相似的 item 聚到一起,丰富 SID embedding 的协同信号,同时惠及检索和排序。
Finding 2: u2i 越丰富、gains 越大。两个最大 gain 出现在 Meituan-Small (+0.0205) 和 Taobao (+0.0177),随后是 KuaiRec-S (+0.0137) 和 KuaiRec-B (+0.0064)——都是 u2i 信号有意义的数据集。这一模式确认排序 bonus 不是检索路径正则化的副作用,而是判别式 SID 边界编码用户偏好的直接结果:驱动检索质量的 u2i 驱动的 codebook 边界,同时通过 $\mathcal{L}_{\mathrm{sem}}$ 把 codebook 几何与 SID embedding 耦合,为排序 MLP 提供结构化协同正则化。
Finding 3: 排序 bonus 的结构机制。两条互补通道:(1) u2i 驱动的 codebook 边界经 $\mathcal{L}_{\mathrm{sem}}$ 在 codebook 几何与 SID embedding 之间提供协同正则化;(2) 逐层 $\mathcal{L}_{\mathrm{recall}}$ 监督鼓励层次嵌入结构,在每个 prefix 深度都锐化 item 判别。两条通道在 rank-only 训练 (recall_loss_weight=0) 中都缺席——这解释了为何 Base 一致低于 DIG。
4.4 Unified Retrieval-Ranking (RQ3)¶
RQ3:unified 模型的候选质量是否优于独立检索?
Table 4: Unified retrieval-ranking AUC gap. Gap 衡量检索路径打分能力相对完整排序路径的差距。
| Dataset | Rank AUC | Recall AUC | Gap ($\Delta$) |
|---|---|---|---|
| Taobao | 0.6402 | 0.6115 | $-0.0287$ |
| KuaiRec-S | 0.8565 | 0.8431 | $-0.0134$ |
| KuaiRec-B | 0.8304 | 0.8132 | $-0.0172$ |
| MT-Large | 0.9071 | 0.8459 | $-0.0612$ |
| MT-Small | 0.6726 | 0.6483 | $-0.0243$ |
Finding 1: Gap 与 u2i 特征复杂度相关、与交互密度无关。KuaiRec u2i 简单 (watch_ratio, like_rate)、MLP$_{\mathrm{u2t}}$ 近似准确——gap 小(-0.0134 KuaiRec-S, -0.0172 KuaiRec-B)。Taobao 和 Meituan-Large 的 u2i 高维(per-category/brand CTR、impression、purchase counts),token 级近似更难、gap 更大(分别 -0.0287 和 -0.0612)。这一 gap 是 unified 模型设计的固有代价:MLP$_{\mathrm{u2t}}$ 在 token 粒度近似 item 粒度的 $\mathbf{c}_{u, v}$,近似误差随 u2i 特征复杂度增长。
4.5 消融实验¶
Ablation 1: 判别梯度必要性 (E2E vs 两阶段)。
DIG 端到端训练替换为两阶段 baseline (Fixed SID):SID 离线用相同的 Balanced K-Means 树初始化预生成,然后冻结 VQ 编码器,codebook 边界不变。这隔离地评估了"判别梯度能否重塑 codebook"在三个公共数据集上的唯一作用。
Table 5: Effect of discriminative gradient on retrieval and ranking across three public datasets.
| Dataset | Config | Rank AUC | Recall AUC | Recall@10 |
|---|---|---|---|---|
| Taobao | DIG (E2E) | 0.6402 | 0.6115 | 0.0019 |
| Fixed SID | 0.6355 | 0.6089 | 0.0014 | |
| $\Delta$ | +0.0047 | +0.0026 | +35.7% | |
| KuaiRec-S | DIG (E2E) | 0.8565 | 0.8431 | 0.0418 |
| Fixed SID | 0.8544 | 0.7562 | 0.0275 | |
| $\Delta$ | +0.0021 | +0.0869 | +52.0% | |
| KuaiRec-B | DIG (E2E) | 0.8304 | 0.8132 | 0.0254 |
| Fixed SID | 0.8308 | 0.7451 | 0.0008 | |
| $\Delta$ | $-0.0004$ | +0.0681 | +212% |
三数据集上,冻结 tokenizer 一致地把 Recall AUC 显著拖低(KuaiRec-S:$-0.0869$;KuaiRec-B:$-0.0681$;Taobao:$-0.0026$),而 Rank AUC 几乎不变($|\Delta| \leq 0.002$)。Recall AUC gap 在 KuaiRec 数据集上特别显著——固定 tokenizer 按内容几何分组 item,beam search 探索语义连贯但与偏好无关的区域。几近零的排序代价确认判别梯度重塑 codebook 不干扰排序 MLP——后者无论如何都接收完整 u2i 特征。判别梯度是 DIG 检索质量的根本来源,对排序代价可忽略。
Ablation 2: training-side u2i 与 inference-side MLP$_{\mathrm{u2t}}$ 的独立贡献。在 Taobao 上做正交消融:
Table 6: Orthogonal ablation on Taobao (R@10 / N@10).
| Config | R@10 | N@10 |
|---|---|---|
| Full DIG | 0.0019 | 0.0341 |
| w/o training-side u2i | 0.0014 ($-26.3\%$) | 0.0253 ($-25.8\%$) |
| w/o inference MLP$_{\mathrm{u2t}}$ | 0.0016 ($-15.8\%$) | 0.0290 ($-14.9\%$) |
| w/o both | 0.0010 ($-47.4\%$) | 0.0183 ($-46.3\%$) |
互补效应进一步确认 mutual reinforcement:移除两者导致 $-47.4\%$,超过两个单独 drop 的和($-26.3\% + -15.8\% = -42.1\%$)。Training-side u2i 把 codebook 边界推向推荐决策边界、改进 MLP$_{\mathrm{u2t}}$ 蒸馏信号质量——两组件相互放大而非独立堆叠。
Ablation 3: MLP$_{\mathrm{u2t}}$ vs 统计均值 u2t。Taobao 上:MLP$_{\mathrm{u2t}}$ (full DIG) R@10=0.0019、统计均值 u2t R@10=0.0015($-21.1\%$)。MLP$_{\mathrm{u2t}}$ 的优势在稀疏 token 和长尾用户上最显著:低活跃用户的统计 mean u2t 高度不稳,而 MLP$_{\mathrm{u2t}}$ 通过模型泛化恢复稳定估计。
Ablation 4: layer-wise supervision 必要性。把 layer-wise $\mathcal{L}_{\mathrm{recall}}$ 替换为只在最后一层监督 ($l = L$):retrieval 指标显著下降($-18.4\%$ R@10),ranking AUC 几乎不变($\approx 0$)。这恰好分离两个机制:逐层监督的价值在于消除训练-推理差异(intermediate prefixes 在没有监督下成为 out-of-distribution 输入)、并非提供排序正则化。DIG 的正向排序效果来自判别式 SID embedding 的结构改进,独立于逐层监督。
4.6 稀疏场景稳定性分析¶
Table 7: Sparse scenario stability. $\Delta$AUC = DIG - Base ranking AUC.
| Dataset | Density | u2i Completeness | $\Delta$AUC | Stability |
|---|---|---|---|---|
| KuaiRec-S | 99.6% | Full | +0.0137 | Stable |
| KuaiRec-B | 16.3% | Sparse | +0.0064 | Stable |
| Taobao | 0.003% | Full (ranking logs) | +0.0177 | Stable |
| MT-Large | 0.0008% | Full$^{*}$ | +0.0013 | Stable |
| MT-Small | 0.31% | Full$^{*}$ | +0.0205 | Stable |
$^{*}$ Meituan 数据集用数百维 u2i 交叉特征直接来自真实工业排序流水线,对所有曝光 user-item pair 提供 full 覆盖。
Finding 1: 训练样本构造决定 u2i 完备性、不是交互矩阵密度。Taobao 交互矩阵密度只有 0.003%,但每条训练样本携带完整 u2i 特征——数据来自排序曝光日志、ranker 只对已有交互历史的 user-item pair 评分。KuaiRec-Big 矩阵密度 16.3%,但训练集从完整交互矩阵(含未观测 pair)构造——83.7% 训练样本 u2i 为零或退化。尽管如此,DIG 仍在 KuaiRec-Big 取得 +0.0064 AUC gain,说明即便部分 u2i 覆盖也足以为判别式 SID 边界提供排序收益。
Finding 2: $\mathcal{L}_{\mathrm{recall}}$ 是 SID embedding 的主要训练信号。$\mathcal{L}_{\mathrm{rank}}$ 用全 item-side embedding $\mathbf{e}_v$(不是 SID embedding $\mathbf{e}_{l, k}^{\mathrm{sid}}$),其梯度主要经由 $\mathbf{e}_v$ 与 $\mathbf{e}_u$ 流。SID embedding 仅通过 $\mathcal{L}_{\mathrm{sem}}$ 接收较弱的间接信号。$\mathcal{L}_{\mathrm{recall}}$ 直接在每一层监督 SID prefix $\mathbf{e}_{\mathrm{sid}}^{(1:l)}$、使 SID embedding 成为其主要优化目标。设 recall_loss_weight=0 导致 SID embedding 退化、ranking AUC 下跌——确认 $\mathcal{L}_{\mathrm{recall}}$ 不可替代。
结论。DIG 跨 5 个数据集稳定,与交互矩阵密度无关。关键驱动是排序曝光日志中 u2i 信号的质量;DIG 利用这些信号重塑 codebook 边界,即便在稀疏交互场景也提供一致的排序 gain。工业部署上,u2i 特征覆盖率应优先评估;低覆盖场景下,配置更强的 MLP$_{\mathrm{u2t}}$ 进一步改善蒸馏质量。
核心贡献总结¶
- 重思 SID 本质 + 提出统一范式:tokenizer 在 item 空间和 token 空间之间架桥;判别式排序内部已经潜伏着生成式检索能力——tokenizer 不需要额外模型,只需要被释放。
- DIG 系统化实现:以 feature assignment taxonomy 为中央设计轴,整合三类创新——tokenizer 设计(SID 寻址/语义解耦、低碰撞设计)、unified training(五项 loss 端到端联训、$\mathcal{L}_{\mathrm{recall}}$ 逐层监督、u2i 隐式塑形 codebook、MLP$_{\mathrm{u2t}}$ 蒸馏)、unified inference(共享 Mixer、训练-推理对称性)。
- 跨 5 数据集实验(3 公开 + 2 工业):检索一致 $+52\% \sim +220\%$ R@10 over SOTA 生成式 baseline,排序在所有数据集都同步改进,稀疏 + 丰富 u2i 场景 gain 尤其显著。
与已归档相关工作的对比¶
OneRanker OneRanker (Tencent Inc., 2026-03-03)¶
关系:独立并发(DIG 引用了 2024 年的另一篇同名 OneRanker (2407.09647 by Zhu et al.),但未引用 Tencent OneRanker;两者方法殊途同归)· 已加载对方精读
- 共同关注的问题:两文都在工业广告 / 推荐场景中追问如何彻底打破"生成 / 检索"和"排序"两阶段流水线的语义鸿沟——同时优化"用户偏好(点击/转化)"和"商业价值(eCPM / GMV)"。两者都把传统 "generate-then-rank" 视为存在三重断裂(表示、计算、误差传播),且都把 SID 视为统一两侧的关键结构。
- 相近的技术骨架:两文都拒绝额外引入独立的生成模型,转而把检索 / 生成能力寄生在原本只承担一侧职责的网络里。OneRanker 把排序能力"寄生"到 G-Decoder 的 KV 缓存里,让 R-Decoder 复用同一份用户表示;DIG 把 tokenizer "寄生"到判别式排序器里,让排序 BCE loss 同时驱动 SID 构造。两者都通过 共享同一个 Mixer / Decoder 块 实现"训练-推理对称性",确保检索目标精确对齐排序目标。
- 本文的差异与推进:方向正好相反——OneRanker 从 generative-first 出发、把 ranking 内化进生成流水线(Step 3 Unified Ranking Decoder);DIG 从 discriminative-first 出发、把 retrieval 释放出判别式排序器(embedded tokenizer + beam search)。结果上 OneRanker 保留了 GPR tokenization(独立的 SID 构造阶段),而 DIG 让 tokenizer 本身被排序信号端到端重塑——SID 边界反映推荐决策边界而非语义距离。DIG 因此还显式回答了 u2i 交叉特征(OneRanker 通过 fake item token 间接处理)的训练-推理粒度对齐问题:MLP$_{\mathrm{u2t}}$ 蒸馏在 token 粒度近似 item 粒度的 u2i。
- 可比的方法 / 实验差异:OneRanker 的核心收益指标是商业价值(在 Weixin Channels 上达成 $+1.55\%$ 收入 / $+0.78\%$ GMV),而 DIG 的核心收益指标是检索质量($+52\% \sim +220\%$ R@10 over SOTA tokenizers)。两者都强调"排序质量不掉甚至同步改进",但 OneRanker 通过 DC loss 双向对齐保证一致性,DIG 通过 codebook 边界的协同正则化($\mathcal{L}_{\mathrm{sem}}$)副产品式获得排序 bonus。
讨论与局限性¶
核心贡献的可借鉴性。DIG 的最大方法论突破是把"训练 tokenizer 的目标"和"训练 ranker 的目标"统一成同一个 BCE:codebook 边界从此承载推荐效用而非内容相似度。这给所有 SID-based 工业系统一个直接可用的工程模板——任何已经在用 DIN+DCNv2+MoE 的厂商,可以在 item embedding 层后插入一个 RQ 量化器、加一个 $\mathcal{L}_{\mathrm{recall}}$ 即可获得"免费"的生成式检索模型。SID embedding-addressing 解耦设计巧妙地绕开了 STE 近似(codebook 处理寻址、SID embedding 处理表达),值得在所有需要量化但要可微的场景借鉴。
值得借鉴的设计:
- Feature assignment taxonomy 作为中央设计轴——明确把所有特征分为三类、各自规定训练 / 推理侧处理方式,比"哪个特征接到哪里"的工程拍脑袋更系统化;
- 逐层 BCE 监督 ($\mathcal{L}_{\mathrm{recall}}$) 对齐 beam search 展开——这与已有把 NTP 改成逐层判别监督的尝试方向一致,但更彻底;
- u2i 隐式塑形 通过 batch 内同 bucket 聚合实现,是把 "排序特征如何参与量化" 这一难题的优雅折中。
存在的局限 / 争议:
- Retrieval-Ranking gap 内在不可消除。MLP$_{\mathrm{u2t}}$ 在 token 粒度近似 item 粒度的 u2i,gap 与 u2i 复杂度正相关。Meituan-Large 上 gap 达到 $-0.0612$,意味着检索召回的部分高分候选进入排序后会被改判。增大 MLP$_{\mathrm{u2t}}$ 容量是直接缓解方式但论文未给出 ablation。
- 稀疏交互矩阵 + 弱 u2i 信号的双重制约。Finding "u2i 覆盖率比交互矩阵密度更关键"是一个重要观察,但反过来说:如果数据来自 retrieval-native pool(如 KuaiRec-Big)且 u2i 信号稀疏,DIG 的优势会被压缩到 +0.0064 ranking AUC——离工业场景的可感知阈值仍有距离。
- 未做 online A/B。论文虽强调两个 Meituan 工业数据集是从生产管线中提取的,但未报告在线 A/B 业务指标(CTR、CVR、GMV)。同期工业生成式推荐工作(OneRec、OneRanker、GR4AD、UniVA)都包含数日到数月的线上验证。这一缺失让"工业部署价值"的论证不完整。
- SID 稳定性 vs 端到端适应的权衡。DIG 通过"VQ 编码器只接收 time-invariant 静态特征"保证 SID 稳定性,但同时也意味着:item 的动态属性(如热度、库存)无法影响 SID 分配。对于商品季节性、广告投放周期等强时变场景,这一设计的代价需要进一步评估。
- 大 SID 空间 vs 倒排索引规模。$L=4, K=256$ 时 SID 空间 ~4B 唯一组合(远超任何目录规模),但同时意味着 bucket 高度稀疏化——深层 bucket 可能只有 $O(1)$ 个 item,beam search 在深层探索时层间分支锐减、检索多样性可能受限。
与已有工作的本质差异。DIG 与同期 OneRec / OneRanker / GR4AD / TwiSTAR 等工业生成式系统的共同价值取向都是"统一两侧",但 DIG 是唯一一篇从 discriminative-first 角度出发 的工作——其他都是"先有生成式骨架、再缝合排序"。这一独特视角让 DIG 在保留判别式排序器已积累的工程优势(u2i 高阶交叉、DIN 用户历史 attention、MoE 多专家分支)的前提下获得生成式检索能力,部署成本远低于全栈 GR 系统。