Intent-Driven Semantic ID Generation for Grounded Conversational News Recommendation¶
1. 研究动机与背景¶
1.1 对话式新闻推荐的独特挑战¶
腾讯团队在主流中文新闻平台上构建 chat-based news assistant,通过自然语言对话提供个性化新闻推荐。与电影、商品等传统稳定类目推荐不同,新闻场景呈现出三个相互交织的结构性矛盾:
- 超短生命周期(Catalog Ephemerality):从生产数据观测,24 小时内大多数文章过期——日曝光中过去 24h 内发布的文章占绝对主导。这使得依赖稳定 item ID 或长期协同信号的推荐方法迅速失效。
- 冷启动普遍化(Cold-Start Ubiquity):不仅新用户冷启,即便是"老用户"在面对全新内容时也会变冷——20–30% 活跃用户在测试窗口内的交互少于 10 次。
- 隐式意图主导(Implicit Intent Dominance):作者从生产对话中提炼出 6 种意图类型,其中 5 种是隐式的(即用户 query 里不含可检索的关键词):
- Candidate Selection("recommend tech news",显式)
- Next-Item Continuation("what else?",隐式)
- Diversity Seeking("something different",隐式)
- Feedback Adjustment("not sports",隐式)
- Cold-Start PADR("recommend news"+稀疏历史,隐式)
- Pure Cold-Start("recommend news"+新用户,隐式)
Inter-annotator agreement 验证了该 taxonomy 的稳定性:Fleiss' κ=0.81(6-way 分类),二元显隐式分类 κ=0.91,均超过"几乎完美一致"的 0.81 阈值。
1.2 RAG 与 retrieve-first 范式的结构性瓶颈¶
传统对话推荐遵循 retrieve-then-generate 流水线:query $q$ 作为检索 key 拉取候选,再由 LLM 在候选上生成推荐。该范式在 5/6 隐式意图下结构性失败——query 中根本不存在可用于检索的关键词。即便使用 embedding-based 检索(如 BGE-large-zh),query 嵌入也缺乏意图特异性内容,dense retrieval 与 BM25 在隐式意图任务上几乎打平(Table 9:5 类隐式任务 Hit@1 普遍只有 9–11%,接近随机基线 10%)。
RAG : R(q) -> LLM(R(q), q) ... (1)
Ours: LLM(u, h, q) -> Match(SID, P)
构造可检索 query(如 LLM 重写)虽可缓解,但显著增加流水线复杂度,且对隐式意图("something different")依然力不从心。
1.3 现有生成式 SID 方案的局限¶
TIGER(Rajput et al., 2023)首创将 item 编码为 RQ-VAE 生成的层次化 Semantic ID 并自回归预测下一 SID,但假设稳定目录,与新闻日刷新场景天然不兼容;OneRec 系列(Zhou et al., 2025)证明了 SID 方案的工业可行性,OneRec-Think / ThinkRec 进一步引入显式推理。然而:
- 这些方案均面向单轮 next-item prediction,依赖丰富的行为序列;
- 对话场景下需要解决两个尚未触及的问题:(1) 从多样化对话意图(不仅是点击序列)生成 SID prefix;(2) 为缺少行为历史的冷启动用户进行推理。
1.4 本文核心思路:Generate-then-Match + Profile-Aware Dual-Signal Reasoning¶
提出 NewsRec-Chat,由两个核心组件组成:
- Intent-Driven Generate-then-Match:不再先检索后生成,而是直接由 LLM 从用户 profile $u$、历史 $h$、query $q$ 生成 3 层 SID prefix,再用 fuzzy matching 把生成的 prefix 落到当前新闻池 $\mathcal{P}$ 上:
$$\text{Match}(\text{SID}, \mathcal{P}) \subseteq \mathcal{P} \tag{2}$$
由结构上保证每条推荐都存在于实时新闻池中(架构级的 0% 幻觉)。
- Profile-Aware Dual-Signal Reasoning (PADR):自适应地路由 warm / hybrid / cold 三种推理路径,使仅有 profile 的用户也能产生有意义的推荐。
工业级 7B 模型(基于 Qwen2.5-7B-Instruct)在 152K 开放生成空间中取得 L1 Match 12.4%(随机 4× 提升)、幻觉率 0%,相对内部生产 baseline Hist-Pop(11.6%)显著提升 +0.8pp(p<0.05),冷启动用户 L1 达 18.0%(随机 6×),是所有用户组中最高的。
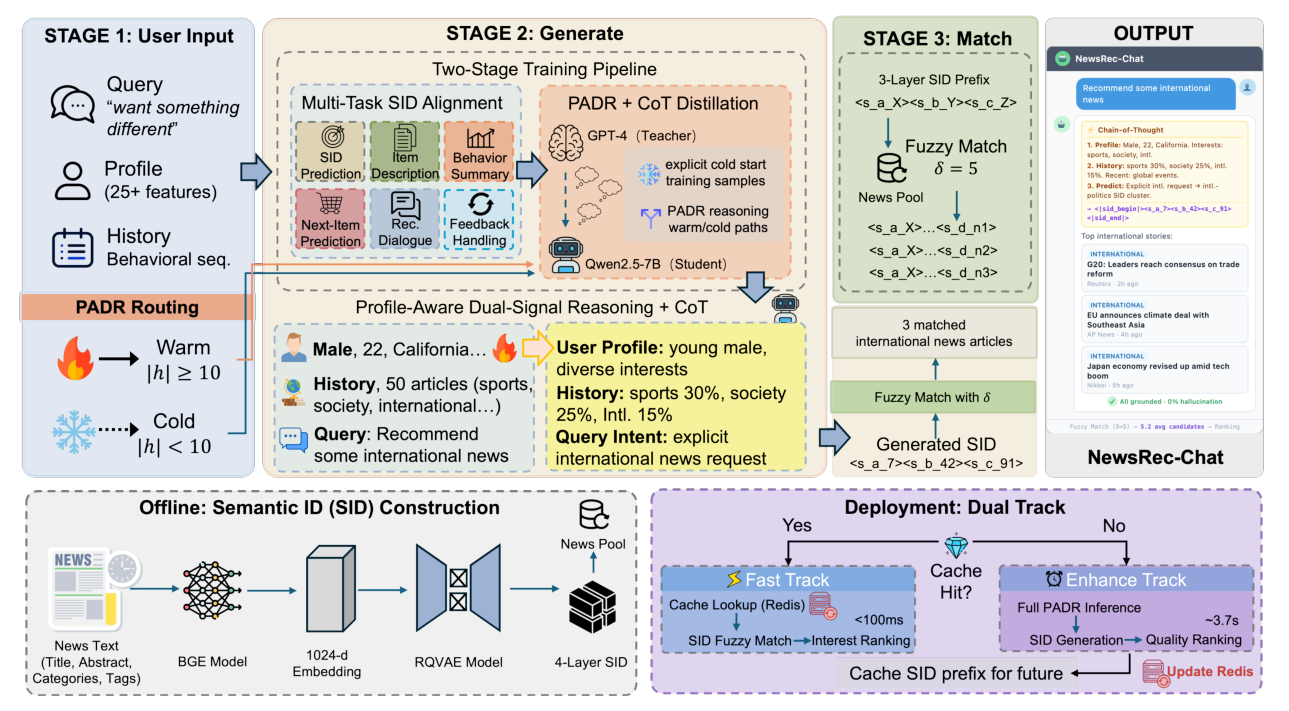
2. 核心方法¶
NewsRec-Chat 围绕三个子模块展开:(§3.1) Generate-then-Match 范式与新闻池落地保证;(§3.2) SID 结构与 fuzzy matching 算法;(§3.3) PADR 自适应推理路径;(§3.4) Dual-Track 工业部署架构。
2.1 Generate-then-Match:取代 retrieve-first¶
形式化地,传统 RAG 用 retrieval $\mathcal{R}(q)$ 拉取候选喂给 LLM;本方法颠倒为 generate-first:LLM 内化用户上下文 $(u, h, q)$,直接生成蕴含目标意图的结构化 SID,再用匹配函数提供池存在性保证:
$$\text{Match}(\text{SID}, \mathcal{P}) \subseteq \mathcal{P} \tag{2}$$
这把"是否能召回到目标"的难题转化成"模型能否在已有 SID 空间内生成靠近目标的 prefix"的生成问题。两个新挑战由此产生:(1) 多样化意图 → SID prefix 的语义映射要稳,(2) 生成的 prefix 要能落到动态刷新的新闻池中,分别由 §2.3(两阶段训练 + PADR)和 §2.2(fuzzy matching)解决。
2.2 4 层 SID 结构与 fuzzy matching¶
4 层 RQ-VAE 层次 SID。沿用 TIGER/OneRec 的设计,每篇文章离线编码为 4 层 SID
$$\text{SID} = \langle s_1, s_2, s_3, s_4 \rangle$$
由 BGE-large-zh(Xiao et al., 2024)生成 1024 维内容嵌入,经 RQ-VAE 量化为 $s_1 \in [0,31]$、$s_2 \in [0,63]$、$s_3 \in [0,127]$、$s_4 \in [0,1023]$ 的层次代码,编码 broad semantic regions → mid-level groups → fine-grained clusters → near-unique article identifier。码本占用率 >98%,152K 代码覆盖 163K 文章;1250 个特殊 SID token 加入 LLM 词表。
为何只生成 3 层 prefix? 第 4 层 $s_4$ 是近唯一的文章标识符,随每日内容池刷新而漂移;预测它会把模型耦合到具体某天的库存上。前 3 层捕捉意图级语义:共享 $(s_1, s_2, s_3)$ 的文章在主题上可互换,prefix 既能精确反映用户意图,又能跨池刷新保持稳定。
Fuzzy Matching 算法。生成的 prefix $P = (s_1, s_2, s_3)$ 与池中所有文章比对,容忍度 $\delta$:
$$\text{Match}(P, \mathcal{P}) = \{ n \in \mathcal{P} : s'_1 = s_1, s'_2 = s_2, |s'_3 - s_3| \leq \delta \} \tag{3}$$
其中 $(s'_1, s'_2, s'_3, s'_4)$ 是池中候选新闻的 SID。L1, L2 必须严格匹配以保留语义连贯性(相邻的 $s_1$ 或 $s_2$ 编码可能跨越不相关语义域,sports↔technology);L3 容忍 $\delta$,因为同一 $(s_1, s_2)$ 群内相邻代码共享细粒度主题相似性。在验证集上对 $\delta \in \{1, 3, 5, 7, 10\}$ 做网格搜索:
| $\delta$ | Hal. | 平均候选数 |
|---|---|---|
| 1 | 4.8% | 1.8 |
| 3 | 2.1% | 3.4 |
| 5 | 0% | 5.2 |
| 7 | 0% | 7.8 |
| 10 | 0% | 12.1 |
$\delta = 5$ 是实现 0% 幻觉的最小值,且候选集大小(mean 5.2,median 3.0)适合下游 ranking。
Algorithm 1: SID-Prefix Fuzzy Matching
Input : SID prefix P=(s1,s2,s3), news pool N, tolerance δ, top-k
Output: Ranked news list R
1 C ← ∅
2 foreach (n, sid_n) ∈ N do
3 (s'1, s'2, s'3, s'4) ← parse(sid_n)
4 if s'1 = s1 and s'2 = s2 and |s'3 - s3| ≤ δ then
5 score ← 1 - |s'3 - s3| / (δ + 1)
6 C ← C ∪ {(n, score)}
7 end
8 end
9 R ← TopK(C, k) by score
10 return R
2.3 两阶段训练流水线¶
模型从 Qwen2.5-7B-Instruct 全参数微调,含两个阶段。
Stage 1: Multi-Task SID Alignment (6 任务 × 483K 样本)
目标是建立 grounded 的 SID 词表,让 LLM 学会 SID 与自然语言、行为序列之间的双向映射。任务被划入 3 组:
| 任务组 | 任务 | 占比 |
|---|---|---|
| SID Understanding (36.2%) | 1. SID Prediction(title/category/tags → 4 层 SID) | 20.7% |
| 2. Item Description(SID → 新闻描述) | 15.5% | |
| User Modeling (10.4%) | 3. Behavior Summary | 5.2% |
| 4. Next Item Prediction | 5.2% | |
| Recommendation Dialogue (53.5%) | 5. Recommendation Dialogue | 48.3% |
| 6. Feedback Handling | 5.2% |
Token Warm-up:Stage 1 之前先冻结主干、单独训练 1250 个新 SID token 的 embedding 3 epoch,学习率 5e-4,让新 token 在融入混合训练前先具备有意义的初始表示。
预实验对比 显示,跳过 Stage 1 直接做 Stage 2 训练会导致 >60% 非 SID token 输出、>50% 幻觉率、L1 <3%——证明 SID 对齐对让模型先掌握 SID 语义至关重要。
Stage 2: PADR Chain-of-Thought Distillation (6 任务 × 48K 样本)
教 LLM 在生成 SID 之前显式推理应该走哪条信号路径。GPT-4 作为 teacher 为每个 (input, target SID) 对生成黄金 CoT 轨迹(Li et al., 2023; Magister et al., 2023),蒸馏到 student 7B 模型。三个关键设计:
- ~31% cold-start 样本:与生产冷启动率(20–30%)对齐;
- Intent-differentiated CoT:每种意图配独立推理结构(如 demographic → interest 用于 cold-start;preference-shift analysis 用于 feedback adjustment);
- Controlled CoT length(150–300 字符):防止推理在 inference 时退化(§4.5 详述)。
人类对 200 条采样 CoT 评分 4.1/5(Logical Coherence 4.2, Recommendation Consistency 4.0, Information Utilization 3.9, Length Compliance 4.5),inter-annotator agreement Krippendorff's α=0.72。
Stage 2 的 6 个训练任务(48,249 样本)按场景拆分:
| Task | 占比 | 输入 | 输出 |
|---|---|---|---|
| Next Item Prediction | 31.6% | profile + 浏览历史 + 目标新闻 | 解释 why 用户点击 → SID |
| Cold-Start PADR | 18.7% | profile + <5 交互 + 目标 | profile-focused 推理 → SID |
| Pure Cold-Start | 12.4% | profile only + 用户首次点击 | 纯 profile 推理 → SID |
| Candidate Selection | 18.7% | profile + 历史 + 5 候选(1 正 4 负) | 比较推理 → 选择 |
| Diversity Exploration | 12.4% | profile + 单一品类历史 + 多样目标 | 跨舒适区推荐的理由 |
| Feedback Adjustment | 6.2% | 上一轮推荐 + 负反馈 + 备选 | 反馈解读 + 兴趣映射调整 |
训练超参:Stage 1 学习率 2e-5、Stage 2 学习率 1e-5、3 epochs、batch size 1(per GPU)× 16 梯度累积 × 4 GPU = 64 effective、Max Seq 1536/2048、DeepSpeed ZeRO-2、4×H20-96G。
2.4 Profile-Aware Dual-Signal Reasoning (PADR)¶
冷启动用户(20–30% 活跃用户)缺乏行为历史。PADR 自适应利用 profile + 行为两路互补信号。
Dual-Signal 上下文构造。设用户 $u$ 有 profile $\mathbf{p}_u$(25+ 维特征:人口统计、长期兴趣、行为模式)与行为历史 $\mathbf{h}_u = [n_1, \ldots, n_t]$,LLM 输入根据历史长度切换:
$$ \mathbf{x}_u = \begin{cases} [\mathbf{p}_u; \mathbf{h}_u; q] & |\mathbf{h}_u| \geq \tau \quad (\text{warm}) \\ [\mathbf{p}_u; \mathbf{h}_u; q;\ \text{"sparse"}] & 0 \lt |\mathbf{h}_u| \lt \tau \quad (\text{hybrid}) \\ [\mathbf{p}_u; q;\ \text{"no history"}] & |\mathbf{h}_u| = 0 \quad (\text{cold}) \end{cases} \tag{4} $$
其中 $\tau = 10$ 是历史充足阈值。显式 availability indicator 引导模型选择正确推理策略,无需独立路由模块。
Learned Reasoning Paths(由 CoT 监督习得,不靠硬编码):
- Warm Path($|\mathbf{h}_u| \geq \tau$):Profile Analysis → Interest Mapping → Behavioral Correlation → SID Generation;
- Hybrid Path:Profile Analysis → Interest Inference → Sparse Behavioral Cross-Reference → SID Generation;
- Cold Path($|\mathbf{h}_u| = 0$):Profile Analysis → Interest Inference → Content Matching → SID Generation(pure cold-start 此路径 L1 18.0%)。
Profile 内容(Appendix T):25+ 特征覆盖人口统计(age/gender/city tier)、长期类目偏好(30/7 天阅读时长加权 Top-3)、行为模式(活跃时段、参与度)、内容格式偏好(视频 vs. 文本)、注册时声明的兴趣 tag。所有特征均来自时间分割截止点之前,测试集 item 发布于截止之后,作者审计确认零特征包含 article ID / SID / 测试期标题——冷启动优势非来自数据泄露。
2.5 Dual-Track 工业部署架构¶
完整 PADR 推理在实时对话中太慢。Fast Track(<100ms P95)走缓存:
- Cache Lookup(~5ms):用 $\text{ctx\_hash}$ 查 Redis;
- SID Matching(~50ms):cache hit 时用 Algorithm 1 把缓存的 prefix 落到当前池;
- Interest Ranking(~20ms):用兴趣对齐分($w_i = 3$ 类目级匹配,$w_i = 1$ 关键词级匹配,$\lambda = 0.1$ 平衡 relevance 与 recency)排序;
- Profile Fallback:候选 <3 时走 §J.1 多级回退级联。
Enhance Track(3.7s 平均)异步运行:完整 PADR 推理 → GPU 加速 SID Generator 输出 top-K SID → 重排候选 → 更新 Redis。
两个关键设计: 1. 缓存的 SID prefix 是池无关的(pool-agnostic),编码用户意图而非具体文章 ID,跨池每日刷新仍有效; 2. Enhance Track 通过 profile 推导出的 preference-based preset queries 主动生成 SID prefix,即便用户尚未发起对话也能保证推荐时新性。
Cache 条目结构:
$$\text{Entry} = \langle \text{ctx\_hash}, \{(s_1, s_2, s_3)\}_{k=1}^{K}, \text{reason}, \text{ts} \rangle \tag{5}$$
其中 $K = 10$ 个 SID prefix,自然语言 reason 用于可解释性,TTL 24 小时。
3. 实验¶
3.1 数据集与评测设置¶
数据集(Table 2):主流中文新闻平台真实数据,时间分割(training 用截止日前的新闻,test 用之后),零 item overlap:
| 数据 | 描述 | 规模 |
|---|---|---|
| News Pool | 带 SID 的文章 | 163,560 |
| User Profiles | 兴趣画像 | 50,000 |
| Stage 1 Training | SID 对齐 | 483,374 |
| Stage 2 Training | PADR 推理 | 48,249 |
| Test Samples | 6 种任务类型 | 9,982 |
主评测是 Open Generation(76% 测试数据):模型在 152K SID 全空间中生成 prefix,没有任何候选检索,最大限度排除负采样偏差。Candidate Selection(24%)用固定候选检验判别能力。
Metrics:
- Candidate Selection:Hit@1 under Rand(4 random negatives)/ Align(2 same-category + 2 random);
- Open Generation (152K 空间):L1 Match(32 类目,编辑级正确)、L2 Match(2048 主题)、Category Match(编辑分类对齐);
- Grounding:Hallucination Rate(生成 SID 不在当前池中的比例);
- System:average & P95 latency。
Baselines 涵盖 5 类:
- Non-Personalized:Random、Popular、Hist-Pop(生产 baseline,融合 30/7 天阅读时长加权 Top-3 类目 + 25+ 特征工程的 informed lookup);
- End-to-End LLM (no SID training):GPT-4 Direct、Qwen-7B Direct;
- Retrieve-then-Rank:BM25、Qwen-7B + (BM25/Dense/Hybrid) RAG、GPT-4 + (BM25/Dense/Hybrid) RAG;
- Generative Recommendation:TIGER、OneRec-7B(相同 Qwen2.5-7B backbone + LoRA + constrained SID decoding,确保 backbone-controlled 比较);
- Sequential Recommenders:SASRec、BERT4Rec。
3.2 主结果(Table 3)¶
| Method | Cand. Hit@1 Rand | Align | L1 | L2 | Cat. | Hal. |
|---|---|---|---|---|---|---|
| Random | 20.0 | 20.0 | 5.1 | 0.1 | 10.3 | — |
| Popular | 20.0 | 20.0 | 7.7 | 0.5 | 12.6 | — |
| Hist-Pop (prod) | — | — | 11.6 | 0.7 | 16.8 | — |
| Qwen-7B Direct | 28.1 | 26.0 | 2.4 | 0.0 | 6.9 | 70.0% |
| GPT-4 Direct | 34.4 | 30.9 | 0.9 | 0.0 | 1.4 | 94.6% |
| BM25 | 23.5 | 23.4 | 10.5 | 0.5 | 15.7 | 0% |
| Qwen-7B + BM25 RAG | 28.1 | 26.0 | 10.1 | 0.5 | 15.2 | 0% |
| Qwen-7B + Dense | 28.1 | 26.0 | 11.8 | 0.5 | 17.4 | 0% |
| Qwen-7B + Hybrid | 28.1 | 26.0 | 11.4 | 0.5 | 18.1 | 0% |
| GPT-4 + BM25 | 34.4 | 30.9 | 11.0 | 0.5 | 15.6 | 0% |
| GPT-4 + Dense | 34.4 | 30.9 | 11.8 | 0.3 | 18.3 | 0% |
| GPT-4 + Hybrid | 34.4 | 30.9 | 12.4 | 0.5 | 18.8 | 0% |
| NewsRec-Chat (Ours) | 59.3 | 30.8 | 12.4 | 1.0 | 20.0 | 0% |
(_下划线_表示 second-best,粗体表示 best)
三大发现: 1. SID 训练消除幻觉。未训练 SID 的 LLM(Qwen-7B Direct, GPT-4 Direct)有 70–95% 输出幻觉;本方法 0% 幻觉 + 12.4% L1(95% CI [11.7%, 13.2%]),在 152K 开放空间中 4× 随机,比生产 Hist-Pop 高 +0.8pp(p<0.05)。Hist-Pop 在冷启动用户(L1=0%)上完全失效,本方法 18.0%。 2. Generate-then-Match 超越检索与生成式双 baseline。L2 比 GPT-4+Hybrid RAG 高 2×(1.0 vs. 0.5),Category +1.2pp(20.0 vs. 18.8),且推理成本仅为 GPT-4 API 的 ~1/100(Table 10)。检索式方法在 76% 隐式意图任务上停留在随机基线(Table 9,Hit@1 9–11%)。OneRec-7B(同 backbone + LoRA + constrained decoding)冷启动 L1 16.1%,本方法 18.0%,且覆盖全部 6 种意图(Table 6)。 3. 双设定 candidate selection 验证鲁棒性。Rand 下 59.3% 大幅领先所有 baseline(p<0.01);更难的 Align(同类目硬负)下 30.8% 与 GPT-4 Direct(30.9%, p=0.94)持平,超 Qwen-7B Direct +4.8pp(p<0.01)。
3.3 系统性能与试点部署¶
Latency-Quality Trade-off(Figure 2):
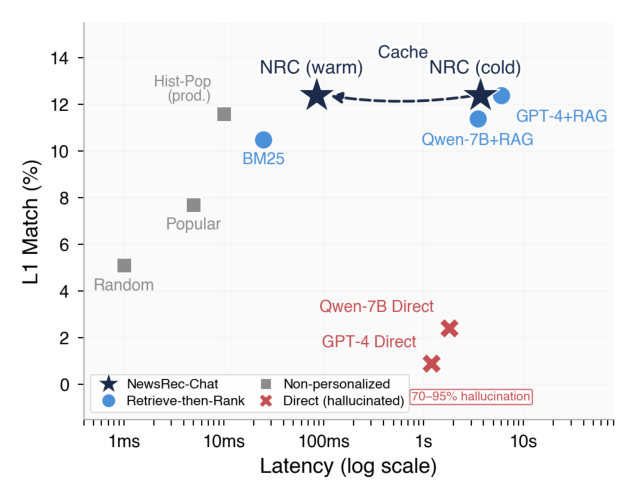
Dual-track 实现 85ms warm-start 平均延迟(P95 150ms),0% 幻觉。超 75% 请求命中缓存;冷启动用户首次 3.7s,后续 cache hit。SID 主通路($\delta = 5$)在 >95% 请求中返回非空候选,Level 2+ 回退用于 <5% 案例。
内部试点:38 天部署到主流中文新闻平台 300+ 内部用户,92 活跃用户 在 141 会话中产生 331 turn(58.9% multi-turn,22.8% return rate),系统在 29 类目下推荐 731 unique articles,零幻觉投诉,与离线 0% 幻觉率一致。内容编辑与产品经理的定性评估覆盖全部 6 种意图,肯定 cold-start 相关性与 multi-turn 优化收益。
3.4 消融实验(Table 4,Rand setting)¶
| Variant | Hit@1 | L1 | Hal. | Lat. |
|---|---|---|---|---|
| Full Model | 59.3 | 12.4 | 0% | 85ms |
| w/o Stage 2 (S1 only) | 51.6 | 8.9 | 18.4% | 0.67s |
| w/o Fuzzy Match | 59.3 | 12.4 | 5.7% | 85ms |
| w/o Dual-Track | 59.3 | 12.4 | 0% | 3.7s |
所有差异 p<0.01(除 w/o Fuzzy 在 Hit@1 上 p=1.0)。
关键结论:
- Stage 2 PADR 是最大贡献者(去除后 Hit@1 −7.7pp、L1 −3.5pp、幻觉飙至 18.4%),CoT 蒸馏对生成准确性与 grounding 纪律均不可或缺;
- Fuzzy matching 恢复 ~6% 的精确 prefix 匹配失败案例(Hal. 0%→5.7%),但本身不影响 L1/L2;
- Dual-Track 对生产延迟必不可少(85ms vs. 3.7s);
- 进一步分析 grounding layer(Appendix K)与 200 失败案例(Appendix S)确认 generation grounding 单独就消除了幻觉——matching 函数提供的池存在性保证(Eq. 2)是 0% 幻觉的本质源头,而非依赖回退机制。
3.5 任务粒度与冷启动分析(Table 5)¶
| Task Type | N | Metric | Qwen-7B | Ours |
|---|---|---|---|---|
| Conversational (LLM-exclusive) | ||||
| Cand. Sel. (Rand) | 2349 | Hit@1 | 28.1 | 59.3 |
| Cand. Sel. (Align) | 2349 | Hit@1 | 26.0 | 30.8 |
| Feedback Adj. | 621 | Hit@1 | 19.2 | 54.8 |
| Open Generation (152K SID 空间) | ||||
| Next-Item Pred. | 5319 | L1 | 3.4 | 12.0 |
| Cold-Start PADR | 611 | L1 | 0.2 | 11.1 |
| Diversity Expl. | 978 | L1 | 0.1 | 11.6 |
| Pure Cold-Start | 721 | L1 | 0.3 | 18.0 |
| Cold-Start Analysis (Open Gen. L1) | ||||
| Warm Tasks | 6300 | L1 | 2.9 | 11.9 |
| Cold Tasks | 1333 | L1 | 0.2 | 14.9 |
| Pure Cold (0 history) | 721 | L1 | 0.3 | 18.0 |
反直觉发现:Cold 任务 L1(14.9%)反而高于 Warm 任务(11.9%,p<0.05),Pure Cold-Start 达 18.0%。Appendix L 通过 distribution-corrected 分析(计算每组的 expected random L1 $E[\text{Rand}] = \sum_i p_i^2$)确认这并非来自类目分布集中:
| Group | N | Actual | E[Rand] | Adj. | Lift |
|---|---|---|---|---|---|
| Warm Tasks | 6300 | 11.9% | 6.9% | 5.0% | 1.72× |
| Cold Tasks | 1333 | 14.9% | 6.8% | 8.1% | 2.19× |
| Pure Cold | 721 | 18.0% | 7.3% | 10.8% | 2.48× |
调整后差距持续存在(cold 8.1% vs. warm 5.0%, +3.1pp)。两个机制共同造成: 1. Rich Profile Signals:profile 包含 30/7 天阅读时长加权类目 Top-3 + 25+ 工程化特征,即便 cold 用户也保留已积累的偏好摘要——比稀疏点击噪声更聚焦; 2. Search Space Narrowing:warm-path 推理需在大量行为上下文中 disambiguate 多个 plausible cluster(mean 6.8 L1 codes per profile);cold-path 把 focused profile 映射到更小的高概率 cluster 集合(mean 3.2),生成更易精确命中。
数据泄露审计(Appendix T)确认 cold 优势真实可信,不来自 profile 中混入 test-period 信息。
3.6 冷启动对比(Table 6)¶
| Method | Params | Cold L1 | Intents |
|---|---|---|---|
| SASRec | 1M | 0% | 1/6 |
| TIGER | 100M | 0% | 1/6 |
| OneRec-7B | 7B | 16.1% | 1/6 |
| NewsRec-Chat | 7B | 18.0% | 6/6 |
SASRec / TIGER 等序列方法完全失效于 0-history 用户;同 Qwen2.5-7B backbone 的 OneRec-7B(LoRA + constrained SID decoding)达 16.1%,本方法的 PADR profile-based reasoning 进一步推高到 18.0%,且唯一覆盖全部 6 种意图。
Cross-Category Generalization:在 29 个 editorial categories 上 L1=23.5%(CV=0.23),9 个 zero-shot categories(出现在测试但训练频次低)均值 L1=19.7%(4× random),训练频次与 L1 的 Spearman 相关 $\rho = 0.35, p = 0.055$,不显著——模型通过 SID alignment 捕捉 semantic category 结构而非记忆频次模式。
3.7 RAG 子分析(Table 9, 10)¶
按 query 类型拆分 BM25 RAG 表现:
| Task Type | GPT-4 | Qwen-7B |
|---|---|---|
| Explicit (retrievable keywords): | ||
| Candidate Sel. | 34.1 | 28.1 |
| Implicit (no retrievable keywords): | ||
| Next-Item Pred. | 11.0 | 10.1 |
| Diversity Expl. | 10.8 | 9.7 |
| Cold-Start PADR | 10.2 | 9.5 |
| Pure Cold-Start | 9.8 | 8.9 |
| Feedback Adj. | 10.5 | 9.3 |
5 类隐式任务全部聚集在 ~10% 随机基线附近——检索式方法无法在 implicit query 上 surface 相关文章。Dense retrieval(BGE-large-zh)vs. BM25 在 implicit 上几乎无差异,证明无论 query 构造策略多复杂(lexical/semantic/混合)都是同一结构性瓶颈:缺乏 query keyword 时检索没有抓手。这是本文 generate-first 设计的根本动机。
Multi-Dimensional Comparison vs. GPT-4+Hybrid RAG(Table 10):L1 持平(12.4% vs. 12.4%)但本方法 L2 翻倍(1.0 vs. 0.5, p<0.01)、Category +1.2pp、Cold L1 +4.7pp、Pure Cold L1 +8.2pp、推理成本 ~1/100。证明 L1 持平掩盖了细粒度优越性与冷启动决定性差异。
3.8 CoT 长度选择(Q.2)¶
| CoT 长度 | 推理质量 |
|---|---|
| <100 chars | 推理深度不够,L1 −1.8pp |
| 100–150 chars | 边际改善但仍浅 |
| 150–300 chars | 最佳 trade-off(profile→interest→SID 2–3 步) |
| >300 chars | 引入冗余,inference-time CoT 坍缩到 ~29 chars(vs. 150–300 训练时的 187 chars) |
Length distribution mismatch:训练时 CoT 太长,含冗余推理步,模型把"推理结束"信号关联到长度线索而非逻辑完成;inference 没有 teacher-forced 长上下文,过早触发 SID generation token。该发现与 Li et al. (2023) 的 CoT 蒸馏观察一致——distillation 需要 appropriately scoped 而非仅 correct 的 reasoning。
4. 与已归档相关工作的对比¶
OneRec-Think OneRec-Think (Kuaishou, 2025-10-13)¶
关系:显式引用但原文未展开对比(仅在 Related Work 提及,未给数值对比)· 已加载对方精读
- 共同关注的问题:如何把 LLM 的显式 CoT 推理能力注入到基于 hierarchical SID 的生成式推荐管道,让模型不仅产出 SID,还能解释为何产出这串 SID。两篇都识别出"直接 LLM 生成 SID"会幻觉、缺解释、依赖隐式预测的同一缺陷。
- 相近的技术骨架:(1) 两阶段训练:Stage 1 多任务 SID 对齐(让 LLM 学会 SID↔自然语言双向映射),Stage 2 CoT 训练;(2) Token Warm-up:冻结主干预训练新 SID embedding(NewsRec-Chat 3 epoch lr 5e-4;OneRec-Think 工业级 6B token);(3) teacher CoT 注入:NewsRec-Chat 用 GPT-4 蒸馏,OneRec-Think 用 pre-aligned 模型从剪枝上下文生成 rationale 再回灌;(4) 缓存解耦延迟:NewsRec-Chat 的 Dual-Track(Fast Cache + Enhance Async)≈ OneRec-Think 的 Think-Ahead(offline reasoning-guided prefix + online prefix-constrained finalization),都通过把昂贵推理移到离线、在线只做轻量匹配/约束解码实现 sub-100ms 服务。
- 本文的差异与推进:(1) 目标场景:OneRec-Think 仍是单轮 next-item 预测(Amazon Review + 快手短视频,稳定目录、丰富行为序列),NewsRec-Chat 直面多轮对话 + 24h 过期目录 + 6 种意图,5/6 意图隐式;(2) 冷启动方案:OneRec-Think 假设用户有足够行为,不为 zero-history 用户设计推理路径;NewsRec-Chat 的 PADR 显式定义 warm/hybrid/cold 三路径并用 31% cold-start CoT 训练样本覆盖(Pure Cold L1 18.0%);(3) 强化学习:OneRec-Think Stage 3 用 GRPO + Rollout-Beam reward 进一步对齐 beam search 与训练 reward;NewsRec-Chat 止步 SFT,无 RL;(4) 生成粒度与池落地:OneRec-Think 生成完整 4 层 SID + RL 在 beam 内寻优,假设 catalog 稳定;NewsRec-Chat 只生成 3 层 prefix(避免预测会日漂移的 $s_4$),再 fuzzy match(L1/L2 严格、L3 容忍 $\delta=5$)到当前池——这是为"ephemeral catalog"专门做的架构妥协。
- 可比的方法 / 实验差异:两者均报告了 SID 训练后 L1/L2 显著高于未训练 LLM;OneRec-Think 离线 R@10 在 Amazon Beauty/Sports/Toys 全面 SOTA,工业 A/B App Stay Time +0.159%;NewsRec-Chat 离线 L1 12.4%(152K SID 空间,4× 随机)、内部 pilot 38 天 0 投诉,但未做线上 A/B 对照——这是 NewsRec-Chat 在 Limitations 中承认的不足。两篇验证了"显式 CoT + SID 生成"路径在不同业务形态(短视频 vs. 新闻对话)下的鲁棒迁移性。
5. 核心贡献与讨论¶
5.1 核心贡献¶
- Intent-Driven Generate-then-Match 范式:通过 4 层 RQ-VAE SID + 3 层 prefix 生成 + L1/L2 严格 / L3 容忍 fuzzy matching,架构级保证 0% 幻觉——把幻觉从"训练目标 / 概率分布问题"转化为"码本词表约束问题"。
- PADR Profile-Aware Reasoning:覆盖 warm/hybrid/cold 三路径,唯一一个能处理 zero-history 用户的生成式 SID 推荐方法(cold L1 18.0%)。同时通过 distribution-corrected lift 与 data-leakage audit 证明 cold > warm 的反直觉结果真实可靠。
- 6 种对话意图分类法:从生产数据驱动地识别 5 种隐式意图(首次系统化),Fleiss' κ=0.81 验证一致性;为后续 CRS 研究提供可复用 taxonomy。
- Dual-Track 工业部署:85ms warm-start P95 150ms 端到端延迟,38 天内部 pilot 92 活跃用户 / 141 会话 / 0 幻觉投诉验证可行性。
- 结构化论证 retrieve-first 的局限:通过 Table 9 把"为何不要 retrieve-first"做成可量化结论——5/6 implicit intents 上 dense/BM25/hybrid 三种 RAG 全部停留在随机基线,结构性缺陷与 query 构造策略无关。
5.2 值得借鉴的设计¶
- 架构级保证 vs. 训练级保证:把"不幻觉"做成 fuzzy-match 集合约束(Eq. 2 + Algorithm 1),而非依赖 RL/post-hoc filter。这种"硬保证"对生产场景特别有价值,且不依赖外部知识库或人工 rules。
- 3 层 prefix 而非 4 层完整 SID:抓住 SID 层次中"语义 vs. 标识"分界点(前 3 层是 intent-level semantic,第 4 层是 instance-level identifier),刻意不预测 instance 层以避免与具体库存耦合——这个观点适用于所有 short-lifecycle 场景(短视频、闪购电商、直播)。
- CoT 长度训练-推理对齐:训练 CoT 太长 → 推理时坍缩到 29 chars 的失败模式(Q.2)是 distillation 中典型陷阱,本文 150–300 chars 的实证选择具有可借鉴的方法论价值。
- Profile-only cold-start outperforms warm:颠覆了"行为信号一定优于人口统计"的传统假设,揭示当 profile 是 well-engineered 长期摘要时,focused profile 比 noisy short history 反而更利于精确推理。
5.3 局限性与争议¶
- 缺线上 A/B 实验:仅内部 38 天 pilot,未对比生产基线的实际收益,Limitations 中已承认;
- GPT-4 CoT 蒸馏成本与依赖:~$850 训练时成本 + 对专有模型依赖,限制可复现性,本文 future work 提出用 DeepSeek-R1 / Qwen2.5-72B 等开源替代;
- SID 码本漂移:依赖 RQ-VAE 离线训练,需周期性重聚类(生产中每周 163K 文章重聚类一次),但模型生成的是语义意图 prefix 而非记忆索引,L1 codes 跨重聚类相对稳定;
- 12.4% L1 绝对值仍偏低:在 152K SID 全空间中预测难度大,partial matches 提供 topically 相关候选(mean 5.2 articles,53.6% 同 majority editorial category),但精确预测准确性 modest;
- Cross-domain 迁移未验证:架构设计为可迁移(SID codebook + profile schema 是平台特定模块,generate-then-match + PADR + fuzzy matching 是通用机制),适配新域需 ~2h GPU 重训 RQ-VAE 码本;但缺乏跨域实证。
5.4 工业落地价值¶
- 业务收益:相比生产 Hist-Pop baseline L1 +0.8pp(p<0.05),冷启动用户从 0% 提升到 18.0%——这部分用户在生产中此前完全无法被 informed 推荐;
- 成本优势:7B 模型单 GPU vs. GPT-4 API,推理成本 ~1/100,且 Fast Track 缓存命中率 >75% 进一步摊薄;
- 部署延迟:85ms 平均 / 150ms P95,符合对话场景的实时性要求;
- 可扩展性:3-layer prefix 缓存 pool-agnostic,跨日内容刷新无需失效;
- 可解释性:每条缓存条目含自然语言 reason,便于运营审计与可解释推荐。