LASAR: Latent Adaptive Semantic Aligned Reasoning for Generative Recommendation¶
作者:Yiwen Chen¹², Fuwei Zhang¹(通讯), Zehao Chen¹, Deqing Wang¹, Hehan Li², Peizhi Xu², Hanmeng Liu², Shuanglong Li², Xin Pei², Fuzhen Zhuang¹⁺†, Zhao Zhang¹
¹ 北京航空航天大学人工智能学院 · ² Baidu
ArXiv:2605.10207 · 2026-05-11 · Preprint
1. 研究动机与背景¶
近两年生成式推荐 (Generative Recommendation) 沿"LLM + Semantic ID (SID)"路线快速演化:P5、M6-Rec 奠基统一的"推荐即语言生成"范式;TIGER 把 item 量化为 hierarchical SID 做 generative retrieval;LC-Rec 在 LLM 词表里融入 collaborative SID;MiniOneRec 提供了首个完整开源的 LLM 生成式推荐 SFT+RL 后训练框架。与此同时,LLM 通用领域里"显式推理"(Chain-of-Thought, CoT)成为标配——但 CoT 在 token 空间逐字生成,对延迟敏感的推荐系统是致命的。GREAM 把 CoT 引入生成式推荐,确实改善了部分指标,但 (a) 推理时延暴涨;(b) 文本生成与协同过滤目标存在 mode 竞争——其作者自己的消融显示 SRPO 微调会让 Direct 推荐指标下降 5.3%(Instruments)。
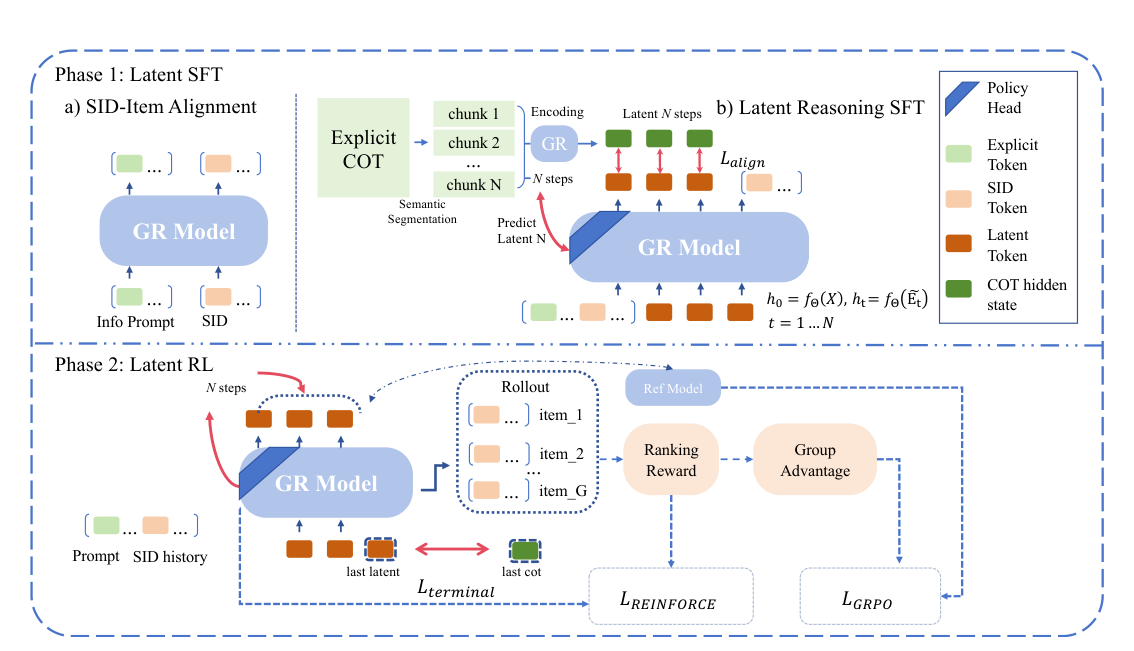
为绕开 token-by-token 的延迟瓶颈,Coconut 系列工作把 LLM 推理迁到 连续 latent 空间:把上一步最末 transformer 层的 hidden state 直接当作下一步的 input embedding,递归 N 次,不产出任何离散 token。后续 Looped Transformers、Huginn、CODI、SoftCoT 从不同角度推广这一范式,在数学/逻辑推理任务上以更低代价获得更强推理能力。
一个自然的问题随之浮现:这种 latent reasoning 范式能否迁移到生成式推荐? 作者梳理后发现交叉极少。传统判别式推荐侧的 ReaRec、LARES 在 ID-embedding ranking 范式里做过递归 latent 推理,但与 decoder-only generative 范式技术路线不同;生成式推荐侧 GREAM 等始终走显式 CoT;少数尝试 (LatentR³, S²GR) 要么用浅层单步注意力,要么本质是插入若干 token 而非"真正"的递归 hidden-state feedback loop。因此 LASAR 自我定位为 第一篇在主流生成式推荐里实现完整 Coconut 风格 latent reasoning(recurrent hidden-state feedback loop) + 自适应步长控制的工作。
但作者实测发现,"把 Coconut 直接搬到 SID 上"不是免费午餐,反而显著掉点。三个独有挑战如下:
- Semantic grounding gap(语义锚定缺口):NLP token 自带语言预训练语义先验,可作为 latent reasoning 的稳定基底;SID 则是从零构造的全新符号系统。把 SID 学习和 latent reasoning 同时 joint train,等于让模型既要建立符号 grounding 又要在连续空间推理,两个目标互相干扰,导致优化塌陷(loss 不下降,反而加大学习率收敛更慢,见 Figure 3)。
- Representation drift(表征漂移):推荐里没有"标准推理过程"作为 ground truth,直接引入 latent reasoning 而不加约束,hidden state 会在连续空间随机漂往无意义方向;而简单加 latent loop 又只能带来近乎为 0 的提升(Table 2 显示 +0.4% NDCG@10)。
- Inflexible fixed-step reasoning(推理步长固定):Coconut 与 ReaRec 都用全局固定步数 K,等于把同样深度的推理给所有用户。但用户行为复杂度差异大——简单浏览历史只需浅推理,复杂多兴趣序列则需要深推理。
针对这三个挑战,LASAR 设计了一个 SFT-then-RL 的训练框架:
- 两阶段解耦 (Stage 1:SID alignment → Stage 2:latent loop) 解决 grounding gap;
- Stepwise bidirectional KL 对齐 把每个 latent 步的 hidden state 锚定到对应"explicit CoT 段"的 hidden state,解决表征漂移;
- Policy Head + REINFORCE 在 RL 阶段动态决定每个样本的推理步数 N。
在 Beauty / Instruments / Sports 三个 Amazon 公开数据集上 LASAR 在几乎所有 metric-dataset 组合上达到 SOTA;推理时仅多几十毫秒,比生成显式 CoT 文本快约 20×。
2. 问题定义与符号¶
设 item 集合 $\mathcal{I}$,每个 item 关联文本特征。给定用户历史交互序列 $\mathcal{S} = \{i_1, i_2, \ldots, i_t\}$,目标是预测 $i_{t+1}$。
Item Tokenization:用 Residual Quantization K-Means pipeline 把每个 item 映射为长度 $M$ 的 hierarchical SID:
$$\mathrm{SID}(i) = Q(\mathbf{e}_i) = (s_1, s_2, \ldots, s_M), \quad s_j \in \mathcal{C}^{(j)} \tag{1}$$
每个 codebook size $|\mathcal{C}^{(j)}|=256$,本文 $M=4$,即每个 item = 4 个 special token。SID token 加入 LLM 词表。
生成式推荐 = 条件序列生成:构造输入序列
$$X = [\mathrm{text}_{nl}, \mathrm{SID}(i_1), \mathrm{SID}(i_2), \ldots, \mathrm{SID}(i_t)]$$
自回归生成目标 $\mathbf{Y}=\mathrm{SID}(i_{t+1})$:
$$p(\mathbf{Y} \mid X; \Theta) = \prod_{k=1}^M p(y_k \mid X, y_1, \ldots, y_{k-1}; \Theta). \tag{2}$$
LASAR 的核心创新在于 $\Theta$(backbone)的 latent reasoning 设计。
3. 核心方法¶
3.1 Latent Reasoning Mechanism¶
Latent token 设计:在 prompt 与 answer 之间插入三类 special token:<s> (start)、<t> (thought, 重复 $N$ 次)、<e> (end)。完整模板:
$$\texttt{[Prompt] \lt s\gt \lt t\gt }\times N\texttt{ \lt e\gt [Answer]}$$
不同于 Coconut / ReaRec 的全局固定 $K$,LASAR 的 $N$ 由 Policy Head 按样本预测,因此每个样本拥有独立的推理深度。
Recurrent latent loop:令 $h_0\in\mathbb{R}^D$ 为 prompt 末尾的最末层 hidden state。Latent reasoning 迭代:
$$h_0 = f_\Theta(X), \quad h_t = f_\Theta(\tilde E_t), \quad t = 1, \ldots, N, \tag{3}$$
其中 $\tilde E_t = [E_X, h_0, h_1, \ldots, h_{t-1}]$ 是把后续位置的 input embedding 替换成上一步 hidden state 的扩展输入。完成 $N$ 轮迭代后,从 $h_N$ 开始复用前缀 KV cache 自回归生成 answer。这是 Coconut 范式在生成式推荐里的首次完整实现——中间状态完全不可观测,模型在 dense vector 空间反复精炼推理。
Adaptive Step Allocation via Policy Head:用一个两层 MLP $\pi_\phi(\cdot \mid h_0)$ 读取 prompt 最末 hidden state,预测每样本的步数 $N$:
$$\pi_\phi(\cdot \mid h_0) = \mathrm{Softmax}\bigl(W_2 \cdot \tanh(W_1 \cdot h_0 + b_1) + b_2\bigr)$$
输出维度 $N_{\max}=8$(最大推理步数)。SFT 阶段取 $N = \arg\max$,监督标签是 Step 3.2 里 CoT 切段后的段数;RL 阶段切到采样 $N \sim \pi_\phi$,用 REINFORCE 优化。关键设计:在 latent loop 之前就预测出 N,使整批样本同 prompt 共享同一 N,简化 batch beam search 的计算图。
Batch-Efficient Variable-N Processing:可变 N 在 batch 内会导致 latent 区域长度参差。LASAR 用 padding + masking 让所有样本走 $\max(N)$ 轮 latent loop,短 N 样本超出步数的 latent 位置 attention mask 置 0,loss mask 也排除,无需 per-sample 分支即可保持 GPU full parallelism(详见 Appendix E.1)。
3.2 SFT Phase:Building Semantically Anchored Latent Reasoning¶
3.2.1 Two-Stage Decoupling(解决 Challenge 1)¶
作者用一个 simple-yet-decisive 的对照实验佐证"语义 grounding 是必须先做的事"。Figure 3 展示了 Beauty 上混合训练 vs 两阶段解耦的收敛对比:
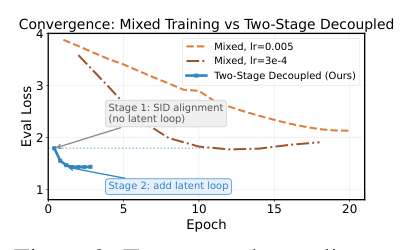
Stage 1:模型仅学"按 SID 生成下一个 item",用 cross-entropy loss 把 SID 符号系统建立起来;这一阶段不含 latent reasoning。 Stage 2:在 Stage 1 finalized 的基础上 warm-start,开启 latent loop + 后续所有损失项。
效果:训练时间从 20+ 小时缩到约 4 小时(4 epochs),Eval Loss 由 1.79 收敛到 1.44。"反直觉地加大 lr 反而更慢"这个观察非常有意义——它证明 grounding 与 reasoning 这两个目标在共优化下会主动互相干扰,不是单纯的容量不足;预先解耦才是正确解药。
3.2.2 Explicit CoT Anchor Construction¶
为了给 latent reasoning 提供"参考轨迹",LASAR 引入 explicit CoT 锚点——但 CoT 文本只在 SFT 训练时作为对齐 anchor,推理时永远不解码 CoT。流程:
- 教师 CoT 生成:用大模型(GPT-5)按 GREAM 的 5 阶段结构化推理链格式(behavioral evidence extraction → latent preference modeling → intent inference → recommendation formulation → denoised sequence rewriting)为每条训练样本生成 CoT 文本。Appendix E.2 给出 Beauty 域一个完整 case:
Step 1 - Behavioral Evidence:用户买过 hydrating serum, facial oils, eye gel, anti-aging moisturizer,强烈倾向 anti-aging 和 deep hydration;偏好天然/有机/冷压未精炼油;非油腻配方。 Step 2 - Latent Preferences:偏好 multi-benefit anti-aging 产品;轻盈快吸收质地;倾向大容量/长效产品。 Step 3 - Intent:用户在构建完整 anti-aging+hydration routine,下一步缺一款温和、天然 cleanser,含舒缓植物成分和透明质酸。 → Recommendation:
<|a_125|><|b_109|><|c_135|><|d_125|>
- 语义切段:用
BAAI/bge-small-en-v1.5embedding 模型把 CoT 文本切成若干语义连贯段(每段对应一个"推理步")。段数即 Policy Head 的监督标签 $N$。 - 离线锚点提取:把每个段单独喂回同一个 backbone(在训练前 offline 完成),取最后一个 token 在最后一层 transformer 的 hidden state 作为该段的 anchor $h_t^{cot}$。
这与 CODI 的 self-distillation 思路相近,但 CODI 用 L1 loss 仅对齐 answer 位置的单 token,LASAR 对齐每个 latent step与对应 CoT 段,并用 bidirectional KL 保留分布形状信息。
3.2.3 Stepwise Bidirectional KL Alignment¶
每个 latent step 的 hidden state $h_t$ 与对应 CoT 段 anchor $h_t^{cot}$ 用对称 KL 对齐:
$$\mathcal{L}_{\text{align}} = \frac{1}{N} \sum_{t=1}^{N} D_{\text{KL}}^{\text{bidir}}(h_t, h_t^{cot}), \tag{4}$$
其中
$$D_{\text{KL}}^{\text{bidir}}(a, b) = \tfrac{1}{2}\bigl(D_{\text{KL}}(\mathrm{Softmax}(a)\Vert \mathrm{Softmax}(b)) + D_{\text{KL}}(\mathrm{Softmax}(b)\Vert\mathrm{Softmax}(a))\bigr).$$
为何 bidir KL 而非 cosine / MSE?后续消融(Table 2)会显示 cosine、MSE 不仅没收益,还使 NDCG@10 比 no-alignment 更差(MSE 直降 11.6%);bidir KL 是唯一带正收益的对齐方式。物理含义:KL 关心分布形状,cosine 只关心方向,MSE 强行拉绝对值——hidden state 在 LLM 内部的语义信息更多藏在 logit 分布中而非欧氏距离。
3.2.4 SFT Total Loss¶
$$\mathcal{L}_{\text{SFT}} = \mathcal{L}_{\text{CE}} + \alpha_{\text{align}} \cdot \mathcal{L}_{\text{align}} + \beta_{\text{policy}} \cdot \mathcal{L}_{\text{policy}}$$
其中 $\mathcal{L}_{\text{CE}}$ 是 answer SID 的 cross-entropy(仅对 answer 区域计算),$\mathcal{L}_{\text{policy}}$ 是 Policy Head 预测 $N$ 的 CE loss。
3.3 RL Phase:Joint Quality and Efficiency Optimization¶
3.3.1 GRPO — Generation Quality(Challenge 3 的第一支柱)¶
对每个 prompt beam-search $G$ 个候选;reward 兼顾 hit 与排序:
$$r_{\text{rule}}^{(i)} = \begin{cases}1 & \hat y^{(i)} = y^* \\ 0 & \text{else}\end{cases} \tag{9}$$
$$r_{\text{NDCG}}^{(i)} = \begin{cases}0 & \hat y^{(i)} = y^* \\ \dfrac{-1/\log_2(i+2)}{\sum_{j=1}^{G} w_j} & \text{else}\end{cases} \tag{10}$$
总 reward $r = r_{\text{rule}} + r_{\text{NDCG}}$。$r_{\text{NDCG}}$ 用 ranking-position penalty 惩罚靠前位置错误候选,强迫 ground truth 上浮。GRPO 主目标(clipped):
$$\mathcal{L}_{\text{GRPO}} = -\mathbb{E}\bigl[\min(\rho_i(\Theta)\hat A_i,\, \mathrm{clip}(\rho_i(\Theta), 1-\varepsilon, 1+\varepsilon)\hat A_i)\bigr] + \beta D_{\text{KL}}(\pi_\Theta \Vert \pi_{\text{ref}}) \tag{5}$$
$\rho_i = \pi_\Theta(y_i|x)/\pi_{\text{ref}}(y_i|x)$,$\hat A_i = (r_i - \mathrm{mean})/\mathrm{std}$ 为组内归一化优势。
3.3.2 REINFORCE — Adaptive Step Optimization(Challenge 3 的第二支柱)¶
SFT 给了 Policy Head 一个"按 CoT 段数预测 N"的 warm-start,但 CoT 段数由切段粒度决定,不一定对应最优推理深度。RL 阶段切换到 sampling $N \sim \pi_\phi$,用 REINFORCE 直接以推荐质量为信号微调 Policy Head:
$$\mathcal{L}_{\text{REINFORCE}} = -\mathbb{E}_{N\sim\pi_\phi}\bigl[(R_{\text{group}} - b_{\text{EMA}} - \lambda N) \cdot \log \pi_\phi(N \mid h_0)\bigr] - \eta\, H(\pi_\phi) \tag{6}$$
- $R_{\text{group}}$:组内平均 reward;
- $b_{\text{EMA}}$:reward 指数滑动均值(方差缩减 baseline);
- $\lambda N$:latent step penalty,鼓励压缩推理深度(默认 $\lambda \in \{1, 5, 10\}\times 10^{-4}$);
- $\eta H(\pi_\phi)$:熵正则,防止分布退化为 single-step。
从 argmax 切到 sampling 是关键——argmax 等价于 SFT 推断,无法探索;sampling 才能让 Policy Head 实测不同 N 对应的 reward 差异。同时 SFT 提供的 warm-start 让初始采样在合理区域,比从零探索效率高得多。
3.3.3 Terminal KL — Semantic Alignment for Variable-Length¶
RL 阶段 N 是动态采样的——SFT 阶段那种"每步对齐固定 CoT 段"的策略不再适用(因为 RL 时 N 可能与 CoT 段数不等)。LASAR 改为只对齐最后一个 latent step到 explicit CoT 最后一段的 hidden state:
$$\mathcal{L}_{\text{Terminal KL}} = D_{\text{KL}}^{\text{bidir}}(h_N, h_{\text{final}}^{cot})$$
这保证 RL 优化推理深度时,推理"终点"始终落在正确语义轨迹上。Terminal KL 不能 fold 进 reward——因为 GRPO 组内 zero-mean advantage 会让常数项被抵消;必须以直接 loss 形式加入。
3.3.4 RL Total Loss¶
$$\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{GRPO}} + \gamma_{\text{KL}}\cdot \mathcal{L}_{\text{Terminal KL}} + \gamma_{\text{RF}}\cdot \mathcal{L}_{\text{REINFORCE}}$$
三个分量职责清晰:GRPO 管生成质量、Terminal KL 管语义一致性、REINFORCE 管推理效率。后续消融会显示三者全部不可缺。
4. 实验设置¶
4.1 数据集¶
三个 Amazon Product Review 子集(5-core filtering, leave-one-out evaluation):
| Dataset | #Users | #Items | #Interactions | Sparsity |
|---|---|---|---|---|
| Beauty | 22,363 | 12,101 | 176,139 | 99.935% |
| Instruments | 24,772 | 9,922 | 74,316 | 99.970% |
| Sports | 35,598 | 18,357 | 106,794 | 99.984% |
Sports 最稀疏,Beauty 最密。
4.2 Baselines¶
6 个 baseline 覆盖 4 大类:
- 传统序列模型:SASRec, GRU4Rec
- LLM-based 生成式:LC-Rec, MiniOneRec
- Latent reasoning:ReaRec
- 显式 CoT 推理:GREAM(保留其 CoT 链,简化为 MiniOneRec prompt template;采用其最强配置 "CoT SFT + direct answer inference",记作 Explicit CoT_GREAM)
所有生成式 baseline 共享相同 base model(Qwen3-0.6B)、prompt 模板、训练数据,差异仅来自推理机制。
4.3 评估指标 & 实现细节¶
- 指标:HR@K, NDCG@K, $K \in \{5, 10, 20\}$;beam width = 50;trie-constrained decoding 保证生成合法 SID。
- 优化器:AdamW;batch=512;max seq len=512;cosine LR with 0.08 warmup。
- Stage 1:lr $5\times 10^{-4}$, 10 epochs;Stage 2:lr $5\times 10^{-5}$, 20 epochs, early stopping。
- RL:lr $1\times 10^{-5}$, $G=8$, KL $\beta = 10^{-3}$, reinforce penalty $\lambda \in \{0.0001, 0.0005, 0.001\}$, terminal KL weight $\gamma_{\text{KL}} = 10^{-5}$。
- $N_{\max}=8$(最大推理步数),$M=4$(每 item 4 个 SID token)。
- Teacher CoT 由 GPT-5 生成;语义分段用
BAAI/bge-small-en-v1.5。 - 8×L40 (48GB)。
5. 实验结果¶
5.1 Main Results (RQ1)¶
Table 1 是三数据集 × 6 指标的完整 baseline 对比:
| Dataset | Model | N@5 | N@10 | N@20 | HR@5 | HR@10 | HR@20 |
|---|---|---|---|---|---|---|---|
| Sports | LASAR | 0.0121 | 0.0152 | 0.0188 | 0.0185 | 0.0280 | 0.0425 |
| Explicit CoT_GREAM | 0.0089 | 0.0118 | 0.0153 | 0.0138 | 0.0228 | 0.0370 | |
| MiniOneRec | 0.0099 | 0.0126 | 0.0152 | 0.0155 | 0.0237 | 0.0339 | |
| ReaRec | 0.0086 | 0.0112 | 0.0143 | 0.0151 | 0.0233 | 0.0355 | |
| LC-Rec | 0.0081 | 0.0100 | 0.0118 | 0.0123 | 0.0184 | 0.0254 | |
| GRU4Rec | 0.0062 | 0.0080 | 0.0101 | 0.0090 | 0.0147 | 0.0232 | |
| SASRec | 0.0060 | 0.0074 | 0.0094 | 0.0089 | 0.0132 | 0.0212 | |
| Instruments | LASAR | 0.0612 | 0.0667 | 0.0730 | 0.0763 | 0.0937 | 0.1184 |
| Explicit CoT_GREAM | 0.0574 | 0.0621 | 0.0674 | 0.0703 | 0.0850 | 0.1060 | |
| MiniOneRec | 0.0604 | 0.0640 | 0.0677 | 0.0715 | 0.0826 | 0.0974 | |
| ReaRec | 0.0494 | 0.0548 | 0.0604 | 0.0705 | 0.0873 | 0.1095 | |
| LC-Rec | 0.0533 | 0.0561 | 0.0587 | 0.0616 | 0.0701 | 0.0803 | |
| SASRec | 0.0449 | 0.0475 | 0.0502 | 0.0536 | 0.0617 | 0.0725 | |
| GRU4Rec | 0.0422 | 0.0454 | 0.0489 | 0.0527 | 0.0629 | 0.0769 | |
| Beauty | LASAR | 0.0239 | 0.0303 | 0.0366 | 0.0365 | 0.0563 | 0.0813 |
| Explicit CoT_GREAM | 0.0228 | 0.0293 | 0.0365 | 0.0351 | 0.0553 | 0.0837 | |
| MiniOneRec | 0.0232 | 0.0295 | 0.0358 | 0.0352 | 0.0542 | 0.0795 | |
| ReaRec | 0.0201 | 0.0255 | 0.0307 | 0.0296 | 0.0464 | 0.0673 | |
| LC-Rec | 0.0178 | 0.0222 | 0.0261 | 0.0260 | 0.0407 | 0.0592 | |
| SASRec | 0.0159 | 0.0195 | 0.0229 | 0.0232 | 0.0343 | 0.0480 | |
| GRU4Rec | 0.0144 | 0.0190 | 0.0242 | 0.0226 | 0.0370 | 0.0573 |
关键观察:
- LASAR 在 21 / 22 组合上拿第一,唯一例外是 Beauty HR@20(被 Explicit CoT_GREAM 以 0.0837 vs 0.0813 略胜——recall 范围越宽,显式 CoT 长尾覆盖能力越显著)。
- 越稀疏,latent reasoning 增益越大:Sports(99.984% sparse)上 LASAR vs MiniOneRec 在 N@10 上 +20.6%(0.0152 vs 0.0126),Beauty 上仅 +2.7%。稀疏域里协同信号有限,模型需要更强的"语义推理"来补全,正是 latent reasoning 的强项。
- latent reasoning 始终强于 direct generation 与 explicit CoT:作者归因为"显式 CoT 创造了 LM 解码与协同过滤目标的 mode 冲突——离散 token 推理会拖累 SID 生成本身;latent reasoning 完全在连续向量空间进行,不打扰 SID 头的语言建模"。
- Bootstrap test 显示 Sports / Instruments 上 $p\lt 0.05$,Beauty 上 $p\lt 0.1$ 边缘显著。
5.2 Ablation Studies (RQ2)¶
5.2.1 SFT Phase Ablation(Table 2,Beauty)¶
| Model | Two-Stage | Latent | Alignment | N@5 | N@10 | HR@5 | HR@10 | ΔN@10 |
|---|---|---|---|---|---|---|---|---|
| Pure SFT (MiniOneRec) | — | 0.0212 | 0.0277 | 0.0329 | 0.0531 | – | ||
| + Latent (w/o align.) | ✓ | ✓ | None | 0.0207 | 0.0278 | 0.0327 | 0.0550 | +0.4% |
| + KL Alignment | ✓ | ✓ | KL | 0.0217 | 0.0285 | 0.0340 | 0.0552 | +2.9% |
| + Cosine Alignment | ✓ | ✓ | Cosine | 0.0211 | 0.0277 | 0.0341 | 0.0543 | 0.0% |
| + MSE Alignment | ✓ | ✓ | MSE | 0.0187 | 0.0245 | 0.0295 | 0.0477 | −11.6% |
结论:
- 不带 alignment 单加 latent loop,N@10 几乎不动 (+0.4%),证明 latent reasoning 不是 free improvement——必须配语义锚定。
- 三种对齐方式里只有 bidir KL 带正收益,cosine 持平、MSE 反而塌方 -11.6%。说明 KL 在保留分布形状信息上是 critical 的,欧氏几何或方向几何都不够;
- Appendix G 在 Sports / Instruments 上重复实验,结论一致:KL 是 dataset-agnostic 的正确选择。
5.2.2 RL Phase Ablation(Table 3,Beauty)¶
| Model | Latent | Terminal KL | REINFORCE | N@5 | N@10 | HR@5 | HR@10 | Mean N | ΔN@10 |
|---|---|---|---|---|---|---|---|---|---|
| MiniOneRec | – | – | – | 0.0232 | 0.0295 | 0.0352 | 0.0533 | – | – |
| RL w/ latent reasoning | ✓ | 0.0227 | 0.0287 | 0.0346 | 0.0533 | 3.59 | −2.7% | ||
| + Terminal KL Alignment | ✓ | ✓ | 0.0233 | 0.0294 | 0.0353 | 0.0543 | 4.20 | +2.4% | |
| + REINFORCE (LASAR) | ✓ | ✓ | ✓ | 0.0239 | 0.0303 | 0.0365 | 0.0563 | 2.47 | +3.1% |
关键发现(与 SFT 消融形成对称结论):
- 裸 RL+latent reasoning 反而掉点 -2.7%:再次验证"无约束 latent reasoning 必然漂移"——SFT 阶段的现象在 RL 阶段更严重,因为 GRPO 没有任何机制阻止 hidden state 偏离语义轨迹。
- 加上 Terminal KL 恢复语义锚定,N@10 +2.4%;但 Mean N 从 3.59 升到 4.20(KL 让 alignment 起效,模型开始倾向多用推理深度)。
- 再加 REINFORCE step penalty,Mean N 从 4.20 降到 2.47(压缩 41%),同时 N@10 进一步上升到 +3.1%。这是"step compression 与 quality improvement 同时发生",强力支持 adaptive step allocation 的设计。
5.3 Step Optimization Analysis (RQ3)¶
Force-N 实验:固定 N vs 自适应 N(Figure 4a, Sports)¶
把所有样本强制走相同 N(=1, 2, 3, 4),与 adaptive 对比:
- Force-N=1:HR@10 表现 OK(保持 representation 不受多余 latent 干扰);
- Force-N=4:HR@10 反而最差 (1.93%)——把简单样本也推 4 步,引入无用推理干扰;
- Adaptive (LASAR):HR@10 = 2.80%,超过所有固定 N。
RL 训练动力学(Figure 5a, Sports)¶
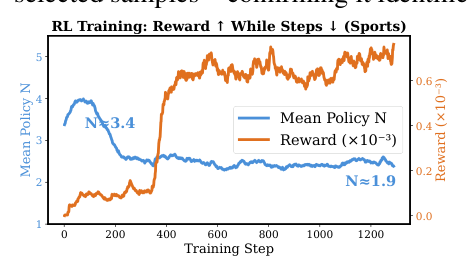
Mean N 从 ~3.4 早期急降到 ~1.9 并稳定下来;同时 Reward 持续上升——REINFORCE 压低了平均推理深度而没牺牲(反而提升了)质量。
Per-N HR@10 分布(Figure 5b, Sports)¶
把测试样本按 Policy Head 输出的 N 分桶后看 HR@10:
- $N \leq 4$ 桶里大多数样本 HR@10 接近 adaptive 平均 (2.80%);
- $N \geq 7$ 桶里 HR@10 显著更高(最难的样本受益于深推理);
- 中间 $N=5, 6$ 桶样本反而偏少且 HR 偏低(既不算 efficient 也不算 thorough,少数样本中间态)。
重要结论:Force-N=4 的最差结果 (1.93%) 与 Policy Head 在 N=4 桶的 3.38% 形成鲜明对比——可见 Policy Head 不是简单地把 N=4 用得"多",而是学会了哪些样本真正需要深推理。这点对未来 inference-time compute scaling 设计是一个有力佐证。
SFT vs RL 的 N 分布漂移(Figure 4b)¶
- SFT 后:99.7% 样本集中在 N=3, 4(被 CoT 切段数主导,Sports 域 83.4% 样本恰好 3 段、16.3% 是 4 段);
- RL 后:分布拓展到 N=1–8 全覆盖,Mean N=2.47。
RL 通过 reward-guided exploration 推翻了 SFT 标签的 segmentation 偏置,重新发现了"教师 CoT 段数"与"真正需要的推理深度"之间的差距。
5.4 Inference Efficiency and Model Scaling (RQ4)¶
推理效率(Table 4,beam width=50, 8×L40)¶
| Dataset | Method | Time/Sample | Total Time |
|---|---|---|---|
| Beauty | MiniOneRec | 0.27s | 12 min |
| LASAR | 0.29s | 13 min | |
| Explicit CoT_GREAM (CoT Gen) | 7.0s | 5.5 h | |
| Instruments | MiniOneRec | 0.25s | 13 min |
| LASAR | 0.29s | 15 min | |
| Explicit CoT_GREAM (CoT Gen) | 6.5s | 5 h | |
| Sports | MiniOneRec | 0.30s | 22 min |
| LASAR | 0.32s | 24 min | |
| Explicit CoT_GREAM (CoT Gen) | 7.0s | 8.5 h |
LASAR 相比 MiniOneRec 仅多 7–16% 推理时延(数十毫秒级),相比生成完整 CoT 文本快 >20×。这是因为 latent loop 不需要自回归解码长 CoT chain,只在 hidden state 空间走 $\leq 8$ 步。LASAR 处于 Pareto 前沿。
Scaling 性 (Table 5, Beauty)¶
| Method | 0.6B Full FT N@10 | 0.6B HR@10 | 1.7B LoRA N@10 | 1.7B HR@10 |
|---|---|---|---|---|
| LASAR | 0.0303 | 0.0563 | 0.0307 | 0.0592 |
| MiniOneRec | 0.0295 | 0.0542 | 0.0299 | 0.0556 |
| Explicit CoT_GREAM | 0.0293 | 0.0553 | 0.0295 | 0.0561 |
scale 到 1.7B (LoRA),LASAR 仍是 SOTA;HR@10 增益 (+6.4% over 0.6B) 比 MiniOneRec (+2.6%) 大——latent reasoning 在更大模型上获益更多,说明它不会限制模型容量。Explicit CoT 在 scaling 上获益最少,作者归因为离散 token decoding 的瓶颈在大模型上被放大。
6. 核心贡献总结¶
- 首次实现 Coconut-style 多步递归 latent reasoning + 自适应步长在 decoder-only 主流生成式推荐范式里的完整落地。区分于先前推荐侧 latent reasoning 工作(ReaRec / LARES 在 ID embedding 判别范式里固定步数;LatentR³ / S²GR 在 LLM 生成范式里浅层单步注意力或 token 插入)。
- 诊断了 latent reasoning 直接迁移生成式推荐的三个独有失败模式(grounding gap、representation drift、fixed-step inflexibility),并给出对应的最小可行解:two-stage decoupling、stepwise bidir KL alignment、Policy Head + REINFORCE。
- 完整的 SFT-then-RL pipeline 设计:SFT 段用 CoT 切段+ bidir KL 把 latent step 锚定到语义轨迹;RL 段用 Terminal KL + REINFORCE 同时拉升 quality 与压缩 N。三个 RL 组件 (GRPO / Terminal KL / REINFORCE) 经消融全部不可缺。
- 效率层面达到 Pareto 前沿:相比 MiniOneRec 仅多约 7–16% 推理时延(几十 ms / sample),比生成完整 CoT 快 20×;推理时不需要 teacher CoT。
- 在 3 个 Amazon 数据集上几乎全部 metric-dataset 组合 SOTA;在最稀疏数据集 Sports 上提升幅度最大(N@10 +20%+),说明 latent reasoning 在协同信号稀疏场景特别有效。
7. 与已归档相关工作的对比¶
FLR FLR: Factorized Latent Reasoning (Meituan LongCat / UNSW, 2026-04-29)¶
关系:独立并发(本文未引用 FLR,FLR 比 LASAR 早 12 天放出 arXiv,两者殊途同归攻同一问题)· 已加载对方精读
- 共同关注的问题:两篇都在解 "主流生成式 / LLM-based 推荐如何引入低延迟的 latent reasoning"——同一 root cause(CoT 推理太慢 + 单一最终 hidden state 不足以承载多步偏好推断),同样的整体框架 SFT-then-RL(LASAR 用 GRPO+REINFORCE,FLR 用 GRPO),同样以 LatentR³ 为重要前置工作并都尝试超越它。
- 相近的技术骨架:两者都在 prompt 与 answer 之间插入 thought token 作为 latent reasoning 载体;都用两阶段训练(先 SFT warm-start,再 RL);都在 RL 阶段用 GRPO 优化生成质量;都不需要在线生成 CoT 文本。
- 本文的差异与推进:
- Latent 机制:LASAR 是 Coconut-style 完整递归 feedback loop——所有 hidden state 经过整个 LLM backbone N 次;FLR 是轻量化多头注意力模块 in-place 刷新单个 thought embedding——LLM backbone 冻结只跑一次,FLR module 在前端做 N 次更新。LASAR 计算量大但表达力强;FLR 计算量极小但表达力受限于因子注意力的容量。
- N 是固定还是自适应:LASAR 用 Policy Head + REINFORCE 做样本级自适应 N;FLR 固定 $T=2$(论文中表述为 reasoning 步数)。LASAR 在 RQ3 中明确证明 Force-N=4 是最差配置 (1.93% HR@10),adaptive 才是关键。
-
表征漂移的处理思路:LASAR 用外部 explicit CoT 锚点 + bidir KL对齐每步;FLR 用结构正则(orthogonal + diversity + sparsity)约束多因子表征。前者把 LLM 通用语义当 anchor,后者靠几何约束避免 mode collapse。两条路径都有效但价值取向不同:LASAR 倾向"对齐"语义而 FLR 倾向"分解"语义。
-
可比的方法 / 实验差异:FLR 在 4 个 Amazon 子集(Toys/CDs/Games/Instruments)上对 LatentR³ 平均 +3.2%(Games N@5 +10.26%);LASAR 在 3 个 Amazon 子集(Beauty/Instruments/Sports)上对 MiniOneRec 在 N@10 上 +2.9%~+20.6%(Sports 最大)。两者都重点验证"latent reasoning 不是 free improvement,必须配语义锚定"。核心 take-away:两个独立团队在 2026 年 4–5 月之间各自得出近乎相同的结论框架——单 latent token 本身不够,必须配 grounding 机制(FLR 是分解 + 正则,LASAR 是 CoT 对齐)。这是 latent reasoning 在生成式推荐里"问题已被广泛认知"的强证据。
8. 讨论与局限性¶
核心贡献 & 借鉴价值:
- 把"prior-less SID 与 latent reasoning 不能 joint train"作为一个可被量化诊断的优化干扰现象(混合训练 lr=5e-4 反而比 lr=3e-4 更慢收敛),是 latent reasoning 移植到任何 prior-less token 系统的通用警示。
- Bidirectional KL 作为唯一稳定有效的 latent state alignment 损失,相比 cosine(信号过弱)和 MSE(信号过强,强行拉绝对值)的双向消融对比说服力很高,这点值得做 latent reasoning 时直接借鉴。
- Policy Head + REINFORCE 的设计原则:在 SFT 阶段用 argmax 配 CE warm-start(避免 cold-start exploration 噪声),在 RL 阶段切到 sampling + step penalty(让 exploration 真正生效)。这种 "exploration scheduling" 思想对任意需要可变深度推理的场景都适用。
局限性 & 争议:
- Hidden state feedback loop 难并行化:作者自己点出 latent loop 每步依赖上一步 hidden state,无法跨 step parallel。如果未来需要把推理深度推到几十步,serial overhead 会成新瓶颈——这是 paradigm-level 的限制,不局限于 LASAR。
- Teacher CoT 依赖:虽然推理时不需要 CoT,但训练时 SFT 阶段每条样本都要 GPT-5 生成 CoT。对于亿级用户/十亿级 interaction 的工业场景,光这一项的 LLM API 成本就难以承受。论文没有讨论如何用更小 model 替代 GPT-5,也没有 ablation "更弱 teacher 是否还能 work"。
- 仅在 Amazon 三个学术数据集上验证:没有工业 A/B 数据;和 MiniOneRec、OneRec 系列的工业落地相比,LASAR 的工业落地仍属空缺。
- CoT 段数 = 推理深度监督信号这一假设值得质疑:SFT 用 CoT 段数作为 Policy Head 监督标签,但 RL 阶段(Figure 4b)实际把分布从"全集中在 N=3,4"漂移到"分布在 N=1–8",意味着 SFT 标签其实并不准。一个开放问题:能否从 user history 的某种内在复杂度指标直接预测 N,跳过昂贵的 CoT 切段?
- Beauty HR@20 不敌 Explicit CoT_GREAM:说明在 top-20 recall 场景下显式 CoT 的长尾覆盖仍有不可替代的价值——latent reasoning 可能更擅长 top-1/5 而非长尾。
与已有工作的差异:相比 GREAM(同样针对生成式推荐的推理增强),LASAR 把"推理"从 token 空间挪到 hidden state 空间,从根本上规避了 GREAM 暴露的 mode 竞争问题(GREAM 自己的消融表明 SRPO post-training 让 Direct 推荐指标降 5.3%,LASAR 的 RL 阶段几乎都是正收益);相比 ReaRec(latent reasoning 用在 SASRec-style discriminative),LASAR 在 decoder-only generative 范式里跑通;相比 LatentR³(单层 attention thinking token),LASAR 实现了真正的多步 hidden state feedback loop。