MaskTab: 工业级表格数据的可扩展掩码预训练框架¶
Zheng B, Chen Y, Xiong Z, et al. MaskTab: Scalable Masked Tabular Pretraining with Scaling Laws and Distillation for Industrial Classification. arXiv:2605.11408, 2026-05-12. (Zhejiang University & MyBank, Ant Group)
研究动机与背景¶
工业表格数据的"未启蒙"地位¶
在金融风控、医疗诊断、欺诈检测等高风险决策场景中,表格数据始终是核心载体。然而,在视觉与语言领域被基础模型范式彻底改写后,表格学习却依然停留在 GBDT 主导、依赖手工特征工程的前深度学习时代。本文将这一反差归结为表格数据自身的三重统计特性:
- 高维稀疏:工业表格往往包含数千到上万个原始字段,但每个字段对当前任务的判别力差异巨大(widely varying information value);
- 结构性缺失:缺失值往往本身就是信号而非噪声——例如"用户未填写收入"在风控场景中是显著的负向特征——但 GBDT 与 NN 标准流程要么直接丢弃高缺失字段、要么用简单插补抹平,造成信息丢失;
- 弱监督:工业场景标注样本仅有几十万量级,而未标注样本可达千万量级,自监督潜力被严重浪费。
正因这些"统计特异性",GBDT 系(XGBoost / LightGBM / CatBoost)能在工业管道里长期占优,不是因为它们最优,而是因为它们对原始输入容忍度最高。深度表格模型如 FT-Transformer 表达力更强,但忽视"缺失"语义、特征数千以上就难以 scale。TabPFN-2.5 试图做 tabular foundation model,但在 5 万样本/2k 特征以上崩坏,无法直接服务于真实工业场景。
三条设计原则¶
作者主张:表格数据完全可以承担"foundation model"的处理范式,前提是架构必须尊重它的统计异质性。MaskTab 在此前提下提出三条设计原则:
- 缺失即信号(Missingness as signal):用专用可学习 token
[MASK](合成掩码)和[MISS](自然缺失)显式编码"为什么这个值缺失",不再让模型把缺失误认为噪声; - 统一预训练(Unified pretraining):用孪生双路(twin-path)架构同时优化"掩码重建"自监督目标和"二分类"有监督目标,消除标准两阶段 SSL→SFT 范式中的目标错位(objective misalignment);
- 可扩展的交互建模(Scalable interaction modeling):用 MoE 重建头将高维特征自适应路由到专家网络,在增加容量的同时控制每 token 计算量。
在 TabReD 公开基准(5 回归 + 3 分类)与作者自有的 CreditRisk 工业数据集(2500 特征,1340 万无标签 + 64 万有标签)上,MaskTab 平均排名 2.3(XGBoost 4.4,CatBoost 5.6,FT-Transformer 6.4),在 CreditRisk 上较 XGBoost 实现 +5.04% AUC 与 +8.28% KS 的提升。蒸馏后的 MaskTab-Distill 在 500 个可解释特征下仍能取得 +2.55% AUC、+4.85% KS,且保持低延迟与 SHAP 等可解释性工具兼容。
任务定义与符号¶
记有标签集 $\mathcal{D}_{\text{sup}}=\{(\mathbf{x}_i, y_i)\}_{i=1}^N$ 与远大于它的无标签集 $\mathcal{D}_{\text{unsup}}=\{\mathbf{x}_j\}_{j=1}^M$($M \gg N$):
$$ \mathcal{D} = \mathcal{D}_{\text{sup}} \cup \mathcal{D}_{\text{unsup}},\quad \mathcal{D}_{\text{sup}}=\{(\mathbf{x}_i, y_i)\}_{i=1}^N,\; \mathcal{D}_{\text{unsup}}=\{\mathbf{x}_j\}_{j=1}^M,\; M \gg N. \tag{1} $$
每条记录 $\mathbf{x}=(v_1,\dots,v_d)$ 是异质特征(数值、类别、文本、或缺失)。论文以二分类($y\in\{0,1\}$)为示范任务,但框架天然扩展到 $n$-way 分类与回归。
基线:异质表格的 Transformer 编码器¶
作者首先构造一个 encoder-only Transformer 作为骨干。对每个特征 $k$,构造一个由"特征名嵌入" $\mathbf{e}_k^{\text{name}}$ 与"特征值嵌入" $\phi(v_k)$ 相加后再 LayerNorm 的 token:
$$ \mathbf{h}_k = \text{LayerNorm}\big(\mathbf{e}_k^{\text{name}} + \phi(v_k)\big) \in \mathbb{R}^h. \tag{2} $$
特征名通过冻结的 BERT 编码后池化获得(一次性预计算),保证不同字段在语义空间可比;值编码器 $\phi(\cdot)$ 按类型分别处理——数值用线性投影、类别用查表 embedding、文本用冻结文本编码器、缺失用一个共享可学习向量。
堆叠所有特征 token 得到 $\mathbf{H} \in \mathbb{R}^{d \times h}$,输入 Transformer:
$$ \mathbf{Z} = \text{Transformer}(\mathbf{H}). \tag{3} $$
通过 mean pooling 得到行级表示后接线性分类头预测 $\hat y$,仅用 $\mathcal{D}_{\text{sup}}$ 与 BCE loss 训练。这相当于一个"无任何预训练"的 vanilla 表格 Transformer,作为消融实验中的"Vanilla baseline"。
核心方法:MaskTab 三大组件¶
组件 1:把"缺失"显式 token 化¶
MaskTab 区分两种缺失:合成掩码(synthetic masking) 来自预训练阶段为做 reconstruction 任务故意 mask 掉的位置,自然缺失(natural missing) 是原始记录中真实为空的位置。两者用独立 token 表示,但初始化共享一个可学习向量 $\mathbf{m}$(避免冷启动):
$$ \phi(v_k) = \begin{cases} \mathbf{e}_{[\text{MASK}]}, & k \in \mathcal{M}, \\ \mathbf{e}_{[\text{MISS}]}, & v_k = \bot, \\ \text{standard encoding}, & \text{otherwise}, \end{cases}\quad \mathbf{e}_{[\text{MASK}]} = \mathbf{e}_{[\text{MISS}]} = \mathbf{m}\;(\text{at init}). \tag{4} $$
其中 $\mathcal{M}$ 是当前 batch 随机选择的掩码位置集合,$\bot$ 表示原始缺失。在训练过程中两个 embedding 可以独立漂移,使模型学到"我是被刻意掩掉的"与"我本就空着"两种语义差异。
掩码重建损失:对未标注样本 $\mathbf{x}$,采样观测特征子集 $\mathcal{M}$ 替换为 [MASK] 得到 $\widetilde{\mathbf{x}}$,编码后 $\mathbf{Z} = \text{Transformer}_\Theta(\phi(\widetilde{\mathbf{x}}))$,对每个掩码位置预测原值:
$$ \mathcal{L}_{\text{MLM}} = \sum_{k\in\mathcal{M}} \ell(g(\mathbf{z}_k), v_k), \tag{5} $$
其中 $g(\cdot)$ 是一个跨特征共享的轻量预测头,$\ell$ 是类型自适应的损失(数值 MSE,类别/文本 cross-entropy 或 contrastive)。这一目标迫使编码器同时捕获特征共现模式与缺失结构。
组件 2:孪生双路混合监督预训练¶
为什么需要"孪生双路"¶
直接把"masked input + 分类头"的方案训练 $P(y\mid\widetilde{\mathbf{x}})$ 会引入 train-test mismatch:推理时输入是自然缺失模式 $\mathbf{x}$,但训练时见到的全是合成掩码污染过的 $\widetilde{\mathbf{x}}$,造成"masking-induced shift"。MaskTab 用一对共享参数 $\Theta$ 的并行路径来消解这一漂移:
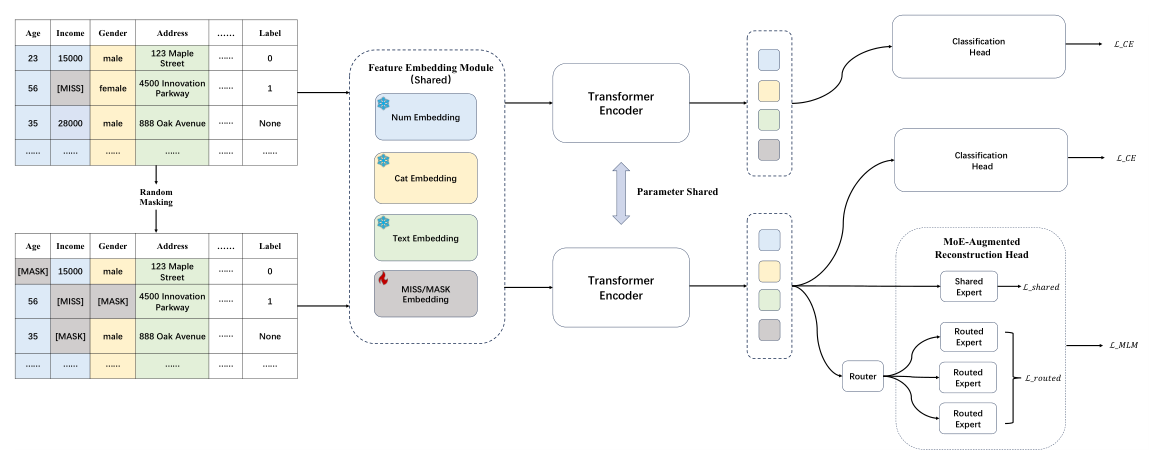
重建路径(reconstruction path):对样本做掩码后用 $\Theta$ 编码,计算 MLM 损失:
$$ \mathbf{Z}^{(\text{MLM})} = \text{Transformer}_\Theta(\phi(\widetilde{\mathbf{x}})),\; \mathcal{L}_{\text{CE}}\big(\mathbf{z}^{(\text{MLM})}\big),\; \mathcal{L}_{\text{MLM}}(\mathbf{Z}^{(\text{MLM})}). \tag{9} $$
分类路径(classification path):保留原始输入 $\mathbf{x}$(含自然缺失但无合成掩码),用同一 $\Theta$ 编码后池化做分类:
$$ \mathbf{z}^{(\text{CLS})} = \text{Pooling}\big(\text{Transformer}_\Theta(\phi(\mathbf{x}))\big),\; \mathcal{L}_{\text{CE}}\big(\mathbf{z}^{(\text{CLS})}\big). \tag{10} $$
参数共享使重建任务学到的依赖/缺失知识能迁移到分类器,同时分类器只见到真实输入分布 $P(y\mid\mathbf{x})$,杜绝预训练-下游 mismatch。
联合目标¶
对有标签样本,混合监督的损失是 MLM + 分类的线性加权:
$$ \mathcal{L}_{\text{hybrid}}^{(\text{sup})} = \lambda\,\mathcal{L}_{\text{MLM}} + (1-\lambda)\,\mathcal{L}_{\text{CE}},\quad \lambda\in[0,1]. \tag{6} $$
对无标签样本,仅有 MLM 损失:
$$ \mathcal{L}_{\text{hybrid}}^{(\text{self-sup})} = \mathcal{L}_{\text{MLM}}. \tag{7} $$
总目标在两个子集上取平均:
$$ \mathcal{L}_{\text{hybrid}} = \frac{1}{|\mathcal{D}_{\text{sup}}|}\sum_{(\mathbf{x},y)\in\mathcal{D}_{\text{sup}}}\mathcal{L}_{\text{hybrid}}^{(\text{sup})} + \frac{1}{|\mathcal{D}_{\text{unsup}}|}\sum_{\mathbf{x}\in\mathcal{D}_{\text{unsup}}}\mathcal{L}_{\text{hybrid}}^{(\text{self-sup})}. \tag{8} $$
这一目标在训练全程保持不变,没有显式的预训练→微调切换。设计上这避免了两阶段 schedule 的超参与对齐问题,工程上也更友好。
自适应掩码率¶
天然就稀疏的样本被进一步加掩码会损坏几乎所有可用信号。作者引入按样本动态调整的 mask 率:设 $\eta(\mathbf{x}) = \frac{1}{d}\sum_{k=1}^d \mathbb{I}(v_k = \bot)$ 为样本的缺失率,$\eta_{\max}$ 是数据集上的最大缺失率,则:
$$ r_{\text{mask}}(\mathbf{x}) = r_{\max}\left(1 - \frac{\eta(\mathbf{x})}{\eta_{\max}}\right)^\alpha, \tag{11} $$
其中 $r_{\max}$ 是最大掩码比例,$\alpha\gt 0$ 控制曲线敏感度。这样"几乎全缺失"的样本几乎不被加额外掩码,"几乎全观测"的样本则被强力扰动以提供丰富 reconstruction 信号。
组件 3:可扩展的 MoE 重建头¶
当特征数从几百扩展到数千,单个线性投影做 mask 重建会成为容量瓶颈。MaskTab 把 MLM 头换成轻量级 MoE 层,灵感来自近期 DeepSeekMoE。核心思想是让每个特征 token 选择一小部分专家做 reconstruction,把容量做大的同时保持单 token 计算上界。具体地结合两类专家:
- 共享专家(shared expert) $\mathbf{w}_0, \mathbf{b}_0$:所有 mask 位置都过;
- 路由专家(routed experts) $K_r$ 个,每个 token top-$K_a$ gating:
MLM 总损失拆为两项加权:
$$ \mathcal{L}_{\text{MLM}} = \alpha\,\mathcal{L}_{\text{Shared}} + \beta\,\mathcal{L}_{\text{Routed}}, \tag{12} $$
共享专家损失:
$$ \mathcal{L}_{\text{Shared}} = \sum_{k\in\mathcal{M}} \ell\big(\mathbf{w}_0 \mathbf{z}_k + \mathbf{b}_0,\, v_k\big), \tag{13} $$
路由专家损失:
$$ \mathcal{L}_{\text{Routed}} = \sum_{k\in\mathcal{M}} \ell\left(\sum_{i=1}^{K_r} g_{i,k}\big(\mathbf{w}_i \mathbf{z}_k + \mathbf{b}_i\big),\, v_k\right). \tag{14} $$
对每个 token,gating 只保留 top-$K_a$ 路由专家:
$$ g_{i,k} = \begin{cases} s_{i,k}, & s_{i,k} \in \text{TopK}(\{s_{j,k}\}_{j=1}^{K_r},\, K_a),\\ 0, & \text{otherwise}, \end{cases} \tag{15} $$
路由分数由质心匹配(centroid matching) 得到:
$$ s_{i,k} = \text{Softmax}_i\big(\mathbf{z}_k^\top \mathbf{e}_i\big), \tag{16} $$
其中 $\{\mathbf{e}_i\}_{i=1}^{K_r}$ 是可学习的专家质心。这一设计鼓励自适应的特征分组与专家专业化——例如收入、消费、信用相关的特征可能被路由到不同专家——在不增加重 MLP 的前提下大幅扩展重建容量。
组件 4:任务特化蒸馏到可解释学生¶
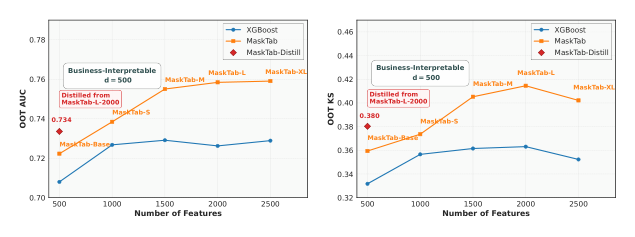
工业部署对延迟与可解释性要求严苛(风控通常要求 SHAP 等工具能直接作用于特征),而扩展后的 MaskTab-L 拥有 134M 参数、2000 个特征,难以直接上线。作者把它蒸馏到 25.16M 参数、500 个业务审计过的可解释特征的 MaskTab-Distill。
蒸馏由表示对齐驱动。学生最后一层的 hidden state $\mathbf{z}^{(\text{CLS})}$ 用线性升维到教师空间:
$$ \mathbf{z}_a = \mathbf{w}_a \mathbf{z}^{(\text{CLS})} + \mathbf{b}_a, \tag{17} $$
其中 $\mathbf{w}_a \in \mathbb{R}^{d_t \times d_s}, \mathbf{b}_a \in \mathbb{R}^{d_t}$。表示损失定义为投影后的学生表示 $\mathbf{z}_a$ 与教师 MaskTab-L 的对应嵌入 $\mathbf{e}_t \in \mathbb{R}^{d_t}$ 的负余弦相似度:
$$ \mathcal{L}_{\text{align}} = 1 - \cos(\mathbf{z}_a, \mathbf{e}_t) = 1 - \frac{\mathbf{z}_a \cdot \mathbf{e}_t}{|\mathbf{z}_a|\,|\mathbf{e}_t|}. \tag{18} $$
学生的总损失是 MLM、CE 和 align 三项加权(权重三者之和为 1):
$$ \mathcal{L}_{\text{hybrid}}^{(\text{sup})} = \lambda_1\,\mathcal{L}_{\text{MLM}} + \lambda_2\,\mathcal{L}_{\text{CE}} + \lambda_3\,\mathcal{L}_{\text{align}},\quad \lambda_1+\lambda_2+\lambda_3 = 1. \tag{19} $$
部署时蒸馏过程先缓存教师在训练集上的 embedding作为软目标,再让学生学这些缓存——避免每步前向都跑教师的开销。最终 MaskTab-Distill 推理快 9.3 倍,且只用 500 个特征。
实验设置¶
数据集¶
- TabReD:包含 8 个公开工业表格数据集(3 分类 + 5 回归),覆盖电商、保险、信用、住房、烹饪、配送、地图、天气等场景;
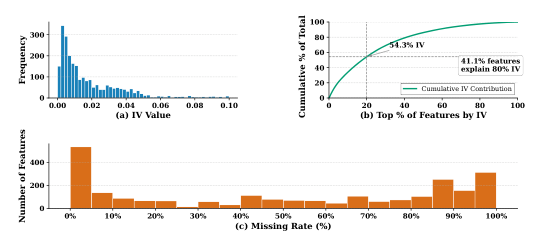
- CreditRisk(专有):2024 年完整一年风控数据,13 M 无标签 + 640 K 有标签,2500 特征(25 类别 + 2475 数值),平均缺失率 49%,月度信息价值(IV)异质(图 5)。严格按时间划分:训练 Jan–Jun 2024(330k),验证 Jul–Sep 2024(180k),测试 Oct–Dec 2024(130k),完全避免泄漏;无标签集与训练集来自同一 6 个月窗口(1.3 M 样本)。
| Dataset | Source | #samples | #num feat. | #cat feat. | 0% miss | 33–66% miss | 66–100% miss |
|---|---|---|---|---|---|---|---|
| EcomOffers (EO) | TabReD | 160 K | 113 | 6 | 0% | 0% | 0% |
| HomesiteInsurance (HI) | TabReD | 261 K | 253 | 46 | 89.93% | 0% | 0% |
| HomeCreditDefault (HCD) | TabReD | 382 K | 612 | 84 | 57.16% | 36.93% | 5.91% |
| CreditRisk (CR) | Private | 13 M | 2475 | 25 | 6.75% | 89.17% | 4.08% |
| SberbankHousing (SH) | TabReD | 28 K | 365 | 27 | 100% | 0% | 0% |
| CookingTime (CT) | TabReD | 320 K | 186 | 6 | 99.10% | 0% | 0% |
| DeliveryETA (DE) | TabReD | 351 K | 221 | 2 | 91.50% | 3.71% | 0% |
| MapsRouting (MR) | TabReD | 280 K | 984 | 2 | 97.08% | 2.82% | 0.10% |
| Weather (W) | TabReD | 424 K | 100 | 2 | 0% | 2.21% | 0.03% |
特别注意 CreditRisk 与 HomeCreditDefault 的特征缺失分布严重偏向 33%+ 区间,这正是 MaskTab 要解决的"missingness 当信号"场景。
模型变体与训练协议¶
| Model | #Params (Non-Emb) | Layers | Heads | KV size | $d_{\text{model}}$ |
|---|---|---|---|---|---|
| MaskTab-Base | 25.16 M | 6 | 8 | 64 | 512 |
| MaskTab-S | 56.62 M | 6 | 12 | 64 | 768 |
| MaskTab-M | 75.50 M | 8 | 12 | 64 | 768 |
| MaskTab-L | 134.22 M | 8 | 16 | 64 | 1024 |
| MaskTab-XL | 201.33 M | 12 | 16 | 64 | 1024 |
| MaskTab-Distill | 25.16 M | 6 | 8 | 64 | 512 |
- MaskTab-Base:端到端用 hybrid 监督目标训练,batch size 2048,余弦学习率(peak $10^{-4}$,warmup 100 steps,decays to $10^{-5}$),8× A100;
- MaskTab-{S/M/L/XL}:scaling 实验用,预训练采用学习率缩放 $\text{LR}_{\text{scaled}} = \text{LR}_{\text{base}} \cdot \sqrt{N_{\text{base}}/N}$,再以 $10^{-5}$ 在标签数据上微调;
- MaskTab-Distill:从 MaskTab-L-2000 蒸馏到 500 可解释特征。
评估协议:CreditRisk 报告月度 OOT(out-of-time)AUC 与 KS(Kolmogorov-Smirnov 统计量,金融风控行业标准),跨月聚合衡量"分布漂移下的稳健性"。
主要实验结果¶
TabReD 8 任务总览¶
Table 1(共 14 个 baseline + MaskTab):MaskTab 平均排名 2.3,显著好于所有 GBDT 与深度表格模型。
| Method | HI (AUC↑) | EO (AUC↑) | HCD (AUC↑) | SH (RMSE↓) | CT (RMSE↓) | DE (RMSE↓) | MR (RMSE↓) | W (RMSE↓) | Avg Rank |
|---|---|---|---|---|---|---|---|---|---|
| XGBoost | 0.9601 | 0.5763 | 0.8670 | 0.2419 | 0.4823 | 0.5468 | 0.1616 | 1.4671 | 4.4 |
| LightGBM | 0.9603 | 0.5758 | 0.8664 | 0.2468 | 0.4826 | 0.5468 | 0.1618 | 1.4625 | 5.5 |
| CatBoost | 0.9606 | 0.5596 | 0.8621 | 0.2482 | 0.4823 | 0.5465 | 0.1619 | 1.4688 | 5.6 |
| SNN | 0.9492 | 0.5996 | 0.8551 | 0.2858 | 0.4838 | 0.5544 | 0.1651 | 1.5649 | 10.5 |
| DCNv2 | 0.9392 | 0.5955 | 0.8466 | 0.2770 | 0.4842 | 0.5532 | 0.1672 | 1.5782 | 11.4 |
| ResNet | 0.9469 | 0.5998 | 0.8493 | 0.2743 | 0.4825 | 0.5527 | 0.1625 | 1.5021 | 8.0 |
| MLP-PLR | 0.9621 | 0.5957 | 0.8568 | 0.2438 | 0.4812 | 0.5527 | 0.1616 | 1.5177 | 4.4 |
| Trompt | 0.9546 | 0.5792 | 0.8381 | 0.2596 | 0.4834 | 0.5563 | 0.1612 | 1.5722 | 11.0 |
| FT-Transformer | 0.9622 | 0.5775 | 0.8571 | 0.2440 | 0.4820 | 0.5542 | 0.1625 | 1.5104 | 6.4 |
| TabR | 0.9522 | 0.5850 | 0.8484 | 0.2851 | 0.4825 | 0.5541 | 0.1637 | 1.4622 | 8.6 |
| TabNet | 0.9531 | 0.5855 | 0.7701 | 0.2828 | 0.4813 | 0.5567 | 0.1651 | 1.5877 | 10.5 |
| TransTab | 0.9564 | 0.5868 | 0.8498 | — | — | — | — | — | — |
| CM2 | 0.9560 | 0.5890 | 0.8392 | 0.2287 | 0.4838 | 0.5569 | 0.1638 | 1.5339 | 9.0 |
| TabPFN-2.5 | 0.9443 | 0.5804 | — | 0.2356 | — | — | — | — | — |
| MaskTab(Base) | 0.9635 | 0.6069 | 0.8698 | 0.2345 | 0.4806 | 0.5486 | 0.1618 | 1.4861 | 2.3 |
结论解读:MaskTab 在所有 3 个分类任务上拿到第一(AUC 最高),在 5 个回归任务上要么第一要么前三,体现"作为一个统一框架,跨任务跨数据均衡领先"的特性,而非"只对某类数据集刷分"。TabPFN-2.5 在 SberbankHousing 上拿到第二(0.2356),但因为 50k 样本/2k 特征上限,在 HCD、CT、DE、MR、W、CR 等大表上无法训练或运行,与作者强调的"工业可扩展性"形成对比。
CreditRisk 单数据集对比¶
Table 2 单独把 CreditRisk(最具工业代表性,2500 特征,13 M 无标签)拎出来:
| Model | Type | #Params (Est.) | #Features | ROC AUC↑ | KS↑ |
|---|---|---|---|---|---|
| XGBoost | GBDT | — | 500 | 0.7080 | 0.3317 |
| LightGBM | GBDT | — | 500 | 0.6949 | 0.3204 |
| TabNet | Seq-to-Seq | 29.71 M | 500 | 0.6581 | 0.2687 |
| MLP-PLR | Feedforward | 37.24 M | 500 | 0.6650 | 0.2860 |
| FT-Transformer | Transformer | 31.52 M | 500 | 0.6832 | 0.2832 |
| CM2 | Transformer | 26.01 M | 500 | 0.6835 | 0.2922 |
| MaskTab-Base | Transformer | 25.16 M | 500 | 0.7149 | 0.3398 |
| MaskTab-L | Transformer | 134.22 M | 2000 | 0.7584 | 0.4145 |
| MaskTab-Distill | Transformer | 25.16 M | 500 | 0.7335 | 0.3802 |
关键观察: 1. 在 500 特征预算下,所有现存深度表格模型(TabNet/MLP-PLR/FT-Transformer/CM2)都输给 XGBoost——印证"深度表格模型在工业数据上未必赢得过 GBDT"的现状; 2. MaskTab-Base 是第一个在同等 500 特征下战胜 XGBoost 的深度模型(+0.69% AUC,+0.81% KS); 3. MaskTab-L 用 2000 特征把 AUC 推高到 0.7584(+5.04% over XGBoost)、KS 0.4145(+8.28%); 4. MaskTab-Distill 在 500 特征下取得 AUC 0.7335 / KS 0.3802,相对 XGBoost 仍有 +2.55% / +4.85% 提升——充分蒸馏的小模型在低延迟与可解释性约束下依然显著领先,这是论文最有工业价值的结果。
消融与分析¶
组件累加消融¶
Table 3:从 vanilla Transformer 起逐步加入三个核心模块,逐项验证贡献。
| Module Additions | ROC AUC↑ | KS↑ |
|---|---|---|
| Vanilla baseline | 0.6472 | 0.2371 |
| + Mask Embedding | 0.6976 (+5.04%) | 0.3107 (+7.36%) |
| + Twin Networks | 0.7090 (+1.14%) | 0.3241 (+1.34%) |
| + MoE | 0.7149 (+0.59%) | 0.3398 (+1.57%) |
结论解读:
- Mask Embedding + Hybrid SSL 一项就提供了最大幅度的提升(AUC +5.04%、KS +7.36%)——这验证了论文的核心论点:把缺失当作可学习信号、把 SSL 重建目标与下游分类对齐,是最关键的设计杠杆;
- Twin Networks 单独消除"masking-induced shift"再带来 +1.14% AUC / +1.34% KS——说明 train-test mismatch 确实存在且 twin-path 是有效解药;
- MoE 重建头 再带 +0.59% AUC / +1.57% KS,体现高维特征下"动态分组重建"的容量收益。
共享 vs 特征专有 mask embedding¶
Table 4 测试是否需要为每个特征单独学一个 mask 向量:
| Configuration | ROC AUC↑ | KS↑ |
|---|---|---|
| Shared Mask Embedding | 0.7149 | 0.3398 |
| Feature-Specific Mask Embedding | 0.7194 | 0.3387 |
差异极小(AUC ±0.0045,KS ±0.0011),证明特征名 embedding $\mathbf{e}_k^{\text{name}}$ 已经携带足够多的 inter-feature 语义区分,掩码 token 本身共享一份即可,参数效率显著高于 per-feature 设计。
与传统缺失值处理方法对比¶
Table 5 在 HomeCredit(AUC)与 Sberbank(RMSE)上对比 4 种 imputation 策略 + MaskTab 的 mask embedding:
| Imputation Method | HomeCredit (AUC↑) | Sberbank (RMSE↓) |
|---|---|---|
| Zero Value | 0.8625 | 0.2448 |
| Mode Value | 0.8383 | 0.2419 |
| HyperImpute | — | 0.2552 |
| ReMasker | 0.8609 | 0.2656 |
| Mask Embedding | 0.8698 | 0.2345 |
结论:MaskTab 的 mask embedding 一致优于 zero-fill、众数填充、以及学习型方法 HyperImpute、ReMasker。把缺失当 token 而非用其他值替换,确实保留了更多预测信号。
Scaling Law 分析¶
Scaling 实验采用贪心串行策略:先在固定特征 500、模型 25.2M 下扫数据量,找到拐点;再固定数据扫特征;最后固定数据 + 特征扫模型大小。
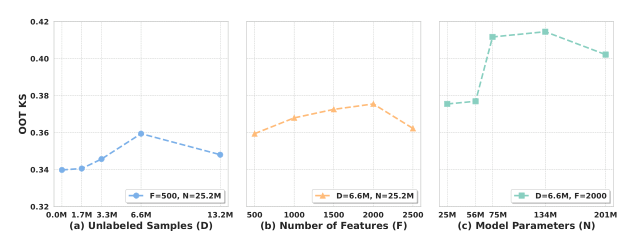
维度 1:未标注数据¶
固定 500 特征、25.2M 参数,无标签:有标签比例从 0× 到 40×:
- 5×、10×、20× 单调提升,至 20× 时 OOT KS = 0.3594(比纯监督 baseline +1.9%);
- 40× 时 KS 反降到 0.3480,说明在当前特征数与容量下 SSL 数据饱和。
维度 2:特征数¶
固定 20× 数据、25.2M 参数,特征 500 → 2500(500 步长):
- 500 → 2000 单调提升,OOT KS 从 0.3594 → 0.3754(+1.6%),峰值在 2000;
- 2500 反降到 0.3653,饱和。
维度 3:模型参数¶
固定 20× 数据、2000 特征,从 25.16M → 201.32M:
- 单调提升至 MaskTab-L (134M),KS = 0.4145(+3.91% over 之前最佳 0.3754);
- MaskTab-XL (201M) 降到 0.4021,再次饱和。
联合结论:三个轴上都表现出可预测的单调提升 + 在当前预算下饱和的曲线,没有出现单一轴贪心扩张能继续无限提升的情况——这意味着想继续提升必须联合扩张(更大的数据 × 更高维 × 更大模型)。MaskTab 是少数在工业表格数据上明确观测到 scaling law 趋势的工作,且把"未标注数据扩张"与"特征维度扩张"作为两个独立可调杠杆。
OOD(时间漂移)鲁棒性分析¶
Figure 4:训练于 2024-01 ~ 2024-06,逐月在 2024-07 ~ 2024-12 的 OOT 数据上评估。
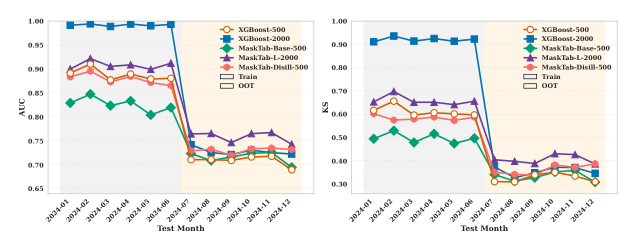
观察:
- XGBoost 训练 KS > 0.60 但 OOT KS ≈ 0.35——严重过拟合到训练期信号;
- MaskTab-Base 训练 KS 显著降低,OOT KS 抬升,gap 收窄;
- MaskTab-Distill 进一步把 gap 压到最小——蒸馏后的学生在维持精度的同时获得了比 GBDT 与原 base 更强的时间分布稳健性。
这是金融风控最在意的指标之一:上线后随着用户行为漂移,模型衰减越慢越好。MaskTab 的预训练 + 蒸馏管道在这一点上展示了独特优势。
知识蒸馏的部署收益¶
MaskTab-L-2000(134.21M)虽是最佳模型,但 2000 个稀疏特征 + 大参数难以服务于低延迟、可解释要求严苛的风控线上系统。蒸馏出的 MaskTab-Base-500:
- KS 相对 MaskTab-Base-500(无蒸馏)提升 +4.04%;
- 推理速度 9.3× faster;
- 仅用 500 个业务审计过、SHAP 兼容的可解释特征。
部署细节:训练时先缓存教师对全训练集的 embedding,学生训练只对缓存做对齐,避免每步前向触发教师巨大计算。
与已有工作的关系¶
Tabular Models:相对 GBDT 系(XGBoost / LightGBM / CatBoost)保留可解释性、增强表达力;相对深度系(FT-Transformer / TabNet / TabR),首次明确把"缺失语义"作为一等公民编码,并配套大规模 SSL 与 scaling law 验证。
TabPFN-2.5:作为 tabular foundation model 的另一条路(基于合成数据 in-context learning),TabPFN 在 50k 样本/2k 特征上限以下表现优秀,但工业级 13 M 样本/2500 特征场景无法支撑——MaskTab 是这一规模下的第一份可落地工业方案。
Scaling Law:相对 LLM 的 Kaplan/Chinchilla、视觉的 Zhai、推荐系统的 Lai 2025、时间序列的 Yao 2024,本文是首次在工业表格上对未标注数据、特征维度、模型参数三个轴做系统扫描;相对 Ma 2024(TabDPT 也做表格 scaling),本文额外覆盖"未标注数据 + 特征维度 + 真实异质缺失"。
Knowledge Distillation:DeepGBM 把 GBDT 知识蒸馏到 NN;TransTab 用大 transformer 教小模型。MaskTab 的独特贡献是把大模型 + 富特征 蒸馏到小模型 + 业务可解释特征子集——这在风控领域意义重大,因为合规层面禁止使用未审计的特征。
讨论与局限性¶
核心贡献总结: 1. 方法论上:把"缺失即信号"提到一等公民地位,配以孪生双路混合监督训练彻底消解 SSL→SFT 的对齐与漂移问题;MoE 重建头为高维 reconstruction 提供可扩展容量。 2. 实证上:在 8 个公开 + 1 个工业的表格 benchmark 上系统验证;在 13 M 样本工业风控数据上明确观测到三轴 scaling law。 3. 工程上:把大模型 + 富特征 蒸馏到小模型 + 可解释特征,解决了"性能-延迟-合规"三难,是论文最有工业价值的设计。
局限性(作者明示):
- Scaling 实验非详尽:贪心单轴扩张而非全因子设计,未拟合出闭式联合 scaling law(如 Chinchilla 形式);
- 模态扩展未覆盖:当前对文本特征仅用冻结 BERT pooling,没有融合更丰富的文本/图像/时间序列信号;
- 时间序列依赖结构未建模:当前每条记录被视作 i.i.d. 样本,但金融场景天然有强时序依赖;
- CreditRisk 闭源:复现需要在公开 TabReD 上做,工业风控收益依赖私有数据,不易第三方复核。
值得借鉴的设计:
1. 对推荐系统稀疏特征(百万级)也存在"缺失即信号"问题(未点击、未曝光、未填写),可借鉴 [MASK] / [MISS] 双 token 设计;
2. 孪生双路是消除 SSL→下游 mismatch 的轻量做法,比标准 pretrain-then-finetune 工程友好;
3. 把可学习 mask token 改写为类型条件 token(数值 vs 类别 vs 文本 vs 缺失)的 idea,可移植到序列推荐中"未发生的 action"建模;
4. 教师 + 受限特征 学生的蒸馏框架对所有需要 SHAP/LIME 可解释性的领域(医疗、风控、信贷)都有直接价值。
与本档案库其他工作的差异:本文与档案库现有工作(多为生成式推荐、序列推荐、CTR 排序的 scaling)分属不同问题域——MaskTab 关注无序异质表格 + 高缺失 + 弱监督的基础模型化,而档案中的 scaling 工作(HSTU、TokenMixer-Large、LoopCTR、MixFormer 等)关注有序行为序列 + 稠密 embedding + 强监督 的架构 scaling。两条路径互补:序列建模负责"行为时间维",MaskTab 类工作负责"属性宽度维"。