Practical Scaling Laws: Converting Compute into Performance in a Data-Constrained World¶
研究动机与背景¶
现代机器学习中训练数据正在变得越来越昂贵。物理代理模型(physics surrogates)需要昂贵的 PDE 求解器为每个样本生成一次解 [4],医学影像基础模型需要专家标注的数据 [40],强化学习智能体每个 transition 都付出真实代价 [39],LLM fine-tuning 在预训练预算的一小部分上运行 [49]。即使是 LLM 预训练——这里 token 曾经是相对算力廉价的输入——也开始随着可抓取的网络文本耗尽而重新审视如何复用数据 [47, 36]。在所有这些场景里,实践者都面对同一个权衡:花钱获取更多 unique 数据,还是花算力反复利用手头已有的数据。这个权衡正是 scaling law 应该回答的问题,但占主导地位的 Chinchilla scaling law 恰恰是在不存在这个权衡的 regime 下被标定的——数据充足、单 epoch 预训练。
scaling law 的标准做法是:用便宜的小规模实验拟合一个 loss 曲面的参数化模型,再用它预测实践者负担不起的大规模 run 的 loss。最被引用的形式是 Hoffmann 等 [26] 的 Chinchilla 形式:
$$L(N, D) = E + \frac{A}{N^\alpha} + \frac{B}{D^\beta} \tag{1}$$
这个"power-law-plus-constant"模板的变种在语言建模 [27]、视觉 [1]、迁移学习 [23]、下游任务 [12, 16] 以及理论模型 [5, 34, 10] 中反复出现,并继承了它的结构性承诺。
三大结构性失效。虽然 Eq. (1) 及其近亲在数据充足、单 epoch regime 下能跨越多个数量级地拟合训练 run,但它们缺失三条关键性质,使其无法泛化到这个 regime 之外:
- No baseline saturation(缺少基线饱和):loss 应当被一个 未训练模型 loss $L_0$ 从上界限定。Chinchilla 在 $D \to 0$ 时给出 $L \to \infty$,而非饱和到 $L_0$。
- Overfitting unreachable(过拟合不可达):在固定 $D$ 下,Eq. (1) 在 $N$ 上严格单调递减,但神经网络在 $N \gg D$ 时会过拟合 [24, 36],validation loss 会在某点之后回升。Chinchilla 没法表达这种 U 形。
- No compute axis independent of $(N, D)$(没有独立于 $(N, D)$ 的算力轴):Chinchilla 形式无法区分"总样本数" $T$ 与"unique 样本数" $D$,所以它结构上不支持多 epoch 训练的分析。
本文(Arena Physica)作出以下贡献:
- 提出一个在 $\mathbb{R}_{\gt 0}^3$ 上定义的单一参数化形式 $L(N, D, T)$,将 loss 分解为 undercapacity、undertraining 与 overfitting 三项,再用一个饱和包装器(saturating wrapper)把整体限定在不可降低 loss $E$ 与未训练基线 $L_0$ 之间。
- 在 4 个 architecture-domain 对(vision、scientific ML、language)上系统地测试该形式。
- 在 5 个公开发表的 LLM scaling-law 数据集上展示 SOTA 外推能力。
- 给出一个 budget-constrained 下选择 $(N^*, D^*, T^*)$ 的策略,把预算最优地拆分到数据获取与训练算力之间。
The Extended Scaling Law:完整形式¶
提出的参数化形式¶
作者从 Chinchilla 的功能形式出发,要求新形式满足一组目标极限行为(Table 1):六行约束行规定了 $(N, D, T)$ 趋向 0 或 $\infty$ 的所有路径上 $L$ 应当趋于什么值。前 5 行要求训练崩溃时 $L \to L_0$;第 6 行刻画 最优行为(资源充足时 $L \to E$)。
由这些约束加上小-$h$ 单 epoch 极限退化到 Chinchilla 的要求,作者推导出(完整推导见 Appendix B):
$$L(N, D, T) = E + (L_0 - E) \cdot \frac{h(N, D, T)}{1 + h(N, D, T)}, \quad h = \frac{a}{N^\alpha} + \frac{b}{T^\beta} + c \cdot \frac{N^\gamma}{D^\delta} \tag{2}$$
符号约定:$N$ 是参数数;$D$ 是 unique 训练样本数;$T$ 是总训练样本数(含重复)。$h$ 中的三项分别表示 undercapacity($a/N^\alpha$)、undertraining($b/T^\beta$)以及 overfitting($cN^\gamma/D^\delta$);外层 $h/(1+h)$ 是饱和包装器,将 $L$ 限定在 $[E, L_0]$ 中。算力 $C$ 用 $C \approx kNT$($k$ 与架构相关)来近似,但形式本身不对 $C$、$N$、$T$ 之间的函数关系做假设。$T/D$ 即训练 epoch 数。八个自由参数为 $(E, a, b, c, \alpha, \beta, \gamma, \delta)$;$L_0$ 由 loss 类型(如 cross-entropy 的 $\ln V$)决定,不参与拟合。
$L$ 的定义:$L(N, D, T)$ 始终指 训练过程中观察到的最低 validation loss——是 checkpoint 上的最小值,而非 final-checkpoint 值。在 $N \gg D$ 的过拟合 regime 里,validation loss 会随着模型记忆而上升,作者拟合的是这个"能取到的最小值",与真实部署中 early-stop 一致。
三项分解的物理含义¶
$$h(N, D, T) = \underbrace{\frac{a}{N^\alpha}}_{\text{undercapacity}} + \underbrace{\frac{b}{T^\beta}}_{\text{undertraining}} + \underbrace{c \frac{N^\gamma}{D^\delta}}_{\text{overfitting}} \tag{3}$$
- Undercapacity $a/N^\alpha$:这是 唯一 一个不随 $D$、$T$ 增大而消失的项。它度量"有限容量模型残余的代价",$\alpha$ 即标准的 Chinchilla 容量指数。在给定架构下,capacity 随 $N$ 单调增长,但具体映射依赖架构。
- Undertraining $b/T^\beta$:随 总 样本数 $T$(含重复)衰减。Chinchilla 单 epoch 拟合下 $T = D$,所以 $b/T^\beta$ 退化为 $b/D^\beta$,与 Chinchilla 的数据项一致;多 epoch 下两个机制分离——undertraining 随每个 gradient step 多看一个 example(不论新旧)而递减。
- Overfitting $c N^\gamma/D^\delta$:仅取决于 capacity $N$ 和 unique data $D$,不依赖训练时长 $T$。两个独立指数的形式比对称比 $(N/D)^\gamma$ 更灵活——它允许 $D$-scaling 和 $N$-scaling 被 独立 标定,因为两者通过不同机制(经验风险最小化的 sample-size variance vs capacity-driven 过表达)影响泛化。
结构性观察:在固定 $D$ 下,$c N^\gamma/D^\delta$(随 $N$ 增大)与 $a/N^\alpha$(随 $N$ 减小)的竞争产生一个 内部最小值 $N^*(D)$(Appendix J)——这意味着 对于有限数据量,存在一个模型大小,超过它后再加 compute 也无法降低 loss,反而 会变差*。这种 U 形是其他参数化形式(survey 见 Section 5)都缺失的结构性特征。
饱和包装器¶
包装器 $w(h) = h/(1+h)$ 是从 $[0, \infty)$ 到 $[0, 1)$ 的单调双射,有两个性质:
- Small-$h$ 线性:当 $h \ll 1$ 时,$h/(1+h) = h - h^2 + h^3 - \cdots$,所以 Eq. (2) 在领先阶近似为 $L \approx E + (L_0 - E)h$。这是 Chinchilla 被标定的 regime;形式自动退化到 Chinchilla($(L_0 - E)$ 前缀被吸收到 $h$ 各项的拟合系数)。
- Large-$h$ 饱和:当 $h \to \infty$ 时,$h/(1+h) \to 1$,$L \to L_0$。形式不会超过基线。
Appendix D 对比了另一个自然选择 $1 - e^{-h}$:两者在 5 个 LLM grid 和 4 个内部域上经验表现相当,无明显优劣。默认选择 $h/(1+h)$ 出于解析简洁性——它的逆 $w^{-1}(L_{\rm rel}) = L_{\rm rel}/(1 - L_{\rm rel})$ 是有理函数,便于成本分配分析(Appendix K)。
未训练基线 $L_0$¶
$L_0$ 是 未训练基线 的 loss——一个完全没有学习数据的模型。它由 loss 类型和输出归一化决定,不参与拟合:
- 对 vocabulary 大小 $V$ 的 next-token cross-entropy:$L_0 = \ln V$(Appendix A);
- 对 $K$-way 分类:$L_0 = \ln K$;
- 对 z-normalized targets 的 relative-$L_2$ regression ($L = \|\hat{u} - u\|_2/\|u\|_2$):$L_0 = 1$(零预测下严格成立);
- 其他有界 loss 取相应未训练-基线极限。
Chinchilla 恢复(Appendix C, Proposition 1):在三个条件下——(i) 单 epoch 约定 $T = D$,(ii) 小 $h \leq 0.1$,(iii) overfitting 项可忽略——Eq. (2) 退化到 Eq. (1),$O(h^2)$ 修正以内,参数映射为 $A = (L_0 - E)a$,$B = (L_0 - E)b$。Chinchilla 的标定常数 $A \approx 406$、$B \approx 411$、$L_0 - E \approx 9.13$ 给出 $a \approx 44.5$、$b \approx 45.0$;$\alpha, \beta, E$ 直接转移;$(c, \gamma, \delta)$ 在 Chinchilla grid 上经验上很小,CI 较宽(多 epoch 数据才能把它们 pin 紧)。
定性行为¶
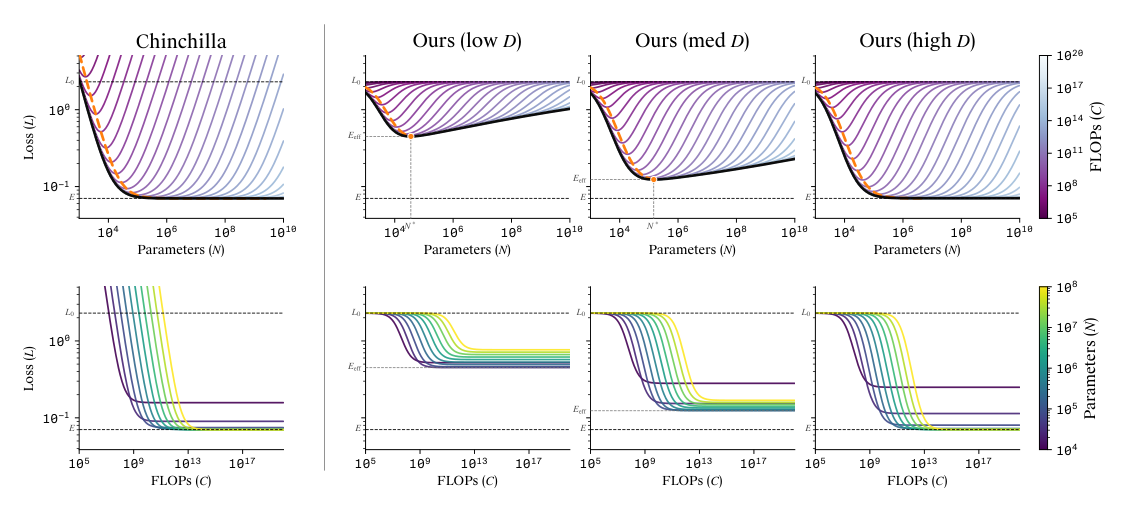
Figure 1 横向对比 Chinchilla(左列)与本文形式(右三列,三种 $D$)。IsoFLOP 视角(顶行,loss vs $N$ 在固定 $C$):Chinchilla 的 isoFLOP 是 U 形——两端发散到无穷,单个最小值定义 compute-optimal 模型大小,并随 $C$ 增长右移并逼近 $E$。本文形式 在最优附近共享这个 U 形,但 两端不同:尾部饱和到 $L_0$,对任意有限 $D$ 不收敛到 $E$ 而是收敛到 $E_{\rm eff} \gt E$。当 $D$ 增大时 $N^*$ 右移、$E_{\rm eff}$ 下降逼近 $E$。无限 data + compute 极限下与 Chinchilla 重合。
训练轨迹视角(底行,loss vs $C$ 在固定 $N$):Chinchilla 轨迹单调下降到不同 plateau(小模型更早 plateau,但更高)。本文形式起始于 $L_0$(饱和上界)然后衰减到一个渐近——但 渐近本身在 $N$ 增大时先降到 $E_{\rm eff}$ 再回升(这就是 U 形)。这种 capacity > optimal 时性能回升的现象是 Chinchilla 表达不出的。
Experiments¶
设计¶
作者分两部分实证验证:
Part 1:多域、多 epoch 训练实验(Appendix H)。作者亲自训练 4 个 architecture × domain 对,覆盖 prior scaling-law 工作未充分探索的 $(N, D, T)$ 立方体:
| 域 | 任务 | 架构 | $N$ 范围 | $D$ 范围 | $L_0$ |
|---|---|---|---|---|---|
| MNIST | 10-way 数字分类 | 2-hidden-layer ReLU MLP | 13K – 74M | 10 – 60K images | $\ln 10 \approx 2.30$ |
| CIFAR-100 | 100-way 图像分类 | PreActResNet | 84K – 7.5M | 500 – 50K images | $\ln 100 \approx 4.61$ |
| Darcy | 2D Darcy 流 PDE 求解 | Fourier Neural Operator | $\approx 90$K – $\approx 3.2$M | 10 – 9K $(a, u)$ pairs | 1 (relative-$L_2$) |
| TinyStories | next-token language modeling | GPT-style decoder-only transformer | 344K – 28.8M | $10^4$ – $5 \times 10^8$ tokens | $\ln 2000 \approx 7.60$ |
MNIST 使用 constant LR、无 cooldown,所以每个 checkpoint 都是一个有效的 end-state 观测——可以收集每个 cell 的整条 $L(N, D, T)$ 轨迹。CIFAR-100、Darcy、TinyStories 采用 Hägele 等 [17] 的 Warmup-Stable-Decay (WSD) schedule:每个 $(N, D)$ cell 一条 constant-LR 主 run + 多个 log-spaced 的 cooldown fork 在不同 $T_{\rm total}$ 处分叉,记录 cooldown 后的 final loss。WSD 让一条主 run 多次重用,节省算力。
Part 2:refit 到 5 个公开 LLM scaling-law grid(Appendix I):
- Chinchilla [26]:DeepMind 公开的 245 行 isoFLOP-3 grid,$N \in [5.7 \times 10^7, 1.6 \times 10^{10}]$,$D \in [2.4 \times 10^8, 3.2 \times 10^{11}]$,单 epoch。canonical compute-optimal reference。
- Muennighoff [36]:唯一公开的 $T \gt D$(多 epoch repetition)grid,C4 上 296 行,$N \in [7.1 \times 10^6, 8.7 \times 10^9]$,重复比 $T/D$ 在固定 $(N, D)$ 下变化。
- Gadre [16]:over-trained regime grid,token multiplier $M = D/N$ 从 Chinchilla-optimal ~20 一直到 ~640,单 epoch。
- Porian [41]:Kaplan stand-in,因为 Kaplan 2020 原数据不公开。Porian 在 RefinedWeb 上以 Kaplan-style LR schedule 重跑 Chinchilla-style 训练。
- Farseer [29]:最大的公开单-recipe scaling-law 数据集(>400 dense-LM runs),cosine-to-zero LR schedule,单 epoch,9 参数 $L(N, D)$ form 在 ~1000 模型上报告 SOTA 外推。
拟合协议¶
- 比较的 form:本文形式(Eq. 2)vs 五个 baseline:Chinchilla (Eq. 1)、Muennighoff(多 epoch 通过 effective-data 替换 $D \to D'$)、M4 [1](单轴 implicit form,bounding $L \in [E, L_0]$,与本文 wrapper 结构最相似)、BNSL [12]($4+3k$ 参数的 smoothly-broken power law 在复合 scalar $x(N, D, C)$ 上,唯一能拟合非单调 $L(N)$ 的 baseline)、Farseer [29]($L(N, D)$ form,$N$-dependent exponents,9 参数)。
- Form fitting:每种 form 的自由参数通过 Huber loss on log-residuals 最小化,BFGS 优化,bootstrap resampling 200 次给出 CI。
- 外推协议:两种 holdout(约占 10% 行)——high-$C$ holdout(按 $C$ 分组,10% 最高 $C$ 用于 held-out)和 high-$D$ holdout(按 $D$ 分组,最高-$D$ 整组)。
主结果:High-$C$ / High-$D$ Holdout¶
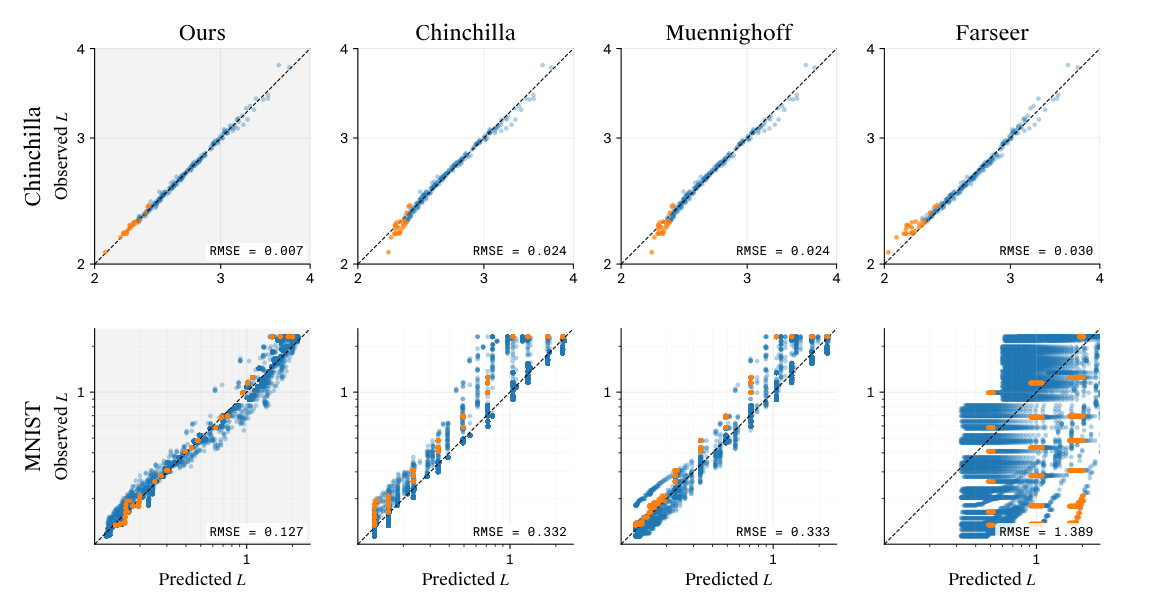
Figure 3 给出 Chinchilla grid(顶)和 MNIST grid(底)的 observed vs predicted 散点。每图 RMSE 标在右下:本文形式的 RMSE 是 0.007(Chinchilla)和 0.127(MNIST),分别比第二名 Chinchilla form 的 0.024 和 0.332 降低 3-3.4×。
Table 2: high-$C$ / high-$D$ extrapolation(log space RMSE,越低越好):
High-$C$ holdout:
| Form | MNIST | CIFAR-100 | Darcy | TinyStories | Chinchilla | Muennighoff | Gadre | Porian | Farseer |
|---|---|---|---|---|---|---|---|---|---|
| Chinchilla [26] | 0.332 | 0.156 | 0.322 | 0.173 | 0.024 | 0.092 | 0.038 | 0.100 | 0.028 |
| Muennighoff [36] | 0.333 | 0.151 | 0.181 | 0.095 | 0.024 | 0.087 | 0.038 | 0.115 | 0.020 |
| M4 ($D$-axis) [1] | 0.295 | 0.126 | 0.404 | 0.337 | 0.067 | 0.094 | 0.074 | 0.111 | 0.111 |
| BNSL $k=2$ [12] | 0.309 | 0.117 | 0.404 | 0.324 | 0.094 | 0.094 | 0.105 | 37.261 | 0.111 |
| Farseer [29] | 1.389 | 0.607 | 0.375 | 0.119 | 0.030 | 0.108 | 0.053 | 0.069 | 0.020 |
| Ours (Eq. 2) | 0.127 | 0.081 | 0.168 | 0.184 | 0.007 | 0.059 | 0.014 | 0.063 | 0.008 |
High-$D$ holdout:
| Form | MNIST | CIFAR-100 | Darcy | TinyStories | Chinchilla | Muennighoff | Gadre | Porian | Farseer |
|---|---|---|---|---|---|---|---|---|---|
| Chinchilla [26] | 0.123 | 0.182 | 0.388 | 0.057 | 0.028 | 0.112 | 0.038 | 0.115 | 0.017 |
| Muennighoff [36] | 0.122 | 0.171 | 0.187 | 0.095 | 0.028 | 0.079 | 0.038 | 0.115 | 0.017 |
| M4 ($D$-axis) [1] | 1.914 | 0.886 | 0.361 | 0.223 | 0.036 | 0.101 | 0.119 | 0.321 | 0.080 |
| BNSL $k=2$ [12] | 0.169 | 0.332 | 66.018 | 69.620 | 0.042 | 0.103 | 0.105 | 0.139 | 0.070 |
| Farseer [29] | 1.490 | 0.899 | 0.462 | 0.060 | 0.012 | 0.113 | 0.053 | 0.100 | 0.041 |
| Ours (Eq. 2) | 0.137 | 0.069 | 0.170 | 0.053 | 0.010 | 0.044 | 0.014 | 0.033 | 0.005 |
关键结论:
- 5 个公开 LLM grid,10 列(5 grid × 2 holdout)本文形式赢下全部 10 列,平均 RMSE 比第二名低 49%。
- 4 个内部域 8 cell(4 域 × 2 holdout)赢下 6 个——唯一两个失利的是 high-$C$ TinyStories(0.184 vs Muennighoff 0.095)和 high-$D$ MNIST(0.137 vs Muennighoff 0.122)。
- TinyStories high-$C$ 缺陷由"asymptote 估计过低"导致(详见 Section "远外推" 与 Appendix L),用 one-sided log-space prior on $E$ 可把 RMSE 减少 4.4× 到 0.042。
- MNIST high-$D$ 缺陷由 cross term $c N^\gamma/D^\delta$ 在 被设计来捕获的小-$D$ 极端 overfitting regime 上拟合后,在 held-out 大-$D$ regime(overfitting 已经很弱)上 过度外推* 导致(详见 Appendix M)。
Take-away:扩展的两个机制(saturating wrapper 和 cross term)共同提供了 Chinchilla 的严格 改进,而非性能 trade-off。Chinchilla、Gadre、Porian、Farseer 这四个 LLM grid 都是单 epoch、数据充足的——本文形式被设计来处理的 multi-epoch / data-constrained regime 在这些 grid 上 没有发生过,但形式仍然 在所有列上赢。这说明扩展的结构性收益不需要"在 data-constrained regime 上才能见效"。
算力开销¶
整个实验 campaign 在 AWS Batch 单 A10G GPU job (g5.2xlarge) 上运行,总计约 206 GPU-hours:MNIST ~46h、CIFAR-100 ~14h、Darcy ~48h、TinyStories ~98h。总 measured training compute ~$6.0 \times 10^{18}$ FLOPs,TinyStories 占大头($4.8 \times 10^{18}$)。这个 footprint 显著低于公开 LLM grid(Farseer 460 raw runs、Chinchilla 245 isoFLOP-3 cells 等),证明 fitting form(而非 generating data)是这种 scaling-law 工作里 incremental work 的主体。
远外推与单边对数空间先验¶
Far extrapolation 的问题¶
Section 3.2 的 high-$C$/high-$D$ holdout 是从 训练 run 的一般分布 内部抽出。Far extrapolation 更激进——预测远超 fit-time 见过的 compute 的 hold-out run。Farseer 数据集自带这样的 benchmark:val_big_d_full.csv 文件包含 7 个 held-out 模型 (widths $w \in \{2304, 2432, 2752, 3072, 3328, 5120\}$, $N \in [2.27\text{B}, 25.1\text{B}]$),held-out compute $C \in [6.8 \times 10^{21}, 2.0 \times 10^{22}]$ FLOPs (2 到 6× 超过 cohort 的 $C \lt 3.5 \times 10^{21}$)。target loss 在 [1.78, 1.88] nats,远超 fitted asymptote。
Naïve far-extrapolation results(log-loss space mean/median/max |err| + MBE):
| Form | Mean |err| | Median |err| | Max |err| | MBE |
|---|---|---|---|---|
| Chinchilla (5 params) | 0.0204 | 0.0165 | 0.0383 | +0.0204 |
| Farseer (9 params) | 0.0115 | 0.0101 | 0.0317 | -0.0102 |
| Ours, vanilla (8 params) | 0.0382 | 0.0355 | 0.0567 | -0.0382 |
本文 vanilla 形式 排名最后,输给了 Chinchilla 和 Farseer。MBE = -0.0382 说明 系统性低估 loss,幅度是 Chinchilla 高估的 1.9 倍。
诊断:wrapper-induced $E$-collapse¶
作者诊断这个 under-prediction 不是拟合偶然,而是 wrapper 家族的结构性缺陷:
-
asymptote 是外推出来的,不是测出来的:在 fit range 内,$E$ 只能通过"曲率需要落到哪里来匹配"被识别。任何 form 表达不了的慢尾(不可降低 label noise、表达能力 floor、distribution-shift residual)会被吸收到 $a/N^\alpha + b/T^\beta + c N^\gamma/D^\delta$ 这些 power-law 项里——它们永远不会归零,所以 $E$ 被投影到这些项延伸到的地方。Farseer 的 fit $E = 0.315$,target loss $L \approx 1.83$ 比该 $E$ 高 1.16 nats;Chinchilla fit 的 $E = 1.471$,target 在 $E$ 之上 0.36 nats。本文形式把 asymptote 放到了数据真实平坦化处之下。
-
wrapper 可识别性塌缩:饱和 wrapper $L = E + (L_0 - E) \cdot h/(1+h)$ 让 $E$ 和 swing 系数 $(L_0 - E)$ 在 fit window 里 quasi-collinear——任何满足局部方程的 $(E, L_0 - E)$ pair 在 bulk 里都同样好,所以 $E$ 只在观测靠近 asymptote 时才被识别(这恰恰是 far extrapolation 想避免的)。lower $E$ 把 $(L_0 - E)$ swing 放大,把 wrapper 的高曲率拐点 (h=1) 推进 fit data 占据的 loss range 里,optimizer 用边际更低的 bulk Huber loss 奖励这种行为。
-
log-space fitting 对 asymptote 慷慨:fit 最小化 $(\log \hat{L} - \log L)^2$。靠近 floor 处,即使绝对小残差在 log-fraction 上也很大,fit 努力匹配最低-loss anchor 点;少有 low-loss anchor(far extrapolation 的定义),这个 pull 约束差,倾向拖低 $E$。
修正:单边对数空间先验 on $E$¶
修正直接源自诊断:当 $E$ 不能被 bulk fit 唯一识别(没有靠近 asymptote 的观测),加一个 弱外部约束,只在 optimizer 把 $E$ 推到一个经验 floor 之下时才介入。Augment Huber 目标加一个 one-sided $L_2$ hinge on $\log E$:
$$\mathcal{L}^*(\theta) = \mathcal{L}(\theta) + \lambda \cdot \left[\max\left(0, \log(m/\kappa) - \log E\right)\right]^2 \tag{15}$$
其中 $m = \min L_{\rm obs}$ 是 training cohort 上观测到的最低 loss,$\kappa = 1.5$ 是固定 offset(floor 设在最低 observed loss 的 33% 之下),$\lambda = N_{\rm train}/4$ 随 cohort 大小线性 scale 以保持先验相对于 Huber sum 的强度恒定。当 $E \geq m/\kappa$ 时 penalty 为零,下方 平滑活跃。在 $E$ 已经被良好识别的 grid 上 prior 是 strict no-op——形式的数学结构不变,预测仍由 $L = E + (L_0 - E) \cdot h/(1+h)$ 计算,只有参数选择目标多了一个 hinge。
修正后结果:
| Form | Mean |err| | Median |err| | Max |err| | MBE |
|---|---|---|---|---|
| Chinchilla (5 params) | 0.0204 | 0.0165 | 0.0383 | +0.0204 |
| Farseer (9 params) | 0.0115 | 0.0101 | 0.0317 | -0.0102 |
| Ours, vanilla | 0.0382 | 0.0355 | 0.0567 | -0.0382 |
| Ours, $E$-hinge prior | 0.0174 | 0.0148 | 0.0385 | -0.0174 |
prior 让本文形式从 worst 移动到 第二名——在每列上超过 Chinchilla,跟随 Farseer。Fitted $E$ 从 0.315 升到 1.211(vs Chinchilla 1.471,held-out target 1.83)。MBE 从 -0.0382 塌缩到 -0.0174,比 Chinchilla 的 +0.0204 还小。held-out RMSE in $L$-space drops 从 0.0391 (vanilla) 到 0.0201 (prior),1.95× reduction。
TinyStories high-$C$ 上的同样配方¶
把同样的 prior 应用到 Section 3.2 TinyStories high-$C$ holdout(vanilla fit 也是 $E$-collapse):held-out log-RMSE 从 0.184 降到 0.042(4.4× reduction),把本文 form 在该协议上从第 4 名升到第 1(best baseline Muennighoff 0.095)。Figure 4 (bottom row) 给出与 Farseer 一样的诊断:vanilla 把 held-out points 系统性预测在对角线下方(under-predicting),配方把它们推回对角线。
适用边界:在已经 $E$ well-identified 的另外 3 个 TinyStories 协议(high-$D$、low-$C$、low-$D$)上,prior 改变 log-RMSE 小于 optimizer noise floor——所以 prior 在 saturating-wrapper form 上 默认安全部署。它 不应 被应用到 additive baselines (Chinchilla、Muennighoff、Gadre、BNSL、M4、Farseer):被迫上推会扭曲 additive decay 项。prior 是 wrapper family 的属性,不是普适修补。
Cost-Aware Allocation¶
一个标定好的 $L(N, D, T)$ 回答两个工程问题:
- (P1) Target-loss optimum:给定目标 loss $L^*$,最低 dollar 成本 $\mathcal{B}^*$ 是多少,预算如何分配?
- (P2) Budget-constrained optimum:给定 dollar 预算 $\mathcal{B}_{\rm max}$,可达到的最低 loss 是多少,分配如何?
Setup:设 $\rho_D$ 是每个 unique example 的 dollar 成本(label、simulation run、scraped token 等),$\rho_C$ 是每 FLOP 的 dollar 成本。dollar 成本:
$$\mathcal{B}(N, D, T) = \rho_D \cdot D + \rho_C \cdot kNT \tag{9}$$
(P1) 和 (P2) 是 dual:相同 Lagrangian 控制,最优 $(N^*, D^*, T^*)$ 同时是两者的解。
(P1) Target-loss optimum¶
构造 Lagrangian $\mathcal{L}_1 = \mathcal{B} + \mu(L - L^*)$,stationarity 条件给出:
$$-\frac{\rho_C kT}{\partial L/\partial N} = -\frac{\rho_D}{\partial L/\partial D} = -\frac{\rho_C kN}{\partial L/\partial T} = \mu \tag{10}$$
即 最优时每美元降 loss 的边际效率在 $(N, D, T)$ 三轴上相等。
(P2) Budget-constrained optimum¶
Lagrangian $\mathcal{L}_2 = L + \lambda(\mathcal{B} - \mathcal{B}_{\rm max})$:
$$\frac{\partial L/\partial N}{\rho_C kT} = \frac{\partial L/\partial D}{\rho_D} = \frac{\partial L/\partial T}{\rho_C kN} = -\lambda \tag{11}$$
即 每美元 marginal loss reduction 三轴相等。两组 stationarity 条件互为倒数,两个问题 trace 同一个 Pareto frontier。
Feasibility 与 boundary¶
反转 wrapper:要达到 target $L^*$,所需 difficulty $h^* = (L^* - E)/(L_0 - L^*)$。$h^*$ 在 $L^* \in (E, L_0)$ 内 positive finite:
- $L^* \lt E$:低于 irreducible loss,(P1) 无解,Newton 发散;
- $L^* \geq L_0$:trivially 可达(未训练模型已经满足),$\mathcal{B}^* \to 0$;
- $L^* \to E^+$:$h^* \to 0$,需要 $a/N^\alpha + b/T^\beta + cN^\gamma/D^\delta \to 0$ 同时——成本 $\to \infty$。
在 feasible interior 内,optimum 在 finite $(N^*, D^*, T^*)$。任意固定 $D$ 下,形式承认 finite interior minimum $N^*(D)$(U 形),$L^*(D) \gt E$。
数值求解与 log-convexity¶
替换 $u = \log N$, $v = \log D$, $w = \log T$,$h = ae^{-\alpha u} + be^{-\beta w} + ce^{\gamma u - \delta v}$ 是 affine functions 的 exponential 和,严格 log-convex($a, b, c, \alpha, \beta, \gamma, \delta \gt 0$ 时 Hessian 正定)。Wrapper $h/(1+h)$ monotone 所以 $L$ 在 $h$ 中 monotone,feasible set 凸;最小化严格凸函数得到唯一 minimum。标准 convex-optimization 工具从任意可行起点 converge。
Asymptotic regimes¶
dollar 成本比 $\eta = \rho_D / \rho_C$ trace 两个极限的 continuum:
- $\eta \to 0$(data free):overfitting 项消失,$(N^*, T^*)$ 重新逼近 Chinchilla compute-optimal,$T$ 轴扮演 Chinchilla $D$ 轴角色。
- $\eta$ 很大(data expensive):overfitting 项 binding,optimum 走向更小 $D$、更多 epochs(更大 $T/D$)、更小 $N$。这是 Muennighoff 等定性记录但 Chinchilla-style cost-aware 分析 [43, 4, 6] 无法表达 的 data-expensive corner——它们继承 Chinchilla 无 overfitting 项的 loss form。
Illustrative allocation table¶
在固定预算 $\mathcal{B}_{\rm max}$,用 Chinchilla 的 fitted exponents $(\alpha, \beta) = (0.34, 0.28)$ [26] 与 illustrative overfitting constants $(c, \gamma, \delta) = (2 \times 10^3, 0.5, 1.0)$(选取以保证 overfitting 项在 LLM-scale $(N, D)$ binding):
Table 3: Cost-optimal allocation (illustrative):
| $\eta$ | $N^*$ | $D^*$ | $T^*/D^*$ | $L^*$ | data $\$ share |
|---|---|---|---|---|---|
| 0 (Chinchilla CO) | $5.2 \times 10^9$ | $3.2 \times 10^{11}$ | 1.0 | 2.14 | 0% |
| $10^{10}$ (web tokens) | $4.4 \times 10^9$ | $1.2 \times 10^{11}$ | 2.7 | 2.14 | 12% |
| $10^{12}$ (licensed corpora) | $1.2 \times 10^9$ | $6.3 \times 10^9$ | 80 | 2.30 | 63% |
| $10^{13}$ (expert/sim) | $2.1 \times 10^8$ | $8.6 \times 10^8$ | 1,250 | 2.66 | 86% |
把 $\eta$ 从 0 增长 1000×(web-token 经济到 expert-label 经济):optimal $D^*$ 缩小两个数量级,optimal $N^*$ 缩小 ~20×,$T^*/D^*$ 从 1 走到 ~1,250 epochs,最优数据预算份额从 12% 跳到 86%。一个 price ratio 被翻译成一个具体分配——这是 cost-aware allocation 的核心实用价值。
Ablation 与诊断¶
组件消融¶
Table 6 (high-$C$) 与 Table 7 (random 5-fold) 给出 4 个 ablation:
- dropping the wrapper(recover Chinchilla-plus-cross-term):marginally hurts on 2 columns we flagged as deficits(TinyStories high-$C$、MNIST high-$D$),其他 non-trivial overfitting 列上失败。
- dropping the overfitting term:MNIST/CIFAR-100 RMSE 增长 5–13×,Muennighoff multi-epoch grid 上 2–3×;单 epoch grid(Chinchilla、Gadre、Porian、Farseer)上 no-overfit variant 退化到 Chinchilla-plus-wrapper,性能与 Chinchilla 接近。
- swap wrapper to $1-e^{-h}$:跨所有 datasets/protocols 统计上不可区分(aesthetic choice)。
- replace $cN^\gamma/D^\delta$ with single-exponent $c(N/D)^\gamma$:在数据丰富单 epoch grid 上 narrowly wins(两 exponent 弱可分),但 MNIST 上 RMSE 增长 5–9×、CIFAR-100 上 4–5×;single-exponent simplification 只在 data-plentifulness 可预先假设时可用。
LLM grid wins 的分解¶
5 个 LLM grid 的 wins partition:
- Removing cross term hurts(Chinchilla、Muennighoff、Farseer):RMSE 增长 2–7×,wrapper 单独效果 small;
- Removing wrapper hurts(Gadre、Porian):cross term 在这里贡献几乎为零,wrapper removal 恢复 Chinchilla baseline 性能。
结论:两个结构性扩展互补——cross term 拣起 additive form $a/N^\alpha + b/T^\beta$ 表达不出的 joint $(N, D)$ residual structure;wrapper 拣起 additive form 只能线性 bound irreducible loss 的 saturating approach。每个 grid 上其中一个是 dominant unmodeled component。
MNIST high-$D$ 的失败诊断(Appendix M)¶
Sweep A(contamination grows,target fixed at asymptote):从 small-$D$ cell ($D \in \{10, 20, 50, 100\}$) 逐步加入 training,看 RMSE 在 $D = 60{,}000$ held-out 上变化:
| $k$ | smallest $D$ in train | Ours | Chinchilla | Muennighoff |
|---|---|---|---|---|
| 5 | 1000 | 0.087 | 0.107 | 0.086 |
| 6 | 320 | 0.084 | 0.109 | 0.094 |
| 7 | 100 | 0.096 | 0.111 | 0.093 |
| 8 | 50 | 0.098 | 0.112 | 0.096 |
| 9 | 20 | 0.108 | 0.110 | 0.098 |
| 10 | 10 | 0.126 | 0.159 | 0.109 |
$k = 6$ 时 ours wins cleanly(0.084 vs Muennighoff 0.094)。每加一个 smaller-$D$ cell,本文 RMSE 单调上升,bias 在 $k = 5$–7 时为负(under-prediction),到 $k = 10$ 翻为 +0.085 over-prediction。contamination threshold 在 $D = 20$ 与 $D = 50$ 之间。
Sweep B(contamination held maximal,target slides up):小-$D$ cell 全部在 training,held-out 从 $D = 320$ 滑到 60,000:本文 mean bias 从 +0.17 到 +0.21 全部 over-prediction in log space(predictions ~20% too high)over 4 orders of magnitude in $D$ where overfitting has ebbed。over-extrapolation 是宽的,不是 asymptote-specific。
Scope of validity:cross term 在 extreme small-$D$ overfitting cell 上 absorb 的 fit-time penalty 不随 $D$ 衰减,对每个 other $D$ 都贡献 positive residual。实践建议:在 grid 包含 extreme small-$D$ cell 时,把它们从 training set 中排除。结构性 fix(在全 $D$ range 上保持 cross-term well-behaved)留给 future work。
Auto-Discovered 12-Parameter Form(Appendix P)¶
作者尝试用 自动 form search 探索是否存在比 8 参数 headline form 更精确的参数化:让一个自主 Claude Code agent [2] (Claude Opus 4.7 [3]) 在 14 轮 BFGS loop 上提议、拟合、选择 form。每轮:(i) 检查当前 leader 的 per-cell residual diagnostics;(ii) 提议小修改;(iii) parallel 拟合所有 candidate;(iv) 更新 leaderboard。
Functional form:12 参数 extended form
$$h(N, D, T) = \frac{a}{N^\alpha} + \frac{b}{T^{\beta_{\rm eff}(N, D)}} + \frac{c N^\gamma}{D^\delta} + e \left(\frac{N}{D}\right)^\phi, \quad L = E + (L_0 - E)(1 - e^{-h}) \tag{16}$$
with $\beta_{\rm eff}(N, D) = \beta_0 + \beta_N \ln N + \beta_D \ln D$(clamped to $[0.01, 5]$)。三个改变:(a) undertraining exponent log-linear in $\ln N$ 和 $\ln D$;(b) 加第二 overfitting cross term $e(N/D)^\phi$;(c) saturating wrapper 切换到 $1 - e^{-h}$。
实证性能:12 参数 extended form 在 9 datasets × 4 protocols 几乎每列上 RMSE 最低或并列最低,超过 headline form 和所有 external baselines。最大 margin 在 data-constrained MNIST/TinyStories,最小在 LLM grid。但 extended form 被排除在 per-column rankings 外——它带 4 个额外参数,且由一个 optimizing against 当前 fit metric 的 agent 发现,所以有 oracle-like 优势 structural baselines 没有。
Caveats:extended form 无理论 grounding:$\beta_{\rm eff}(N, D)$ 不从 LR schedule 或 capacity argument 派生,$e(N/D)^\phi$ 不对应 separable underperformance mechanism;可识别性弱($(\beta_0, \beta_N, \beta_D)$ 联合 poorly constrained,>50% multistart disagreement on individual datasets),bootstrap intervals on derived quantities (e.g., $N^*$) 会宽。
作者保留 8 参数 headline form 作为推荐:(i) 每项有 structural justification(Section 2),(ii) parameter-identification table(Appendix F)给出每参数 empirical regime,(iii) cost-allocation analysis(Appendix K)承认 extended form 没有的 closed-form stationarity 条件。extended form 作为 empirical upper bound 包含——给出"parsimony 是否花费 material accuracy"问题的答案:确实有,但不足以替换 structural justifiability 作为 headline 标准。
Limitations¶
- In-distribution validation loss only:本文 scaling law 预测 in-distribution validation loss(held-out from same distribution)。Downstream task performance scaling [16]、task-level metrics、emergent capabilities、out-of-distribution behavior 是 scaling-law stack 的 separate layer,超出 scope。
- Double descent:经典 double descent [8, 37] 研究 在 interpolation threshold $N \approx D$ 而非 asymptotically far from it。本文 form asymptotic and smooth,不预测 $N \approx D$ 处的 peak。Form 不尝试 capture this structure;experiments 也未观察到该现象(likely 因为 best-so-far validation loss 抑制了 model-wise peak [21, 37],且 peak 的窄 $N$ range 落在 log-spaced grid 的 cell 之间)。
- Universality of form, not of fits:claim form 的 generality,不是 fitted constants 的 portability。架构选择、训练 recipe、parameter-counting convention 被吸收到 $(E, a, b, c, \alpha, \beta, \gamma, \delta)$,跨设置不可移植。统一一个 form 跨这些 choices 超出 scope;practitioner 应该 hold these fixed across calibration grid 并 per-setting recalibrate。
- Optimistic $E$ in far compute extrapolation:saturating wrapper 使 $E$ 只在观察靠近 asymptote 时 identifiable;prior 是 wrapper family 的属性,不是 universal tweak。
- Modeling low-$D$ regime:MNIST high-$D$ 上 cross term $c N^\gamma/D^\delta$ 在 small-$D$ extreme overfitting cell 上 fit 后,外推到 held-out 大-$D$ regime(overfitting 已经消失)时贡献 positive residual。Practical use 可以排除 extreme small-$D$ cell 从 training;structural fix 留给 future work。
与已归档相关工作的对比¶
Prescriptive Scaling Laws for Data Constrained Training Prescriptive Scaling Laws for Data Constrained Training (Cornell, 2026-05-02)¶
关系:独立并发(本文未引用 Cornell Prescriptive Scaling Laws,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两者都直击 Chinchilla 在数据受限 / 多 epoch 训练下 无法表达 loss 随 capacity 上升而回升 的结构性失效,并明确指出 Muennighoff 等的 effective-data 形式($D \to \hat{D}$ 替换)只能描述递减回报、不能描述"过拟合阶段 loss 回升"。两篇都是 May 2026 同一周(5 月 2 日 vs 5 月 9 日)发布,互不引用,是教科书级的独立并发工作。
- 相近的技术骨架:两篇都选择"在 Chinchilla 上加显式 overfitting 项"的解法路径——拒绝 effective-data 的间接表达,承认 overfitting 是 第三个 与 (capacity, data sufficiency) 并列的失效机制。两者的过拟合项都带 两个独立指数:本文 $c \cdot N^\gamma / D^\delta$,Cornell 4-参数形式 $P \cdot R_D^\delta \cdot (N/U_D^\gamma)^\kappa$。两者都明确指出 N 和 D 的标定应当独立,因为它们通过不同的机制(capacity-driven excess representation vs sample-size variance of empirical-risk minimizer)影响泛化。两者都验证 prescriptive 建议——cost-optimal allocation 与 Chinchilla 定性不同。
- 本文的差异与推进:(a) 饱和包装器 $h/(1+h)$:把整个 loss 限定在 $[E, L_0]$ 闭区间,loss 不会发散到 $+\infty$ — Cornell 的 additive penalty 在 $R_D \to \infty$ 时 $L \to \infty$,没有未训练基线 ceiling,无法表达"训练完全崩溃时模型退化到 random init"的极限行为。(b) 算力轴 $T$ 与数据轴 $D$ 解耦:本文显式区分 $T$(总样本数,含重复)和 $D$(unique),undertraining 项 $b/T^\beta$ 随 任何 gradient step 减少(不论新旧 example)— Cornell 把"重复 token 的角色"在 data-sufficiency 项与 penalty 项 双重 计入,但仍以 $D = U_D \cdot (1 + R_D)$ 作为 input,没有独立 $T$ 轴。(c) 跨域跨架构验证:本文跨 vision/scientific ML/language 4 域 + 5 个公开 LLM grid(共 9 个 grid)— Cornell 限于 FineWeb + Llama 2 一种架构,扩展到 Muennighoff C4 验证 generalization,但范围更窄。
- 可比的方法/实验差异:Cornell 在 fit quality 上给出更直接的 multi-epoch $R^2$:1p form $R^2_{\rm multi}$ 0.95 vs Chinchilla 0.58;4p form 0.9945。本文给出 held-out RMSE:高-$C$ 协议下 average 49% lower than 2nd best。两者的 prescriptive 建议方向 相同——都建议在数据受限下放弃 "more epochs is always good" 的 Chinchilla 直觉;但具体方向有微妙差异:Cornell(fixed $U_D$ 和 $C$)建议 更大模型 + 更少 epoch;本文(按 cost ratio $\eta$)建议 更小模型 + 更多 epoch(当 $\eta$ 大、data expensive 时)。这不矛盾——Cornell 固定 unique data budget 比较"加 model size 还是加 epoch",本文则把 unique data 视为决策变量之一,data 越贵越倾向少买、多 epoch。两者结合可以做"在数据受限下,先确定 $D$ 的预算,再在 $C$ 内选 (N, epochs)"的两阶段决策。Cornell 单独的额外贡献:把 weight decay 强度作为 prescriptive 工具——$\lambda = 1.0$ 把 overfitting 系数 $P$ 削减 70%,并预测 crossover compute level。本文单独的额外贡献:cost-aware allocation 的 closed-form Pareto frontier 推导(Appendix K),允许把 $\rho_D/\rho_C$ 价格比直接翻译为分配方案;以及未训练基线 $L_0 = \ln V$ 作为结构上限,让形式具备"模型啥都没学到时退化到 random init"的极限行为。
核心贡献总结¶
- 形式简洁、结构有据:8 参数 closed-form $L(N, D, T) = E + (L_0 - E) h/(1+h)$,每项有明确物理含义(undercapacity、undertraining、overfitting),三个失败模式逐一对应;wrapper 把 loss bounded 在 $[E, L_0]$;小-$h$ 单 epoch 极限退化到 Chinchilla。
- SOTA 外推:在 5 个公开 LLM scaling-law grid 上 10/10 columns 都赢,average RMSE 比 2nd-best 低 49%。
- 可解释的 cost-aware 分配:从 $\rho_D/\rho_C$ 价格比 closed-form 推出最优 $(N^*, D^*, T^*)$;data 越贵分配越走向 small corpora + many epochs + small models,刻画 Chinchilla-form cost analysis 无法表达的 corner。
- 跨架构、跨域可迁移的结构:四个独立内部域(MLP/MNIST、ResNet/CIFAR-100、FNO/Darcy、Transformer/TinyStories)验证形式适用于 vision、scientific ML、language,再 refit 5 LLM grid 确认。
- 诊断到修补:远外推下 wrapper-induced $E$-collapse 通过 one-sided log-space prior 修正,TinyStories 上 4.4× RMSE 降低、Farseer far compute 上从最后一名升到第二名。
- 诚实的局限说明:MNIST high-$D$ 上 cross term over-extrapolates;远外推下 $E$ 仅在观察靠近 asymptote 时可识别;form universality 不等于 fitted constants portability;double descent 不被 capture。
讨论与局限性¶
值得借鉴的设计:
- 三机制分解 (undercapacity / undertraining / overfitting):把 loss 拆成三个 物理上独立 的失效项,每项有清晰的 limiting behavior(Table 1 row 1-5),让形式的边界行为变成 设计 而非 偶然——这种"先列约束,再构造形式"的设计范式值得在其他 scaling law 工作中推广。
- 饱和包装器 $h/(1+h)$:bounded loss form 把 wrapper 引入 scaling law literature 是结构性贡献。alternative wrapper $1 - e^{-h}$ 经验上不可区分,但 rational wrapper 让 inverse $h^* = L^*_{\rm rel}/(1 - L^*_{\rm rel})$ closed-form,便于 cost-allocation。
- 未训练基线 $L_0$ 作为 unit-bearing 常数:$L_0 = \ln V$(cross-entropy)或 1(relative-$L_2$ on z-normalized targets)由 loss type 决定而非 fitted,让形式具备 scale-equivariance($L \to kL$ 重 scale 下 $E \to kE$、$L_0 \to kL_0$,exponents 不变)。这种 "let physics fix the boundary" 的做法显著减少了参数数。
- Parameter identification table(Appendix F):明确把每个参数($E$、$a$、$b$、$c$、$\alpha$、$\beta$、$\gamma$、$\delta$)映射到 能识别它的 empirical regime——告诉 practitioner "如果你的 grid 缺少 small-$D$ multi-epoch cell,$c, \gamma, \delta$ 会 unidentified"。这是 scaling-law fitting 实践的高 bar 标准。
- 诚实记录失败模式:MNIST high-$D$ 上的 cross-term over-extrapolation(Appendix M)、far compute extrapolation 上的 $E$-collapse(Appendix L)都用 sweep 实验定位根因,不强行掩盖。这种 forensic 风格的局限说明让 form 更可信。
存在的局限/争议:
- 未引用 Cornell Prescriptive Scaling Laws (2605.01640):两篇 May 2026 同一周发布、解决几乎同一问题(数据受限下 overfitting 表达)、解法骨架类似(加显式 overfitting 项)。本文未引用 Cornell,Cornell 未引用本文——这是 timing 决定的,并非有意;但读者比较两篇时缺少 author-level 对比。Cornell 的 4-参数 form $P \cdot R_D^\delta \cdot (N/U_D^\gamma)^\kappa$ 与本文 $c N^\gamma / D^\delta$ 在 multi-epoch 上行为非常接近,本文如果加入对比会更完整。
- MNIST high-$D$ 的失败:cross term 在 extreme small-$D$ overfitting cell 上 fit 后,在 held-out 大-$D$ regime 上 系统性 过度 over-prediction(log space ~+20%, 4 orders of magnitude in $D$)。Practical fix(exclude extreme small-$D$ from training)是 ad-hoc 的,没有 structural fix。
- fitted constants 不可移植:Section 5 (Universality of form, not of fits) 明确承认,但这对 practitioner 是 大限制——每个新 architecture × dataset × recipe 组合都需要 expensive 重新 calibrate。这一限制本文未给出解决方案。
- far compute 上的 $E$-collapse:依赖 one-sided log-space prior 修正——$\kappa = 1.5$、$\lambda = N_{\rm train}/4$ 等 hyperparameter 是经验选取的,跨数据集是否需要重新 tune 未充分验证。
- 12 参数 extended form 的不一致:作者承认它"in-sample best 但 not theoretically grounded"。但用 Claude Code agent 14 轮 BFGS loop 发现的 form 与人工构造的 8 参数 form 拟合差距虽小但稳定,提示"theoretical grounding 不等于 best fitting"——这对 scaling law 工作的方法论有挑战意味,论文未深入讨论。
- double descent 不被 capture:作者承认形式 asymptotic and smooth,不预测 $N \approx D$ 处的 peak。如果未来更精细的 grid 测出 model-wise double descent,形式需要修补。
与已有工作的差异:
- Chinchilla [26]:本文是 Chinchilla 的 严格扩展——单 epoch 小-$h$ 极限即退化为 Chinchilla(Appendix C 证明),五个 Chinchilla 参数 $(\alpha, \beta, E, A, B)$ 严格对应于本文 $(\alpha, \beta, E, a(L_0-E), b(L_0-E))$。
- Muennighoff [36]:Muennighoff 用 effective-data 替换 $D \to \hat{D}$ 间接表达 repetition cost,本文显式拆成 separate overfitting term。两种 form 在 single-epoch 行为上 identical;在 multi-epoch 上本文承认了"capacity 与 data 通过不同机制影响 loss"。
- Farseer [29]:Farseer 用 $N$-dependent exponents($\alpha(N) = a_1 N^{a_2} + a_3$)让 Chinchilla coefficients 自适应,9 个参数。本文 8 个参数但通过结构性 wrapper 和 cross term 实现 SOTA 外推。两者代表两种思路:Farseer 让 exponents 灵活,本文让结构灵活。
- M4 [1]:M4 是 implicit single-axis form bounding $L \in [E, L_0]$,是本文 wrapper 最近的 structural analog——但 M4 是 single-axis(一个 scalar $x$ 而非 joint $h(N, D, T)$),不能 decompose loss 到 separate $N, D, T$ 贡献。
- BNSL [12]:smoothly broken power law $4+3k$ 参数,能拟合 non-monotone $L(N)$,但 breakpoint 位置和形状是 fit 出来的,而非由 $(N, D, T)$ 结构预测的。本文形式的 U 形是 预测 而非 拟合 的。
工业落地价值:
- 数据获取 vs 训练算力的 dollar-aware allocation:是 LLM 预训练实际操作里最直接可用的产出。给定 $\rho_D/\rho_C$(web token 抓取 vs licensed corpora vs expert label),从 Appendix K 的 closed-form recipe 算出 $(N^*, D^*, T^*)$。
- Physics surrogates / scientific ML 训练规划:Darcy / PDEBench / FNO 实验线给出了 scientific ML 上的 calibration——这类应用每个 training example 都来自 PDE solver,data cost 极高,本文的 cost-allocation 直接适用。
- 推荐系统大模型训练规划:虽然本文未直接覆盖推荐系统,但生成式推荐(HSTU、OneRec 等)面临类似的"用户行为序列重复利用"问题,cross term 表达 capacity vs unique users 比的 overfitting 适用——预期未来推荐系统 scaling law 工作会借用类似结构。
- 小机构友好:整个实验 campaign 206 GPU-hours 在 single A10G 上完成,证明"做出有用的 scaling-law 工作不需要 Hyperscaler 级算力"。Arena Physica 两人团队 vs DeepMind/Meta/字节 的 LLM scaling-law grid,data efficiency 对比鲜明。