研究动机与背景¶
问题的根源:item-only 用户序列是结构性瓶颈¶
序列推荐(SR)的主流范式将用户历史建模为按时间排序的交互 item 序列 $\mathcal{S}_u=[i_1,i_2,\dots,i_T]$,并通过下一个 item 预测(next-item prediction)来训练。从 GRU4Rec、BERT4Rec、SASRec 等基于 ID embedding 的判别式模型,到 TIGER、LETTER 等使用语义 ID(SID)的生成式推荐(GR)模型,这一 "item-only sequence + next-item objective" 的假设几乎未受触动。
RAGR 作者的核心论断是:这种 item-only 假设并不是一个被忽视的机会,而是一个结构性瓶颈。原因在于用户决策本质上是多面的:用户在购买前通常会进行浏览、比较,并在事后通过文本评论(review)等显式反馈表达使用感受。McAuley & Leskovec [17] 等工作早已指出,review 揭示了 hidden evaluative dimensions —— 质量、可用性、美学等评分驱动因素,这些信号在交互日志中是不可见的。
item-only 序列只记录了"用户选了什么(outcome)",却抹去了"为什么这样选(rationale)"。模型不得不仅凭 item 共现模式去推断用户意图,得到的偏好理解是浅层且脆弱的。
已有机制的不对称:tokenizer 的表达力没有被用在 review 上¶
值得注意的是,生成式推荐范式本来就具备解决这一瓶颈的机器:unified tokenizer 能将 item 文本内容投射到一个共享的离散 token 空间。但在当前实践中,这个 tokenizer 几乎只被用于 item(把每个 item 映射成 SID 给自回归生成使用)。事实上同一机制完全可以等价地作用于用户产出的任何文本信号——尤其是 post-interaction reviews。
换言之,已有研究极大地扩展了 item 表征的表达力,却几乎没碰 user sequence 的表达力。这种不对称引出本文的中心研究问题:
能否将 GR 的统一 tokenizer 重新利用来把 user review feedback 编码为语义 token,并织入交互序列,使模型不仅能捕捉行为结果(outcomes),还能捕捉底层的偏好理由(preference rationale)?
两个挑战¶
要把 review 当作"一等公民" token 注入到 GR 的生成序列中,需要解决两个相互纠缠的问题:
- 异质序列构建(Heterogeneous Sequence Construction):item 和 review 在粒度与功能上不同(item 是离散选择目标,review 是连续文本反馈);通过一个共享 tokenizer 把两者投影到一致的序列中需要精心设计,否则会引入噪声。
- 推荐目标保留(Recommendation-objective Preservation):一旦 review token 进入生成序列,需要一个有原则的对齐机制来确保它们扮演的是"支持性证据"角色,为 next-item prediction 服务,而不是变成与之竞争的生成目标。
针对以上两个挑战,论文提出 Review-Augmented Generative Recommendation(RAGR),包含两个互补组件:(i) Review-Augmented User Sequence Modeling,把 item SID 与 review SID 按时间顺序交错构成混合行为—语义序列,让 review context 直接参与自回归生成过程;(ii) Item-Centric Task Generation Alignment,使用 DPO 让模型在预测位偏向于生成 item SID 而非 review SID,确保学习目标仍锚定在 next-item recommendation。

问题形式化¶
令 $\mathcal{U}$、$\mathcal{I}$ 分别表示用户集与 item 集。对用户 $u\in\mathcal{U}$,观测到按时间排序的交互历史:
$$\mathcal{S}_u=\big[(i_1,r_1),(i_2,r_2),\dots,(i_T,r_T)\big] \tag{1}$$
其中 $i_t\in\mathcal{I}$ 是第 $t$ 步交互的 item,$r_t$ 是对应的文本反馈(如评论)。与只建模 item 序列的传统 SR 不同,RAGR 同时建模 item 交互与 review 反馈。在第 $t-1$ 步之前的历史是:
$$\mathcal{S}_u^{\lt t}=\big[(i_1,r_1),(i_2,r_2),\dots,(i_{t-1},r_{t-1})\big] \tag{2}$$
目标是学习一个生成式推荐模型:
$$f_\theta:\mathcal{S}_u^{\lt t}\mapsto i_t \tag{3}$$
为支持生成式建模,将 item 和 review 都映射到统一的 token 空间。设 $\mathbf{z}(i_t)$、$\mathbf{z}(r_t)$ 分别为 item $i_t$ 与 review $r_t$ 的 tokenized 表示,则序列改写为:
$$\widetilde{\mathcal{S}}_u^{\lt t}=\big[\mathbf{z}(i_1),\mathbf{z}(r_1),\mathbf{z}(i_2),\mathbf{z}(r_2),\dots,\mathbf{z}(i_{t-1}),\mathbf{z}(r_{t-1})\big] \tag{4}$$
推荐目标变成自回归地生成 next item 的 tokenized 表示:
$$p_\theta\big(\mathbf{z}(i_t)\,\big|\,\widetilde{\mathcal{S}}_u^{\lt t}\big) \tag{5}$$
训练集为:
$$\mathcal{D}=\big\{\big(\widetilde{\mathcal{S}}_u^{\lt t},\mathbf{z}(i_t),\mathbf{z}(r_t)\big)\,\big|\,u\in\mathcal{U},\,2\le t\le T\big\} \tag{6}$$
其中 $\mathbf{z}(r_t)$ 是用户对应 review 的 tokenized 表示,将在 task alignment 阶段作为 negative 信号使用。
方法详解¶
RAGR 总体框架¶
RAGR 包含三个阶段:(A) Tokenizer Training,(B) Review-Augmented User Sequence Modeling,(C) Item-Centric Task Generation Alignment。整体如下图所示:
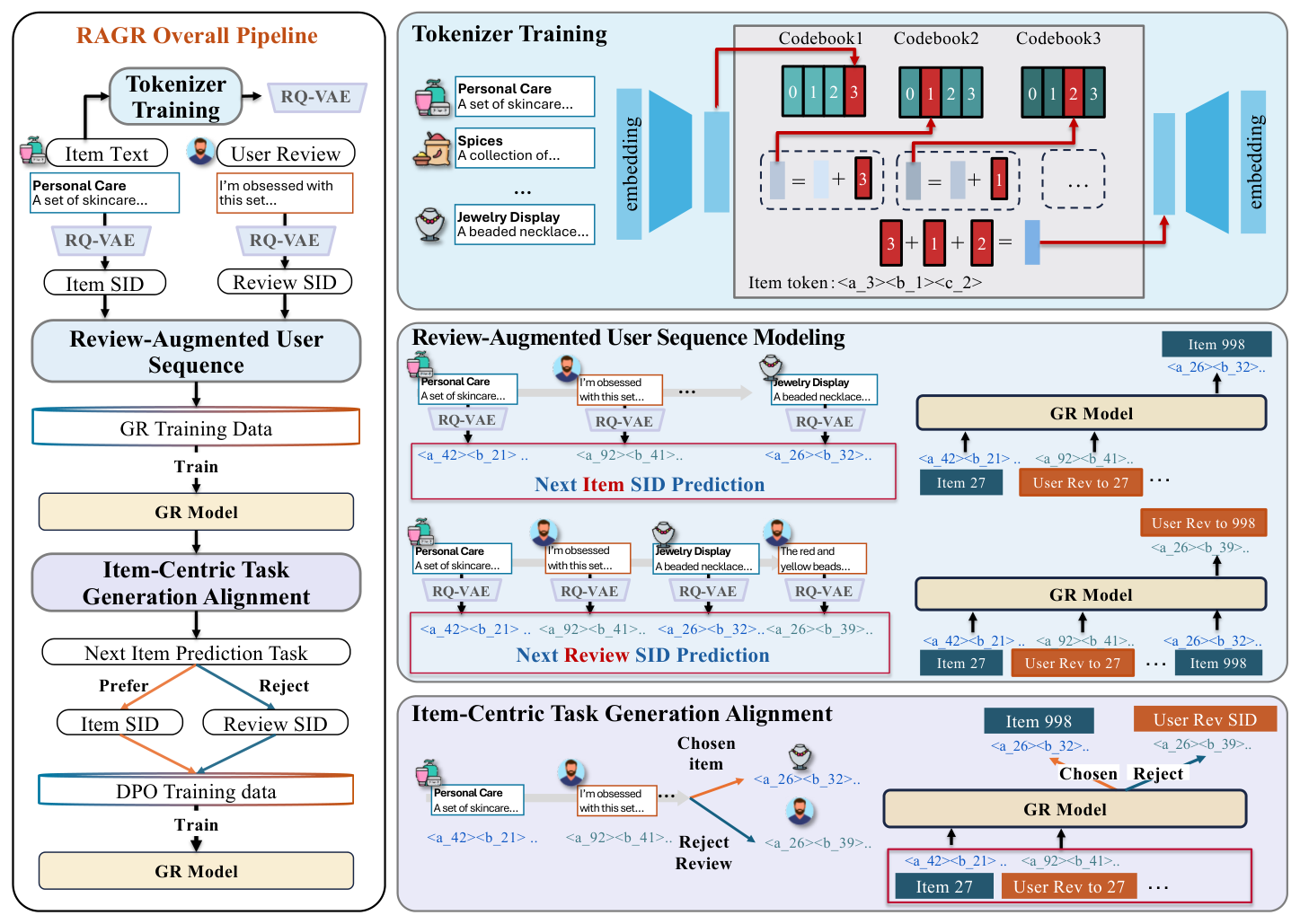
第一阶段:训练一个 RQ-VAE [11] 把 item 与 review 都映射到统一的 SID 空间。第二阶段:构建 review-augmented 用户序列,将 item 和 review 按时间交错,训练 GR 模型同时建模 next-item SID prediction 与 next-review SID prediction。第三阶段:使用 DPO [20] 把生成目标偏向于 item,使 review 仅作支持性证据存在。
A. Tokenizer Training¶
LLM 文本编码 → RQ-VAE 残差量化
为同时支持 item 与 review 的离散 token 化,第一阶段先用 LLM 文本编码器把 item 文本(标题、类别、描述)转成稠密 embedding:
$$\mathbf{e}_i=E(x_i) \tag{7}$$
其中 $E(\cdot)$ 是 LLM-based text encoder,$\mathbf{e}_i\in\mathbb{R}^d$ 是 item $i$ 的语义 embedding。相比 raw item ID,这种 text-informed 表征蕴含语义信息,是 tokenizer 学习的基础。
然后在 item embedding 上训练一个 residual quantization VAE(RQ-VAE)来把连续语义空间离散化为 code index 序列。具体地,encoder 把 $\mathbf{e}_i$ 映射为潜变量:
$$\mathbf{h}_i=g_\text{enc}(\mathbf{e}_i) \tag{8}$$
随后在 $M$ 个 codebook $\{\mathcal{C}^{(1)},\dots,\mathcal{C}^{(M)}\}$ 上做粗到精的残差量化。在第 $m$ 层,残差表示被量化到对应 codebook 中的最近 codeword:
$$q_i^{(m)}=\arg\min_k\big\Vert\mathbf{r}_i^{(m-1)}-\mathbf{c}_k^{(m)}\big\Vert_2^2 \tag{9}$$
其中 $\mathbf{c}_k^{(m)}\in\mathcal{C}^{(m)}$ 是第 $m$ 个 codebook 中第 $k$ 个 codeword,$\mathbf{r}_i^{(m-1)}$ 是第 $m$ 层之前的残差。残差按下式更新:
$$\mathbf{r}_i^{(m)}=\mathbf{r}_i^{(m-1)}-\mathbf{c}_{q_i^{(m)}}^{(m)} \tag{10}$$
初始残差为 $\mathbf{r}_i^{(0)}=\mathbf{h}_i$。经过 $M$ 层量化后,item 的潜变量近似为各层选中 codeword 之和:
$$\hat{\mathbf{h}}_i=\sum_{m=1}^{M}\mathbf{c}_{q_i^{(m)}}^{(m)} \tag{11}$$
由此每个 item $i$ 被表示为一个多级离散语义 ID:
$$\mathbf{z}(i)=\big[q_i^{(1)},q_i^{(2)},\dots,q_i^{(M)}\big] \tag{12}$$
直观上:靠前的 codebook 捕获粗粒度语义,靠后的 codebook 逐步刻画细粒度细节。RQ-VAE 的训练损失包含重构、codebook、commitment 三项:
$$\begin{aligned} \mathcal{L}_\text{tok}=&\underbrace{\big\Vert\mathbf{h}_i-\hat{\mathbf{h}}_i\big\Vert_2^2}_{\mathcal{L}_\text{rec}}\\ &+\sum_{m=1}^{M}\underbrace{\big\Vert\text{sg}\big[\mathbf{r}_i^{(m-1)}\big]-\mathbf{c}_{q_i^{(m)}}^{(m)}\big\Vert_2^2}_{\mathcal{L}_\text{code}}\\ &+\beta\sum_{m=1}^{M}\underbrace{\big\Vert\mathbf{r}_i^{(m-1)}-\text{sg}\big[\mathbf{c}_{q_i^{(m)}}^{(m)}\big]\big\Vert_2^2}_{\mathcal{L}_\text{commit}} \end{aligned} \tag{13}$$
其中 $\text{sg}[\cdot]$ 是 stop-gradient 算子,$\beta$ 是 commitment 系数。
关键设计选择 1:tokenizer 在什么文本上训练?
这是论文的一个核心实验问题(RQ3)。三个候选策略:
- Item Text-Only:仅用 item 文本 embedding 训练 RQ-VAE。
- Review Text-Only:仅用 review 文本 embedding 训练。
- Item and Review Text:把两类文本合并训练。
直觉上,混合训练能让 SID 空间同时刻画 item 与 review。但实验(见 RQ3 部分)表明 item-only 训练是最优的——把 review 直接混入 tokenizer 会扭曲 item 的 SID 分布。最终系统选择 Item Text-Only 作为默认。
B. Review-Augmented User Sequence Modeling¶
核心思想:item SID 与 review SID 按时间交错
第二阶段处理 item-only 序列只记录"用户选了什么"而忽略"为什么这样选"的局限。RAGR 把传统的 item 轨迹替换为 item-review 交错的序列(公式 (4)),使每个历史交互同时由 item SID 与对应 review SID 表示。这样 GR 模型在做下一个 item 生成时,可以同时基于行为结果与语义反馈进行建模。
统一文本生成任务:两种 seq2seq 实例
基于交错序列,RAGR 把 next-item 与 next-review 都视为同一个统一的文本生成任务,序列化为两种训练样本:
- Next-item SID prediction:input 是直到第 $t-1$ 步的 item-review 历史 $\widetilde{\mathcal{S}}_u^{\lt t}$,target 是下一个 item 的 SID 序列 $\mathbf{z}(i_t)$。
- Next-review SID prediction:input 在前者基础上附加目标 item $\mathbf{z}(i_t)$,target 是对应 review 的 SID 序列 $\mathbf{z}(r_t)$。
两类样本不被视为独立的优化目标,而是同一种"对 review-augmented 用户行为做文本序列生成"任务的两种实例。
形式化地,令 $(\mathbf{x},\mathbf{y})$ 为从 review-augmented 序列构造的训练样本,GR 模型用统一的自回归生成目标优化:
$$\mathcal{L}_\text{seq}=-\sum_{(\mathbf{x},\mathbf{y})\in\mathcal{D}_\text{seq}}\log p_\theta(\mathbf{y}\mid\mathbf{x}) \tag{14}$$
(论文中编号为 (15);为内部保持公式编号递增,这里使用 (14)。原文章节 III-C 见 公式 (15)。)
其中 $\mathcal{D}_\text{seq}$ 是所有 next-item 与 next-review 训练实例的集合。
两个收益
这种统一序列建模带来两点收益:
- 更精细的生成序列:把 item 交互与 review 反馈交错,使模型在 item 转移之外建模了用户的语义反馈轨迹。
- 共享生成空间内的语义依赖:模型能学习 item SID 与对应 review SID 在共享生成空间内的依赖关系,为后续 item-centric task alignment 打基础。
C. Item-Centric Task Generation Alignment¶
问题:混合序列引入预测目标的歧义
review-augmented 序列建模虽然丰富了用户表示,但也带来一个新风险:在预测位置上,item SID 与 review SID 都是该上下文下的"可信"延续。如果不加约束,模型可能把生成能力分配给 review,而不是 next-item recommendation,从而模糊任务边界。
第三阶段引入 item-centric task alignment 来显式地把 GR 模型的生成偏好对准 item,而不是 review。
DPO 偏好对(preference pair)的构造
设 $\mathbf{x}_t$ 是从目标交互前的历史序列构造的 review-augmented 上下文:
$$\mathbf{x}_t=\big[\mathbf{z}(i_1),\mathbf{z}(r_1),\dots,\mathbf{z}(i_{t-1}),\mathbf{z}(r_{t-1})\big] \tag{15}$$
对每个时间步 $t$ 的目标交互,构造偏好三元组:
$$(\mathbf{x}_t,\mathbf{y}_t^+,\mathbf{y}_t^-) \tag{16}$$
其中:
$$\mathbf{y}_t^+=\mathbf{z}(i_t),\quad \mathbf{y}_t^-=\mathbf{z}(r_t) \tag{17}$$
$\mathbf{y}_t^+$(preferred)是应当被推荐的下一个 target item,$\mathbf{y}_t^-$(rejected)是 review feedback,应作为推荐信号但不应替代推荐目标本身。基于这些对,DPO 训练集为:
$$\mathcal{D}_\text{dpo}=\big\{(\mathbf{x}_t,\mathbf{y}_t^+,\mathbf{y}_t^-)\,\big|\,u\in\mathcal{U},\,2\le t\le T\big\} \tag{18}$$
DPO 损失
设 $\pi_\theta$ 是当前 GR 模型,$\pi_\text{ref}$ 是 reference 模型(即第二阶段训练完的模型)。为可读性,先定义相对偏好分数:
$$\Delta_\theta(\mathbf{x},\mathbf{y}^+,\mathbf{y}^-)=\log\frac{\pi_\theta(\mathbf{y}^+\mid\mathbf{x})}{\pi_\text{ref}(\mathbf{y}^+\mid\mathbf{x})}-\log\frac{\pi_\theta(\mathbf{y}^-\mid\mathbf{x})}{\pi_\text{ref}(\mathbf{y}^-\mid\mathbf{x})} \tag{19}$$
对每个偏好三元组 $(\mathbf{x},\mathbf{y}^+,\mathbf{y}^-)\in\mathcal{D}_\text{dpo}$,DPO 损失写为:
$$\ell_\text{DPO}(\mathbf{x},\mathbf{y}^+,\mathbf{y}^-)=-\log\sigma\big(\beta\,\Delta_\theta(\mathbf{x},\mathbf{y}^+,\mathbf{y}^-)\big) \tag{20}$$
整体目标:
$$\mathcal{L}_\text{DPO}=\mathbb{E}_{(\mathbf{x},\mathbf{y}^+,\mathbf{y}^-)\sim\mathcal{D}_\text{dpo}}\big[\ell_\text{DPO}(\mathbf{x},\mathbf{y}^+,\mathbf{y}^-)\big] \tag{21}$$
其中 $\sigma(\cdot)$ 是 sigmoid,$\beta$ 是温度系数,控制偏好优化的尖锐度。
直观解读
该目标显式鼓励模型给 target item SID 赋予比 review SID 更高的条件似然。等价地,review 反馈没有从生成序列中被剔除,而是作为支持性上下文证据保留;同时模型被约束保留 item-centric 推荐目标。第三阶段与第二阶段互补:后者用语义反馈丰富了用户序列,前者确保这种反馈是推荐的"证据"而非"竞争的生成目标"。
实验设置¶
数据集¶
实验使用三个 Amazon Review benchmark:Beauty、Toys and Outdoors、Toys and Games(论文中 Sport 实际指 Amazon-Sports,下同)。每个数据集均包含 user-item 交互记录和 user-written reviews。遵循 SR 常规做法,过滤交互数少于 5 的 user 与 item,按时间排序后采用 leave-one-out 评估(最后一次交互测试、倒数第二次验证、其余训练)。每次历史交互对应的 review 文本被保留,从而能整合到 review-augmented 序列中。统计如下表所示:
| Dataset | #Users | #Items | #Inter. | #RAGR Train | #Val. | #Test |
|---|---|---|---|---|---|---|
| Beauty | 22,363 | 12,101 | 198,502 | 285,189 | 22,363 | 22,363 |
| Toys | 19,412 | 11,924 | 167,597 | 238,134 | 19,412 | 19,412 |
| Sport | 35,598 | 18,357 | 296,337 | 414,684 | 35,598 | 35,598 |
注意 #RAGR Train 显著大于 #Inter.:每个交互被实例化为两种训练样本(next-item SID 与 next-review SID),所以训练样本数约为交互数的 1.4~1.5×。
Baselines¶
两组对比方法:
顺序推荐 baselines:
- GRU4Rec [22]:经典 RNN-based SR,用 GRU 建模交互序列。
- BERT4Rec [10]:双向 Transformer 扩展,学习双向上下文表征。
- SASRec [4]:self-attention sequential recommender,捕捉长短期序列依赖。
- S³-Rec [23]:通过 self-supervised 预训练(item attribute、co-occurrence、sequence context)增强 SR。
生成式推荐 baselines:
- TIGER [11]:多级 SID 表示 item,把推荐重构为 SID 序列自回归生成。
- LETTER [13]:改进 SID 学习以提升 item 语义可表征性。
RAGR 被实例化在 TIGER 与 LETTER 两个生成式 backbone 上,得到 TIGER+RAGR 与 LETTER+RAGR。
Evaluation Metrics¶
采用 top-$K$ 排序指标 HIT@K 与 NDCG@K,$K\in\{5,10,20\}$。
Implementation Details¶
- Tokenizer 阶段:text encoder 用 sentence-T5(Hugging Face
sentence-transformers/sentence-t5-base)。RQ-VAE 为 6 层 encoder/decoder MLP,hidden dim $[2048,1024,512,256,128,64]$,4 个 residual codebook、每个 256 codeword、codeword dim 32。k-means 初始化 100 iter,cluster 数 10。优化器 AdamW(lr $10^{-3}$、batch size 2048、weight decay $10^{-4}$),最多训练 2000 epoch,监控 collision rate。 - Review-augmented user sequence modeling:序列最大长度 20,超过的从左截断。GR backbone 用 T5 [24]。AdamW,lr $10^{-3}$、per-device batch 256、gradient accumulation step 2、weight decay 0.01,warmup ratio 0.01 的余弦学习率,训练 200 epoch。
- Item-centric task alignment:用第二阶段的 GR 模型同时作为初始 policy 与冻结的 reference model 做 DPO。$\beta\in\{0.5,0.7\}$(在 RQ5 中分析),lr $10^{-6}$、per-device batch 256,AdamW。
- 硬件:Ubuntu + 8× NVIDIA RTX PRO 6000 GPU(96 GB)。主性能实验报告 3 次不同随机种子(42、43、44)的平均值。
主要实验结果¶
RQ1: 整体性能比较¶
下表是三个数据集上的全面对比。$\text{Imp.}$ 列是 RAGR 相对其 backbone 的相对提升,星号 $^*$ 表示 $p\lt 0.05$ 显著(双侧 t-test)。
| Dataset | Metric | GRU4Rec | BERT4Rec | SASRec | S³-Rec | TIGER | TIGER+RAGR | Imp. | LETTER | LETTER+RAGR | Imp. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Beauty | HIT@5 | 0.0174 | 0.0202 | 0.0377 | 0.0361 | 0.0386 | 0.0435* | 13% | 0.0371 | 0.0446* | 20% |
| NDCG@5 | 0.0108 | 0.0111 | 0.0220 | 0.0228 | 0.0254 | 0.0292* | 15% | 0.0253 | 0.0294* | 16% | |
| HIT@10 | 0.0323 | 0.0311 | 0.0605 | 0.0598 | 0.0607 | 0.0649* | 7% | 0.0582 | 0.0677* | 16% | |
| NDCG@10 | 0.0156 | 0.0155 | 0.0303 | 0.0305 | 0.0325 | 0.0361* | 11% | 0.0321 | 0.0370* | 15% | |
| HIT@20 | 0.0513 | 0.0518 | 0.0933 | 0.0940 | 0.0866 | 0.0944* | 9% | 0.0885 | 0.1019* | 15% | |
| NDCG@20 | 0.0204 | 0.0207 | 0.0385 | 0.0391 | 0.0391 | 0.0435* | 11% | 0.0397 | 0.0455* | 15% | |
| Toys | HIT@5 | 0.0147 | 0.0140 | 0.0369 | 0.0376 | 0.0331 | 0.0410* | 24% | 0.0321 | 0.0386* | 20% |
| NDCG@5 | 0.0095 | 0.0082 | 0.0217 | 0.0238 | 0.0206 | 0.0259* | 26% | 0.0210 | 0.0243* | 16% | |
| HIT@10 | 0.0257 | 0.0177 | 0.0591 | 0.0604 | 0.0526 | 0.0630* | 20% | 0.0512 | 0.0604* | 18% | |
| NDCG@10 | 0.0130 | 0.0090 | 0.0289 | 0.0311 | 0.0269 | 0.0329* | 22% | 0.0272 | 0.0312* | 15% | |
| HIT@20 | 0.0420 | 0.0333 | 0.0860 | 0.0910 | 0.0781 | 0.0934* | 20% | 0.0770 | 0.0902* | 17% | |
| NDCG@20 | 0.0172 | 0.0104 | 0.0356 | 0.0388 | 0.0333 | 0.0406* | 22% | 0.0337 | 0.0387* | 15% | |
| Sport | HIT@5 | 0.0152 | 0.0114 | 0.0212 | 0.0204 | 0.0231 | 0.0267* | 16% | 0.0240 | 0.0264* | 10% |
| NDCG@5 | 0.0102 | 0.0085 | 0.0138 | 0.0136 | 0.0148 | 0.0176* | 19% | 0.0156 | 0.0172* | 10% | |
| HIT@10 | 0.0231 | 0.0224 | 0.0311 | 0.0306 | 0.0385 | 0.0415* | 8% | 0.0403 | 0.0433* | 7% | |
| NDCG@10 | 0.0127 | 0.0091 | 0.0177 | 0.0169 | 0.0197 | 0.0224* | 14% | 0.0209 | 0.0227* | 9% | |
| HIT@20 | 0.0359 | 0.0300 | 0.0506 | 0.0483 | 0.0564 | 0.0619* | 10% | 0.0612 | 0.0661* | 8% | |
| NDCG@20 | 0.0159 | 0.0080 | 0.0220 | 0.0213 | 0.0242 | 0.0274* | 13% | 0.0262 | 0.0284* | 9% |
三点观察:
- RAGR 在两个 GR backbone(TIGER 与 LETTER)、三个数据集、所有指标上一致地提升性能。在 Beauty 上 TIGER+RAGR 提升 7%–15%,LETTER+RAGR 提升 15%–20%。在 Toys 上提升最大(达 24%/26%),多数指标 ≥20%。Sport 上提升较小(7%–19%),仍稳定显著。
- review 增强不仅提升强 GR baseline,也使 GR 显著超越传统 SR。TIGER+RAGR 与 LETTER+RAGR 在所有三个数据集上以明显幅度超越 GRU4Rec、BERT4Rec、SASRec、S³-Rec,表明 review 反馈带来的语义证据补足了 item-only 交互建模的不足。
- review-augmented 序列建模在文本反馈承载更强偏好信号的场景中尤为有效。Toys 上 RAGR 的提升一致大于 Beauty 和 Sport,且 HIT 与 NDCG 同步提升,说明 RAGR 不只是召回更好,排序质量也提升。
RQ2: 消融实验¶
为验证 review augmentation 与 task alignment 的各自贡献,作者在 TIGER 与 LETTER 上设计了一个渐进式 ablation:
- +Input:仅把 review SID 增加到 input 序列中,target 仍然只是 next-item,不改变训练目标。
- +Task:在 +Input 基础上进一步把 next-review SID prediction 加入文本生成目标,与 next-item SID prediction 联合训练。
- +RAGR:在 +Task 基础上加入 item-centric DPO 对齐。
完整 ablation 表如下:
| Method | H@5 | N@5 | H@10 | N@10 | H@20 | N@20 |
|---|---|---|---|---|---|---|
| Beauty | ||||||
| TIGER | 0.0386 | 0.0254 | 0.0607 | 0.0325 | 0.0866 | 0.0391 |
| +Input | 0.0260 | 0.0164 | 0.0417 | 0.0215 | 0.0619 | 0.0287 |
| +Task | 0.0427 | 0.0289 | 0.0649 | 0.0361 | 0.0938 | 0.0434 |
| +RAGR | 0.0435 | 0.0292 | 0.0649 | 0.0361 | 0.0944 | 0.0435 |
| LETTER | 0.0371 | 0.0253 | 0.0582 | 0.0321 | 0.0885 | 0.0397 |
| +Input | 0.0311 | 0.0205 | 0.0511 | 0.0269 | 0.0778 | 0.0351 |
| +Task | 0.0421 | 0.0280 | 0.0634 | 0.0353 | 0.0971 | 0.0431 |
| +RAGR | 0.0446 | 0.0294 | 0.0677 | 0.0370 | 0.1019 | 0.0455 |
| Toys | ||||||
| TIGER | 0.0331 | 0.0206 | 0.0526 | 0.0269 | 0.0781 | 0.0333 |
| +Input | 0.0273 | 0.0174 | 0.0424 | 0.0223 | 0.0676 | 0.0287 |
| +Task | 0.0405 | 0.0258 | 0.0624 | 0.0327 | 0.0930 | 0.0402 |
| +RAGR | 0.0410 | 0.0259 | 0.0630 | 0.0329 | 0.0934 | 0.0406 |
| LETTER | 0.0321 | 0.0210 | 0.0512 | 0.0272 | 0.0770 | 0.0337 |
| +Input | 0.0273 | 0.0174 | 0.0424 | 0.0223 | 0.0676 | 0.0287 |
| +Task | 0.0382 | 0.0240 | 0.0600 | 0.0310 | 0.0901 | 0.0386 |
| +RAGR | 0.0386 | 0.0243 | 0.0604 | 0.0312 | 0.0902 | 0.0387 |
| Sport | ||||||
| TIGER | 0.0231 | 0.0148 | 0.0385 | 0.0197 | 0.0564 | 0.0242 |
| +Input | 0.0190 | 0.0120 | 0.0317 | 0.0161 | 0.0482 | 0.0202 |
| +Task | 0.0266 | 0.0170 | 0.0413 | 0.0223 | 0.0606 | 0.0271 |
| +RAGR | 0.0267 | 0.0176 | 0.0415 | 0.0224 | 0.0619 | 0.0274 |
| LETTER | 0.0240 | 0.0156 | 0.0403 | 0.0209 | 0.0612 | 0.0262 |
| +Input | 0.0194 | 0.0124 | 0.0310 | 0.0164 | 0.0484 | 0.0208 |
| +Task | 0.0263 | 0.0172 | 0.0430 | 0.0223 | 0.0658 | 0.0284 |
| +RAGR | 0.0264 | 0.0172 | 0.0433 | 0.0227 | 0.0661 | 0.0284 |
三个关键结论:
-
仅扩 input 反而显著降性能。+Input 在两个 backbone × 三个数据集上一致地比 vanilla TIGER/LETTER 差。例如 Beauty 上 TIGER 从 0.0386 跌到 0.0260(HIT@5),LETTER 从 0.0371 跌到 0.0311。这说明 review SID 如果只塞进 input 而不引入对应的预测目标,反而会作为噪声扰乱原本 item-only 训练目标下的表征学习。这是一个反直觉但重要的负例:单纯加 side information 并不"免费"。
-
+Task 显著提升。当训练目标扩展为同时建模 next-item SID 与 next-review SID 后,性能比原 backbone 与 +Input 都明显提升。例如 Toys 上 TIGER+Task 达到 0.0405/0.0258(HIT@5/NDCG@5),远超 TIGER 与 +Input。这说明 review SID 只有在被显式纳入序列生成任务时才有益。
-
+RAGR 进一步提升、且总体最优。在大多数设置下,DPO-based item-centric alignment 在 +Task 之上还有提升。Beauty 上 TIGER+RAGR 在 HIT@5 从 0.0427 升到 0.0435、HIT@20 从 0.0938 升到 0.0944;LETTER+RAGR 在 HIT@5 从 0.0421 升到 0.0446、HIT@20 从 0.0971 升到 0.1019。Sport 上提升较小但稳定。这验证了 DPO 对齐保留了 next-item 的任务边界——当 review prediction 加入后,alignment 防止 review 信号"喧宾夺主"成为竞争目标。
SID 分布对比:为什么 +Task 和 +RAGR 有效?
为进一步理解 review augmentation 为何能提升推荐性能,作者对比了 item 与 review 在不同 SID 位置上的频率分布:
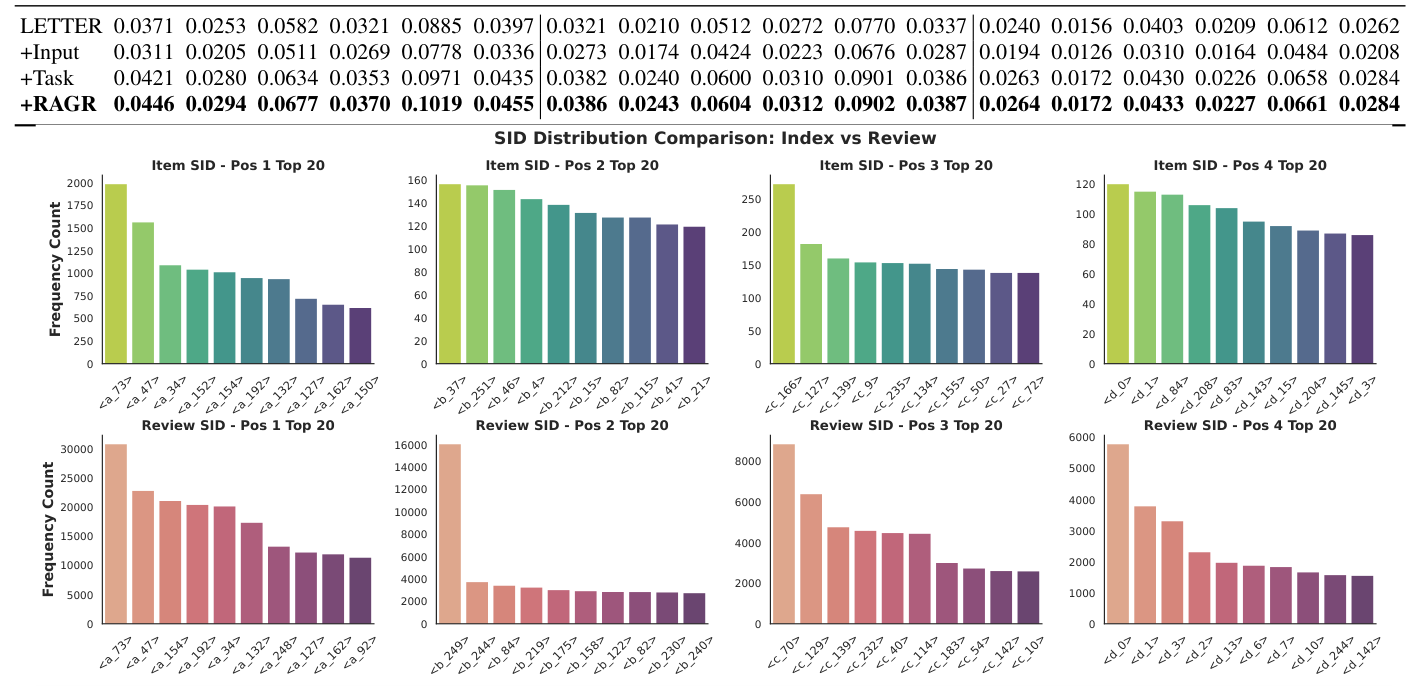
观察结果:引入 review 反馈后,SID 分布在不同 token 位置上变得更加多样。item-only 序列下 SID 分布过度集中在少数 item-side SID 上,supervision 信号集中在小子集,造成训练利用率不足。review-augmented 序列激活了 SID 空间中更宽的 token 集合,使更多 SID 接收到有效的训练信号,统一 SID 空间的利用率提高,token 表征更具区分度。
RQ3: Tokenizer 训练策略¶
为回答 tokenizer 训练策略哪种最优,作者比较 Item Text-Only、Review Text-Only、Item and Review Text 三种 RQ-VAE 训练数据来源。
效率与碰撞率对比:
| Tokenizer | Training Time | Beauty Col. | Toys Col. | Sport Col. |
|---|---|---|---|---|
| Item Text-Only | 2s/epoch | 0.0009 | 0.0011 | 0.0025 |
| Review Text-Only | 29s/epoch | 0.0009 | 0.0012 | 0.0024 |
| Item and Review Text | 33s/epoch | 0.0008 | 0.0044 | 0.0005 |
下游性能对比(HIT 与 NDCG@5/10/20 各数据集 × 各 backbone):
三个观察:
- Item Text-Only 一致最优:在 TIGER 与 TIGER+RAGR 两种 backbone、Beauty/Toys/Sport 三个数据集上,Item Text-Only 训练的 tokenizer 在多数 HIT 与 NDCG 指标上给出最高分。
- Review Text-Only 最差:尽管 review 文本携带丰富的偏好信号,但仅用它训练 tokenizer 会偏离 item 的分布,降低 item SID 质量,从而损害下游推荐。Item and Review Text 通常优于 Review Text-Only,但仍稳定不如 Item Text-Only。
- Item Text-Only 同时也是效率最高的策略:每 epoch 仅 2s,相比 Review Text-Only(29s)与 Item and Review Text(33s)有约 15× 的训练时间优势。collision rate 在三种策略下差异不一致,所以 collision rate 并不能完美预测下游性能。
结论:review 反馈应作用在序列建模阶段,而不是 tokenizer 阶段。
RQ4: SID 长度敏感性¶
SID 长度(codebook 数 $M$)控制语义空间的细粒度。token 数越少则空间越小、碰撞越多;token 数越多则区分度越高但自回归生成更难。作者在 $M\in\{3,4,5\}$ 范围内做敏感性分析:
碰撞率:
| SID Num | Beauty Col. | Toys Col. | Sport Col. |
|---|---|---|---|
| 3 | 0.0121 | 0.0017 | 0.0045 |
| 4 | 0.0009 | 0.0012 | 0.0026 |
| 5 | 0.0007 | 0.0003 | 0.0018 |
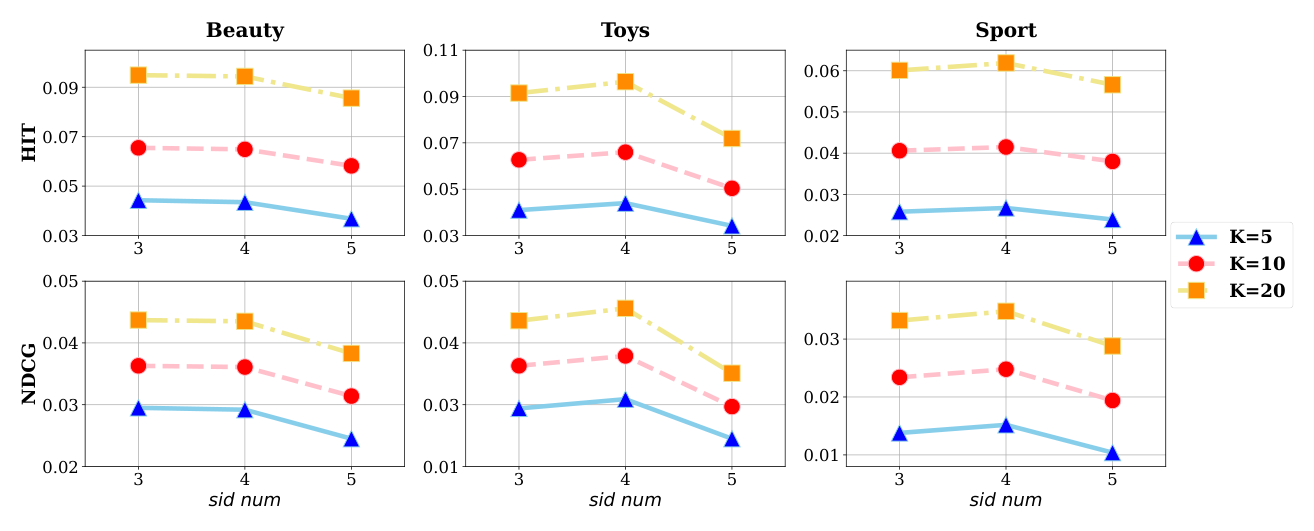
三个观察:
- SID=4 给出最佳总体性能:在三个数据集、两个指标家族上,4 个 token 一致地达到最强的 HIT/NDCG。
- SID 长度与性能呈非单调关系:SID=3 时 collision rate 显著高于 SID=4,但下游 HIT/NDCG 反而具有竞争力。一个可能的解释是高碰撞强制了语义相近或高频 item 合并到共享 SID,引入了一种"平滑"效应,部分缓解了数据稀疏,但代价是 item 区分度下降,性能仍不如 SID=4。
- SID 越长越差:SID=5 进一步降低 collision 但一致损害性能,说明:一旦 collision 被充分控制,再延长 SID 主要是放大生成空间和自回归解码难度,得不到表征质量的同等收益。
结论:SID 长度控制 unique 性与生成复杂度的权衡。适度的 SID 长度(在本配置下为 4)最为理想。
RQ5: DPO 超参数敏感性¶
作者分析 DPO 对齐对 $\beta$(preference 系数)与 training epoch 的敏感性:
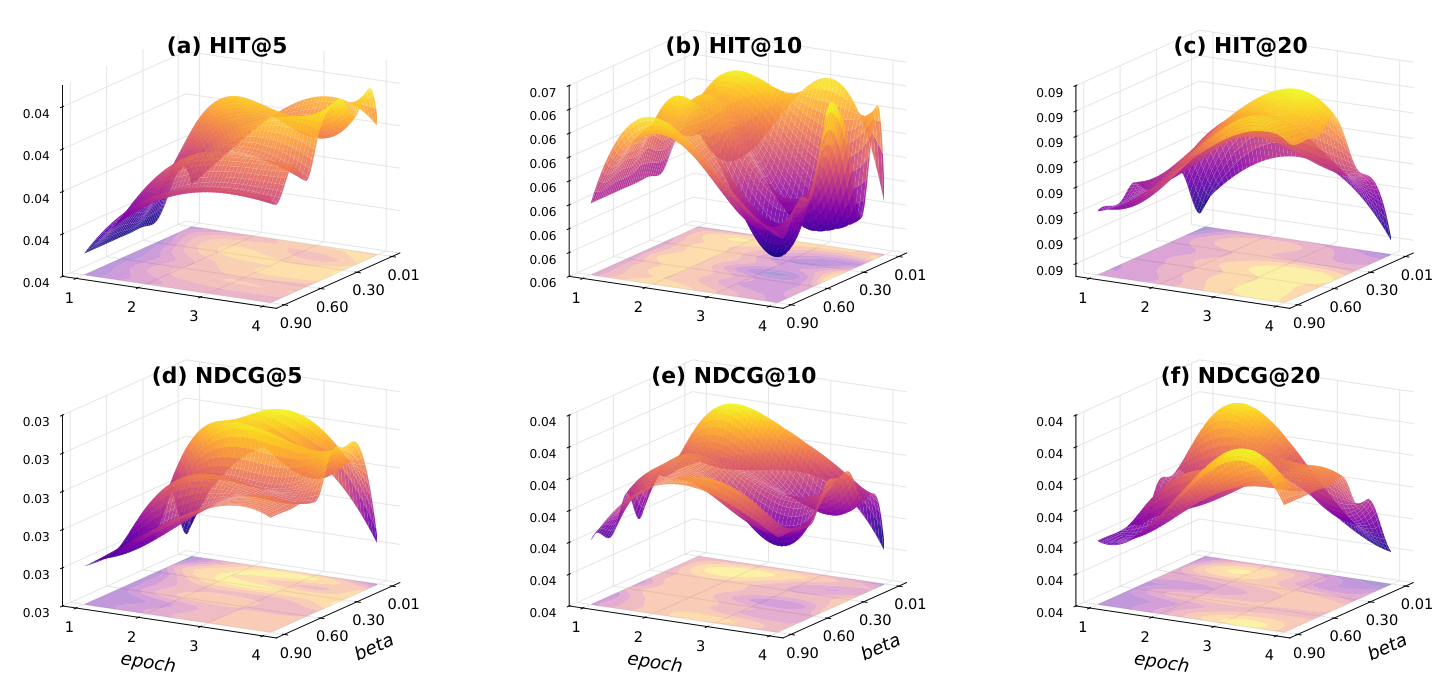
三个观察:
- 性能面整体平滑:不是 sharp local optima,说明 DPO 对齐在较宽的超参数范围内稳定。
- $\beta$ 中等最佳:过小则偏好信号太弱无法强制 item-centric alignment;过大则 chosen-rejected 对比过强,损害原 GR 生成能力。
- epoch 也是中等最佳:DPO 对齐需要足够强才能把模型偏移到 item 上,但又不能过强地拟合 preference pair。最佳通常在中间 epoch(不是最早或最晚)。
结论:RAGR 不依赖极窄的 DPO 超参数区间;适度调参可获最佳性能。
与已归档相关工作的关系(简述)¶
按照 Step 2.5 的"问题 + 解法双同构"标准,文档库内没有严格意义上的孪生论文,故不展开单独的对比章节。需要简要提及的是:AttnMVP(2603.10369, LinkedIn 2026-03-11)也直接讨论了"GR 用户序列中异质 token 是否应该交错"这一问题,但走向相反结论——它批判 HSTU 风格的 item+action token 交错带来注意力噪声,并以非交错的因果 pooling 替代;而 RAGR 倡导一种新的交错(item+review)+DPO 对齐。两者从不同角度切入同一个底层架构问题,可作为有意思的反向对照,但其问题陈述("action token 的因果稀释"vs"item-only 序列缺失偏好理由")的 root cause 并不同构。HSTU(2402.17152)作为 item+engagement 交错的奠基性 GR 工作,RAGR 没有引用也未做基线对比,是一个较明显的 missed comparison(同样的"交错异质 token"思想在 RAGR 中变换为 item+review)。OneRec-Think / SAPO / LASAR 等论文同样在 SID 序列中注入额外 token,但是模型自生成的 reasoning token 而非用户观测到的 review token,技术骨架与监督源都不同。
讨论与局限性¶
核心贡献¶
- 诊断:RAGR 第一个系统地指出生成式推荐沿用了"user sequence = item-only trajectory"的传统假设,并把这一点视为结构性瓶颈而非"被忽视的机会"——已有研究极大扩展了 item representation 的表达力,却几乎没碰 user sequence 的表达力,这种不对称留下了显著的改进空间。
- 机制:把 GR 的 unified tokenizer 重新利用来 tokenize user-side textual feedback(reviews),从而让 GR 范式自带的机器同时服务于 item 与 user-side 信号。这是一个低额外架构成本的方案:不增加新模块,只把现有 tokenizer 多用了一遍。
- 对齐:通过 DPO 把 next-item 设为 preferred、next-review 设为 rejected,从而维持 item-centric 推荐目标边界。这是论文最微妙也是最值得借鉴的一点——它解决了"丰富 input 与保持 task focus"这一对潜在矛盾。
- 实证:在两个强 GR backbone(TIGER、LETTER)× 三个 Amazon 数据集 × 所有指标上的一致且统计显著提升,证明框架不绑定特定 GR 架构。
- 细节:tokenizer 实验给出反直觉发现(item-only 训练优于混合训练),SID-number 实验给出 collision rate 与下游性能的非单调关系,DPO 敏感性显示对超参数稳健,三者共同提高了方法的实用性与可复现性。
值得借鉴的设计¶
- "扩展 input 必须配合扩展 task":+Input 单独使用反而降性能,+Task 才能解锁收益。这条经验对任何想往 GR 中注入 side information 的工作都是警示——单纯把更多 token 塞进输入而不改 objective 是负 ROI 的。
- "用 DPO 维持任务边界" 而不是用 hard masking 或 weighting:当 input 含多种 token 类型且每种都是"看上去合理"的生成延续时,DPO 是一种自然的偏好对齐工具。chosen/rejected 的构造方式(同一上下文下的 next-item vs next-review)也非常优雅——无需额外标注。
- "tokenizer 阶段不要混 user-side 信号":把 user-side 信号留给序列建模阶段,而不是 tokenizer 训练阶段。这条建议对工业实践有直接意义——保持 tokenizer 简单且只受 item 文本驱动可能比"端到端融合"更稳健。
局限性¶
- 数据范围有限:三个数据集都是 Amazon Review(Beauty、Toys、Sport),都属于电商 + 较稠密 review 的场景。在用户极少留 review 的场景(短视频、社交、广告点击)下,review-augmented 序列会高度稀疏,方法是否仍然奏效未知。
- review 视为"客观信号":用 LLM encoder 对 review 文本做语义 embedding 再 RQ-VAE 量化,等于把 review 当作偏好的客观表达。review 的主观性、噪声、虚假 review、星级与文本不一致等问题未被讨论。
- 没有讨论冷启动:对于没有 review 历史的新用户、新 item,review-augmented 序列退化为 item-only,理论上应回退到 baseline。但论文没有给出 review 缺失下的性能分析。
- DPO 对齐还是 offline 形式:preferred 与 rejected 都来自训练集中观察到的 item 与 review,没有 online preference signal。如果未来用真实用户 implicit feedback 做 preference labeling,可能进一步对齐线上目标。
- 对比 baseline 较保守:只对比了 TIGER 与 LETTER,没有对比 HSTU(item+engagement 交错)、ActionPiece 等其他形式的 user-side token 工作;也没有对比 review-aware 判别式方法(如 NARRE)在公平条件下的表现。在 related work 中虽提及,但没纳入实验。
- alignment 阶段额外 token 成本:序列长度被 review SID 翻倍后,自回归生成的内存与计算成本显著增加(约 2× input 长度)。对长用户历史尤其需要注意,未来工作可以探索把 review SID 压缩为更短的 abstraction(如 1 个 token)。
未来方向¶
- 多模态 user-side 信号:把 review 之外的图像、评分、停留时长等 user-side 信号也通过同一 tokenizer 注入。
- online DPO:把线上点击/转化作为 preference signal,端到端对齐工业目标。
- 稀疏 review 下的回退策略:用 LLM 生成 pseudo-review 作为缺失反馈的代理,或学习 review-free 子模型作 mixture。
- 更长 SID 序列的高效生成:随着 user-side token 加入,序列长度增长,需要更高效的 decoder(如 parallel decoding [31]、speculative decoding 等)。
整体评价¶
RAGR 是一个理论清晰、实验扎实的工作:它精准地指出了 GR 范式遗留的一个不对称问题,给出了简洁的扩展(重用 tokenizer),并通过 DPO 这一关键设计避免了"扩展即损害"的坑。三个数据集上 ~10%–20% 的提升幅度对 GR 领域是显著的。最重要的是,它把 review-aware recommendation 与 generative recommendation 这两条平行研究线索打通——前者长期把 review 当作 side information 用于匹配或评分预测,后者一直在 item-only 序列上深耕。RAGR 让 review 第一次以一等公民进入 GR 的生成序列本身。这个范式转变本身就值得后续工作探索(多模态、跨语种 review、对话式 review 等方向都有空间)。