SAPO: Step-Aligned Policy Optimization for Reasoning-Based Generative Recommendation¶
作者:Zaiyi Zheng¹, Guanghui Min¹, Yaochen Zhu¹, Liang Wu², Liangjie Hong², Chen Chen¹, Jundong Li¹ 所属:¹University of Virginia · ²Nokia ArXiv:2605.17648 · 2026-05-17 · 代码:https://github.com/zhengzaiyi/SAPO
1. 研究动机与背景¶
生成式推荐(Generative Recommendation, GR)正在用「自回归生成 item 标识符」的范式取代传统打分式 + 排序的多阶段 cascading。为了避免给每个 item 单独分配一个 token(词表会爆炸),主流做法(TIGER、LCRec、LETTER 等)借鉴 RQ-VAE 思路把每个 item 编码成一个由 $K$ 个层次化 token 组成的 Semantic ID (SID) 元组 $\phi(v) = (s^{(1)}, s^{(2)}, \dots, s^{(K)})$:早期 token 表征粗粒度语义(如品类),后续 token 不断细化(品牌、型号)。模型只需在每个 codebook 上预测一个 token,再用 trie-based constrained decoding 把生成结果约束到合法 item 集合 $\Phi=\phi(\mathcal{C})$ 内。本文设 $K=3$,足以覆盖实验中的所有目录。
近期一条平行的研究路线(OneRec-Think、SIDReasoner、R²ec、ReaRec 等)为 GR 加入了 推理 trace:让模型在输出最终 SID 之前先生成一段 chain-of-thought,再把整个生成过程用 verifiable rewards (RLVR) 做后训练。典型 recipe 是「SFT 对齐 SID 词表 → SFT 激活推理 → GRPO-style outcome reward RL」,奖励信号就是「生成的 SID 元组是否与 ground-truth 完全相等」这个 exact-match 指示。
问题在于:outcome-reward GRPO 给整条 rollout 的所有 token(推理 token + 所有 $K$ 个 SID token)广播同一个标量优势,与 SID 解码的层次结构完全错位。考虑 $K=3$、ground-truth 为 $(s_\star^{(1)}, s_\star^{(2)}, s_\star^{(3)})$ 的情况:
- near miss $(s_\star^{(1)}, s_\star^{(2)}, \tilde{s}^{(3)})$(最后一位错);
- coarse error $(\tilde{s}^{(1)}, \tilde{s}^{(2)}, \tilde{s}^{(3)})$(全部错)。
两者拿到的 outcome reward 完全一样(都是 0),group-relative advantage 也一样,于是「near miss 的前两位预测对了」这一信息被完全抹掉、和「全错」的 rollout 一视同仁地受罚。作者把这条核心病灶命名为 action-granularity mismatch:rollout 太粗,单个 token 又太细,真正适配的 credit-assignment unit 是「一个 thinking block + 它配对的 SID token」这一对。
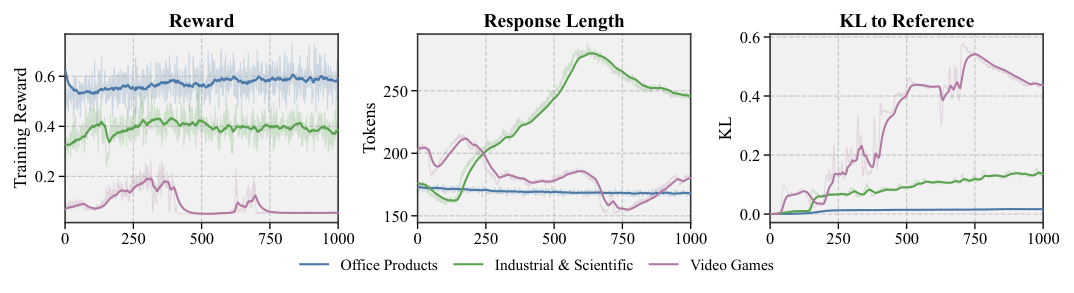
图 1 在三个 Amazon 类目上同时展示了 outcome-reward GRPO 的三条特征性曲线:训练 reward 早期上升后塌陷或抖荡、response length 持续漂移、KL 相对参考模型快速增长。reward shaping 不能根治这件事:即使把 outcome reward 换成 $r_{\text{shape}}=\sum_k \mathbb{1}[s_i^{(k)}=s_\star^{(k)}]$ 这种 codebook-level 累计匹配(公式 3),只要 advantage 仍按 rollout 归一化、广播到全部 token,就还是不知道哪个 SID 位置错了。SAPO 的核心论断是:reward 放置、advantage 归一化、token 聚合必须同时下沉到 reasoning-step 这一层。
主要贡献: 1. 把「outcome-reward RL 在 reasoning-based SID 解码下失效」诊断为 action-granularity mismatch——rollout 级 reward 不能定位是哪个 SID 位置出错,rollout 级 advantage 会把不相关的推理 token 和正确的 SID token 一并奖惩; 2. 提出 SAPO,把每个 reasoning step(一个 thinking block 配对一个 SID token)作为 RL 的 action unit,由此自然导出 per-step verifiable match reward、per-step group-relative advantage、step-normalized token 聚合三件套,全程不引入额外的 learned reward model; 3. 在三个真实推荐数据集上验证 SAPO 既能稳定 RL 训练动态,又能持续提升 Recall / NDCG,且 SID-token credit-assignment 越关键的设定下收益越大。
2. 预备知识与训练范式¶
2.1 Hierarchical Semantic ID 化的生成式推荐¶
设 $\mathcal{C}$ 为 item 目录,$K$ 个 codebook $\mathcal{V}^{(1)}, \dots, \mathcal{V}^{(K)}$。RQ-VAE 风格的量化器 $\phi: \mathcal{C}\to \mathcal{V}^{(1)}\times\dots\times \mathcal{V}^{(K)}$ 把每个 item $v$ 唯一映射成 $\phi(v)=(s^{(1)}, \dots, s^{(K)})$。$\Phi=\phi(\mathcal{C})$ 是合法 SID 元组集合。给定按时间排序的交互序列 $x=(v_1,\dots,v_{T_x})$,目标是预测下一个 item $v^\star=v_{T_x+1}$。在最简单的不带推理的设定下,策略 $\pi_\theta(y|x)$ 直接解码 $K$ 个 SID token,rollout $y$ 终止于一个合法的 SID 元组 $\phi(\hat v)\in \Phi$。
2.2 三阶段训练 setup¶
沿用 OneRec-Think、SIDReasoner 等已有工作的方案:
- Stage 1(SFT 词表对齐):让 LM 学会输出合法的 SID token 序列;
- Stage 2(推理激活):训练模型生成「$K$ 个 thinking block + $K$ 个 SID token」的结构化响应,每个 thinking block 对一个 SID 位置进行推理;
- Stage 3(强化学习):在 verifiable exact-match 反馈下做 RL;本文聚焦此阶段。
Stage 3 的标准做法是 outcome-reward GRPO:对 prompt $x\in \mathcal{D}_{\text{RL}}$ 采样 $G$ 条 rollout $\{y_i\}_{i=1}^G$,每条赋一个标量 reward $r(x, y_i)$(典型即 exact-match 指示),group-relative 归一化:
$$\hat{A}_i = \frac{r(x, y_i) - \mathrm{mean}_{j\in[G]} r(x, y_j)}{\mathrm{std}_{j\in[G]} r(x, y_j)} \tag{1}$$
token-level clipped surrogate(KL 与 Stage 2 reference 的对齐项在所有变体里共享,记号略去):
$$\mathcal{J}_{\text{GRPO}}(\theta) = \mathbb{E}_{x, \{y_i\}}\left[\frac{1}{\sum_{\ell=1}^{G} |y_\ell|}\sum_{i=1}^{G}\sum_{t\in y_i} \min\bigl(w_{i,t}(\theta)\hat A_i,\ \mathrm{clip}(w_{i,t}(\theta), 1-\epsilon, 1+\epsilon)\hat A_i\bigr)\right] \tag{2}$$
其中 $w_{i,t}(\theta) = \pi_\theta(y_{i,t}|x, y_{i,\lt t})/\pi_{\theta_{\text{old}}}(y_{i,t}|x, y_{i,\lt t})$ 是 per-token importance ratio,$\epsilon$ 是 clipping 半径。
3. 诊断:Outcome-Reward GRPO 的 Action-Granularity Mismatch¶
公式 (2) 把同一个标量 $\hat A_i$ 广播给整个 response 的每一个 token。但 large-catalog SID 解码下 exact-match 只能告诉你「最终元组对不对」,不能告诉你具体哪一位 SID 错了。
两个具体失败模式: 1. Matched SID-token credit is discarded:near-miss rollout 里前 $K-1$ 个 SID token 都预测对了,但只要最后一位错,整条 rollout 就拿 0 reward;正确的 SID-token 预测因此被当作完全失败处理,无法积累正向信号; 2. Reasoning-step advantage localization is lost:错的 SID-token 位置上的一处错误,被同样广播到所有 thinking block 和所有 SID-token 位置;在长推理响应下,这种弥散式的广播会一起强化或惩罚许多与错误无关的推理 token,导致 length 漂移、format 退化、group-relative contrast 微弱。
reward shaping 无法消除这件事:哪怕用 $r_{\text{shape}}=\sum_{k=1}^{K} \mathbb{1}[s_i^{(k)}=s_\star^{(k)}]$ 这种 codebook-level dense reward(公式 3)替代二值 exact-match,
$$r_{\text{shape}}(x, y_i) = \sum_{k=1}^{K} \mathbb{1}\bigl[s_i^{(k)} = s_\star^{(k)}\bigr] \tag{3}$$
公式 (2) 仍然会把这个分数挤成一个 rollout-level 标量再广播到所有 token——告诉你「partial 对了」但仍然定位不到 哪个 SID-token 预测正确或错误。rollout 太粗,token 太细,自然的 credit-assignment 单元是介于两者之间的 reasoning step——一个 thinking block 配对其 SID token。
4. SAPO 方法¶
4.1 总览与 reasoning step 拆分¶
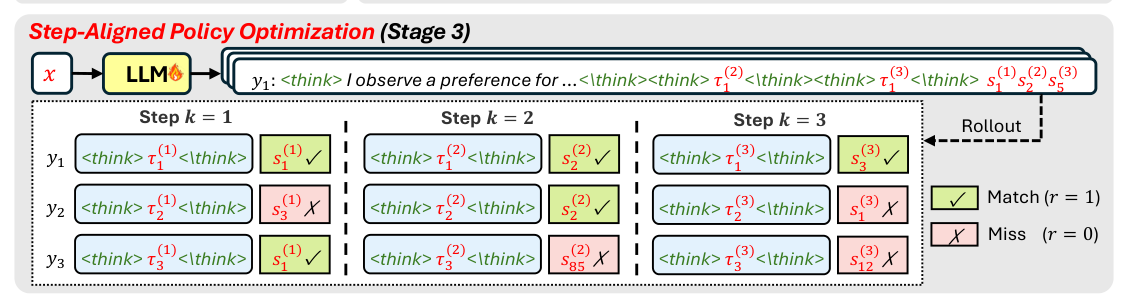
为了能跨 SID 位置复用 trie + KV cache,SAPO 沿用「先生成 $K$ 个 thinking block,再生成 $K$ 个 SID token 的连续块」这种 blocked decoding layout:
$$y = \underbrace{\bigl[\langle\text{think}\rangle\tau^{(1)}\langle/\text{think}\rangle \oplus \cdots \oplus \langle\text{think}\rangle\tau^{(K)}\langle/\text{think}\rangle\bigr]}_{\text{reasoning trace with } K \text{ thinking blocks}} \oplus \underbrace{s^{(1)} s^{(2)} \cdots s^{(K)}}_{\text{all } K \text{ SID tokens}} \tag{4}$$
对 credit assignment 而言,SAPO 把第 $k$ 个 thinking block $\tau^{(k)}$ 与第 $k$ 个 SID token $s^{(k)}$ 配对作为 reasoning step $k$,定义 $y_i^{(k)} = (\tau_i^{(k)}, s_i^{(k)})$,对应 token 数 $|y_i^{(k)}| = |\tau_i^{(k)}| + 1$。这只用于 credit assignment,不改变自回归分解:原模型在生成 $s^{(k)}$ 时仍然 condition on 全部 $K$ 个 thinking block 与已生成的 SID token,blocked layout 让 trie-based constrained decoding 与 beam search 在 KV-cache 复用下高效推进,同时允许后面的 thinking block 反向 refine 前面的——这是单方向因果但前向信息流可以「迂回回看」的优势。
4.2 Reasoning-step match reward¶
reward 必须放到 SID-token 位置(而不是 rollout 末端)才能给出 per-step 监督。对每条 rollout $y_i$,记生成的 SID 序列 $(s_i^{(1)}, \dots, s_i^{(K)})$ 与 ground-truth $(s_i^{\mathrm{gt},(1)}, \dots, s_i^{\mathrm{gt},(K)})$:
$$r_{i,k} = \alpha\cdot\mathbb{1}\bigl[s_i^{(k)}=s_i^{\mathrm{gt},(k)}\bigr] + \beta\cdot\mathbb{1}[k=K]\cdot b_i \tag{5}$$
其中 $\mathbb{1}[\cdot]$ 是指示函数,$b_i=1$ 当且仅当 $y_i$ 含恰好 $K$ 个抽取得到的 thinking block 且以一个合法 SID 元组结尾,否则 $b_i=0$。第一项是 per-step match reward:哪怕其它 SID 位置错了,对的 SID token 仍然能拿到 $\alpha$ 的奖励;第二项是 final-step format bonus:仅在最后一个 SID token 位置加一个小的 format bonus,激励结构上良构的 rollout。
objective consistency:定义 match 分量 $m_{i,k}:=\alpha\mathbb{1}[s_i^{(k)}=s_i^{\mathrm{gt},(k)}]$。原 outcome reward 对应概率 $\mathcal{J}_{\text{out}}(\pi)=\Pr[\phi(\hat v)=\phi(v^\star)]$(联合命中所有 SID 位置),SAPO 的 match 期望累积量 $\mathcal{J}_{\text{match}}(\pi)=\mathbb{E}[\sum_k m_k]$。论文 Proposition 1 证明:
$$\sum_{k=1}^{K} m_{i,k} = \alpha\cdot\bigl|\{k\in[K]: s_i^{(k)}=s_i^{\mathrm{gt},(k)}\}\bigr| \tag{6}$$
Optimum preservation:若策略类 $\Pi$ 中存在 exact-match 最优策略 $\pi^\star$(realizability),则
$$\arg\max_{\pi\in\Pi}\mathcal{J}_{\text{out}}(\pi) = \arg\max_{\pi\in\Pi}\mathcal{J}_{\text{match}}(\pi) \tag{7}$$
也就是 SAPO 没有改变 exact-match 最优解——证明思路:$\mathcal J_{\text{out}}$ 的上界为 1 且在 realizability 下可达,对应 $K\alpha$ 的 $\mathcal J_{\text{match}}$ 上界也仅在 $\phi(\hat v)=\phi(v^\star)$ 时取到。Aligned refinement:若不存在 exact-match 策略,$\mathcal J_{\text{match}}(\pi)=\alpha\sum_k R_k(\pi)$($R_k$ 是 level-$k$ marginal match 概率),是 outcome 联合命中概率 $\mathcal J_{\text{out}}(\pi)=\Pr[\bigwedge_k s^{(k)}=s_\star^{(k)}]$ 的「marginal 求和精化」。两个策略可能联合命中率相同,但各级 marginal 不同,cumulative match reward 能区分它们。
Informative rollout groups(论文中的 Remark):outcome-reward GRPO 的 group-relative contrast 非零仅当组内 rollout 的 exact-match 指示不同。SAPO 的 step-level contrast 在「组内某些 rollout 的第一位匹配而另一些不匹配」时就可以非零——即使所有 rollout 都没拿 exact match。也就是说,SAPO 的 advantage 在一个 strictly larger 的 rollout group 集合上有信息。
4.3 Reasoning-step advantage 与 SAPO surrogate¶
reward 既在 SID-token 位置发放,advantage 与 surrogate loss 就要同 granularity 定义。对位置 $k$ 的回报 $r_{i,k}$,独立地在该 step 内做 group-relative 归一化:
$$\hat A_{i,k} = \frac{r_{i,k} - \mathrm{mean}_{i'\in[G]}(r_{i',k})}{\mathrm{std}_{i'\in[G]}(r_{i',k})},\quad \tilde A_{i,k} = \frac{\hat A_{i,k}}{|y_i^{(k)}|} \tag{8}$$
「step-normalized」指除以配对单元长度 $|y_i^{(k)}|=|\tau_i^{(k)}|+1$,使更新幅度只取决于推理 step 本身的「质量」,不被 thinking block 的 token 数量主导。沿用 per-token importance ratio $w_{i,t}(\theta)$(与公式 2 同),SAPO 的 surrogate 是:
$$\mathcal{J}_{\text{SAPO}}(\theta) = \mathbb{E}_{x,\{y_i\}}\left[\frac{1}{\sum_{\ell=1}^{G}|y_\ell|}\sum_{i=1}^{G}\sum_{k=1}^{K}\sum_{t\in y_i^{(k)}} \min\bigl(w_{i,t}(\theta)\tilde A_{i,k},\ \mathrm{clip}(w_{i,t}(\theta), 1-\epsilon, 1+\epsilon)\tilde A_{i,k}\bigr)\right] \tag{9}$$
外层归一化 $1/\sum_\ell|y_\ell|$ 与 GRPO 保持一致,只是 token 处的标量从「rollout 标量优势 $\hat A_i$」换成了「step-级优势除以 step 长度 $\tilde A_{i,k}$」。
梯度视图(暂时忽略 clipping):
$$\nabla_\theta \mathcal{J}_{\text{SAPO}}(\theta) \propto \mathbb{E}\left[\frac{1}{\sum_\ell|y_\ell|}\sum_{i,k,t\in y_i^{(k)}} \underbrace{w_{i,t}(\theta)}_{\text{importance}}\cdot \underbrace{\hat A_{i,k}}_{\text{reasoning-step advantage}}\cdot \underbrace{\frac{1}{|y_i^{(k)}|}\nabla_\theta\log\pi_\theta(y_{i,t}|x, y_{i,\lt t})}_{\text{step-normalized token gradient}}\right] \tag{10}$$
两点与 rollout-level GRPO 不同:(a) rollout-wide 的标量优势被 step-level $\hat A_{i,k}$ 替换,因此组内只在 SID 位置 $k$ 上有差异的 rollout 才会在 step $k$ 上贡献对比更新,不影响无关 SID 位置;(b) $1/|y_i^{(k)}|$ 把同一 step 内的 token 梯度做了步内平均,使更新幅度依赖「该 reasoning step 的质量」而非该 step 的 token 数。这两点共同解释了为什么 SAPO 能压住 outcome-reward GRPO 下常见的 reasoning verbosity 和 length drift。
5. 实验¶
5.1 设置¶
数据集:Amazon Reviews 三个类目——Office-Products、Video-Games、Industrial-and-Scientific。沿用 Kang & McAuley 的 5-core sequential recommendation 协议、leave-one-out split:最后一次交互留作 test,倒数第二次作 valid,其余作 train(含所有有效 (history, next-item) sliding-window 对)。
| Category | #Users | #Items | #Train | #Valid | #Test | Avg. seq. len. |
|---|---|---|---|---|---|---|
| Office-Products | 4,866 | 3,459 | 38,924 | 4,866 | 4,866 | 5.97 |
| Video-Games | 6,142 | 3,858 | 49,133 | 6,142 | 6,142 | 6.45 |
| Industrial-and-Scientific | 4,533 | 3,686 | 36,259 | 4,532 | 4,533 | 5.96 |
每个类目独立训练一个 $K=3$ RQ-VAE codebook(256 entries × 3 levels)。codebook 实际占用如下表:level 1 极稀疏(19–34%),level 2/3 完全占满。这条非对称恰好是 SAPO per-step credit assignment 的天然受益场景——level 1 决定大类,level 2/3 决定具体 item,预测难度差异巨大。
| Category | Level 1 ($a$) | Level 2 ($b$) | Level 3 ($c$) |
|---|---|---|---|
| Office-Products | 88 | 256 | 256 |
| Video-Games | 60 | 256 | 256 |
| Industrial-and-Scientific | 48 | 256 | 256 |
Backbone & 训练:Qwen3-1.7B;4×NVIDIA H100 (80 GB)。Stage 1/2 用 HuggingFace Trainer + AdamW + cosine schedule + 5% warmup(Stage 1 学习率 $3\times 10^{-4}$、Stage 2 学习率 $1\times 10^{-5}$,BF16,max sequence length 1024,batch 1024 samples)。Stage 3 基于 VERL + vLLM rollouts:每个 prompt 采样 $G=16$ 条 rollout(temperature 1.0,top-$p$ 1.0,max response 1024 tokens),mini-batch 256 prompts/update,actor learning rate $1\times 10^{-6}$(2% warmup),KL 系数 $\lambda=10^{-3}$ 对 Stage 2 reference,entropy 0,clip $\epsilon=0.2$(SAPO 与 outcome-reward 都用),SAPO 系数 $\alpha=1.0$(match)、$\beta=0.2$(format),decoding 始终走 trie-based constrained decoding。compute:Stage 1 约 20h、Stage 2 约 1h、Stage 3 约 48h/类目(wall-clock)。
Baselines:三类 9 个——
- 传统序列推荐:GRU4Rec、SASRec、Caser;
- 不带推理的生成式推荐:TIGER、HSTU、LCRec、LETTER;
- 带推理的生成式推荐:SIDReasoner(用官方 checkpoint)、OneRec-Think、R²ec、ReaRec。SAPO 与 outcome-reward 的对照实验共享 Stage 1/2 checkpoint,使差异只来自 Stage 3 算法。
5.2 主结果(RQ1)¶
Table 1. Main results on three Amazon-review datasets. The best result is bolded and the second best is underlined.
| Method | OP R@5 | OP N@5 | OP R@10 | OP N@10 | VG R@5 | VG N@5 | VG R@10 | VG N@10 | IS R@5 | IS N@5 | IS R@10 | IS N@10 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (i) Traditional sequential | ||||||||||||
| GRU4Rec | 0.0240 | 0.0135 | 0.0386 | 0.0181 | 0.0207 | 0.0139 | 0.0357 | 0.0187 | 0.0457 | 0.0408 | 0.0532 | 0.0432 |
| SASRec | 0.1019 | 0.0824 | 0.1167 | 0.0871 | 0.0501 | 0.0345 | 0.0723 | 0.0416 | 0.0807 | 0.0647 | 0.0964 | 0.0697 |
| Caser | 0.0232 | 0.0139 | 0.0347 | 0.0176 | 0.0247 | 0.0161 | 0.0417 | 0.0214 | 0.0459 | 0.0377 | 0.0578 | 0.0415 |
| (ii) Generative w/o reasoning | ||||||||||||
| TIGER | 0.0569 | 0.0415 | 0.0729 | 0.0467 | 0.0475 | 0.0328 | 0.0692 | 0.0397 | 0.0979 | 0.0792 | 0.1291 | 0.0885 |
| HSTU | 0.1204 | 0.1069 | 0.1323 | 0.1107 | 0.0539 | 0.0396 | 0.0746 | 0.0462 | 0.1008 | 0.0898 | 0.1138 | 0.0940 |
| LCRec | 0.0193 | 0.0135 | 0.0370 | 0.0191 | 0.0158 | 0.0115 | 0.0177 | 0.0121 | 0.0552 | 0.0512 | 0.0600 | 0.0527 |
| LETTER | 0.1315 | 0.1074 | 0.1520 | 0.1139 | 0.0445 | 0.0294 | 0.0709 | 0.0378 | 0.1080 | 0.0850 | 0.1389 | 0.0950 |
| (iii) Reasoning-based generative | ||||||||||||
| R²ec | 0.1147 | 0.0894 | 0.1486 | 0.1004 | 0.0655 | 0.0399 | 0.0931 | 0.0525 | 0.0880 | 0.0774 | 0.1253 | 0.0774 |
| ReaRec | 0.1173 | 0.0988 | 0.1385 | 0.1057 | 0.0568 | 0.0381 | 0.0746 | 0.0470 | 0.1196 | 0.1205 | 0.0870 | 0.0870 |
| OneRec-Think | 0.1353 | 0.1107 | 0.1506 | 0.1166 | 0.0413 | 0.0296 | 0.0575 | 0.0349 | 0.0464 | 0.0398 | 0.0520 | 0.0416 |
| SIDReasoner | 0.1381 | 0.1116 | 0.1629 | 0.1197 | 0.0385 | 0.0277 | 0.0578 | 0.0345 | 0.1109 | 0.0905 | 0.1438 | 0.1010 |
| SAPO | 0.1362 | 0.1141 | 0.1643 | 0.1245 | 0.0620 | 0.0413 | 0.0986 | 0.0529 | 0.1176 | 0.0931 | 0.1416 | 0.1012 |
关键观察:
- SAPO 在三个类目的 NDCG@5 和 NDCG@10 全部第一——这是「ground-truth item 在 top-K 列表中的位置」级别的指标,对 SID 序的细粒度精炼最敏感;
- 与最直接的可比工作 SIDReasoner(同样三阶段 + reasoning,Stage 3 用 rollout-level shaped reward)相比,SAPO 在 6 个 NDCG 列里有 6 个胜出,3 个 R@10 列里有 2 个胜出,仅在 OP R@5 与 IS R@10 上稍逊;说明「reasoning activation 本身不够,credit signal 还要尊重 SID 层次结构」;
- R@5/R@10 不一定每个 setting 都领先(VG R@5 上 R²ec 0.0655 略优 SAPO 0.0620),但 SAPO 在所有 Recall 列里都是第一或第二,并未出现单点崩盘;
- 不带推理的生成式 baseline(HSTU、LETTER)在 Office-Products 这种 catalog 较紧凑的类目上反而强于多数 reasoning-based baseline——这从侧面证明「光加推理并不够,关键在于 RL 信号怎么和 SID 结构对齐」。
5.3 训练动态(RQ2)¶
注:图 3(main text,Industrial-and-Scientific)与 Appendix M 中的 Figure 8 (Video-Games)、Figure 9 (Office-Products) 一致——本节描述以 Industrial-and-Scientific 为代表数据集。
五张诊断图(training reward / response length / stepwise response length / KL to reference / SID match rate)从同一 Stage 2 checkpoint 出发,比较 SAPO 和 outcome-reward GRPO:
- reward:GRPO reward 上升后塌陷或抖荡;SAPO reward 稳定爬升;
- response length & stepwise response length:GRPO 响应长度持续漂移(length drift)、单 thinking block 长度也分化;SAPO 把整体推理长度和单 thinking block 长度都控制在更窄的范围内——而且不是靠把单个 thinking block 砍短,而是靠在 SID 位置间稳定 reasoning budget;
- KL to reference:GRPO 对 Stage 2 reference 的 KL 快速攀升(format degradation 的伴随现象);SAPO 显著平稳;
- SID match rate:SAPO 的 SID-token-level 匹配率持续上升,而 GRPO 在抬高 reward 时未必抬高 SID-token-level 匹配——再次印证 outcome-level reward 提升不等价于 SID 结构上的提升。
Appendix M 的 Figure 8 / 9(Video-Games、Office-Products)扩展了同样的诊断到另两类目:VG 上 GRPO 不稳定模式更剧烈(reward collapse 与 length drift 同时发生),OP 上差异较温和但方向一致——三套数据集都支持「SAPO 通过 reasoning-step credit assignment 把 sparse exact-match RL 稳住」这一结论。
5.4 消融(RQ3)¶
Table 2. Component ablation of SAPO on three Amazon-review datasets.
| Method | OP R@5 | OP N@5 | OP R@10 | OP N@10 | VG R@5 | VG N@5 | VG R@10 | VG N@10 | IS R@5 | IS N@5 | IS R@10 | IS N@10 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Reasoning Activation (Stage 2 only) | 0.1143 | 0.0933 | 0.1410 | 0.1020 | 0.0577 | 0.0375 | 0.0926 | 0.0466 | 0.1032 | 0.0812 | 0.1299 | 0.0899 |
| Full SAPO | 0.1362 | 0.1141 | 0.1643 | 0.1245 | 0.0620 | 0.0413 | 0.0986 | 0.0529 | 0.1176 | 0.0931 | 0.1416 | 0.1012 |
| w/o per-step advantage | 0.1229 | 0.1008 | 0.1494 | 0.1093 | 0.0625 | 0.0411 | 0.0979 | 0.0528 | 0.1171 | 0.0916 | 0.1401 | 0.0990 |
| w/o per-step match reward | 0.1268 | 0.1029 | 0.1535 | 0.1115 | 0.0591 | 0.0385 | 0.0941 | 0.0498 | 0.1149 | 0.0913 | 0.1389 | 0.0990 |
| w/o both (pure GRPO) | 0.1235 | 0.1001 | 0.1490 | 0.1083 | 0.0290 | 0.0209 | 0.0427 | 0.0256 | 0.1032 | 0.0846 | 0.1207 | 0.0903 |
三种消融变体:
- w/o per-step group-relative advantage:把 $\hat A_{i,k}$ 换成 sequence-level scalar advantage,但保留 per-step match reward 与 step-normalized token aggregation;
- w/o per-step match reward:把 per-step match 换成最末位置的整 SID 元组 exact-match reward(被所有 step 共享);
- w/o both (pure GRPO):纯 rollout-level reward + rollout-level advantage 广播。
观察:
- pure GRPO 在 Video-Games 上 NDCG@10 跌到 0.0256,相对 full SAPO 损失 ~52%,SAPO 的两个组件加在一起才能避免最糟的 rollout-level 信号塌陷;
- 单独去掉任一组件,性能下降是「moderate」(OP NDCG@10 从 0.1245 跌到 0.1093/0.1115),都仍优于 pure GRPO 与 Reasoning Activation only,说明两个组件互补而非冗余。
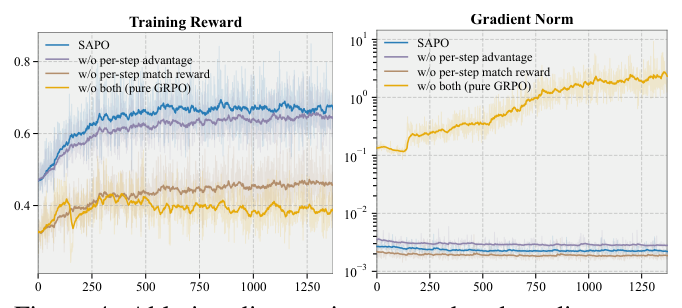
图 4 与 Industrial-and-Scientific 的训练 reward 与梯度范数 log₁₀ 曲线。Full SAPO(蓝)与去掉任一组件的变体(粉/橙)相比,pure GRPO(黄)单独表现出 gradient-norm explosion。
图 4 进一步说明组件互补:单组件消融变体并不会触发 pure GRPO 那样的 gradient-norm 爆炸——意味着「保留 per-step match reward」或「保留 step-aligned surrogate」任意一个都足以避免 rollout-level update 的最差放大。但两者都保留时 ranking 才达到最佳——stability alone is not sufficient,需要 denser SID-token feedback 加 reasoning-step advantage assignment 才能拿到峰值,由此可见 SAPO 不是孤立的 stabilizer,而是「保留完整的 step-aligned credit structure」。
5.5 训练效率¶
Table 7. Training efficiency comparison on Office-Products (Qwen3-1.7B, 4× GPU).
| Method | Wall-clock / step (s) | Peak GPU mem. (GB) | Reward+adv. / step (s) |
|---|---|---|---|
| Outcome | 85.15 | 74.83 | 0.59 |
| SAPO | 85.03 | 74.89 | 1.13 |
SAPO 与 outcome-reward 的 wall-clock per step 差距在 0.15% 以内(85.03 vs 85.15s),峰值显存几乎不变(74.89 vs 74.83 GB)。reward + advantage 计算耗时从 0.59s 升到 1.13s,但这只占整步的 0.63%——剩余开销由 rollout 生成与 actor update 主导。结论:SAPO 的额外开销不可测量,几乎是 free。
5.6 案例研究(Figure 5)¶

在 Industrial-and-Scientific 的一个测试 prompt 上,用户历史里既有 3D 打印机相关耗材(喷嘴、PLA filament、柔性联轴器)又有电子设备(pin-header + Dupont 连接器套件、NEMA17 步进电机),target 是 DRV8825 步进电机驱动器 <a_158><b_89><c_233>(3D 打印机电子 / CNC / 机器人电机驱动)。Outcome-reward GRPO 的三段 thinking block 都笼统说「3D 打印爱好者,未来会买兼容耗材」,最终预测 <a_91><b_105><c_93>(喷嘴 + 喷嘴维护套件),漏掉了「filament + extrusion → NEMA17 → motion control」这条真正的迁移信号。SAPO 的三段 thinking block 反而抓住了「电子组件 + 步进电机」这条线索,最终预测命中 ground-truth。
两个方法共享同一 prompt 与同一 Stage 2 reasoning-activation checkpoint,所以差异完全归因于 Stage 3 的 credit assignment 目标。Outcome reward 只区分「完整 SID 元组成功」与「失败」,所以一个接近正确(broadly relevant but wrong accessory)的预测与一个完全无关的预测受到同样的标量惩罚;SAPO 把 feedback 落到 reasoning step,使得 update 对「哪一位 SID 位置正确,哪一位 refinement 失败」敏感。Appendix N 提供了另外三个跨类目 case study:
- Malformed Reasoning and Lost Series Signal (Video-Games):用户历史以 Nintendo 系列为主(Super Mario World、Donkey Kong 64、Cruis'n USA),target 是 Yoshi's Story(任天堂)。GRPO 产出两段重复的 PlayStation 2 段落(malformed:thinking blocks 1 和 2 完全雷同),第三段又跳到 Nintendo 3DS 配件,最终预测
<a_219><b_116><c_229>(28-in-1 3DS 卡盒);SAPO 三段递进地论证 platforming / Nintendo / 经典风格,正确预测 Yoshi's Story。结论:outcome reward 会导致重复/格式异常的 thinking block,SAPO 保持系列信号; - Final-SID Refinement (Industrial-and-Scientific):用户历史是 thermal paste、digital audio converter、1000mL filtering flask,target 是 Buchner-style filter funnel
<a_94><b_93><c_57>。Outcome GRPO 前两位都对 (<a_94><b_93>),只在最后一位 c_57 上错成 c_171,最终预测 generic glass funnel;SAPO 在前两位与 GRPO 一致,但在最后一位精准选中 c_57。这正是 SAPO 论文中的核心论点:outcome reward 把这种「前 K-1 位对、最后一位错」的近 miss 和完全无关样本一视同仁地惩罚,SAPO 通过保留 matched-step credit 把这种 final-level refinement 学得更稳; - Recovery of a Recency-Sensitive Product-Family Cue (Office-Products):用户历史中包含 Brother ink、Canon toner、Avery foam stamp pad、3-ring binder、Staples invisible tape、LINKYO Canon toner、BIC black ballpoint pens、ACCO mini binder clips、BIC blue ballpoint pens,target 是 BIC Round Stic red ballpoint pens。Outcome GRPO 给出一段较 broad 的 office supplies 推断,最终预测 LINKYO HP toner cartridge(target not in top-10);SAPO 抓到了「最近购入两支 BIC ballpoint pens」这条 recency-sensitive cue,正确预测 BIC red ballpoints。Takeaway:SAPO 保留了 outcome GRPO 容易被 broad summary 冲掉的 recency-sensitive product-family cue。
不过 Appendix N 也诚实展示了一个 SAPO 失败 case(Over-Continuity under Sharp Product-Family Shift,Office-Products):用户历史只有两支 Sharpie highlighter,target 跳跃到 Pendaflex file folders。outcome GRPO 借助一种笼统「办公文具」的判断意外猜中,SAPO 因为过度复用 highlighter family 反而预测了 Sharpie pink highlighter。这条 takeaway 是「SAPO 并非消除所有错误:当 next item 与历史出现 sharp family shift 时,SAPO 反而会 over-use 局部连续性」——值得在后续工作里探讨 reasoning-step prior 与 list-level diversity 的折衷。
6. 与已归档相关工作的对比¶
ReRec ReRec: Reasoning-Augmented LLM-based Recommendation Assistant via Reinforcement Fine-tuning (HK PolyU, 2026-04-09)¶
关系:独立并发(SAPO 未引用 ReRec,两者殊途同归)· 已加载对方精读
- 共同关注的问题:reasoning-augmented LLM-based 推荐里,outcome-level / rollout-level RL advantage 会把同条 rollout 的所有 token(包括对的推理段 / 推理 token、对的最终预测 token)一并奖惩,无法区分「中间推理段正确与否」。两篇论文的诊断高度同构:rollout 太粗、需要在 rollout 内部寻找更精确的 credit-assignment unit。
- 相近的技术骨架:都让 group-relative advantage 下沉到 sub-rollout 单元,再把单元级 advantage 广播到该单元内的 token。
- 本文 SAPO 的差异与推进:
- 拆分单元:SAPO 把推理 trace 拆成 $K$ 个「thinking block + 配对 SID token」step,是结构层面的 先验固定 拆分(来自 RQ-VAE 的层次 codebook);ReRec 用
\n\n段落切分自然语言推理,是 文本启发式 拆分。SAPO 的拆分粒度恰好与 verifiable per-step reward 对齐——每个 step 都有 ground-truth SID 可比对——所以 reward placement 与拆分单元天然 1:1 匹配;ReRec 需要额外用 (prediction, object) 元组语义匹配来判定段落对错,缺少天然可验证 supervision; - reward design:SAPO 只用 per-SID-token 匹配指示 + 末位 format bonus,没有学习型 reward model,per-step reward 与 outcome 联合的 exact-match optimum 在 realizability 下严格一致(Proposition 1);ReRec 用 NDCG + dual-graph soft reward (QAS + PAS),需要 attribute graph 与预训练 LightGCN,引入额外信号源;
- 目标场景:SAPO 在 SID-decoded sequential next-item 上(K=3 codebook),ReRec 在 query-driven 复杂查询推荐上(RecBench+),任务形态差异较大但 RL 改造模式高度一致;
-
训练稳定性诊断:两篇都对比了 outcome-reward GRPO 与自家方法的 reward 与梯度动态(SAPO 强调 length drift / KL 漂移 / SID match rate 解耦;ReRec 强调段落级反馈带来的细粒度信号),结论一致——sub-rollout credit assignment 显著改善 sparse-reward RL 稳定性。
-
可比的方法差异:SAPO 的拆分有「先 K 段 thinking、再 K 段 SID」的 blocked layout,并依赖 trie-based constrained decoding;ReRec 的段落拆分对解码格式更松;两者结合可能性:把 ReRec 的 dual-graph soft reward 当 SAPO per-step reward 的补充(attribute-level 软监督 + SID-level hard 监督),可能进一步降低稀疏命中下的 group degeneracy。
ReCast ReCast: Recasting Learning Signals for Reinforcement Learning in Generative Recommendation (Huawei, 2026-04-24)¶
关系:独立并发(SAPO 未引用 ReCast,两者直指同一痛点的不同维度)· 已加载对方精读
- 共同关注的问题:稀疏 exact-match reward 让 GRPO 在生成式推荐 RL 阶段的优化信号塌陷——SAPO 形式化为「rollout 太粗、单 token 太细,需要 reasoning-step 这一中间单元」;ReCast 形式化为「sampled group 不再是 usable learning unit——85% 的 group 全零、13% single-hit、只有 2% multi-hit」。
- 相近的技术骨架:两者都拒绝默认的 GRPO advantage 公式,但改造方向正交:
- SAPO 改 rollout 内部 的 advantage granularity:把 rollout 拆成 reasoning step,每个 step 单独做 group-relative 归一化,使「同位置的不同 rollout」直接对比;
-
ReCast 改 rollout 之间 的 advantage 构造:把 all-zero group 注入 ground-truth anchor 修复,再只挑「最强正例 + 结构最相似的 hardest near-miss」做对比更新,弃用整组 reward 归一化。
-
本文 SAPO 的差异与推进:
- credit-assignment 单元:SAPO 是 step-level(一个 rollout 内拆 K 份);ReCast 是 sample-pair-level(一个 group 内挑一对正负);
- 是否使用 ground-truth anchor:SAPO 不引入 anchor、只用 ground-truth SID 元组与生成 SID 比对得到 per-step match;ReCast 在全零 group 时把 ground-truth 注入 group 替换最差 sample,最大化保留 informative negative;
- 理论 anchor:SAPO 给出 Proposition 1(per-step match 与 outcome optimum 在 realizability 下重合),ReCast 给出 group-degeneracy 经验统计(图 1);
-
补足关系:两者互补而非替代——一篇是「group-level 学得动了之后怎么落到 step」,另一篇是「group 根本无信号时如何修复」。组合用法(先 ReCast 修复全零 group,再用 SAPO step-level advantage 替换全组归一化)值得后续探索;
-
可比的方法 / 实验差异:ReCast 与 SAPO 都在 Amazon-review 三个类目(OP/IS + Toys,分别配置)上做实验,但 ReCast 用 OpenOneRec 系列设置(不带推理),SAPO 用 Qwen3-1.7B + 三阶段(带推理)。目前两篇没有在同一 setting 下交叉比较,是未来联合实验可补的空白。
7. 讨论与局限性¶
核心贡献:SAPO 把「outcome-reward GRPO 在 reasoning-based SID 解码下失效」这一长期被混入「reward sparsity」名下的现象,精确诊断为 action-granularity mismatch——rollout 太粗、token 太细,正确单元是「thinking block + 配对 SID token」这一 reasoning step。围绕这个单元,论文同时定义了:
- per-step match reward(denser supervision,但与 outcome exact-match optimum 在 realizability 下一致);
- per-step group-relative advantage(更宽的 informative rollout-group 集合);
- step-normalized token aggregation(让 update 幅度依赖 step 质量而非 step 长度)。
三件套是「同一 granularity 上的三个一致 design choice」,缺一不可(Table 2 + Figure 4 验证)。论文的核心方法论 takeaway——「generation task 凡是天然带层次结构(codebook、tool-call schema、structured answer format)的,hierarchy 本身就可以作为 RL per-step supervision 的根本来源,无需学习型 reward model」——把 SAPO 提升到 PRM-style process supervision 的通用方法论高度,对 tool-use、structured output、多轮 agent 等场景都有迁移潜力。
值得借鉴的设计: 1. 结构先验作为 process supervision 来源:SID codebook hierarchy 本身决定了 RL 的天然 step 划分,不需要标注;这点和 RecCoT、Process-RM 等需要人工或学习型 PRM 的工作形成鲜明对比; 2. 「reward placement / advantage granularity / token aggregation」必须同 granularity:三者错配(如 only per-step reward + rollout advantage)会带来 Table 2 中观察到的 moderate 性能下降; 3. step-normalized aggregation 隐式控制 length drift:用 $1/|y_i^{(k)}|$ 而不是「平均到 rollout 总长」更稳,避免被某条 rollout 内最长的 thinking block 主导,对反向缓解 reasoning verbosity 有实证效果(Figure 3); 4. objective-consistency proof:把 dense per-step match reward 与 outcome optimum 严格相连,避免「reward shaping 改变了 optimum」的常见疑虑。
局限:
- Catalog 规模与 SID 深度:实验只在三个英语 Amazon Reviews 类目(≤4k items、$K=3$);catalog 更大、SID 层次更深或层级更不均衡时,per-step credit assignment 是否仍稳定,尚未验证。论文 Appendix C 也明确指出这是一个 evaluation scope 的限制;
- Stage 2 reasoning activation 的依赖:SAPO 把 thinking block 作为 已经有结构化推理 的 starting checkpoint;如果 Stage 2 推理激活做得不到位(如某些 thinking block 完全无信息),per-step advantage 的信号质量可能下降。论文未给出对 Stage 2 弱 checkpoint 的鲁棒性分析;
- Feedback signal 的依赖:当前实验全部是 ground-truth SID exact-match 的 clean per-level verifiable feedback,对噪声 implicit feedback(click、dwell、conversion)、production-oriented 多 ground-truth 场景下的拓展尚需验证;
- Decoding layout 的局限:blocked layout 要求 K 个 thinking block 在前、K 个 SID token 连续在后,约束了 reasoning–SID 交错布局;如「写完一个 thinking block 立刻输出对应 SID token、再继续下一段 thinking」这种 interleaved 结构在 SAPO 当前框架下是否仍稳定,是一个开放方向;
- 应用价值:当前仅在公开学术 dataset 上验证,未在工业平台上线,没有 A/B 数据;SAPO 的 free-of-overhead 特性(Table 7)意味着工业落地阻力低,但实际收益需要真实场景验证。
与已有工作的差异:
- 相比 SIDReasoner、OneRec-Think、R²ec、ReaRec 等 reasoning-based GR baseline,SAPO 不是引入新的推理结构或预训练数据,而是改造 Stage 3 RL 算法本身——共享同一 Stage 1/2 checkpoint,单点改造,性能在 NDCG 列上一致领先;
- 相比 ReRec、ReCast 等独立并发的「sub-rollout credit assignment」工作,SAPO 选择了 hierarchical SID 这条 天然结构 的拆分维度,证明在结构化生成任务里 hierarchy 就是免费的 process supervision 信号。