The Geometric Wall: Manifold Structure Predicts Layerwise Sparse Autoencoder Scaling Laws¶
Eslam Zaher, Maciej Trzaskowski, Quan Nguyen, Fred Roosta ARC Training Centre for Information Resilience (CIRES) / University of Queensland / QIMR Berghofer arXiv:2605.09887, May 11 2026
研究动机与背景¶
Sparse Autoencoder 程式所依赖的"线性可读性"假设¶
机理可解释性(mechanistic interpretability)当前的主流路径是把语言模型某一层的隐藏激活 $h_\ell \in \mathbb{R}^{d_\ell}$ 用稀疏自编码器(Sparse Autoencoder, SAE)拆解:
$$a = \phi(W^{\text{enc}} h + b^{\text{enc}}) \in \mathbb{R}^n, \quad \hat h = W^{\text{dec}} a + b^{\text{dec}}, \quad n \gg d_\ell$$
字典原子($W^{\text{dec}}$ 的列)被假设为可解释的语义方向,激活则是它们的稀疏线性组合。这一切的隐含几何前提是线性表示假设(Linear Representation Hypothesis, LRH):激活空间本质上是一个"被一组稀疏线性基服务良好的全局欧氏空间"。
Gao et al. (OpenAI, 2025) 把这件事数量化:在 GPT-4 的某一层(约总层数的 5/6 深度)拟合到一个联合幂律
$$L(n, k) = A(k) n^{-\alpha(k)} + B(k) \tag{1}$$
其中 $n$ 是字典宽度,$k$ 是稀疏度(活跃 latent 数),$L$ 是 per-sample NMSE。$A(k) n^{-\alpha(k)}$ 是可约损失(reducible loss),$B(k)$ 是不可约的渐近地板(asymptotic floor)。Gao et al. 只在一个层上拟过,并提出一个 tentative 的"结构光谱"(spectrum of structure)解释:地板的存在源于"激活中有一部分像无结构高斯噪声那样的成分"。
三个独立线索暗示 LRH 不够¶
但有三类经验观测已经独立暴露出 LRH 这副单层线性叙事的裂缝:
- 跨层差异:在同一族 Gemma 2 模型上,SAE 重构误差在中层之外几乎水平、在末层突然抬升,并且把激活换成 SAE 重构在下游会让模型损失放大数倍(Engels et al. 2025 的 "dark matter" 现象、Gurnee 2024 的 "empirically pathological" SAE 重构)。
- 非线性特征几何:Engels et al. 2025("Not all features are one-dimensionally linear")、Li et al. 2025、Park 等关于多层级 polytope 的工作显示语义特征本身就经常长在曲面上而非简单方向上。
- 激活流形几何:Ansuini 2019 / Valeriani 2023 / Mabrok 2026 在不依赖 SAE 的视角下测出 Transformer 激活流形的内禀维度沿深度呈"驼峰"型剖面——早层快速上升、中层达到峰值、深层下降;曲率与维度系统性变化(Park et al. 2026 "information geometry of softmax")。
这三条线索此前都是孤立观察。本文的核心主张:它们共享同一个根因——几何错配(geometric mismatch)。一组"全局共享、平展的稀疏线性原子"无法被均匀地适配到一个曲率与内禀维度随深度变化的流形上,于是 SAE 的宽度-稀疏度 scaling law 必然沿层成为流形几何的函数,而不是某条普适常律。
宽度-稀疏度 scaling 本身不会失效,它会失去普适性——这就是"几何墙"(geometric wall):SAE 遭遇的不是有限算力的天花板,而是被它试图重构的流形几何决定的下界。
本文要回答的问题¶
作者把上述论点压缩为一个可证伪的预测:每一层的 SAE scaling law 的两个钩子——可约部分的 width exponent $\alpha(k)$、不可约的地板 $B(k)$——都应该是该层激活流形若干几何量的函数;这些函数还应该跨模型可迁移**。
实验对象:Gemma Scope 公开放出的 844 个 JumpReLU SAE 检查点,覆盖 Gemma 2 2B(26 层)和 9B(42 层)的残差流。
核心贡献¶
作者把贡献明确归纳为三条:
(i) 几何框架:用 pullback 信息几何把"为什么激活空间不一定承认全局高效稀疏线性码"形式化,给出可证伪的方向性预测——内禀维度更高、曲率更大的层应该宽度 scaling 更慢。
(ii) 几何条件 scaling law:把 Gao et al. 的单层定律扩展为几何条件版本——scaling 参数本身是层级几何特征的层级函数。模型分别拟合,并通过闭式 leave-K-layer-out 交叉验证 + 层置换 null 来做严格识别。
(iii) 跨模型几何律 + 地板耦合:在 844 个检查点上验证:(a) 在 2B 上学到的几何回归系数能在 9B 上预测每层 $\alpha$,反之亦然,$R^2 \approx 0.92\sim0.99$;(b) 在 width 网格够密的 6 个 "showcase" 层上识别出的地板 $B_\ell$,其层间排序与 $d_\text{int}, \kappa_\text{ms}$ 完全一致——把 Gao et al. 模糊的 "spectrum of structure" 解释具体化为两个明确的几何通道。
几何框架:pullback 信息几何¶
Fisher–Rao 度量与拉回¶
Transformer 的前向预测映射 $F_\ell : \mathbb{R}^{d_\ell} \to \Delta_\circ^{V-1}$ 把隐藏态送到 next-token 分布。统计模型上"自然的"黎曼度量是 Fisher 信息度量(按 Chentsov 定理,是在充分统计量下唯一不变的度量)。对于 logit 坐标下的范畴分布 $\pi$,Fisher 度量是
$$\boldsymbol{\Sigma}_\pi = \text{diag}(\pi) - \pi \pi^\top \tag{4}$$
利用预测映射 $F_\ell$ 把这个度量拉回到激活空间,得到拉回度量(pullback metric):
$$\mathbf{G}_\ell(h) = J_\ell(h)^\top \boldsymbol{\Sigma}_{F_\ell(h)} J_\ell(h) \tag{5}$$
其中 $J_\ell(h) = \partial z_\ell / \partial h$。在 $\ker J_\ell$ 方向上的扰动对输出不可见——也就是说,激活空间中欧氏距离接近的两点在拉回度量下可能很远,反之亦然(详见附录 A)。
几何错配的两个来源¶
作者把 SAE 的几何错配解剖成两层:
- basis–manifold 错配:SAE 的扁平 $k$-稀疏线性字典即使配上正确的度量也无法适配一个弯曲的流形;
- objective–metric 错配:训练目标里的 $\ell_2$ 损失用的是环境欧氏距离而不是拉回距离。
为了在大规模实验中可计算,作者用 4 个外在欧氏估计量作为几何代理:
- $d_{\text{int},\ell}$ — 内禀维度:流形局部自由度数。Facco et al. 2017 的 TWO-NN 估计量(取最近邻距离与次近邻距离之比);
- $\kappa_{\text{ms},\ell}$ — 多尺度曲率:多尺度局部 PCA 残差(小邻域 vs 大邻域)的差,捕捉切平面之外的二阶项;
- $\kappa_{\text{tv},\ell}$ — 切平面变动率:邻近点切空间之间的主角度,用 chordal/Frobenius 距度量;
- $\nu_\ell$ — 异质性:层内逐点内禀维度的标准差。
直观上,这 4 个量分别度量"流形多大""曲多远""扭多快""粗糙程度"。每一个都会从不同方向影响"全局稀疏线性近似的效率"。
为什么这些代理够用¶
对 4 个估计量与拉回几何的数学对应,作者在附录 A 中证明:(1) 内禀维度是流形的拓扑性质,独立于度量;(2) 拉回曲率与欧氏曲率相差一个连续的非退化变换,保持定性序关系;(3) 异质性 $\nu$ 继承内禀维度的度量不变性。换言之,欧氏估计量的层间排序与拉回估计量的层间排序在大概率上一致。
方法:两阶段几何回归¶
整体方法可以拆为两步:先在每层上拟合一个 4 参数 scaling 曲面;然后把每层的拟合参数用 4 个几何量去回归。这种"先做层级摘要、再做跨层回归"的结构,使得"几何决定 scaling"这条因果链可以用统计检验来 falsify。
Stage 1:层级 scaling 曲面拟合¶
在每层 $\ell$,对所有可用的 $(n, k, L)$ 三元组做 PCHIP 插值后,拟合 4 参数对数线性曲面
$$\log L_\ell(n, k) = a_{0,\ell} + \beta_{n,\ell} \log n + \beta_{k,\ell} \log k + \gamma_\ell \log n \cdot \log k \tag{6}$$
这是 Gao et al. 的 with-floor 形式(公式 1)在 $B = 0$ 假设下的 log-linearisation。在 $A n^{-\alpha}$ 仍占主导的小-$k$ 区间,这是 $L(n,k)$ 的合理近似。Gemma Scope 数据集中绝大多数层只有 2 个 backbone 宽度(小: 16K, 大: 65K/128K),没有足够的 width 网格识别 with-floor 6 参数曲面——只有 6 个 "showcase 层"(2B: $\ell \in \{5, 12, 19\}$;9B: $\ell \in \{9, 20, 31\}$)有 ≥3 widths。所以全层用 no-floor 4 参数曲面,showcase 层再额外做一次 with-floor 重拟合。
从 Stage 1 系数读出每层在任意稀疏度 $k$ 下的宽度 scaling exponent:
$$\alpha_\ell(k) = -(\beta_{n,\ell} + \gamma_\ell \log k) \tag{7}$$
正文重点报告 $k = 50$ 下的 $\alpha_\ell(50)$。这是一个层级标量目标,下面 Stage 2 就是要用层级几何特征把它解释掉。
Stage 2:跨层几何回归¶
把每层的 4 个几何量 $\mathbf{g}_\ell = (d_{\text{int},\ell}, \kappa_{\text{ms},\ell}, \kappa_{\text{tv},\ell}, \nu_\ell)$ 经过统一 log + 1/99 percentile clip + per-feature standardise 后,做 OLS:
$$y_\ell = \mu + \sum_{p=1}^P \theta_p\, g_{\ell, p} + \varepsilon_\ell, \quad P \in \{1, 2, 4\} \tag{8}$$
回归目标 $y_\ell$ 分别取:$\alpha_\ell(k = 50)$(主结果),以及分解出的 $\beta_{n,\ell}$ 和 $\gamma_\ell$(消融)。回归是 per-model 单独拟合——不把两个模型的层堆在一起跑,以避免模型特定的截距污染。
假设阶梯¶
为了把"几何到底有没有贡献"做成一个可证伪的统计检验,作者列了一组嵌套假设:
- H0(geometry-invariant null):$y_\ell$ 跨层是常数(1 个参数)。这是"单层 scaling law 推到全层"的隐含假设——什么也不用解释。
- H1$_g$(单特征):$y_\ell$ 只依赖于一个几何特征 $g$。每个 $g$ 给一行。
- H2$_{\text{low}\rho}$:依赖于在 9B 上相关系数 $|\rho|$ 最小的两个特征(最小共线对);为了对称两个模型上都用同一对。在 9B 是 $d_{\text{int}} + \kappa_{\text{ms}}$,2B 是 $d_{\text{int}} + \nu$。
- H$_{\text{full}}$:依赖于全部 4 个几何特征。
每个嵌套模型给出 in-sample $R^2$、leave-1/2/3-layer-out $R^2$(通过 hat 矩阵闭式计算)、AIC/BIC、F-检验。关键比较是 H0→H1:如果 H0 被拒绝,"单层定律普适"假设就被推翻。
Floor calibration(showcase 层)¶
在 6 个 showcase 层上重新拟合 with-floor 6 参数曲面(Eq. 1),用多 seed 非线性 LSQ + 3 重单调过滤(L-单调前缀、局部-$\alpha$ 单调、跨-$k$ $\alpha$-单调)。结果给出每层的"严格地板" $B_\ell(k)$,与几何特征对照排序,作为 $\alpha$ 之外的第二个几何信号。
关键技术细节¶
- 几何 / 误差数据严格不相交:用 C4 验证集的 0–5K 条序列估几何,5K–10K 条估误差,每层每分区抽 50K 激活向量。跨语料用 WikiText-103 重测误差作为稳健性检查;
- 激活 norm 顶/底 5% 修剪:防止极端范数 token 扭曲 $k$-NN 图(影响所有几何估计量);
- 激活做全局中心化但不白化、不归一化:归一化会破坏曲率信号;
- NMSE 用 5/95 trimmed mean:per-token NMSE 是重尾的,少量小/大 $\|h\|$ token 会让标准均值偏离中位数,trimmed mean 紧跟中位数(图 6 的 6 个 representative cell 验证)。
实验设置¶
模型与 SAE 家族:
| 模型 | 层数 $\mathcal{L}$ | 维度 $d$ | Backbone widths | Showcase widths(layer 上 ≥3 widths) |
|---|---|---|---|---|
| Gemma 2 2B | 26 | 2304 | 16K, 65K | 6 layers × up to 7 widths |
| Gemma 2 9B | 42 | 3584 | 16K, 128K | 6 layers × up to 7 widths |
总检查点:312(2B) + 532(9B) = 844 个 JumpReLU SAE。
训练 budget(width-dependent,关键 caveat):4B / 8B / 16B tokens 分别对应 ≤16K / 32K–524K / 1M dictionary widths。这是 sublinear in width——按 Gao et al. 在 GPT-4 上对 TopK SAE 的 convergence-scaled allocation 应该是 $n^{0.65}$,所以发布的 1M-width SAE 大约只跑到 convergence-budget 的 1/4。这意味着本文给出的绝对 scaling exponent 是"as-trained"而不是"to-convergence"的值;但跨层几何相关性的存在性不依赖这个 caveat。
协议要点:
- Stage 1 用 PCHIP(scipy.interpolate.PchipInterpolator)在稀疏度轴插值;
- Stage 2 用闭式 LOO via hat 矩阵 + 1000 次层置换 null + nested F-test ladder(H0 → H1$_\text{best}$ → H2$_\text{best+next}$ → H$_\text{full}$);
- 跨模型转移:在源模型上拟参数(含 mean/std 标准化),把同一组系数用于目标模型的层级几何,对比 transfer $R^2$ 与目标模型自身 in-sample $R^2$。
主要实验结果¶
现象学:几何与重构沿深度共变¶
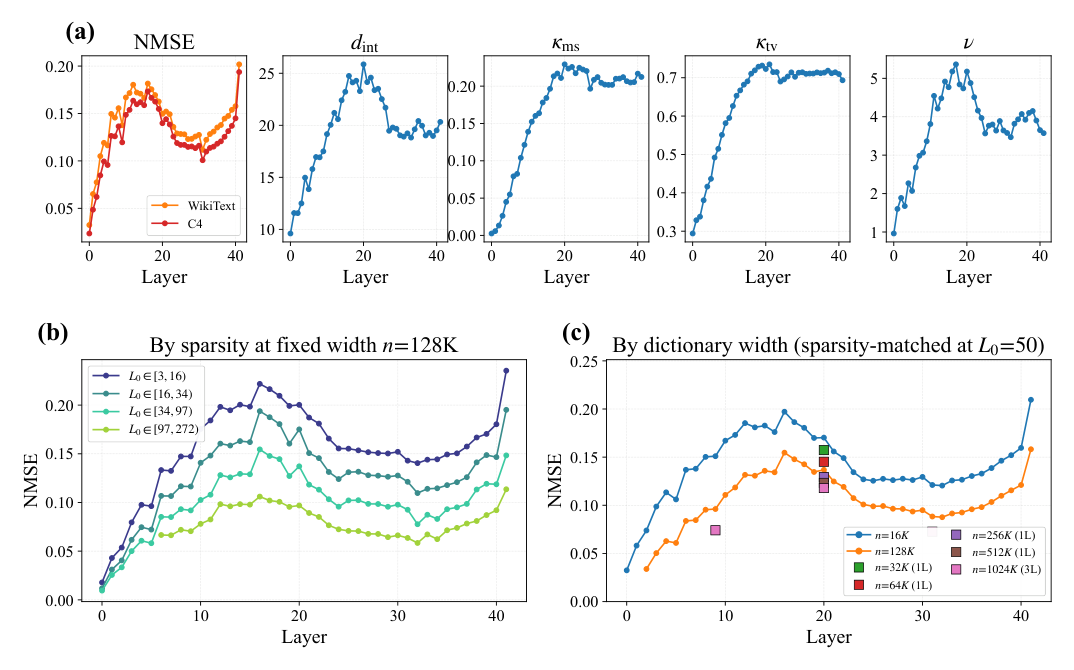
图 1(a)(9B)和 Figure 8(2B)展示了整篇文章的现象学:
- NMSE 剖面:早层快速上升,中层短暂下凹,中后段平台,末层突变向上抬升;C4 与 WikiText-103 两条曲线全程贴合(同一现象不是某语料的 artefact);
- 几何摘要:$d_{\text{int}}$ 与 $\nu$ 在中段达到峰值后下降(驼峰型),$\kappa_{\text{ms}}$ 与 $\kappa_{\text{tv}}$ 从早层抬升后维持平台;
- 稀疏度切片(图 1b):增大 $L_0$ 整体把 NMSE 抬高一个常数 level,但层间剖面形状几乎不变——稀疏度移动 stratum 不重塑形状;
- 字典宽度切片(图 1c):两条 backbone 在绝对值上大致平行,但乘积比 shrinks with depth——每层 width-scaling 效率沿深度变化。
这就是 Stage 1+2 要正式刻画的"两段式 fit"的现象基础。
Per-layer scaling exponent 被几何预测¶
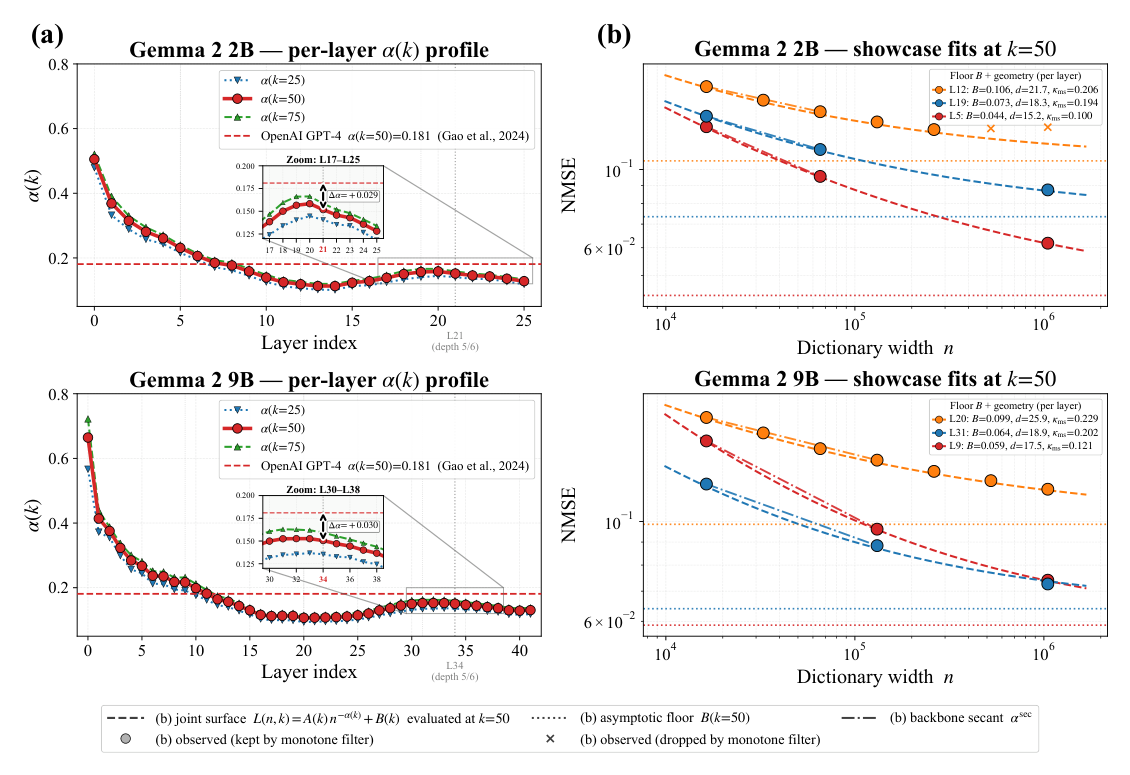
图 2(a) 是文章最有力的可视化:
- 每层 $\alpha_\ell(k = 50)$ 从输入侧的较高值(早层 ~0.5)下降到中后层的最低值,然后在约 5/6 深度反弹到 ~0.181——精确落在 Gao et al. 在 GPT-4 同一相对深度报告的 $\alpha(k=50) = 0.181$ 的 ±0.03 之内。两个不同尺寸的 Gemma 与 GPT-4 在相同相对深度上 $\alpha$ 一致,这是首个观察到的跨架构 $\alpha$ 深度对齐。
- 在 Showcase 层右侧 (b):水平虚线是拟合的渐近地板 $B_\ell(k=50)$,层间排序与 $d_{\text{int}}, \kappa_{\text{ms}}$ 同序——更曲、更高维的层有更高的地板。
Table 1:Stage 2 在 9B 上的回归结果¶
Stage 2 在 Gemma 2 9B 上以 $\alpha_\ell(k=50)$ 为目标的回归($n = 42$ layers):
| Hypothesis | $R^2$ | LOO | L2O | L3O | AIC | BIC | F vs H0 | $p$ |
|---|---|---|---|---|---|---|---|---|
| H0 | 0.000 | -0.049 | -0.050 | -0.051 | -188 | -186 | — | — |
| H1$_{d_\text{int}}$ | 0.812 | +0.738 | +0.738 | +0.737 | -256 | -253 | 173.2 | $\lt 10^{-10}$ |
| H1$_{\kappa_{\text{ms}}}$ | 0.929 | +0.869 | +0.869 | +0.869 | -297 | -294 | 523.6 | $\lt 10^{-10}$ |
| H1$_{\kappa_{\text{tv}}}$ | 0.862 | +0.793 | +0.792 | +0.791 | -269 | -266 | 250.6 | $\lt 10^{-10}$ |
| H1$_\nu$ | 0.821 | +0.745 | +0.744 | +0.743 | -258 | -255 | 182.9 | $\lt 10^{-10}$ |
| H2$_{d_\text{int}+\kappa_{\text{ms}}}$ | 0.935 | +0.863 | +0.863 | +0.862 | -299 | -294 | 281.2 | $\lt 10^{-10}$ |
| H$_{\text{full}}$ | 0.940 | +0.806 | +0.806 | +0.805 | -298 | -290 | 145.5 | $\lt 10^{-10}$ |
关键观察:
- H0 被压倒性拒绝(每行 $p \lt 10^{-10}$)。"层级 scaling exponent 是常数"的零假设彻底崩塌——单层 scaling law 不能推到全层;
- $\kappa_{\text{ms}}$ 是单特征冠军:单独一项就把跨层变化解释掉 ~87%(LOO $R^2 = +0.869$);H$_\text{full}$ 加入剩余 3 个特征只多 ~0.07 in-sample $R^2$,LOO 反而因共线性掉到 +0.806。
- 多尺度曲率是主导通道:4 个特征里几乎所有信号都集中在 $\kappa_{\text{ms}}$ 上;它和 $d_{\text{int}}$ 高度 colinear(都是同一个"流形复杂度"的不同侧面),AIC/BIC 偏好更简单的 H1 / H2。
2B 上的对应表(Table 2)显示几乎相同模式:H1$_{\kappa_{\text{ms}}}$ in-sample $R^2 = 0.979$, LOO $R^2 = +0.976$;H$_\text{full}$ 在 2B 上更高(layer 数更少时 H$_\text{full}$ 更容易拟合)。
Table 3:$\beta_n$ 与 $\gamma$ 的分解¶
直接对 $\alpha(k)$ 回归并不能区分"几何抬高了曲线的整体水平"还是"几何调了曲线对 $\log k$ 的斜率"。Table 3(9B)把 $\alpha_\ell(k) = -(\beta_{n,\ell} + \gamma_\ell \log k)$ 分解,分别回归 $\beta_n$ 和 $\gamma$:
| Target | Hypothesis | $R^2$ | LOO | F vs H0 | $p$ |
|---|---|---|---|---|---|
| $\beta_n$ | H1$_{d_\text{int}}$ | 0.751 | +0.662 | 120.5 | $1.2\text{e-}13$ |
| $\beta_n$ | H1$_{\kappa_{\text{ms}}}$ | 0.684 | +0.477 | 86.6 | $1.5\text{e-}11$ |
| $\beta_n$ | H$_\text{full}$ | 0.856 | +0.685 | 54.8 | $4.7\text{e-}15$ |
| $\gamma$ | H1$_{\kappa_{\text{ms}}}$ | 0.661 | +0.354 | 78.1 | $6.0\text{e-}11$ |
| $\gamma$ | H$_\text{full}$ | 0.740 | +0.229 | 26.4 | $2.2\text{e-}10$ |
$\beta_n$(level)比 $\gamma$(tilt)回归更干净——几何先决定 $\alpha(k)$ 曲线的整体水平,再次决定其对稀疏度的斜率。物理含义:层级几何把整条 $\alpha(k)$ 曲线作为一个单元上下平移,而不是只调它在某个 $k$ 上的某个特殊点。
Table 5:跨模型几何律转移¶
这是文章最有冲击力的结果。在源模型上拟 Stage 2 系数,直接套到目标模型的层级几何上预测目标模型的 $\alpha(k=50)$(不重新拟参数):
| Target | Train→Test | Hypothesis | Transfer $R^2$ | Test in-sample $R^2$ | $\Delta$ |
|---|---|---|---|---|---|
| $\alpha(50)$ | 2B→9B | H1$_{\kappa_{\text{ms}}}$ | +0.920 | +0.929 | -0.009 |
| $\alpha(50)$ | 2B→9B | H2$_{d_\text{int}+\kappa_{\text{ms}}}$ | +0.933 | +0.935 | -0.002 |
| $\alpha(50)$ | 2B→9B | H$_\text{full}$ | +0.935 | +0.940 | -0.005 |
| $\alpha(50)$ | 9B→2B | H1$_{\kappa_{\text{ms}}}$ | +0.970 | +0.979 | -0.009 |
| $\alpha(50)$ | 9B→2B | H2$_{d_\text{int}+\kappa_{\text{ms}}}$ | +0.985 | +0.988 | -0.003 |
| $\alpha(50)$ | 9B→2B | H$_\text{full}$ | +0.983 | +0.989 | -0.006 |
Transfer $R^2$ 与目标模型自身 in-sample 上界相差 $\le 0.01$——这是几乎完美的跨模型迁移。在两个方向都成立。几何上的解读是:从激活流形几何到 width-scaling rate 的函数 $f: \mathbf{g}_\ell \mapsto \alpha_\ell$ 在 Gemma 2 家族的 2B↔9B 尺寸跳跃上是保留的,不是某种 idiosyncratic 偏置。
Floor calibration:几何墙的"严格读数"¶
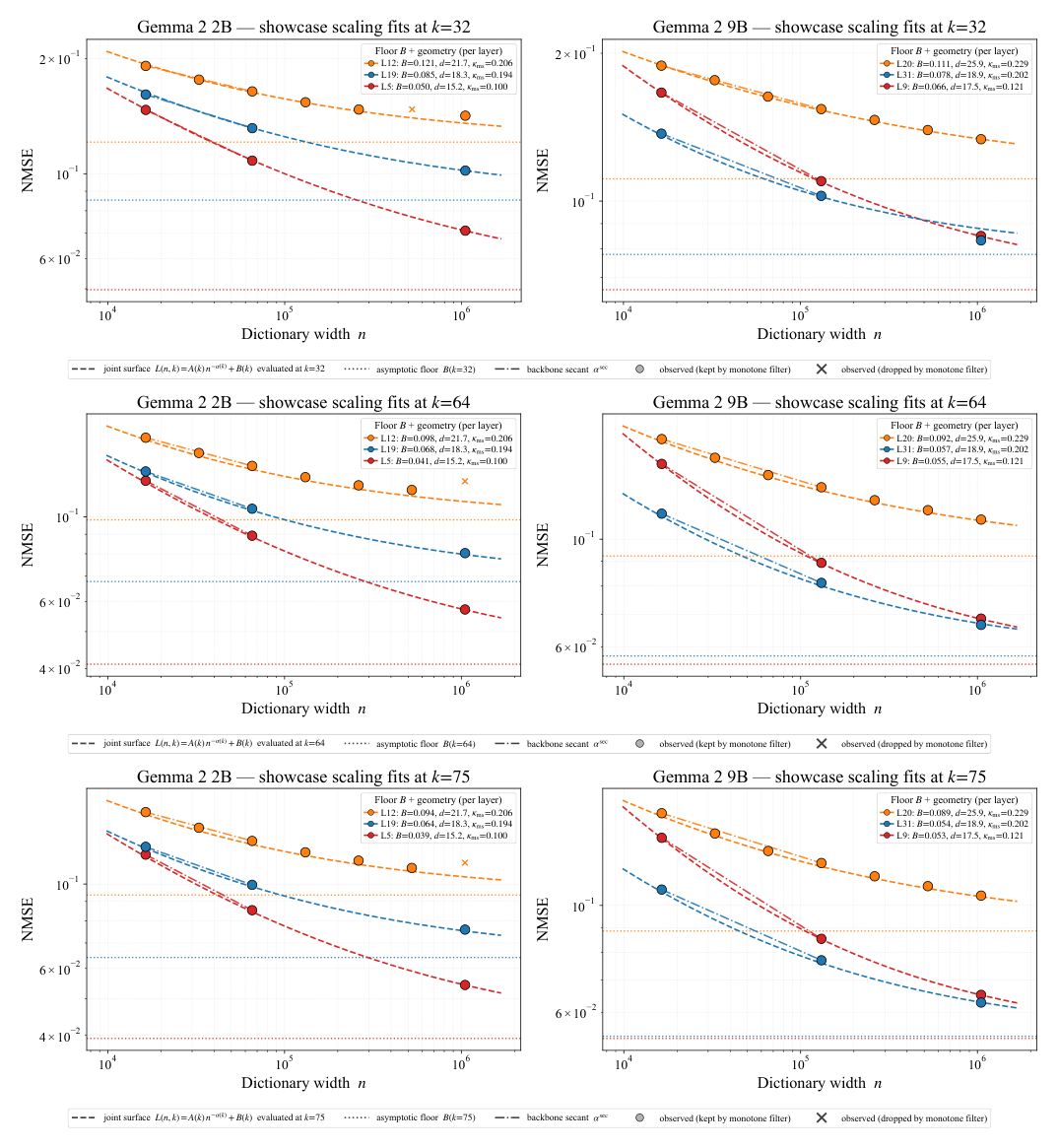
在 6 个 showcase 层重新拟 6 参数 with-floor 曲面($L(n,k) = A(k) n^{-\alpha(k)} + B(k)$),得到的严格地板 $B_\ell(k = 50)$ 排序与该层的 $d_{\text{int}}, \kappa_{\text{ms}}$ 排序在所有 6 个层、两个模型上都一致。图 7 把这个排序在 $k \in \{32, 64, 75\}$ 上也复现——地板-几何耦合不是 $k = 50$ 的 artefact。
机理解读(附录 E):SAE 字典原子用扁平 $k$-稀疏线性组合逼近激活流形,最佳局部近似在切平面。当主曲率非零,切平面与流形偏离一个 $\sim$ (squared local distance) × (curvature) 的二阶项;即便原子无穷致密,这部分残差也不可消除——这就是地板。同时高 $d_{\text{int}}$ 意味着任何有限原子预算覆盖局部切空间的份额更小。两个机制同向:$d_{\text{int}}$ 通道对应 Gao et al. 的 "spectrum of structure"(无结构方差),$\kappa$ 通道是真正新的——即便在低 $d_{\text{int}}$ 的曲面流形上 SAE 仍会被曲率打住。
鲁棒性与验证¶
作者花了相当大力气把"是 artefact 还是真信号"的可能性堵死:
- 层置换 null(每行假设 1000 次随机重指派几何向量):观察到的 LOO 落在零分布之上,$p \le 0.01$ 全部 cells;
- 非参数 secant exponent(附录 D):直接用两条 backbone width 间的 chord slope $\alpha_\ell^{\text{sec}}(k)$ 替换 Stage 1 参数化拟合,同结论(每层 $\alpha$ agreement within ±0.01);
- 范数修剪:trimmed vs untrimmed NMSE、$L_0$ 都做了——除了 $\nu$ 在早期层稍敏感外,其余三个几何量稳定;
- 多 $k$ 稳定性(图 9):在 $k \in \{16, 25, 32, 50, 64, 75\}$ 上重复 Stage 2 回归,H1$_{\kappa_{\text{ms}}}$ 在 2B 上 LOO $R^2 \in [0.96, 0.98]$,9B 上 $[0.85, 0.92]$,单 feature 排序在所有 $k$ 上都保持;
- PCHIP 插值检验:留 1 个 $L_0$ 重拟,预测 vs 实测 median per-cell $R^2 = 0.998$(2B)/ 0.9996(9B)——插值在 Stage 1 表面拟合上引入的噪声可忽略;
- 跨语料检查:用 WikiText-103 重算 NMSE 同时几何仍来自 C4,深度剖面不变;
- per-checkpoint 直接回归 $\log L$ on geometry(附录 F):在所有 312/532 checkpoints 上直接回 $\log L$,加上 width/sparsity 交互项,H$_\text{full}$ 在 2B 上 LOO $R^2 = 0.90$、9B 上 $0.93$——几何信号也存在于 raw checkpoint 损失而非仅 Stage 1 拟合参数。
多尺度曲率为何是冠军¶
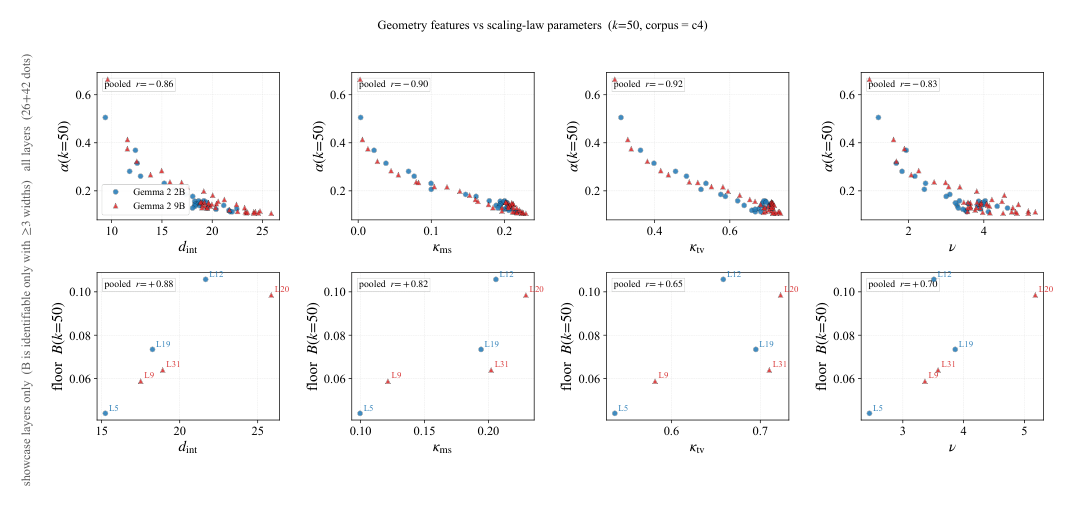
图 10 给出最直观的视觉证据:上行 $\alpha(k=50)$ 与 $\kappa_{\text{ms}}$ 散点是 4 个几何特征里最干净的,两个模型的层叠加在同一条单调下降趋势上。下行 $B_\ell$ vs 几何特征显示 $d_{\text{int}}$ 与 $\kappa_{\text{ms}}$ 都与地板排序一致。
作者的几何直觉(§5 的 mechanistic reading):层的 width-scaling rate 主要由 $\kappa_{\text{ms}}$ 决定,因为扁平流形上每加一个原子能覆盖的局部线性结构份额更大。$d_{\text{int}}$ 与 $\kappa_{\text{ms}}$ 因为都是"流形局部复杂度"的不同表象而高度共线,AIC/BIC 偏好把它们当成一个因子,故 H1 优于 H$_\text{full}$。
与已归档相关工作的对比¶
Step 2.5: no semantically twin papers found in archive — 本档案库没有专注于 SAE / 机理可解释性 / 激活流形几何的论文,scaling-law 类邻近论文(Practical Scaling Laws、Prescriptive Scaling Laws、InfoLaw)针对的是 LLM 预训练 损失对 $(N, D, T)$ 的依赖,与本文针对固定 LLM 的 SAE 重构 $(n, k)$ scaling 是不同 root cause、不同实验对象。
讨论与局限性¶
核心贡献的本质¶
把本文放在 SAE / LRH / 几何深度学习三条线上看,它的真正贡献是把这三个独立的经验社群在数量上接起来:
- SAE 社区:知道 reconstruction error 沿层不均、知道 dark matter;不知道为什么;
- 几何社区:把 transformer 激活流形的 $d_{\text{int}}, \kappa$ 沿层剖面测过;不知道这些数据怎么落到下游 tool 上;
- scaling 社区:把 SAE width-sparsity scaling 在单层上拟出来;不知道它怎么沿层变化。
作者展示这三件事是一件事:一组扁平 $k$-稀疏线性原子被几何上不匹配(geometrically mismatched)地用到一个曲率与维度随深度变化的流形上,结果就是 scaling 参数沿层成为几何特征的函数;而这个函数可在同家族不同尺寸的模型间共享。换言之,几何墙是一个关于 SAE 程式整体而非某个具体 SAE 的论断——同一家族换尺寸不能逃避它,因为几何本身才是约束。
值得借鉴的方法论¶
- 两阶段层级回归 是把"per-layer scaling 不普适"做成可证伪检验的最干净 setup:先在每层独立拟一个低阶 scaling 曲面,再把曲面参数作为层级目标交给跨层回归。这是任何想要 falsify "X 在 LLM 上是常数"的工作都该用的模板。
- 嵌套假设阶梯 + 层置换 null + 跨模型转移:三件事共同把"几何相关性是不是 coincidence" 这个问题封死。仅有 $R^2$ 不够——置换 null 给出 $p$ 值,转移 $R^2$ 给出 generalisation upper bound。
- 几何 / 误差数据严格不相交:在做"几何预测重构误差"这类回归时,几何和误差用不同的 token 子集来估,是消除 token-level artefacts 的关键。
局限¶
作者自己列了几条诚实的局限:
- 训练 schedule 是 width-dependent 而非 convergence-scaled:Gemma Scope 大宽度 SAE 没跑到 convergence。所以本文报告的绝对 $\alpha$ 值是 as-trained 值,不是真正的 "asymptotic" exponent。但作者论证:跨层几何相关性的存在性不依赖这个 caveat——几何在所有 width 预算下都会决定层间相对差异。要彻底解决需要做 width-matched budget 的新 SAE training,这是 future work。
- with-floor surface 只在 6 个 showcase 层可识别:因为只有这些层有 ≥3 widths。整层的地板剖面要等更密的 width 网格。
- 只覆盖 residual stream:MLP、attention sub-layer 的 SAE 可能有自己的几何-scaling 关系,没测。
- 几何代理是欧氏 $k$-NN 估计,不是直接计算拉回度量:直接计算 $\mathbf{G}_\ell(h) = J^\top \Sigma J$ 需要在每个激活上计 Jacobian,在 LLM 规模上代价高。作者证了三个 metric-invariance 性质论证欧氏代理保序,但没有直接验证——附录 I 把直接拉回计算列为 future work。
- Gemma 2 家族内的跨模型转移:只验证了 2B↔9B,没有跨架构(Llama / Mistral / Qwen)跨。
对 LRH 的隐含批评¶
最值得品的还是这篇文章对 LRH 的温和但深刻的批评。LRH 当前是这么用的:把每个激活拆成稀疏的"环境欧氏"线性方向之和,方向被叫做"特征"。但 pullback 框架说激活空间的自然距离不是欧氏的而是 Fisher–Rao 的——它由模型的预测结构决定。LRH 当前形式的"meaningful linear direction" 是 metric-dependent 的对象:在欧氏度量下两个原子正交,在拉回度量下可能近共线(反之亦然)。
这给两个具体建议:
- 几何接地的特征解耦:把字典原子当作流形上的局部 frame field(atlas chart)而非全局欧氏方向;
- 拉回距离训练目标:用 $\mathbb{E}[d_{\text{FR}}(F_\ell(h), F_\ell(\hat h))^2]$ 替换 $\|h - \hat h\|^2$,让 SAE 训练目标和度量本身一致。
这是把"线性表示"从一个经验工作假设升级为可证伪的几何陈述——后者更小更脆弱但更有信息量。
与档案库中 scaling 类论文的核心差异¶
虽然本文与 Practical Scaling Laws / Prescriptive Scaling Laws 共享 "scaling law" 名词,但它们的研究对象彻底不同:
- 前两者预测LLM 预训练损失对 $(N, \text{params}, D, \text{tokens})$ 的依赖,用于compute allocation 的 prescriptive 决策;
- 本文预测固定 LLM 上 SAE 重构误差对 $(n, k)$ 的依赖怎么随层变化,用于 interpretability tool 的 trust calibration。
它们一前一后处于 LLM 生命周期不同阶段(pretraining vs post-hoc tool),评估指标(loss vs NMSE)、scaling 维度(参数/数据 vs 字典宽度/稀疏度)、操控对象(训练配置 vs 字典结构)都不同。在档案库里登记本文时归类为 llm + 几何/interpretability 主题,不与传统 scaling-laws 论文合并。
工业 / 工程角度¶
这篇文章没有任何工业 A/B 实验、没有部署。它的工程价值在于:给"使用 SAE 解释 LLM 的从业者"一份层级风险地图——哪些层(高 $\kappa_{\text{ms}}$ 高 $d_{\text{int}}$)的 SAE 解释可能从根本上不可靠,这些层上的下游操作(feature steering、circuit discovery、attribution)需要额外校准。