GrowthGR: 面向可持续增长的多价值感知生成式检索框架(Taobao Search)¶
研究动机与背景¶
大规模电商平台(如淘宝)的搜索系统既是交易枢纽,也是承载长尾新品供给的动态生态。新品(new items)是平台增长的"血液"——它们体现最新消费趋势、孵化品牌创新、防止商品池僵化。然而在工业搜索中分发新品却非常困难:主流检索系统天然为历史 engagement(CTR / CVR)优化,导致Matthew effect("富者愈富")——头部 high-CVR 商品反复获得曝光,新品由于缺少历史交互而被概率性遗忘,长尾良品被困在"cold-start dilemma"里。
作者用 Figure 1 给出直观图景:
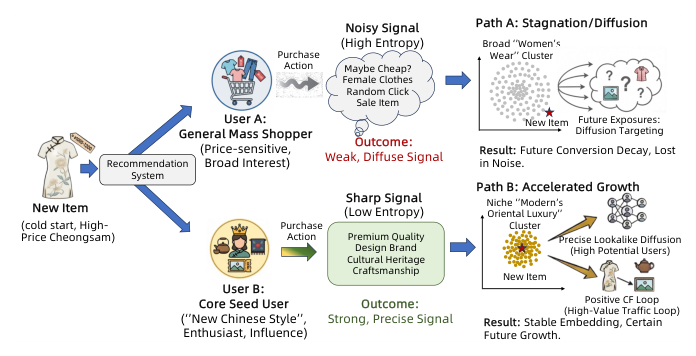
- 用户 A(General Mass Shopper):行为宽泛、价格敏感,对新品的购买信号 high entropy、broad signal,对新品来说是 noisy signal,扩散到"Maybe Cheap / Female Cotton / Random One / Sale Item"等宽集合,结果是 stagnation 与 diffusion,曝光稀释。
- 用户 B(Core Seed User):人群标签清晰("New Chinese Style"、风格忠诚、有影响力),其购买行为对新品是 low entropy、sharp signal,能够让系统快速"解码"新品的市场定位("Premium Quality / Design Brand / Limited Edition / Craftsmanship"),打通"positive lookalike diffusion → high-potential users → stable embedding"的正反馈。
作者由此抽象出两条根本限制:(1) 现有系统缺乏对新品长期价值的量化测量——多用"当前曝光份额 / 即时 CTR/CVR"这类简单 proxy,忽视早期一次互动对未来生命周期的"涟漪"效应;(2) 缺乏在即时转化效率与长期生态健康之间的平衡机制——策略过度偏向 high-conversion 头部品,牺牲了新品成长。
为系统性解决冷启问题,作者提出新品分发需要两项基础能力:
- 量化单次交互的边际增长价值:不能只看"是否转化",而要量化某一次 click/conversion 对未来一段时间内 new item transaction 的增量贡献,从而支持细粒度的流量分配决策。
- 精准的初始分发:新品的初始轨迹会显著塑造系统-用户对它的"感知"——把它精准地投到 high-affinity user 而非稀释到 mass user,是积累有效后验反馈、跑通正反馈循环的关键。
围绕这两点,作者提出 GrowthGR ——业界首个为新品增长设计的多价值感知生成式检索框架。它由两个协同模块构成:
- ItemLTV(Item Long-term Transaction Value):用 counterfactual causal inference 量化"一次特定 click"在未来 30 天后续 7 天窗口内带来的 transaction 增量(uplift);
- MultiGR(Multi-Value-Aware Generative Retrieval):在 TIGER-style 层次化 SID 自回归 backbone 上引入 MoPO (Multi-Value-aware Policy Optimization)——一种把 search funnel cascade 信号(曝光、点击、购买)与 ItemLTV 长期信号一起 list-wise 对齐的 GRPO 变体,并通过 Clipped Importance Weighting (CIW) 抵消 popularity bias。
GrowthGR 在淘宝搜索生产系统部署超过 2 个月,user-side A/B 取得+5.39% 新品 GMV、+1.54% PVR(page view ratio)、+0.31% 整体搜索 GMV(统计显著、非 zero-sum redistribution),item-side A/B 在 T+30 天后续 7 天 GMV 上取得 +20.0% 增长。论文的核心立论是:generative retrieval 不应只承担"召回",更应该作为新品长期价值的对齐器和发现器。
核心方法 / 模型架构¶
GrowthGR 的整体框架如 Figure 2 所示,分为左右两路:左侧 ItemLTV 提供 item 级长期价值预测,右侧 MultiGR 在搜索 cascade 中做生成式检索并通过 MoPO 训练对齐多价值目标。
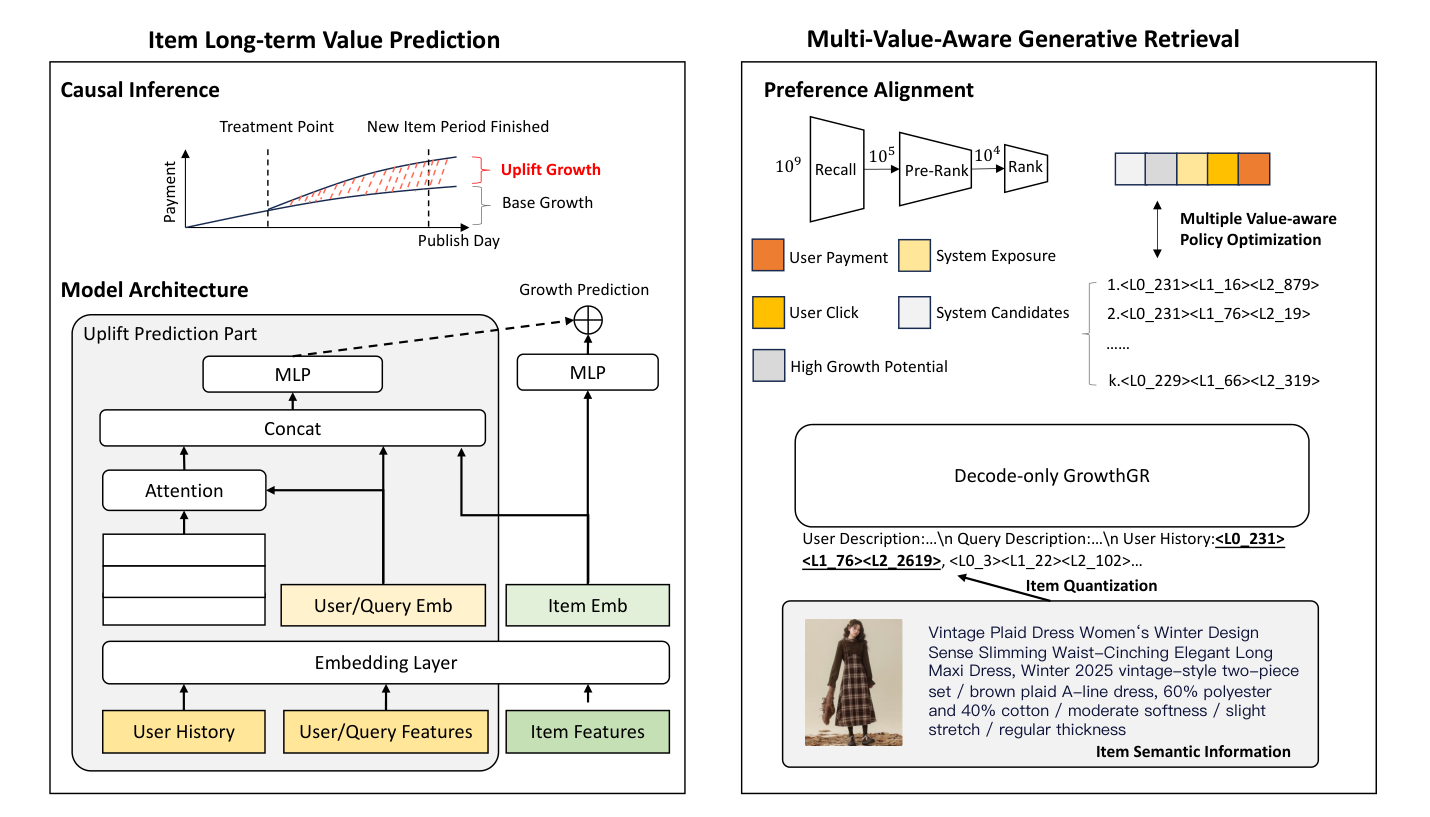
3.1 Item Long-term Transaction Value Prediction (ItemLTV)¶
3.1.1 问题定义¶
ItemLTV 把"一次用户交互对新品未来 transaction 的影响"形式化为反事实因果推断(counterfactual causal inference)问题。Treatment Point 定义为某 user 在新品发布后的一次 click($W_i = 1$)。covariate 包括 item-specific attribute $x_i^I$ 和 user/query context $x_i^C$,即 $X_i = \{x_i^I, x_i^C\}$。论文针对新品发布后初始 30 天 "New Item Period" 内的某一次 click 事件,定义其 potential outcomes:
- $Y_i(1)$:发生该 click 后,初始 30 天结束之后 紧随的 7 天窗口内该新品的日均订单数;
- $Y_i(0)$:同一 7 天窗口 内若无该次 click 时的反事实日均订单数。
Uplift Growth 与 Base Growth 分别定义为 $Y_i(1) - Y_i(0)$ 和 $Y_i(0)$。注意:treatment 是"用户 click 经系统曝光",作者选这个变量出于三点考虑:
- 信号可靠性:单纯系统曝光对 item 的内在轨迹影响有限,又会在工业大规模数据下引入很高方差;click 是用户主动行为,更能反映真实兴趣;
- 缓解 negative feedback:工业搜索引擎中"曝光但没点击"会被解释为 negative feedback,反而抑制该 item 在未来 pre-rank/rank 阶段的得分;
- 正反馈强化:click 后伴随收藏/购买等下游行为,能提供 high-fidelity 标签反馈给模型,自然增加未来曝光机会。
由于 transaction value 呈重尾分布,作者在 log space 中做估计,目标是 Conditional Average Treatment Effect (CATE):
$$\tau(X_i) = \mathbb{E}\bigl[\log(Y_i(1) + 1) - \log(Y_i(0) + 1) \mid X_i\bigr] \tag{1}$$
3.1.2 双塔架构¶
ItemLTV 用两塔分别拟合 base growth 和 uplift growth。
Item Tower (Base Growth):item-only 特征过 embedding 层得 item embedding,再用 MLP 输出 base growth 分数:
$$G_{\text{base}}(X_i) = f_1(x_i^I) \tag{2}$$
Uplift Prediction Tower (Uplift Growth):把 User History、User/Query Features 与 Item Embedding 一起送入 attention,再 concat + MLP 输出 incremental value $\tau(X_i)$:
$$G_{\text{uplift}}(X_i) = f_2\bigl(g(x_i^C), x_i^I\bigr) \tag{3}$$
训练时观测到的 outcome 由 treatment $W_i$ 决定,因此预测被构造为:
$$\hat{y}_i = G_{\text{base}}(X_i) + W_i \cdot G_{\text{uplift}}(X_i) \tag{4}$$
监督目标是 log 空间下的 MSE:
$$\mathcal{L}_{\text{ItemLTV}} = \sum_i \|\hat{y}_i - \log(Y_i + 1)\|_2^2 \tag{5}$$
其中 $Y_i$ 是地面真值订单数。通过让 base + uplift 联合拟合实际购买数,模型自然把"item 本征 base 价值"与"用户交互带来的额外价值"解耦——base tower 学到 item-level prior,uplift tower 学到 user-conditioned incremental contribution。
3.2 Multi-Value-Aware Generative Retrieval (MultiGR)¶
MultiGR 的目标是从十亿级候选池中检索 high-potential 新品,把范式从传统 ID-matching 切到 semantic ID generation,并在自回归生成时显式平衡 immediate conversion value 与 long-term growth value。
3.2.1 Item Quantization¶
作者沿用 TIGER 的层次化 SID 分词:先用 pre-trained e-commerce foundation model 提取多模态 item 表征(含 title / properties / images),再对该表征做 RQ-VAE 残差量化得到 3-layer SID 路径,例如 $\langle L_0\_231 \rangle \langle L_1\_16 \rangle \langle L_2\_879 \rangle$。共享前缀编码了 item 之间的语义层级关系,使得模型对未见过 / 冷启 item 也能依靠同前缀邻居泛化。
3.2.2 Generative Architecture¶
MultiGR 的 backbone 是 decoder-only Transformer,把检索建模为 seq2seq:
- Input Composition:把自然语言 User Description、Query Description 与用户历史 SID 序列拼接成单条上下文;
- Autoregressive Generation:自回归生成 next item 的 SID,从而隐式建模用户兴趣和 transition pattern;
- Constrained Decoding:用 trie 约束生成 token 必须沿预定义的 SID 层级合法路径,过滤幻觉。
3.2.3 Multi-Objective Training Strategy¶
这是全文最核心的训练设计:分为 Supervised Pre-training 和 Preference Alignment 两个阶段。
Supervised Pre-training (NTP 阶段):以历史 transaction 日志做 next-token prediction,让模型学到协同过滤先验、对齐 SID 与自然语言描述:
$$\mathcal{L}_{\text{NTP}} = -\frac{1}{\sum_{k=1}^{N} |o_k|} \sum_{i=1}^{N} \sum_{t=1}^{|o_i|} \log \mathcal{P}(o_{i,t} \mid o_{i,\lt t}, x) \tag{6}$$
其中 $x$ 是上下文(用户行为),$\mathcal{P}$ 是生成对应购买 item SID 的概率。
Preference Alignment (MoPO 阶段):作者强调 NTP + MLE 的两大局限:(a) 在 cascade(曝光→点击→购买)的因果分桶下无法区分细粒度的相对 preference,(b) 推理是 beam search 输出 top-K,因此必须对集体价值(list-wise)做优化而不是单点 likelihood。为此提出 MoPO——在 GRPO 框架上扩展 multi-value reward engine。
核心改动 (1):Cascaded Value Labels——把 search funnel 的层级状态全部纳入 reward:user purchase > user click > system exposure > system rank candidates。
核心改动 (2):Long-term Labels——利用 ItemLTV 输出,把"被点击 item 中 predicted uplift 高于全局均值"的 item 标记为 high growth potential。这一项让 MoPO 直接对齐"长期生态价值"而非仅短期点击概率。
不同 interaction label 被赋予不同 weight,total reward 是 calibrated weighted sum:
$$r_i = \mathrm{Clip}\bigl(-\log \pi_{\theta_{\text{old}}}(o_i \mid x),\ 1,\ M\bigr) \sum_k w_k s_k \tag{7}$$
其中 $s_k \in \{0, 1\}$ 是 k-th 目标的 indicator(如 purchase / click / exposure / long-term high-uplift),$w_k$ 是其权重,$\pi_{\theta_{\text{old}}}(o_i \mid x)$ 是 behavior policy 下生成 SID $o_i$ 的概率。$M \gt 1$ 是 clip 上界,超参。
核心改动 (3):Clipped Importance Weighting (CIW)——前缀 $-\log \pi_{\theta_{\text{old}}}$ 起到 importance weight 的作用:给罕见、长尾 SID(low likelihood)放大 reward,给头部高曝光 SID 压缩 reward。直接的动机是抵消 head sample 主导导致的 popularity bias。$w_k$ 按训练 batch 中各目标 label 分布做校准,使 reward 分布与 ground-truth value 分布对齐。clipping 进一步压制极端 outlier 的影响,避免 gradient explosion,又给头部 ID 保留一个 baseline reward 防止 vanishing。综合效果是:模型被推离 head-dominated 分布,转而探索更多样、更高潜力的长尾 SID 路径。
Importance sampling ratio 与 GRPO 完全一致:
$$\rho_{i,t}(\theta) = \frac{\pi_\theta(o_{i,t} \mid x, o_{i,\lt t})}{\pi_{\theta_{\text{old}}}(o_{i,t} \mid x, o_{i,\lt t})}$$
denote importance sampling ratio。最终 MoPO loss 为:
$$\mathcal{L}_{\text{MoPO}}(\theta) = -\frac{1}{G} \sum_{i=1}^{G} \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \bigl[\hat{\mathcal{J}}_{i,t}^{\text{CLIP}}(\theta) - \beta D_{\text{KL}}(\pi_\theta \| \pi_{\text{ref}})\bigr] \tag{8}$$
其中 clipped surrogate objective 为:
$$\hat{\mathcal{J}}_{i,t}^{\text{CLIP}}(\theta) = \min\bigl[\rho_{i,t}(\theta) \hat{A}_{i,l},\ \mathrm{clip}(\rho_{i,t}(\theta),\ 1-\epsilon,\ 1+\epsilon) \hat{A}_{i,l}\bigr] \tag{9}$$
而 normalized advantage $\hat{A}_{i,t} = \frac{r_i - \text{mean}(\mathbf{r})}{\text{std}(\mathbf{r})}$,即 group-relative advantage。$\beta$ 控制 reference policy KL 约束的强度。
3.2.4 Inference¶
推理时 MultiGR 用 beam search 取 top-k 最高 likelihood 的 SID 序列,并使用 constrained decoding 保证生成的 SID path 落在预定义合法集合内。当一个 SID identifier 对应多个 item(collision)时,会调用一个内部 re-ranking 模型在该桶内排序(细节见 Appendix B 的 Decoding Strategy:constrained decoding + dynamic-width beam search)。
部署架构¶
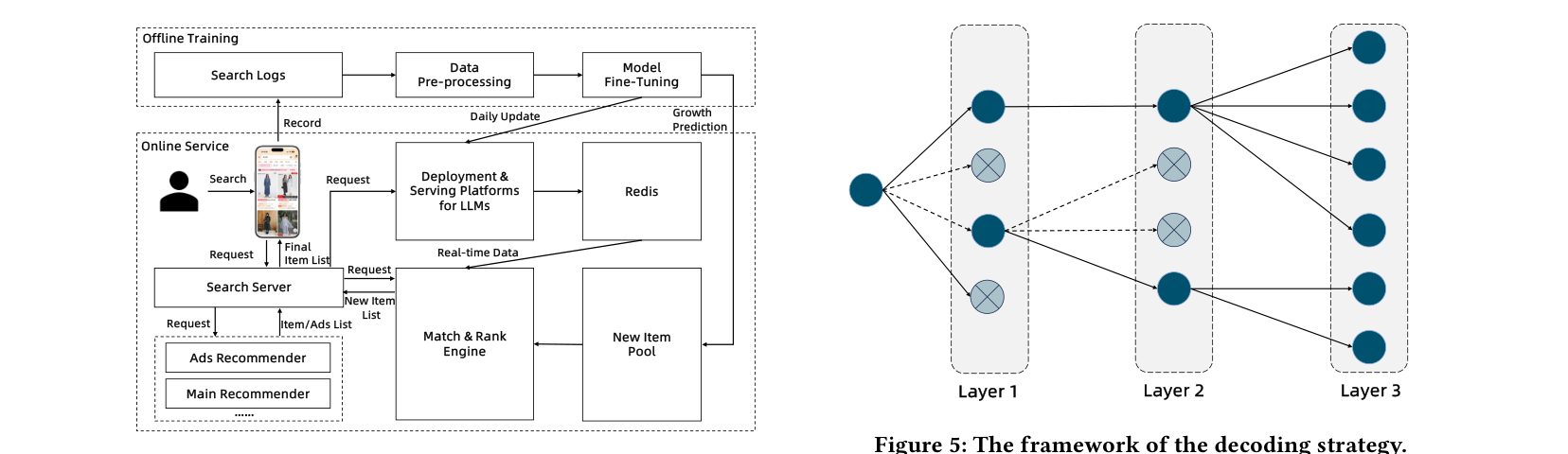
部署如 Figure 4,分两大块:
- Offline Training:从 MaxCompute 抽取 search log → data pre-processing → 双轨训练:ItemLTV 做日级 retrospective labeling(最近 1 天 transaction label 与前 1 月 features 做配对训练 uplift 模型);MultiGR 做 daily fine-tuning(融合 ItemLTV inference 与 cascade behavior labels)。MultiGR 用 0.5B 参数配置部署到阿里巴巴专用 LLM serving platform。
- Online Service Engine:search 请求并发触发多个 recommender stream,含 ads / mainstream / new item stream。new item stream 由 MultiGR 异步 inference 后写入 Redis 缓存(首要 trigger 机制 + 0.5B 模型效率使得 cache hit rate 99%);请求到达 Match & Rank 引擎时从 Redis 拉取,再用轻量 ranker 把 1000 候选过滤为 top-20 返回给 search server 与其他通路 blending。
New Item Pool Selection:每天从超过 200M 涌入的新品中,按 ItemLTV uplift score 筛选出约 2M high-potential 新品池供 MultiGR 检索。
实验¶
4.1 Experimental Setup¶
数据集(Table 1)¶
| Dataset | Interactions | Users | Items | New Items |
|---|---|---|---|---|
| Uplift | 2.4B | 0.1B | 0.16B | 3M |
| Full-chain | 5.0B | 0.17B | 0.11B | 2M |
| Online Daily | 1.6B | 0.15B | 0.3B | 3M |
- Uplift Prediction Dataset:click-oriented,覆盖 0.1B users / 0.16B items(含 3M 新品),用于训练 ItemLTV;
- Full-chain Conversion Dataset:5.0 billion user-item 交互覆盖 0.17B users / 0.11B items(含 2M 新品),用于 MultiGR 的 retrieval + collaborative filtering 训练;
- Online Daily Traffic:约 1.6B 交互、0.15B 活跃用户、0.3B 唯一 items(3M 新品)。
Evaluation Metrics¶
- Offline:
- In-scenario / Platform-wide / Long-term:三类 ground-truth label——
search(搜索场景内转化)、all-net(站内 cross-scenario 转化,反映 ranking 范化能力)、long-term(与 ItemLTV uplift 定义一致,正相关未来新品转化); - Recall@K:$\text{Recall@k} = \frac{1}{N}\sum_{i=1}^N \mathbb{I}(\text{rank}_i \le k) \tag{10}$;
-
NDCG:列表排序质量。
-
Online:GMV(核心)、PVR(page view ratio,分配给新品的曝光比例,反映流量结构与 Matthew effect 缓解)、TI@30(new item transaction at T+30,新品初始 30 天后续 7 天 GMV,量化"渡过 cold-start → 进入稳定增长"的能力)。
Implementation¶
DR (Dense Retrieval) 40B sparse embedding 参数 + 10M dense 网络参数,即当前 Taobao 生产环境 SOTA dense baseline。所有 GR 模型 total size 0.5B(含 0.15B embedding)。
4.2 Main Results (RQ1)¶
4.2.1 ItemLTV Effectiveness (Table 2)¶
| Metric | MSE ↓ | NDCG ↑ |
|---|---|---|
| base | 1.348 | 0.842 |
| +uplift part | 1.329 | 0.853 |
"+uplift part" 在 base item-tower 之上加上 uplift prediction part 做联合估计——MSE 与 NDCG 都改善,证实 uplift module 有效捕捉了用户交互对未来订单的影响。
4.2.2 MultiGR Effectiveness (Table 3)¶
| Method | search Recall@10 | search Recall@100 | search Recall@1000 | search NDCG | all-net R@10 | all-net R@100 | all-net R@1000 | all-net NDCG | long-term R@10 | long-term R@100 | long-term R@1000 | long-term NDCG |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DR | 0.4115 | 0.6775 | 0.8820 | 0.3628 | 0.2465 | 0.4260 | 0.6194 | 0.2422 | 0.3990 | 0.6704 | 0.8772 | 0.4119 |
| TIGER | 0.2950 | 0.5909 | 0.8215 | 0.2842 | 0.2159 | 0.4430 | 0.6969 | 0.2307 | 0.3810 | 0.7209 | 0.8883 | 0.3375 |
| GrowthGR | 0.3419 | 0.6306 | 0.8438 | 0.3160 | 0.2568 | 0.4981 | 0.7147 | 0.2555 | 0.4440 | 0.7523 | 0.8991 | 0.3820 |
| GrowthGR-twoStage | 0.513 | 0.8062 | 0.8820 | 0.4102 | 0.3187 | 0.5702 | 0.7578 | 0.2970 | 0.6221 | 0.8558 | 0.9261 | 0.4801 |
关键观察:
- GrowthGR 在 all-net 和 long-term 两个维度上均显著超过 TIGER:long-term R@1000 0.8991 > DR 0.8772,说明 multi-value preference alignment 真正改善了"识别高潜新品"的能力;
- DR 在 search label 上更强:合理——production DR 长期为当前生产分布优化,所以"模仿当前系统输出"的能力最强。但在跨场景的 all-net 与未来导向的 long-term 上 DR 反而被 GrowthGR 反超;
- GrowthGR-twoStage(GrowthGR 做初召回 → DR 做 re-rank):所有指标 SOTA。意味着 GrowthGR 提供了一个"对 immediate relevance 与 long-term potential 双高"的候选池,让下游 ranker 在更优的候选空间内做精排;
- long-term R@1000 0.6221 vs DR 0.4440 / TIGER 0.3810:对 uplift-based label 的拟合保真度极高,直接证明了 "Preference Alignment 把训练目标真正映射到了 retrieval behavior"。
4.3 Ablation Study (RQ2) (Table 4)¶
| Model | all-net R@10 | all-net R@1000 | long-term R@10 | long-term R@1000 |
|---|---|---|---|---|
| GrowthGR (Ours) | — | — | — | — |
| w/o ItemLTV | -0.0006 | +0.0004 | -0.0532 | -0.0165 |
| w/o CIW | -0.0010 | -0.0038 | -0.0004 | -0.0060 |
| w/o MoPO | -0.0220 | -0.0368 | -0.0539 | -0.0325 |
4.3.1 w/o ItemLTV¶
移除 ItemLTV 分数后,long-term R@10 掉 5.32 pt、R@1000 掉 1.65 pt,验证 ItemLTV 在捕捉长期价值方面的关键作用;而 all-net Recall@1000 几乎不动(-0.04 pt),说明 ItemLTV 专门服务于长期目标,不会干扰即时召回。
4.3.2 w/o CIW¶
去掉 clipped importance weighting 后所有指标轻微下降——all-net R@10 -0.38 pt、long-term R@1000 -0.60 pt。这两个数据说明 CIW 通过校准 head 样本的 reward,能让模型探索 high-value 但 sparse 的长尾模式,对长期目标尤其敏感。
4.3.3 w/o MoPO¶
把 MoPO 换成 vanilla GRPO(targeting immediate conversion)后退化最严重:all-net R@10 -2.20 pt、R@1000 -3.68 pt;long-term R@10 -5.39 pt、R@1000 -3.25 pt。意味着 MoPO 的多目标设计本身是 GrowthGR 取得最优 retrieval 精度的关键。
附录 C.2 也对比 rollout 策略(Table 5):Beam Search 与 Top-p Sampling 的取舍——
| Strategy | all-net R@10 | all-net R@1000 | long-term R@10 | long-term R@1000 |
|---|---|---|---|---|
| Top-p Sampling | 0.2568 | 0.7147 | 0.4440 | 0.8991 |
| Beam Search | 0.2722 | 0.7138 | 0.4459 | 0.9064 |
Beam Search 在 top-tier metric(R@10)上更强(更精准),Top-p Sampling 在 broader retrieval (R@1000) 上微弱占优(更多样)。ItemLTV 提供的高潜先验让 Beam Search 也能很好地捕捉 long-term 高价值候选。
4.4 Scaling Analysis (RQ3)¶
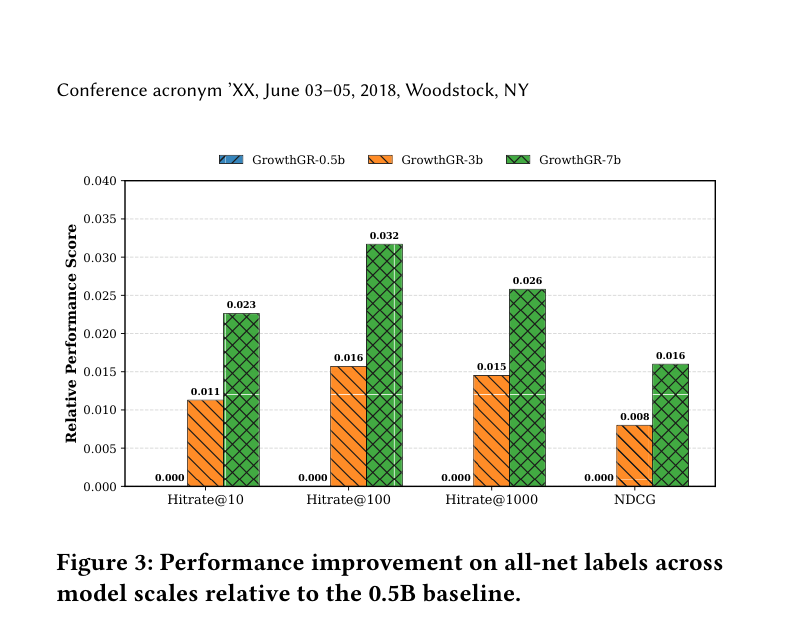
跨 0.5B / 3B / 7B 三档参数,所有 metric(Hitrate@10/100/1000、NDCC)一致单调改善。其中 0.5B → 7B 在 Recall@1000 上提升超 +2.0 pt,说明模型容量未到 plateau。结论:GrowthGR 遵循 scaling law,工业 GR 在可见未来仍有显著扩参收益。
4.5 Online A/B Testing (RQ4)¶
在淘宝主搜索系统上线 2 个月,并行做两路 A/B:
4.5.1 User-side A/B¶
User-level partitioning(按 user ID hash 分桶):
- New item GMV +5.39%;
- PVR +1.54%;
- Overall Search GMV +0.31%(统计显著、非 zero-sum)——证明 GrowthGR 是"真正创造增量"而非"以头部品的损失换新品的增量"。这点是工业策略最看重的:很多冷启策略能拉新品指标但损失整体 GMV,GrowthGR 把"扩大候选池 + 多价值对齐"做到了真正的 incremental value generation。
4.5.2 Item-side A/B¶
Item-level partitioning(按 item ID hash 分桶 + coupled bucket 防止 cross-contamination):在 T+30 后续 7 天 GMV 上 GrowthGR 新品 TI@30 +20.0%——意味着策略并不是"上线初期一次性的流量注射",而是真的把高潜新品孵化成了长期高表现的稳定品。
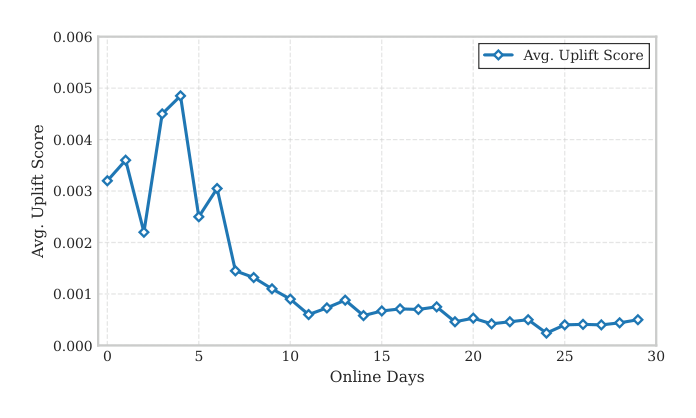
C.1 Online Days Analysis (Figure 6)¶
uplift 分数在 listing 的最初几天最大(~0.0045),约 5 天后开始陡降,30 天后趋于 ~0.001 的稳定低位。这与电商直觉一致——新品对早期 user interaction 最敏感,越早干预,长期 transaction trajectory 改写的杠杆越大。
C.3 Category-wise Analysis (Table 6)¶
跨 16 个一级品类,PV uplift 全部为正(+0.50% ~ +2.90%),GMV 大多正(最大 +22.18% 在 3C & Digital),少量负(Food & Fresh -0.67%、Pets -2.62%、Toys & Hobbies -5.48%、Automobiles -0.81%)。作者分析:在高品牌忠诚 / 头部依赖品类(Food & Fresh、Toys)引入新品候选会暂时稀释 immediate conversion;这种 "discovery cost" 是防止品类长期僵化、维持 long-term seller diversity 的必要代价。逾 70% 品类 GMV 正增长进一步证实 incremental value generation 假设:substantial GMV 增长来源于"以前因数据稀疏而 underexposed 的 high-quality 候选"。
与已归档相关工作的对比¶
UniVA UniVA: Unified Value Alignment for Generative Recommendation in Industrial Advertising (Tencent WeChat Channels Ads, 2026-05-07)¶
关系:独立并发(GrowthGR 未引用 UniVA,两者在不同业务场景下殊途同归地把"多价值对齐"贯穿到 SID-based GR 全链路)· 已加载对方精读
- 共同关注的问题:两者都瞄准"工业 GR 不能只学 likelihood——必须把下游业务价值显式贯通到训练与服务全链路"。UniVA 关注的 value 是"广告 eCPM/GMV"(即时商业价值),GrowthGR 关注的是"item long-term transaction uplift"(长期生态价值);但两者都把问题诊断为MLE-trained GR 与下游 value 之间的对齐鸿沟,并都坚信单纯在 reward 上加权或事后 ranking 不够。
- 相近的技术骨架:两者都基于 TIGER-style 层次化 SID + decoder-only Transformer;都把训练拆成 SL 预训练 + value-aware RL 对齐;都用 group/batch level normalized advantage;都把 value-aware logic 同时贯彻到训练与线上 serving(GrowthGR 的 trie + constrained decoding 等价于 UniVA 的 personalized trie + value-guided beam)。
- 本文(GrowthGR)的差异与推进:GrowthGR 的关键差异在长期价值的来源——通过 counterfactual causal inference 训一个独立的 ItemLTV 模型估计 "click → 未来 30+7 天订单"的 CATE,再把 uplift 高于全局均值的 click item 当作 long-term high-potential label 输入 MoPO 的 reward。这个 causal uplift 路径是 UniVA 没有的(UniVA 的 value 来自实时 eCPM 模型)。GrowthGR 还引入 Clipped Importance Weighting (CIW) 显式抵消 head SID 主导带来的 popularity bias,是相对 UniVA 的 PPO+MCTS-PPO 更轻量的 RL 设计。
- UniVA 的差异:UniVA 在 SID 构造层显式把商业属性离散化进最后一层 token(Commercial SID),通过 dual-head(gen + value)+ fused logits 在 token-level 实时融合 value,并用 PPO+MCTS-PPO 做高价值低概率路径的结构化探索;其 value reward 来自 simulation-based 离线模拟器。
- 可比的方法 / 实验差异:UniVA 报告 offline HR@100 +37.04%、online GMV +1.50%;GrowthGR 报告 new item GMV +5.39%、overall GMV +0.31%、TI@30 +20.0%。两者无法直接对比指标,但共同验证 "value-aware GR 是工业可落地方向"。从设计哲学上:UniVA 走"重 SID + 重 RL 探索"路线,GrowthGR 走"重 causal uplift label + 轻 RL 算法(GRPO+CIW)"路线,是同问题域下的互补设计。
GenRec GenRec: A Preference-Oriented Generative Framework for Large-Scale Recommendation (JD.com, 2026-04-16)¶
关系:独立并发(GrowthGR 未引用 GenRec,两者都用 GRPO 变体做 industrial GR 的偏好对齐)· 已加载对方精读
- 共同关注的问题:都瞄准"SFT 后的 GR 模型只是模仿历史行为分布,需要 RL 进一步对齐到真实用户偏好",且都把 reward hacking、popularity bias 作为关键工程难题。
- 相近的技术骨架:两者都基于 RQ-K-means/RQ-VAE 多码 SID + decoder-only backbone;都在 SFT 之后用 GRPO 变体 做偏好对齐;都在 reward 中混合多种信号(GenRec 是点击 + 订单的 hybrid reward + SIM 软打分;GrowthGR 是 cascade exposure/click/purchase + ItemLTV 长期信号);都使用 advantage normalization。
- 本文(GrowthGR)的差异与推进:GrowthGR 把"长期 uplift"作为一等公民引入 reward(GenRec 完全没有长期 / 因果维度),并通过 CIW 用 $-\log \pi_{\theta_\text{old}}$ 给罕见 SID 加权——这是 GenRec 没有的 popularity-bias 对消机制(GenRec 用 SIM gate + 真实 $\mathcal{D}^+$ 锚定来对抗 reward hacking,但不直接处理 head bias)。GrowthGR 也是首篇明确报告"item-side A/B + TI@30 后续增长"的工业 GR 论文。
- GenRec 的差异:GenRec 提出 Page-Wise NTP (PW-NTP) 处理 cardinality mismatch(一前缀对一页 K 个正样本),把 SFT 监督从 point-wise 升到 page-wise;引入 Token Merger 在 prefilling 侧把多码 SID 压缩 ~2x;用 NLL 正则锚定到真实用户轨迹防 reward hacking。这些都是 GrowthGR 没有的、专门服务于 JD 首页 feed 分页场景的设计。
- 可比的方法 / 实验差异:GenRec 报告 JD 首页 click +9.5%、transaction +8.7%(一个月 A/B);GrowthGR 报告 Taobao Search new item GMV +5.39%、overall +0.31%、TI@30 +20.0%。两者最大的范式差异是 GenRec 关注全量推荐质量,GrowthGR 关注新品长期增长——这决定了 reward 设计与 A/B 协议的区别(GenRec 用 user-side A/B 看总量指标,GrowthGR 额外做 item-side A/B 验证 long-term lifecycle 影响)。
OneSearch-V2 OneSearch-V2: 潜在推理增强的自蒸馏生成式搜索框架 (Kuaishou Mall Search, 2026-03-25)¶
关系:独立并发(GrowthGR 未引用 OneSearch-V2,两者在不同电商平台上独立提出 GRPO 变体做生成式搜索的偏好对齐)· 已加载对方精读
- 共同关注的问题:都在工业电商搜索场景上做 SID-based 生成式检索(query → SID 生成),都识别到 SFT/MLE 不能直接对齐用户满意度,必须用 RL 把策略往真实偏好对齐;都直面 "vanilla GRPO 在 SID 的层次因果结构下信用分配粗糙" 的问题。
- 相近的技术骨架:两者都用 cascade 行为信号(exposure / click / order)构造 hybrid reward;都在 GRPO 框架上做扩展并通过 advantage normalization + 引入额外结构约束来稳定训练;都在生产环境做线上 A/B 验证。
- 本文(GrowthGR)的差异与推进:GrowthGR 在 reward engine 上引入长期价值维度(ItemLTV uplift),并用 CIW + label-distribution-calibrated $w_k$ 显式校正 popularity bias;其 reward 计算是 sequence-level 的 weighted sum,结合 importance weight clipping。在线 A/B 协议上引入 item-side partition + TI@30 来量化"长期成长",这是 OneSearch-V2 没有的视角。
- OneSearch-V2 的差异:OneSearch-V2 强调 token-position-level 信用分配——提出 TPMA(Token-Position Marginal Advantage)按 SID 层级给出 per-position advantage,并用 prefix gate 保证 "前缀错就关后续梯度",形成隐式的层次化课程;同时引入 keyword-based CoT + self-distillation 解决复杂 query 理解。这两个方向 GrowthGR 没有触及。OneSearch-V2 的视角是"在 SID token 维度做更精细的 RL 信用分配",GrowthGR 的视角是"把长期价值作为额外 reward 维度",两个方向高度互补,原则上可以叠加:TPMA 做层级信用 + GrowthGR 的 ItemLTV 做长期 reward。
- 可比的方法 / 实验差异:OneSearch-V2 在 Kuaishou Mall 上线报告 Item CTR +3.98%、Order +2.11%;GrowthGR 在 Taobao Search 上线报告 new item GMV +5.39%、overall GMV +0.31%。两者的 reward 设计与 A/B 评估指标显示了两条不同的电商搜索 GR 演进路径——OneSearch-V2 强调"理解能力 + 信用分配粒度",GrowthGR 强调"长期价值 + 长尾发现"。
核心贡献总结¶
- 形式化新品 sustainable growth 问题:首次系统地将"工业搜索新品 cold-start"拆解为 (a) 长期价值量化 与 (b) 即时-长期平衡两个子问题,给出了一个明确的问题域。
- ItemLTV: counterfactual causal inference for new-item uplift:通过 30+7 天窗口 CATE 估计、双塔架构(base + uplift)、log-space MSE,把"一次 click 对未来订单的边际贡献"作为可学习信号,是首个直接预测 item-level long-term uplift 的工业 GR 组件。
- MultiGR + MoPO: multi-value preference alignment:在 TIGER-style 层次 SID + decoder-only GR 之上,引入 cascade signals + long-term uplift label 的 multi-value reward engine;通过 Clipped Importance Weighting (CIW) 显式对消 popularity bias,让 GRPO 可以稳定地探索 high-value 长尾候选。
- Item-side A/B + TI@30 评估范式:与 user-side A/B 互补地引入 item-level partitioning 与 30 天后续转化指标,量化"新品 → 稳定品"的生命周期演进,给工业 GR 长期影响评估提供了一个新评估协议。
- 生产部署 ≥ 2 个月:在淘宝主搜索系统验证 new item GMV +5.39%、overall search GMV +0.31%(非 zero-sum)、TI@30 +20.0%、PV +0.5%~+2.9% 覆盖 16 个一级品类,证明 sustainable growth 范式在亿级 DAU 的电商搜索可落地、可观测、可演进。
讨论与局限性¶
值得借鉴的设计:
- Causal uplift 作为 reward label:业界已经普遍尝试"在 reward 中加多目标",但绝大部分 stick 在 cascade signal(click/conversion)级别。GrowthGR 把 counterfactual 估计直接挂到 RL 的 reward engine 是一次范式跃迁——把"行为分布"换成"因果干预效应",对所有需要"突破当前数据分布"的工业 GR(特别是 cold-start、recommendation diversity、long-term retention)都具有借鉴价值。
- Clipped Importance Weighting 抵消 popularity bias:用 behavior policy 的 $-\log \pi_{\theta_\text{old}}$ 作 importance weight + clipping 是一招轻巧的、不需要额外模型的 head/tail 校正机制。可作为对所有 RL-on-GR 工作的通用 add-on。
- Item-side A/B 与 TI@30 的评估范式:工业 GR 通常只做 user-side A/B 看 GMV,但 user-side A/B 在策略影响 item 长期生命周期时会结构性低估真实收益(因为每个 user 看到的曝光是混合的)。Item-side partitioning + 后续 30 天观察是更精确的"item lifecycle 评估"协议。
- 0.5B 模型 + 99% 缓存命中率:把 GR 真正塞进生产 SLA 的工程妙招——把 GR 做成异步生成 + Redis cache + 轻量 ranker 二阶段过滤,证明工业 GR 不必走"大模型实时推理"的高成本路径。
局限与争议:
- MoPO 与现有 GRPO 变体的实验消融缺失:作者只对比 vanilla GRPO,没有把 MoPO 与同期的 GRPO 变体(如 ReCast ReCast 的 boundary-focused contrastive update、OneSearch-V2 OneSearch-V2 的 TPMA-GRPO、GenRec GenRec 的 GRPO-SR)在公开 benchmark 上做横向对比。CIW 的相对增益与其他 popularity-bias 抑制方法的对比也缺失。
- ItemLTV 的 treatment 选择争议:把 "click" 作为 treatment 而非 "exposure" 是合理的工程取舍,但论文未量化 click 信号的可观察性偏差(high-affinity user 的 click 本身就是被现行系统选择的)——这可能导致 estimated uplift 系统性偏向"系统当前能 reach 的人群",错失更深度 OOD 的 high-potential audience。
- 20% TI@30 的可解释性:item-side A/B +20% 是惊人的数据,但论文没把它拆到具体机制:到底是 (a) 更精准的 user-item 匹配、(b) 更多 high-affinity user 的早期曝光、还是 (c) 更多元的初始接触面带来的口碑/搜索回流效应?缺乏细分实验。
- 新品池筛选阈值:从 200M+ 新品中筛 2M 高潜池,论文未说明阈值如何确定,也未说明那些被筛掉的新品是否被其他通路兜底——这影响整体新品生态的覆盖率与公平性评估。
- Long-term label 仅看 30+7 天:CATE 窗口固定 37 天对快消品/生命周期短的品类合适,但对高客单价、长决策周期品类(家电、汽车配件)可能过短。论文 Category-wise 分析中 Automobiles、Major Appliances 的 GMV 提升相对较低/为负,是否与窗口选择有关?
- CIW 与 head item 收益的平衡:放大长尾、压制头部对新品有利,但可能损伤 head item 用户的体验。论文未量化"对 head item 习惯用户的 search satisfaction 是否退化"。
- 公平性与多样性评估缺失:value-guided retrieval 在抑制 Matthew effect 的同时是否引入了新的偏差(例如对 high-uplift-but-high-margin 品类的偏向)?论文没有 fairness / diversity 评估,只在 Food & Fresh、Toys 等 "negative GMV" 品类含蓄提到"discovery cost is necessary investment"。
与已有工作的差异:相对 TIGER/OneRec 等 semantics-centric GR backbone,GrowthGR 在 reward 维度上额外把"长期 causal uplift"纳入;相对 GR4AD/UniVA(即时商业价值对齐),GrowthGR 走"长期生态价值对齐"路线;相对 OneSearch-V2/GenRec/ReCast(同期 GRPO 变体),GrowthGR 选择"维度扩展"而非"信用分配粒度细化"——在同问题域下是一个独立的、互补的设计哲学。
工业落地价值:GrowthGR 几乎每一个设计——ItemLTV 双塔、MoPO 多目标 reward、CIW、0.5B + Redis cache 部署、item-side A/B + TI@30——都明确以 production-grade serving 为约束。在淘宝主搜索 2 个月的部署期、亿级 DAU 流量上,仅 0.31% 的整体 GMV 提升就意味着可观的实际营收增量,更何况 +5.39% 新品 GMV 和 +20.0% TI@30 暗示着对长期生态健康的实质性贡献。