UxSID: Semantic-Aware User Interests Modeling for Ultra-Long Sequence¶
研究动机与背景¶
现代工业推荐系统普遍面临两条矛盾的诉求:一方面,超长用户行为序列建模(Ultra-Long Sequence Modeling,ULSM)能捕捉用户长时偏好演化,已被反复证明能驱动 engagement、转化率与长期留存(活跃用户单周交互可达 10,000 条);另一方面,工业系统承载海量实时流量,序列每延长一截,计算成本就显著增加,与毫秒级延迟约束产生冲突。
为在轻量在线计算下扩展序列长度,已有 ULSM 方案可被归纳为两条主流路径:
- 路径一:Item-Specific Top-K Subsequence Selection(项相关检索式压缩)——以 SIM、TWIN、TWINv2 为代表,采用 "Global Search First, Exact Search Later"(GSU + ESU)的两段式架构。GSU 用一个轻量级单元(hard categorical match、LSH/Hamming、低精度 attention、target-aware attention)在长序列上做 Top-$K$ 检索;ESU 在压缩后子序列上做精细 attention。其缺点是受预定义 key 空间的表达力与配额限制,比如搜索单元偏向 "pants" 时会丢掉与之同款搭配的腰带或鞋——关键的组合意图在表层匹配下被过滤。
- 路径二:Item-Agnostic Pre-trained User-Interest Compression(项无关压缩)——以 MIMM、HPMN、PinnerFormer、LURM、C-Former、LREA、DV365 等为代表,把超长序列离线蒸馏成一组紧凑的、用户中心的静态 memory(例如 100 个 static embeddings)。在线模型从该 memory 中读取长时兴趣信号。其问题是 memory 完全 target-agnostic:相当于一个低通滤波器,保留粗粒度全局趋势但抹平了 target 相关的高频兴趣峰,无法把"当前查询意图"从用户大量历史背景中分离出来。
作者认为,这两条路径之间存在一条未被充分探索的中间路径:保留 user sequence 与 target item 的部分相关性,同时只暴露有限信号来引导压缩方向。这条中间路径不追求 item-specific 的用户兴趣压缩,而是寻求 semantic-group 共享的用户兴趣 memory——属性语义相近的 item 共享同一份压缩后的兴趣表示。该 paradigm 的关键支点是 Semantic IDs(SIDs):来自 RQ-VAE 等深度量化的高密度语义代码,天然与用户兴趣聚类对齐,且基数远低于原始 item ID。把 SID 作为压缩与检索的语义 key,既能在 offline 阶段对每个语义类做共享压缩,又能在 online 阶段以 $O(1)$ 时延按 target item 的 SID 拉取对应的 memory。
作者把这条中间路径具体化为 UxSID(User histories × Semantic IDs),一个用 target SID 作为语义探针、生成 semantic-specific 用户兴趣 embedding 的端到端框架。UxSID 由三大模块构成:(1) SIDs Generator:基于 MLLM 编码器 + Res-KmeansFSQ 把 target 物品的多模态属性(文本、图像、世界知识)量化为分层语义码;(2) Item-Agnostic Interest Compression(IAIC):用交叉 attention + Per-token FFN + 正交损失,把原始行为序列压缩成 $K$ 个互补的 interest anchors;(3) Hierarchical Semantic Probing:用 target SID 作为查询,先对原始序列做 explicit attention 得到 $e_{global}$,再经 gated MLP 调制后对 interest anchors 做 attention 得到 $e_{local}$,最终拼接为 UxSID embedding。整个 framework 完全 offline 训练,online inference 通过 $\text{Hash}(UID \oplus SID)$ 的 $O(1)$ 点查拉取 embedding,再以轻量 attention 与 target 融合,严格保持序列长度增长不影响 online 延迟。
在 XLong、KuaiRec-Big 两个公开 benchmark 和快手广告大规模工业数据集上,UxSID 一致地超越 DIN、SIM、ETA、SDIM、MIRRN、TWIN、C-Former 等所有 SOTA baseline;序列从 1k 扩展到 10k 时性能仍稳定增长,体现 scaling 行为。Kuaishou 广告系统一周线上 A/B 取得 Exposure +0.111%、Cost +0.231%、Revenue +0.337% 的显著提升,且推理延迟仅增加 0.16 ms。
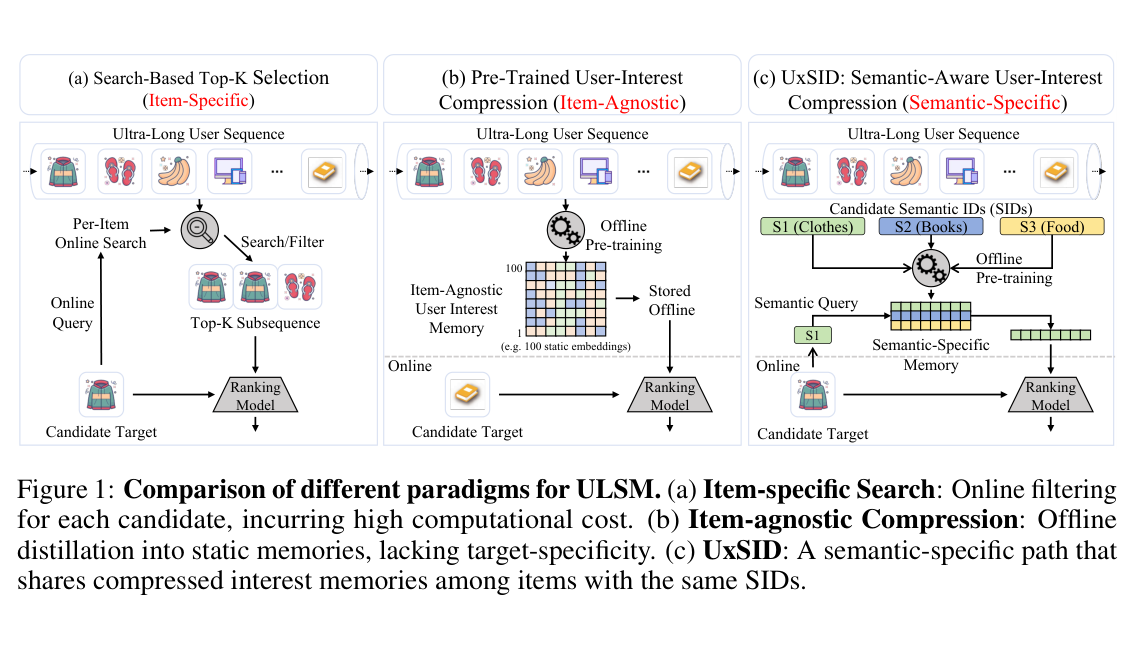
Figure 1 直观对比三种范式:(a) Item-Specific Search 在 online 阶段为每个候选做检索,开销大;(b) Item-Agnostic Compression 把超长序列离线压成静态 memory,缺乏 target 特异性;(c) UxSID 用 Candidate SIDs(如 S1=Clothes、S2=Books、S3=Food)作为语义键,在 offline 阶段把序列压成与 SID 对齐的 semantic-specific memory,online 通过 Semantic Query 直接拉取对应 SID 的 memory 输入 ranking。
核心方法:UxSID 框架¶
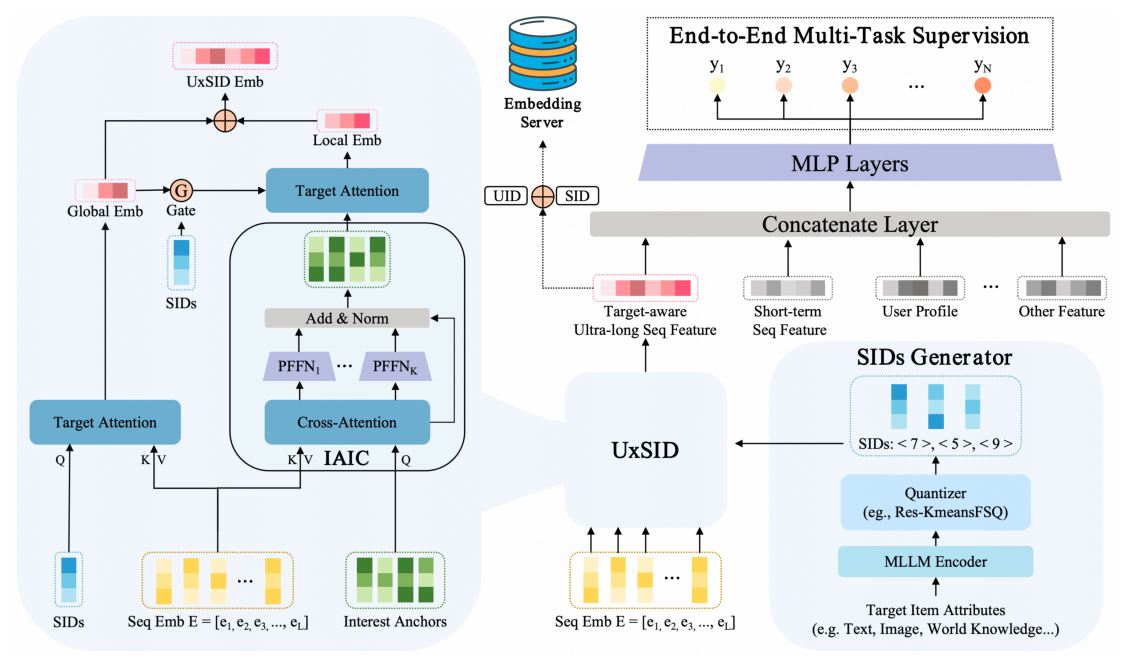
Figure 2 给出 UxSID 的完整架构。左侧蓝色框为 UxSID embedding 生成模块,右侧为 end-to-end multi-task supervision 框架;底部 SIDs Generator 给出 target 物品的语义 ID。整套架构离线训练并把 $E^{\text{UxSID}}$ 缓存在 Embedding Server,online ranking 模型通过 (UID, SID) 拉取作为 target-aware ultra-long seq feature 与短期序列、用户画像等拼接进 MLP 预测多任务。
2.1 Semantic IDs Generation¶
为了让模型获得能跨越字面 ID 匹配的语义探针,UxSID 通过基于推理的对齐机制 [QARM v2] 为每个物品生成 SIDs。给定物品 $i$ 的多模态属性(视频帧、文本描述等),首先用 MLLM encoder 投影到与业务对齐的连续语义空间:
$$\mathbf{z}_i = \text{Enc}_{\text{MLLM}}(\text{Attributes}_i) \tag{1}$$
其中 $\mathbf{z}_i \in \mathbb{R}^d$。为兼顾计算与存储效率,采用 Res-KmeansFSQ 混合量化(残差 + k-means + Finite Scalar Quantization)。该过程把 $\mathbf{z}_i$ 分解为 $M$ 层分层语义码:
$$\mathbf{z}_i \approx \sum_{m=1}^{M} \mathcal{C}_m(k_m), \quad k_m = \arg\min_j \|\mathbf{r}_{m-1} - \mathbf{c}_{m,j}\|_2 \tag{2}$$
其中 $\mathcal{C}_m$ 是第 $m$ 层 codebook,$\mathbf{c}_{m,j} \in \mathbb{R}^d$ 是该层第 $j$ 个码字;残差向量 $\mathbf{r}_m = \mathbf{z}_i - \sum_{l=1}^m \mathcal{C}_l(k_l)$,初始 $\mathbf{r}_0 = \mathbf{z}_i$。最终物品被表示为 SID 序列 $(k_1, k_2, \ldots, k_M)$。在快手工业部署里,UxSID 仅取第一层 SID $k_1$ 作为 target SID(记为 $c_{target}$),以在语义粒度和推理延迟之间求平衡。第一层 codebook size 设为 4096,embedding dim 设为 32(与下游 attention 的 head dim 严格对齐)。
2.2 Item-Agnostic Interest Compression(IAIC)¶
IAIC 模块负责把原始交互序列 $\mathcal{B} = [b_1, b_2, \ldots, b_L]$ 压缩成一组紧凑的 interest anchors $\mathbf{P} \in \mathbb{R}^{K \times d}$($K \ll L$)。
Interest Anchor Compression:先用 embedding lookup 把每个 item $i_t$ 转为 $d$ 维向量,得 $\mathbf{E} = [\mathbf{e}_1, \mathbf{e}_2, \ldots, \mathbf{e}_L] \in \mathbb{R}^{L \times d}$。定义一组可学习的 interest anchors $\mathbf{Q}_{anc} \in \mathbb{R}^{K \times d}$ 作为 attention 查询,通过 cross-attention 聚合 salient 特征:
$$\mathbf{H} = \text{Softmax}\!\left(\frac{(\mathbf{Q}_{anc}\mathbf{W}^Q)(\mathbf{E}\mathbf{W}^K)^\top}{\sqrt{d}}\right)(\mathbf{E}\mathbf{W}^V) \tag{3}$$
其中 $\mathbf{H} = [\mathbf{h}_1, \ldots, \mathbf{h}_K]^\top \in \mathbb{R}^{K \times d}$ 是压缩后的兴趣特征,$\mathbf{W}^Q, \mathbf{W}^K, \mathbf{W}^V \in \mathbb{R}^{d \times d}$ 是可学习投影。
为强化每个 anchor 的独立表达,作者引入 Per-token FFN(PFFN):每个 anchor 走自己的 FFN 子网络,再接 residual 与 LayerNorm:
$$\mathbf{p}_k = \text{LayerNorm}\!\left(\mathbf{h}_k + \sigma\!\left(\mathbf{h}_k \mathbf{W}_1^{(k)} + \mathbf{b}_1^{(k)}\right) \mathbf{W}_2^{(k)} + \mathbf{b}_2^{(k)}\right) \tag{4}$$
其中 $\mathbf{W}_1^{(k)}, \mathbf{W}_2^{(k)}, \mathbf{b}_1^{(k)}, \mathbf{b}_2^{(k)}$ 是第 $k$ 个 anchor 专属参数,$\sigma$ 为 sigmoid。PFFN 确保每个 anchor 在自己的语义子空间内被独立 refine,最终得到 $\mathbf{P} = [\mathbf{p}_1, \ldots, \mathbf{p}_K]^\top \in \mathbb{R}^{K \times d}$。
Diversity and Orthogonality Constraint:为防止 $K$ 个 anchor 退化到单一兴趣,引入一个归一化 Orthogonality Loss:
$$\mathcal{L}_{ortho} = \left\| \frac{\mathbf{P}\mathbf{P}^\top}{\|\mathbf{P}\|_2^2} - \mathbf{I} \right\|_F \tag{5}$$
分母对 $\mathbf{P}$ 的 $L_2$ 范数平方做归一化,使该约束在不同 scale 下数值稳定。最小化 $\mathcal{L}_{ortho}$ 等价于让 anchors 间内积接近正交,确保每个 anchor 代表一个独立、separable 的长时兴趣 facet。
2.3 Hierarchical Semantic Probing¶
不同于静态压缩方法,UxSID 用 target SID $c_{target}$ 作为主动探针驱动一个 dual-stage attention,被一个 gating 模块连接。
Stage 1 — Explicit Semantic Probing:第一阶段直接用 target SID 查询原始行为序列 $\mathbf{E}$,捕捉 target 与历史 item 间的细粒度全局相关性:
$$\mathbf{e}_{global} = \text{Softmax}\!\left(\frac{(c_{target}\mathbf{W}_g^Q)(\mathbf{E}\mathbf{W}_g^K)^\top}{\sqrt{d}}\right)(\mathbf{E}\mathbf{W}_g^V) \tag{6}$$
其中 $\mathbf{e}_{global} \in \mathbb{R}^d$ 代表全局兴趣响应——即用户长序列中与 target 高相关的细粒度信号。
Stage 2 — Gated Latent Probing:第二阶段进一步在 IAIC 输出的 anchor 上做 attention,但用一个 gating 向量 $\mathbf{g}_{ctx} \in \mathbb{R}^d$(由 $\mathbf{e}_{global}$ 经两层 MLP 生成)调制 target SID embedding:
$$\mathbf{g}_{ctx} = \sigma(\text{GatedNet}(\mathbf{e}_{global})) \tag{7}$$
$$\mathbf{q}_{ref} = c_{target} \odot \mathbf{g}_{ctx} \tag{8}$$
通过 Hadamard 积,gating 向量像一层 latent mask 把 target 语义对齐到当前 user 的 global behavior context,得到 refined query $\mathbf{q}_{ref}$。再用 $\mathbf{q}_{ref}$ 对 anchors $\mathbf{P}$ 做 attention 提取 localized intent:
$$\mathbf{e}_{local} = \text{Softmax}\!\left(\frac{(\mathbf{q}_{ref}\mathbf{W}_l^Q)(\mathbf{P}\mathbf{W}_l^K)^\top}{\sqrt{d}}\right)(\mathbf{P}\mathbf{W}_l^V) \tag{9}$$
最终 UxSID embedding 是两段输出拼接:$\mathbf{E}^{\text{UxSID}} = [\mathbf{e}_{global}; \mathbf{e}_{local}]$。两段同时存在的设计让 UxSID 既能捕捉广义历史 context(item-level explicit attention),又能聚焦 anchor 维度的 target-specific 峰值。
2.4 Model Training and Loss Function¶
precomputed $\mathbf{E}^{\text{UxSID}}$ 与 target 特征 $\mathbf{E}^t$、user profile $\mathbf{E}^u$、context 特征 $\mathbf{E}^c$、短期行为 $\mathbf{E}^{\text{short}}$ 一起送入 ranking head:
$$p(x) = \sigma\!\left( \text{MLP}\!\left( \mathbf{E}^t; \mathbf{E}^u; \mathbf{E}^c; \mathbf{E}^{\text{short}}; \mathbf{E}^{\text{UxSID}} \mid x \right) \right) \tag{10}$$
端到端联合损失:
$$\mathcal{L} = -\frac{1}{N}\sum_{n=1}^N \left[ y_n \log(p(x_n)) + (1-y_n)\log(1-p(x_n)) \right] + \lambda \mathcal{L}_{ortho} \tag{11}$$
第一项为推荐任务的 BCE,第二项为 orthogonality 正则,$\lambda$ 控制 diversity 力度。
2.5 Serving in Production¶
线上服务的关键设计是 offline pre-compute + O(1) online lookup:训练完成后,$\mathbf{E}^{\text{UxSID}}$ 被按 $(UID, SID)$ pair 离线计算并缓存到 Embedding Server(ES),存储 key 由 bitwise concatenation 生成:
$$\text{Key} = \text{Hash}(UID \oplus SID), \quad \text{Value} = \mathbf{E}^{\text{UxSID}} \tag{12}$$
由于 SID 的强聚类性,每个用户的活跃 SID 数有限(实际部署里平均约 100 个 unique SID/user),因此总存储量在工业可行范围内(4 亿活跃用户 × 100 SID/user 约 2.56 TB,远小于现代分布式 KV 存储容量)。Online 时按当前 target item 的 SID 拉取对应 $\mathbf{E}^{\text{UxSID}}$,与 target query(加上 side info)以轻量 attention 融合后送 ranking。
实验设置¶
数据集:两个公开 benchmark + 一个工业数据集:
| Dataset | #Users | #Items | #Interaction | Avg Seq Len | Max Seq Len |
|---|---|---|---|---|---|
| XLong | 1,000 | 3,269,017 | 1,000,000 | 1,000 | 1,000 |
| KuaiRec-Big | 7,176 | 10,728 | 12,530,806 | 1,746 | 3,000 |
工业数据集来自快手广告系统(2026.4.1–4.7),含 impression log 与多任务 label,序列长度保留至 10k。
Baselines:DIN、SIM-Hard、SIM-Soft、ETA、SDIM、MIRRN、TWIN、C-Former。所有 baseline 共享同一 bottom 层、仅 attention 层不同。
Metrics:AUC、UAUC、WUAUC 评估总体与 user-level 排序;引入 Interest Recall@K(Int.R@K) 量化语义激活精度,定义为 explicit semantic probing 检索到的 Top-$K$ 行为中与 target 共享 first-layer SID(或 category tag)的比例。
Implementation:序列长度 KuaiRec-Big 2k、XLong 1k、工业数据集 1k(10k scalability 单独分析)。GSU retrieval quota = 100;prediction head MLP [200, 80, 2],sparse embedding dim 16。所有公开数据集用 Adam(batch 256,lr 1e-3,NVIDIA L20 GPU)。UxSID 配置:gating network [16, 16] + activation;PFFN 每个 FFN 是 [16, 32, 16];用 LETTER 工具包训练 SIDs,公开数据集 codebook shape [256, 256, 256, 256],工业部署只取 first layer,IAIC anchor 数 $K=16$。
主要实验结果¶
3.1 Performance on Public Datasets¶
Table 1 (AUC) 与 Table 7(三次随机种子的 robustness)展示 UxSID 在两个公开 benchmark 的表现:
| Models | XLong | KuaiRec-Big |
|---|---|---|
| DIN | 0.7889 | 0.8181 |
| SIM-Hard | – | 0.8201 |
| SIM-Soft | 0.7971 | 0.8279 |
| ETA | 0.7910 | 0.8231 |
| SDIM | 0.7915 | 0.8209 |
| MIRRN | 0.7926 | 0.8217 |
| TWIN | 0.8154 | 0.8269 |
| C-Former | 0.8135 | 0.8276 |
| UxSID | 0.8408 | 0.8348 |
XLong 上 UxSID 0.8408 比最强 search-based baseline TWIN(0.8154)高 +0.0254 AUC,比 advanced compression model C-Former(0.8135)高 +0.0273 AUC。这一差距相当大:C-Former 已用 learnable anchor 做 clustering,但 anchor 在压缩阶段仍 target-agnostic;UxSID 用 SIDs 作为 semantic query 激活 target-specific 兴趣,证明了target-aware probing 是 ULSM 精排不可或缺的成分。Table 7 显示三次随机种子下 UxSID 的标准差仅 ±0.0001(KuaiRec-Big)和 ±0.0023(XLong),框架对初始化噪声极其鲁棒。
3.2 Performance on Large-Scale Industrial Datasets¶
Table 2 给出快手工业数据集上 CTR 与 CTCVR 任务的对比(0.1% 已是显著 milestone):
| Models | CTR AUC | CTR UAUC | CTR WUAUC | CTCVR AUC | CTCVR UAUC | CTCVR WUAUC |
|---|---|---|---|---|---|---|
| SIM-Hard | 0.8698 | 0.6042 | 0.6063 | 0.8599 | 0.6161 | 0.6221 |
| SIM-Soft | 0.8711 | 0.6084 | 0.6099 | 0.8608 | 0.6228 | 0.6307 |
| TWIN | 0.8712 | 0.6093 | 0.6104 | 0.8609 | 0.6232 | 0.6310 |
| UxSID (Ours) | 0.8728 | 0.6125 | 0.6161 | 0.8626 | 0.6269 | 0.6350 |
UxSID 在 CTCVR AUC 上达 0.8626,超过 SIM-Soft(+0.18%)和 TWIN(+0.17%)。论文把这一优势归因于 IAIC + hierarchical probe:SIM/TWIN 通过 retrieval/attention 提供 item-specific 能力,UxSID 在此之上用 SIDs 的高密度语义引导探针导航整片兴趣 landscape,避免传统启发式过滤的信息损失。
3.3 Online A/B Test¶
在快手短视频广告平台部署 UxSID,进行一周线上 A/B:
| Scenarios | Exposure | Cost | Revenue |
|---|---|---|---|
| Advertising | +0.111% | +0.231% | +0.337% |
值得注意的是 Revenue(+0.337%)显著高于 Exposure(+0.111%),意味着每次曝光带来的转化效率提升明显——这正是 target semantic-specific 压缩驱动高精度转化的直接证据。延迟方面,相比 baseline 仅增加 +0.16 ms,完全满足工业延迟约束。
3.4 Ablation Study¶
Table 4 系统消融每个组件:
| Variants | CTR AUC | CTR UAUC | CTR WUAUC | CTCVR AUC | CTCVR UAUC | CTCVR WUAUC | Int.R@50 (Ind) | XLong AUC | KuaiRec-Big AUC | KuaiRec-Big Int.R@50 |
|---|---|---|---|---|---|---|---|---|---|---|
| Category (Tag) | 0.8707 | 0.6081 | 0.6088 | 0.8605 | 0.6186 | 0.6288 | 0.0543 | – | 0.8261 | 0.0916 |
| w/o $\mathbf{e}_{global}$ | 0.8714 | 0.6101 | 0.6108 | 0.8615 | 0.6230 | 0.6318 | – | 0.8370 | 0.8302 | – |
| w/o $\mathbf{e}_{local}$ | 0.8719 | 0.6114 | 0.6121 | 0.8618 | 0.6238 | 0.6327 | 0.1454 | 0.8375 | 0.8314 | 0.2009 |
| w/o $\mathcal{L}_{ortho}$ | 0.8725 | 0.6119 | 0.6144 | 0.8624 | 0.6261 | 0.6342 | 0.1471 | 0.8385 | 0.8344 | 0.2063 |
| w/o Gate | 0.8723 | 0.6116 | 0.6127 | 0.8623 | 0.6249 | 0.6334 | 0.1467 | 0.8376 | 0.8342 | 0.2044 |
| UxSID | 0.8728 | 0.6125 | 0.6161 | 0.8626 | 0.6269 | 0.6350 | 0.1488 | 0.8408 | 0.8348 | 0.2071 |
SID-based Semantic Querying 的有效性(Category Tag 行):把 candidate SIDs 替换为粗粒度 category tag 后,所有指标全面下滑,Int.R@50 从 0.1488 跌到 0.0543(工业数据集),KuaiRec-Big 上从 0.2071 跌到 0.0916。说明 category-level 属性的语义分辨率根本不足以精确导航复杂用户兴趣;SID 的高密度量化才是 target-specific 探针的成功基础。
Hierarchical Probing 的两个分支:去掉 $\mathbf{e}_{global}$ 导致最显著的 AUC 跌落,证明直接对原始序列做 explicit attention 不可替代——它捕捉的细粒度 item-to-item 信号在 compression 中会被平滑掉;去掉 $\mathbf{e}_{local}$ 同样下降,说明 interest anchors 不仅能过滤历史噪声,还能提供一个 $\mathbf{e}_{global}$ 无法覆盖的 diverse、structural 视角。两者互补。
Gating 与 Orthogonality 的角色:去掉 GatedNet(直接用原始 SID 探针)导致明显下降,说明用 $\mathbf{e}_{global}$ 作为 latent mask 是必要的——它把 user 全局 context 注入 local query,使探针不仅看 target 本身、还看 user 实际兴趣分布;去掉 $\mathcal{L}_{ortho}$ 同样下降,验证 anchors 间的正交约束防止 mode collapse,保留多面用户偏好。
3.5 Efficiency and Scaling Analysis¶
Table 5 对比 inference 时间复杂度:
| Model | Inference Time Complexity |
|---|---|
| SIM-Hard | $O(B\log(A) + BRd)$ |
| SIM-Soft | $O(BLd + BRd)$ |
| ETA | $O(BLm + BRd)$ |
| SDIM | $O(Bm\log(d))$ |
| MIRRN | $O(BLm + BR\log(R)d + BRd^2)$ |
| TWIN | $O(BL + BfLd + BRd)$ |
| C-Former | $O(BRd)$ |
| UxSID | $O(Bcd)$ |
$B$ 是 batch size,$L$ 原始序列长度,$R$ 检索后序列长度,$c$ compressed interest length。Search-based paradigm(SIM, TWIN)在 online 阶段都有 matching overhead,而 UxSID 把 ULSM 完全 offload 到 offline,online 复杂度对 target-level compression 维持 $O(1)$,即使序列扩展到 10k,延迟仍恒定。
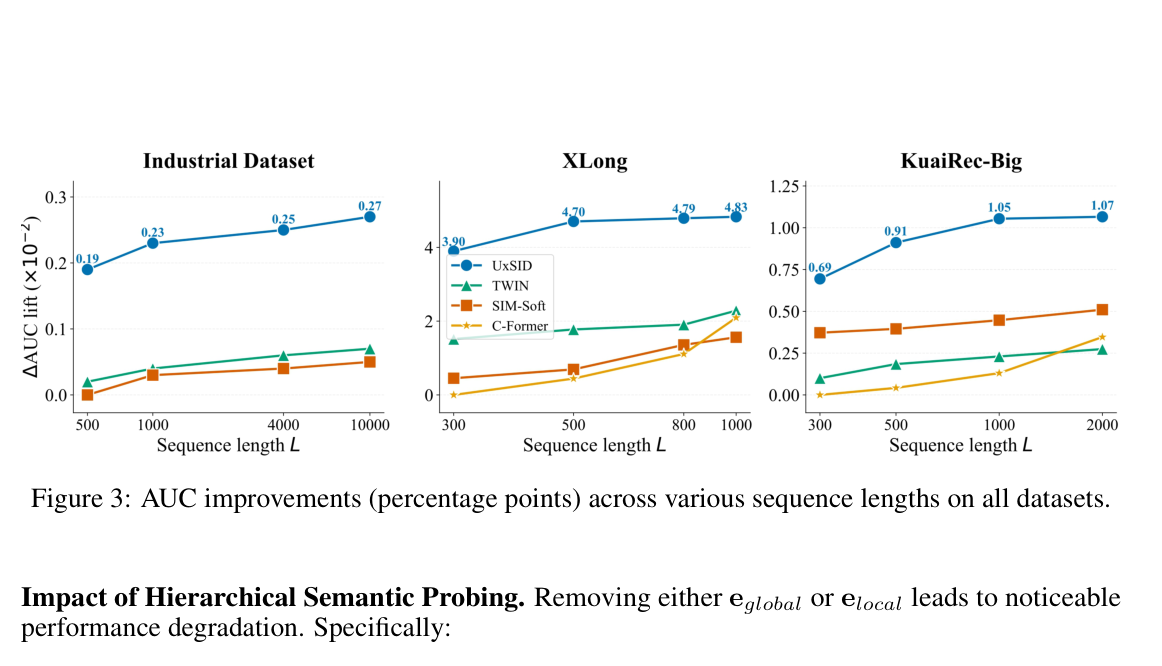
Figure 3 给出 Industrial Dataset(500–10000)、XLong(300–1000)、KuaiRec-Big(300–2000)三个 scale 上不同模型的 ΔAUC 增益。UxSID 始终保持最高 AUC,且性能差距在 10k 处最显著(工业 ΔAUC ≈ 0.27×10⁻²)。Search-based 方法(SIM, TWIN)在序列变长时呈现 deceleration,固定 retrieval scope 排除了远端相关交互;C-Former 在短序列上不稳定,长序列时虽提升但仍落后——静态压缩在缺乏 target-aware 引导时难以从噪声里解耦信号。UxSID 的 SID-based routing 把广阔行为数据可靠地转化为可观增益,确立其 lifelong behavior modeling 的潜力。
3.6 Parameter Sensitivity & Visualization¶
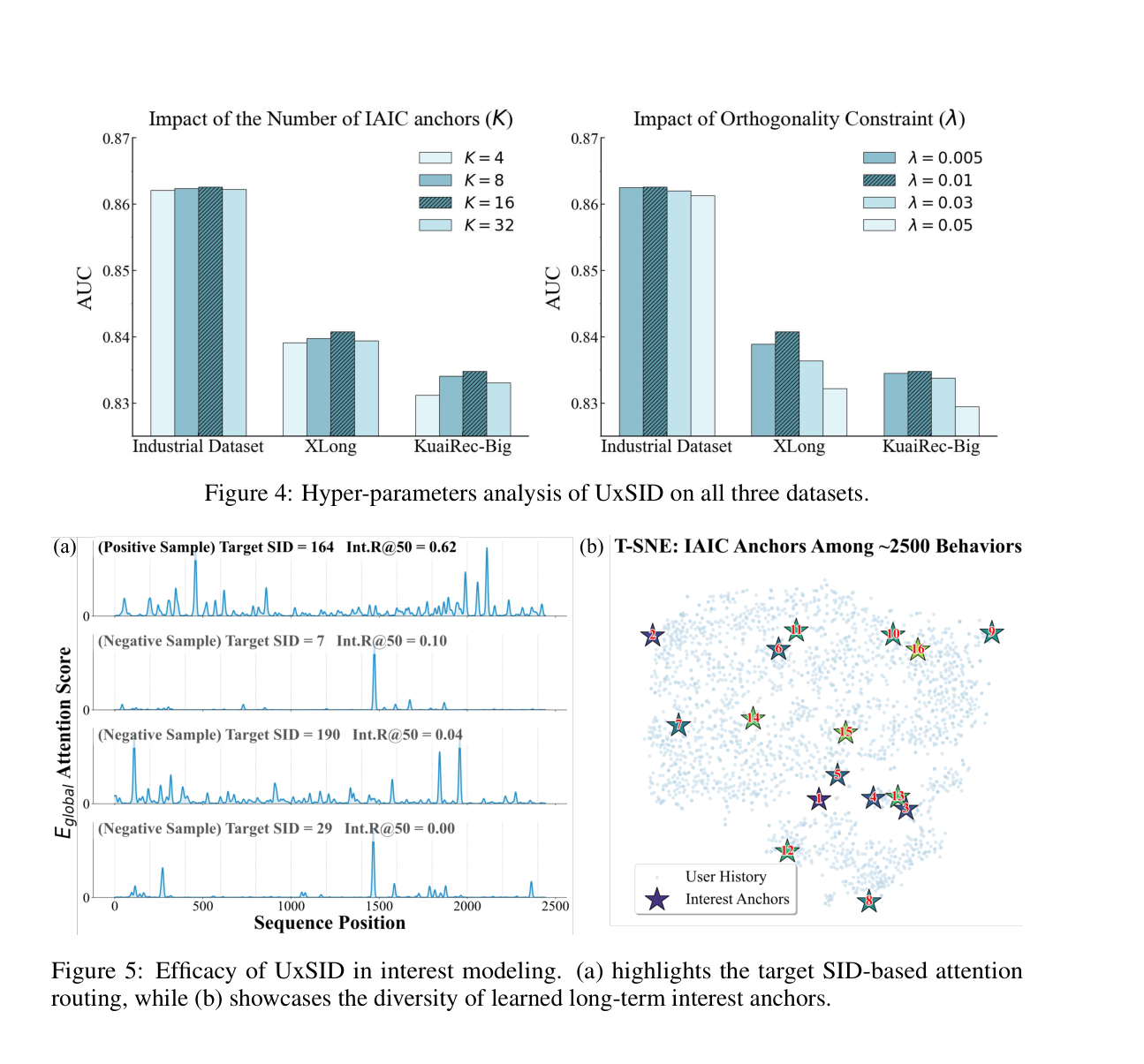
Figure 4 给出两个关键超参的敏感性:
- IAIC anchor 数 $K$:$K=4$ 时性能下降——压缩瓶颈过窄导致兴趣纠缠与细粒度信息损失;$K$ 增大到 16 时性能 peak;过大($K=32$)反而引入冗余和过分散的 routing。最终 $K=16$。
- Orthogonality $\lambda$:$\lambda$ 过小,anchors 容易拟合高频模式,IAIC 多样性不足;$\lambda$ 过大反而过约束 latent 空间,破坏主 CTR 预测。论文最终选 $\lambda=0.01$ 左右。
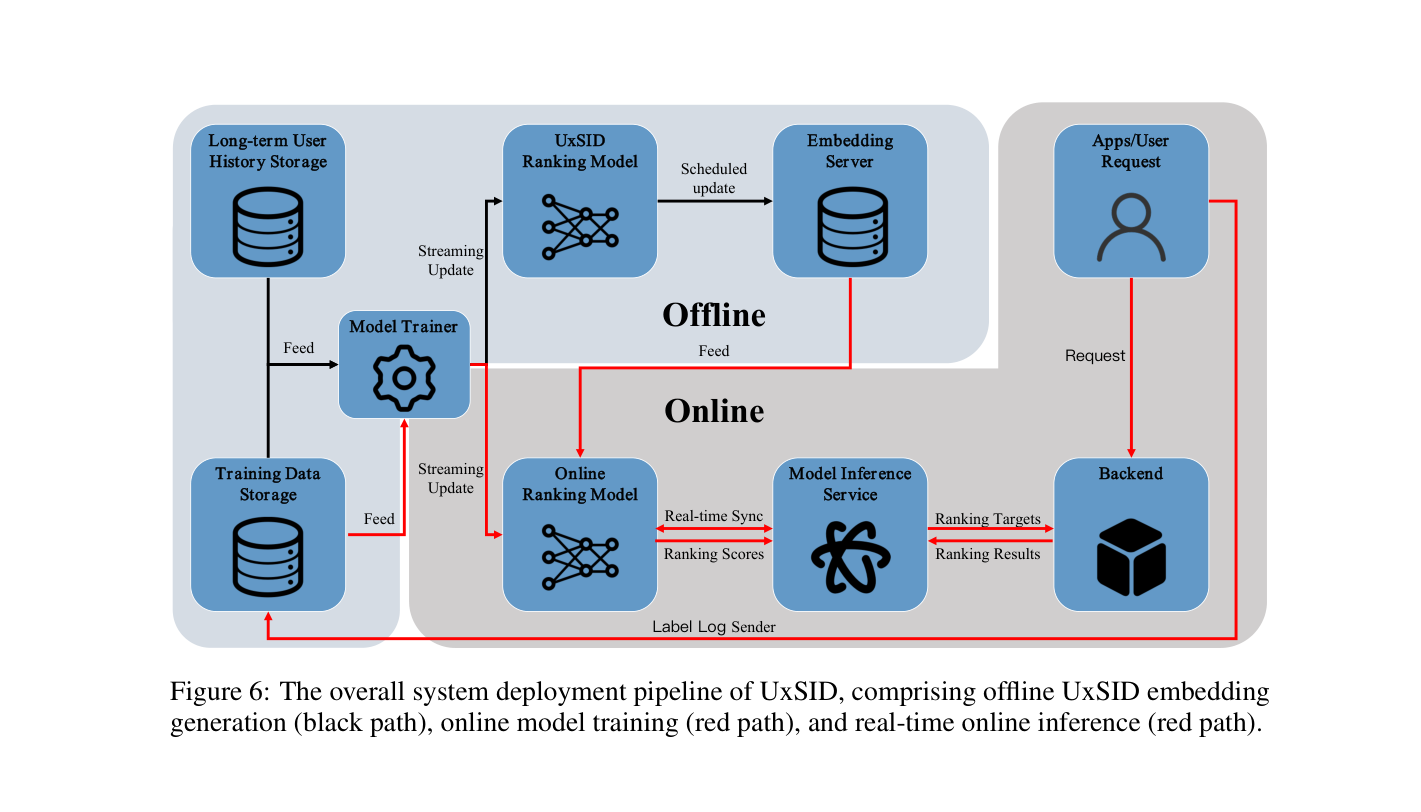
Figure 5(a) 在 KuaiRec-Big 上展示 explicit probing 的 attention 分布:positive sample(target SID=164,Int.R@50=0.62)attention 峰大量散布于整个历史区间,包括序列早期 behaviors;negative samples(target SID=7/190/29,Int.R@50≈0.0–0.1)则 attention 弥散且 recall 几近零。这定量证明 SIDs 作为高密度语义探针的精确激活能力,且能跨越整个 behavioral cycle——粒度是传统压缩难以企及的。Figure 5(b) 是 IAIC anchors 在 ~2500 个用户 behavior 上的 t-SNE 可视化:anchors(星形)分布于不同语义簇,覆盖整个 behavior 空间,证明 IAIC 学到的是 diverse 而非退化兴趣。
工业部署与可行性¶
注:上面 Figure 5 与 Figure 6 在 PDF 中位于不同页,但本目录的提取脚本把 deployment pipeline 也命名为 fig_05.png,请按 caption 区分。
部署 pipeline 含三条路径:(1) black path(offline UxSID embedding generation):长序列存储 → UxSID Ranking Model 训练 → 定时写入 Embedding Server;(2) red path(online training):训练数据流式更新 Online Ranking Model;(3) online inference:Request → Online Ranking Model + Embedding Server lookup → Model Inference Service → 排序结果。
Online deployment 可行性:UxSID 做 user-target 交叉压缩,按 $(UID, SID)$ 索引,存储 footprint 比单 user-embedding 方案大。但 SID 的强聚类性使每个用户活跃 SID 数有限——快手 4 亿活跃用户场景下平均 100 unique SID/user,总存储 ≈ 2.56 TB,在分布式 KV 系统容量内。
Model 配置与维护:codebook 架构与 QARM V2、OneRec-v2 共享,first-level codebook size 4096、embedding dim 32,与 UxSID 三个单头 attention 网络的 hidden unit 严格对齐,保证表征一致性。Embedding Server 每周一次 scheduled update 保持语义表征时效性。
计算成本与延迟:UxSID 1k 训练需 16 A10,扩展到 10k 需 40 A10。Online 模型由于只读取压缩 $E^{\text{UxSID}}$ 而非整条 10k 序列,资源消耗与序列长度无关。当前 1k 在线模型用 450 A10;若线上模型直接处理 10k 序列则需 5,300 A10——UxSID 把这一负担转移到 offline,仅增加 +0.16 ms 在线延迟。
关于 SID 信息泄漏(Appendix D.2):作者担心 UxSID 增益是否仅来自 item-side SID 信息丰富。Table 8 把 first-layer SID 作为 sparse feature 加到所有 baseline 上:DIN 0.7889 → 0.7932,TWIN 0.8154 → 0.8189,C-Former 0.8135 → 0.8180(XLong);UxSID base 0.8408 → UxSID+SID 0.8439。所有 baseline 加 SID 后仍显著落后 UxSID base,证明性能增益来自架构(IAIC + hierarchical probing),而不仅是 SID 信息注入。
与已归档相关工作的对比¶
SIF SIF: Sample Is Feature(Meituan, 2026-04-17)¶
关系:独立并发(双方互不引用,殊途同归提出"offline 量化压缩 + 工业 ranking")· 已加载对方精读
- 共同关注的问题:工业 ranking 在样本信息扩展(行为序列延展)与模型容量扩展(统一 Transformer)两条路径上都遇到瓶颈,必须找到在线计算成本可控的方式来携带更多历史信号。SIF 与 UxSID 都把瓶颈定位为在线时延 vs 历史信号承载的矛盾。
- 相近的技术骨架:两者都把核心计算 offline 化,并用残差/分层量化作为压缩骨架:SIF 用 Hierarchical Group-Adaptive Quantization(4 个语义组 × Adaptive sub-token × RVQ M 层 V=256),UxSID 用 Res-KmeansFSQ(MLLM 编码 → 4 层 codebook 256×256×256×256,部署只取 first layer 4096 entries)。两者都把 quantization 索引作为在线 embedding lookup 的 key,省去在线侧的高维存储与计算。
- 本文的差异与推进:SIF 走的是 UxSID 所归类的 "item-agnostic compression" 路径——它把每条历史 sample 量化为 Token Sample,整个压缩过程不感知 target,依靠下游 SIF-Mixer 的 sample-level 注意力恢复 target-aware 信号。UxSID 提出的第三条路径明确是 target SID 介入压缩:anchors 与 hierarchical probing 都由 target SID 直接驱动。两者代表了同一空间内的两种 design philosophy:SIF 是 "信息密度优先 + 在 mixer 阶段 disambiguate",UxSID 是 "compression 阶段就引入 target 语义先验"。
- 可比的方法 / 实验差异:SIF 美团本地生活离线 +0.88% GAUC、线上 +2.03% CTR / +1.21% CVR / +1.35% GMV;UxSID 快手广告 +0.337% Revenue / +0.231% Cost。两者都在 0.1%–几% 量级,但 SIF 的样本压缩力度更激进(每个 sample 27 sub-token × 3 RVQ × 8 bit = 648 bits),UxSID 在每个 (UID,SID) pair 上存 [2, 32] 浮点 embedding,存储模型显然不同。
STCA STCA: Make It Long, Keep It Fast(ByteDance Douyin, 2025-11-08)¶
关系:独立并发,相同目标(10k 序列)+ 互补解法 · 已加载对方精读
- 共同关注的问题:把端到端推荐序列建模从几百扩展到 10k,是 ULSM 的核心 scaling 目标。两篇都明确以 "10k sequence" 为里程碑,且都观察到了类 scaling law 的行为(UxSID Figure 3 + STCA Figure 1)。两者都来自头部短视频/直播平台(Kuaishou × ByteDance),且都明确反对 TWIN 类两段式 GSU+ESU 带来的端到端中断与 retrieval bias。
- 相近的技术骨架:两篇都用 target 作为唯一查询去聚合长序列信号(STCA:target-to-history 单查询 cross-attention;UxSID:target SID 在 hierarchical probing 中作为唯一探针),都论证了 "历史 item 之间二阶关系信息量低,target-to-history 才是主信号"。
- 本文的差异与推进:STCA 把方案彻底押在端到端 online 推理——通过单查询交叉注意力把复杂度从 $O(L^2)$ 降到 $O(L)$,再用 Request-Level Batching 把同用户多候选共享 user encoding,最后用 Train Sparsely / Infer Densely 把训练成本和部署长度解耦。UxSID 走相反方向:把整段 ULSM 推到 offline pre-compute,online 仅做 $O(1)$ KV lookup + 轻量 attention。两条路径在 trade-off 上彼此互补:STCA 保留实时性、能在 fresh 行为上即时更新(每条新行为立刻参与下次推理),但要付出 GPU 5,300 卡级别的在线开销;UxSID 用 weekly 离线刷新的 Embedding Server 把在线开销固定在 +0.16 ms,但失去对极近期行为的瞬时反应。
- 可比的方法 / 实验差异:STCA 通过实测把 RLB 在 m=8 时 host↔device I/O 节约 87.5%、端到端 77–84%,且 GPU 吞吐 +2.2×;UxSID 把 1k → 10k 所需在线 GPU 从 5,300 卡降至 0 增量(offline 40 A10)。两者均报告 scaling law 行为:STCA 是 model+seq 维度的,UxSID 是序列长度维度的(Figure 3 中 UxSID ΔAUC 随 L 单调上升)。STCA 没用 SID;UxSID 没尝试在 ESU/前向中加入实时 fresh signal——两者结合(STCA 处理近期行为 + UxSID 离线长时记忆)是显然的下一步组合空间。
IAT IAT: Instance-As-Token Compression(ByteDance, 2026-04-10)¶
关系:独立并发,问题相近但 token 单位不同 · 已加载对方精读
- 共同关注的问题:现有 ULSM 用稀疏手工 item-level 特征(item ID + 少量手工字段)描述历史交互,丢失了大量原始 sample 上下文。IAT 与 UxSID 都看到了"raw item embedding 信息密度不足" 这一共性瓶颈,并都把解法放在offline 集中预计算 + online 检索的 pipeline 里(IAT 写 Parameter Server,UxSID 写 Embedding Server)。
- 相近的技术骨架:两篇都构造了一个两阶段架构:第一阶段离线生成紧凑表征(IAT 的 InsEmb / UxSID 的 $E^{\text{UxSID}}$),第二阶段在 downstream ranking 中作为高密度 sequence token / 用户兴趣 embedding 使用。IAT 的 Source Instance Transformer 与 UxSID 的 IAIC 都用 attention 在压缩阶段聚合跨样本/跨 item 信号;两者都强调 streaming training + 定期物化更新。
- 本文的差异与推进:IAT 的 "token 单位" 是训练样本(每次历史交互的所有字段被压成一个 64 维 InsEmb),核心目标是突破手工序列特征的容量限制;它的压缩 完全 target-agnostic——一旦 InsEmb 生成,所有下游 ranking 共享同一份 token。UxSID 的 "token 单位" 是用户的 target-aware 兴趣 embedding:相同用户在不同 target SID 下生成不同的 $E^{\text{UxSID}}$,存储为 $(UID, SID)$ 索引;本质上 UxSID 把"按用户存 1 份"升级为"按 (用户, target 语义组) 存 N 份",用存储换 target 特异性。
- 可比的方法 / 实验差异:IAT 部署在多个 ByteDance 广告场景获显著线上提升;UxSID 在快手广告 +0.337% Revenue。两者在 ByteDance vs Kuaishou 的并行验证强化了 "offline compress + PS/ES lookup" 范式的工业可行性。一个有意思的组合空间:把 IAT 的 InsEmb(携带完整样本 context)作为 IAIC 的输入序列,而不是裸 item embedding,可能进一步丰富 anchor 的语义。
讨论与局限性¶
核心贡献:
- 第三条 ULSM 范式:UxSID 是首个明确以 SID 作为语义路由键桥接 item-specific 检索与 item-agnostic 压缩的工作。其哲学是 "semantic-group shared interest memory"——比 user-level memory 更精细,比 item-level retrieval 更高效。
- Hierarchical probing 的 dual-stage 设计:用 $\mathbf{e}_{global}$ 直接对原始序列做 attention 不可替代(细粒度信号),用 gated $\mathbf{e}_{local}$ 对 anchor 做 attention 提供 anchor 维度的 target-specific 峰值,两者互补。Gating 把 user context 注入 query 是非平凡设计。
- O(1) online inference + offline scalability:通过 $(UID, SID)$ 索引彻底把 ULSM 从在线 path 移除,10k 序列下仅 +0.16 ms 在线延迟,工业可复现性强。
- 大规模真实部署:快手 400M 用户广告平台一周 A/B +0.337% Revenue,存储 ~2.56 TB 在分布式 KV 容量内,pipeline 与 QARM V2 / OneRec-v2 共用 codebook 架构,落地路径清晰。
值得借鉴的设计:
- PFFN + Orthogonality Loss 联手保证 $K$ 个 anchor 的语义独立性,是一种比 routing/MoE 更简单的 diversity 约束。
- Gated Latent Probing 的 $\mathbf{q}_{ref} = c_{target} \odot \sigma(\text{MLP}(\mathbf{e}_{global}))$ 把"target 应该被 user 当前兴趣条件化"形式化为一个 Hadamard 调制,可推广到其他 target-conditioned retrieval 场景。
- Hash(UID ⊕ SID) 索引复用现有 KV 基础设施,没有引入新的存储/检索 stack。
局限与未解决问题:
- 新鲜度(freshness)问题:Embedding Server 每周一次 scheduled update,意味着用户近期 1 周内的新行为不会立即反映到 $E^{\text{UxSID}}$。论文用一个短期 seq feature $\mathbf{E}^{\text{short}}$ 在 online 阶段弥补,但这本质上是回到了短序列建模——如何让 offline ULSM 与 online 近期信号无缝融合仍是开放问题。STCA / OneTrans 等端到端方案恰好在新鲜度上更强。
- SID 粒度选择:部署只用 first-layer SID(4096 entries),牺牲了 second/third layer 的更细粒度。如果 first-layer 同 SID 内有多个 distinct sub-cluster,UxSID 会在该层级失去分辨能力。多层 SID 联合查询(多 query attention 或 hierarchical routing)是潜在改进方向。
- 存储成本随 SID 数线性增长:每用户 100 unique SID/user 是平均值;长尾用户兴趣可能跨更多 SID,导致存储开销不均匀。论文未提供存储的 worst-case 估计或 SID 数上限策略。
- Cold-start / 新 SID:codebook 是 weekly refresh,新出现的 item(尤其内容快速更迭的短视频/广告创意)需要等下周才能进入 KV 表。论文未详细讨论冷启动 fallback。
- 公开 dataset 与工业数据集的差异:XLong 仅 1k 序列,KuaiRec-Big 仅 2k 序列;10k scalability 仅在工业数据集上分析,公开复现门槛较高。
与已有工作的差异:相比 TWIN/SIM 的 "检索后精排" 两段式架构,UxSID 不做 retrieval 而做语义级 routing;相比 C-Former/LURM 的静态压缩,UxSID 在压缩输出和检索两端都引入 target SID 信号;相比生成式推荐(HSTU, MTGR, OneRec),UxSID 仍是判别式 ranking head,没有走 next-token 预测路线,但巧妙地把 SID(generative rec 的核心 token)借用为 ranking 阶段的语义查询键,为生成式与判别式 ranking 的混合架构提供了一个支点。
工业落地价值:在 Kuaishou 这种 400M 活跃用户、毫秒级 SLA 的真实场景中以 +0.337% Revenue 落地,证明 SID-based semantic routing 不是论文 trick 而是可工业化的 paradigm shift。对于已部署 generative recommender(如 OneRec-v2、QARM V2)的团队,复用 codebook 架构即可平滑集成 UxSID,是非常低成本的增益路径。