AsymRec: Asymmetric Generative Recommendation via Multi-Expert Projection and Multi-Faceted Hierarchical Quantization¶
一、研究动机与背景¶
1.1 生成式推荐的统一范式与残差量化¶
生成式推荐(Generative Recommendation, GenRec)把推荐重新表述为序列生成任务:每个物品 $i$ 通过一个语义编码器(如 OpenAI text-embedding-3-large 或多模态编码器)映射成高维连续嵌入 $x_i \in \mathbb{R}^d$,再用 RQ-VAE / 向量量化等手段将其离散为一段层次化的 Semantic ID(SID)ID($x_i$)。然后一个 Transformer 自回归地以历史交互 SID 序列为输入,预测下一物品的 SID。这条流水线对 long-range 依赖捕获、多模态信号集成都有友好的形式,是 TIGER [21]、HSTU [29]、RPG [8]、OneRec [3] 等近期工业落地工作的共同框架。
1.2 "对称量化"造成的双阶段信息瓶颈¶
AsymRec 的核心观察:现有 GenRec 模型对 SID 采用完全对称的使用方式——同一份离散 SID 序列既作为模型输入、又作为预测目标。这种对称性掩盖了 GenRec 中一个被严重忽视的双阶段信息瓶颈:
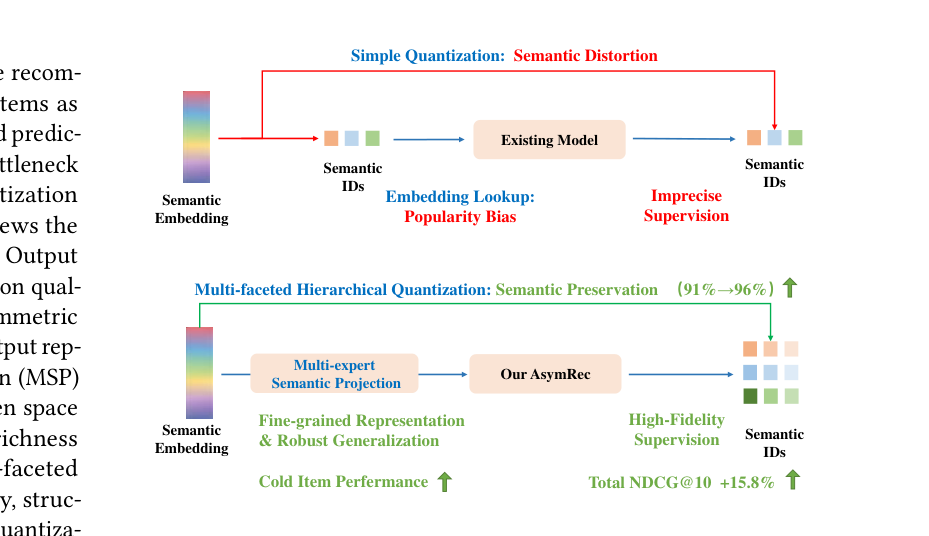
Input Bottleneck — Semantic Distortion + Popularity Bias.
传统做法把离散 SID 通过 lookup table 投影到 Transformer 隐空间。问题有两层:
- 量化本身不可逆地损失语义:连续 embedding $x_i$ 经 RQ-VAE 量化时丢弃了大量细粒度语义差异,从离散 token 反查 embedding 永远无法恢复原始表达力;
- 频次偏置:lookup table 的离散 ID embedding 在训练中按物品频次更新——热门物品其 SID 被反复"刷",长尾冷门物品的 SID 表征极度欠拟合。Figure 3(见后文实验)将这种偏置量化为"discrete-input baseline 在最低频物品桶上 Recall@10 反而显著高"——它把更多容量留给了 popular items。
直接的替代方案是"既然 SID 失真,那就用连续 embedding 作为 transformer 的目标"。但实证 Figure 4 显示:
Output Bottleneck — Imprecise Supervision or Dimensional Collapse.
若仍预测离散 SID,监督信号被简化的量化误差和"codebook collision"(不同物品被映射到相同 / 极相近 SID)严重稀释;但若改为直接回归连续 embedding,模型的输出表征会发生 dimensional collapse [9]——SVD-rank 从 178.1 跌到 99.5,输出分布被压扁到低维流形上,无法区分高精度差异。换言之:
| 输出形式 | 缺陷 |
|---|---|
| 离散 SID(粗粒度) | 监督不准确,含 codebook collision |
| 连续 embedding | dimensional collapse, lazy mean-vector solution |
结论:discrete output 是必须的,但要"高保真"的 discrete——既保留维度多样性,又能精确区分细粒度语义差异。
1.3 AsymRec 的设计哲学¶
针对 input 与 output 的不同"病灶",AsymRec 主张非对称(asymmetric) 表示:
- Input side:直接用连续 embedding $x_i$ 经一组 Multi-expert Semantic Projection(MSP) 投到 Transformer 隐空间,完全绕过离散 lookup,保留全部语义信号,并通过 MoE 把不同语义 facet 分给不同专家以平衡冷热物品;
- Output side:用 Multi-faceted Hierarchical Quantization(MHQ) 将 embedding 切到 $M$ 个子空间,每个子空间内做深度 $L$ 的残差量化(叠加 PQ + RQ 的几何性质),辅以 EMA codebook 更新、subspace 能量均衡、正交正则,得到高容量、抗 collapse 的离散 SID 作为预测目标。
这正是论文标题"asymmetric continuous-discrete framework"的来源:连续投影做输入、层次量化做监督,两端各取所长。
1.4 主要贡献¶
- 识别并量化分析了 GenRec 的双阶段信息瓶颈——给出 input 端 popularity bias(Figure 3)与 output 端 dimensional collapse(Figure 4)的实证证据;
- 提出 Multi-expert Semantic Projection(MSP):用 MoE-style 连续投影替代离散 ID lookup,保留语义拓扑、提升冷物品泛化;
- 提出 Multi-faceted Hierarchical Quantization(MHQ):结构化的 $M \times L$ 量化框架,结合 EMA codebook 更新和能量平衡 / 正交正则,提供高保真离散监督;
- 公开 + 工业双重验证:在四个 Amazon Review 子集上 NDCG@10 平均提升 15.8%,并在某世界级广告平台 pCVR 系统线上部署,A/B 取得 +1.4% 消耗 / +1.9% GMV。
二、相关工作梳理¶
2.1 生成式推荐演进¶
GenRec 从 ID-based 序列推荐(GRU4Rec、SASRec、BERT4Rec)跳出,转为基于物品多模态/文本嵌入的语义离散化。代表工作包括 TIGER(首个 RQ-VAE + Transformer 的 GR 流水线,引入 hierarchical SID)、HSTU(工业规模 GR 扩展定律)、RPG(latent path 生成)等。
2.2 Semantic ID 生成方法¶
SID 生成主要两类:
- Residual Quantization(RQ):迭代量化残差形成 coarse-to-fine 层次 codebook。优点是层次性自然适配 AR 生成;缺点是单一残差路径会出现 semantic entanglement——独立属性(品牌、品类、风格)被强行压入耦合 ID 序列;
- Product Quantization(PQ):把 embedding 切到独立子空间,每个子空间独立量化。优点是 multi-faceted;缺点是缺少 hierarchical depth——每个子空间只有一层 codebook,不像 RQ 那样能在同一 facet 上做 coarse-to-fine 渐进。
AsymRec 在 MHQ 中首次系统性地把二者合并:先切 $M$ 个 subspace,再在每个 subspace 内做深度 $L$ 的 RQ,从而同时获得 multi-faceted(M)+ hierarchical(L)双重结构。
三、问题定义与表示¶
给定用户交互序列 $\mathcal{S}_u = [I_1, I_2, \ldots, I_T]$,每个物品 $I_i$ 由连续语义嵌入 $x_i \in \mathbb{R}^d$ 表征。量化器把 $x_i$ 映射成离散 SID 集合 $\mathbf{ID}(x_i)$。目标是预测下一物品 $I_{T+1}$ 的 SID $\mathbf{ID}(x_{T+1})$。
值得注意的是:在 prior GenRec 工作中,只有离散 token 通过 lookup table 进入 transformer——连续 embedding $x_i$ 实际从未被显式使用。AsymRec 的关键转变就是要把 $x_i$ 重新挂回到输入侧。
四、核心方法¶
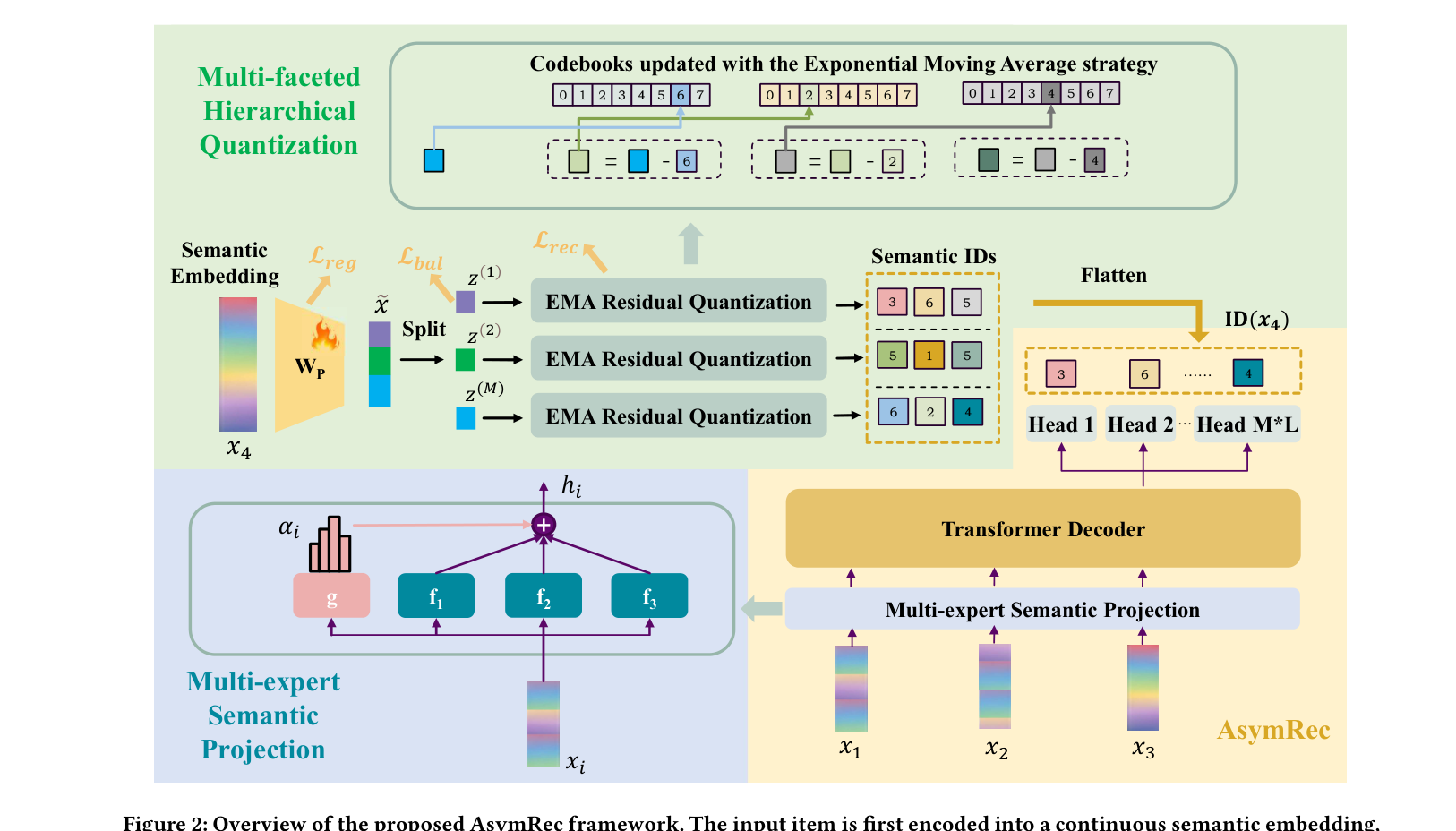
4.1 Multi-expert Semantic Projection(MSP)¶
4.1.1 设计动机¶
传统输入路径:
$$h_i^{\text{old}} = \text{Lookup}\bigl(\mathbf{ID}(x_i)\bigr)$$
只有 SID 经 lookup 进入模型,原始 $x_i$ 完全被丢弃。两个直接缺陷:
- 量化损失不可逆:连续 embedding 经 RQ-VAE 后无法恢复,模型再也看不到原始语义;
- 学习对热门 ID 严重偏置:lookup table 的更新频率与物品频次成正比,长尾物品 embedding 欠拟合。
MSP 用一组 MLP 专家 + gating 直接把 $x_i$ 投到模型隐空间 $\mathbb{R}^{d_m}$,完全绕过离散查表。
4.1.2 形式定义¶
$$h_i = \text{MSP}(x_i) \in \mathbb{R}^{d_m} \tag{1}$$
具体地,MSP 包含 $E$ 个 expert function $\{f_e(\cdot)\}_{e=1}^E$ 和一个 gating $g(\cdot)$:
$$h_i = \sum_{e=1}^{E} \alpha_{i,e}\,f_e(x_i),\quad \boldsymbol{\alpha}_i = g(x_i),\quad \sum_{e=1}^{E}\alpha_{i,e} = 1,\quad \alpha_{i,e}\ge 0. \tag{2}$$
$f_e(\cdot)$ 是 2 层 MLP,捕获物品语义的某一方面(如 brand / category / style 等);$g(x_i)$ 是 instance-aware gating,动态决定每个专家的权重,让不同物品激活不同的语义 facet 组合。
4.1.3 与 lookup 的根本差异¶
- 连续映射:拓扑结构(语义近的物品在 latent 上仍相近)被保留,对低频冷启动物品有利——它们能通过"邻居热门物品的更新"间接受益;
- 专家分工:MoE 允许不同物品落到不同专家的"擅长区",从根上抑制了"训练流量被热门主导"的退化路径。
4.2 Multi-faceted Hierarchical Quantization(MHQ)¶
MHQ 是 AsymRec 的另一支柱。给定 embedding $x \in \mathbb{R}^d$,MHQ 输出一段长度为 $M \times L$ 的多重 SID。
4.2.1 投影与子空间切分¶
先用可学习线性变换 $W_P \in \mathbb{R}^{D \times d}$ 把 $x$ 映到 latent 空间:
$$\tilde{x} = W_P x \in \mathbb{R}^D.$$
把 $\tilde{x}$ 切成 $M$ 个不相交子空间:
$$\tilde{x} = [z^{(1)}, z^{(2)}, \ldots, z^{(M)}],\quad z^{(m)} \in \mathbb{R}^{d_m} \tag{2}$$
其中 $d_m = D / M$。
4.2.2 子空间内残差量化¶
对每个 subspace $m$,维护深度 $L$ 的 codebook 集 $\{C^{(m,l)}\}_{l=1}^L$,每层 $C^{(m,l)} = \{c_k^{(m,l)}\}_{k=1}^K$,$K$ 是 codebook 大小。Residual quantization 过程:
$$i_{m,l} = \arg\min_{k\in\{1,\ldots,K\}} \bigl\| r_l^{(m)} - c_k^{(m,l)} \bigr\|_2^2 \tag{3}$$
初始 $r_1^{(m)} = z^{(m)}$;下一层残差 $r_{l+1}^{(m)} = r_l^{(m)} - c_{i_{m,l}}^{(m,l)}$。最终 subspace $m$ 的重构为 $\hat{z}^{(m)} = \sum_{l=1}^L c_{i_{m,l}}^{(m,l)}$。
4.2.3 EMA codebook 更新¶
为稳定离散优化,codebook 更新用 EMA 而非反向传播(避免梯度路径中的 straight-through estimator 噪声):
$$N_k^{(m,l)} \leftarrow \gamma N_k^{(m,l)} + (1-\gamma)\sum_{j=1}^{B}\mathbb{1}[i_{m,l}^{(i,j)} = k] \tag{4}$$
$$m_k^{(m,l)} \leftarrow \gamma m_k^{(m,l)} + (1-\gamma)\sum_{j=1}^{B}\mathbb{1}[i_{m,l}^{(i,j)} = k]\,r_l^{(m,j)} \tag{5}$$
$$c_k^{(m,l)} = \frac{m_k^{(m,l)}}{N_k^{(m,l)}} \tag{6}$$
$\gamma$ 是衰减因子(实验设 0.99),$B$ 是 batch size。这里 $N_k$ 记录每个 codeword 被命中次数,$m_k$ 记录命中残差之和,$c_k$ 即移动平均得到的新 codeword。
每个物品最终被表示为长度 $M \times L$ 的索引序列 $\mathbf{ID}(x) = \{i_{1,1}, i_{1,2}, \ldots, i_{M,L}\}$。
4.2.4 损失:重建 + 能量均衡 + 正交¶
(a) Reconstruction loss:
$$\mathcal{L}_{\text{rec}} = \bigl\| \tilde{x} - \text{concat}(\hat{z}^{(1)}, \ldots, \hat{z}^{(M)}) \bigr\|_2^2 \tag{7}$$
(b) Subspace energy balance:防止信息聚到少数 subspace。先算各子空间平均能量:
$$\bar{E} = \frac{1}{M}\sum_{m=1}^{M}\mathbb{E}\bigl[\|z^{(m)}\|_2^2\bigr] \tag{8}$$
再定义能量均衡损失:
$$\mathcal{L}_{\text{bal}} = \frac{1}{M}\sum_{m=1}^{M}\Bigl|\mathbb{E}\bigl[\|z^{(m)}\|_2^2\bigr] - \bar{E}\Bigr| \tag{9}$$
这个 $\ell_1$-style penalty 强制 $M$ 个 facet 信息量大致相当——避免几个 subspace 抢走主导信号,其它沦为冗余。
(c) Orthogonality regularization:让 $W_P$ 行向量近似正交,减少子空间间冗余:
$$\mathcal{L}_{\text{reg}} = \bigl\| W_P W_P^\top - I \bigr\|_F^2 \tag{10}$$
(d) 整体目标:
$$\mathcal{L}_{\text{MHQ}} = \mathcal{L}_{\text{rec}} + \lambda_{\text{bal}}\mathcal{L}_{\text{bal}} + \lambda_{\text{reg}}\mathcal{L}_{\text{reg}} \tag{11}$$
实验 $\lambda_{\text{bal}} = \lambda_{\text{reg}} = 0.01$。MHQ 仅在 tokenizer 阶段训练,之后冻结,用得到的 $\mathbf{ID}(x_i)$ 为下游 GR 提供监督目标。
4.3 AsymRec 整体架构¶
给定序列 $[x_1, \ldots, x_T]$,每个 $x_i$ 先经 MSP 投到 $h_i = \text{MSP}(x_i)$,加位置编码:
$$H^0 = [h_1 + p_1, h_2 + p_2, \ldots, h_T + p_T] \tag{12}$$
送入 $L_T$ 层 Transformer Decoder:
$$H^i = \text{Decoder}(H^{i-1}),\quad i = 1, \ldots, L_T \tag{13}$$
取最末位置最后一层的隐状态 $\mathbf{H}_T^{L_T} \in \mathbb{R}^{d_m}$,配 $M \times L$ 个并行预测头,第 $(m, l)$ 个头是一个 2 层 MLP,把 $\mathbf{H}_T^{L_T}$ 映为对 $K$ 个 codeword 的分类分布。所有头共享同一个 hidden state(low-cost multi-task),cross-entropy 在所有 $M \times L$ 头上求和:
$$\mathcal{L}_{\text{CE}} = -\frac{1}{ML}\sum_{m=1}^{M}\sum_{l=1}^{L}\log p\bigl(i_{m,l}^{T+1}\,\big|\,\text{model}(x_{\le T})\bigr) \tag{14}$$
推理时用图约束 beam search [8] 保证只生成 valid codeword 组合。
这一非对称设计的核心 elegance:MSP 把"连续 → 模型隐空间"的拓扑结构保护好,MHQ 把"模型隐空间 → 离散监督"的几何分散性保护好,两端共同抵御了对称 SID 表示带来的双阶段瓶颈。
五、实验设置¶
5.1 数据集¶
四个 Amazon Review 子集 [19]:
| Dataset | #Users | #Items | #Interactions | Avg $t$ |
|---|---|---|---|---|
| Sports & Outdoors | 18,357 | 35,598 | 260,739 | 8.32 |
| Beauty | 22,363 | 12,101 | 176,139 | 8.87 |
| Toys & Games | 19,412 | 11,924 | 148,185 | 8.63 |
| CDs & Vinyl | 75,258 | 64,443 | 1,022,334 | 14.58 |
按用户 review 时间排序,5-core 过滤(用户与物品至少 5 次交互)。
5.2 评估协议¶
Leave-one-out:每个用户最后一物品做 test,倒数第二做 validation,其余作训练。报告 Recall@$K$ 与 NDCG@$K$($K \in \{5, 10\}$)。所有结果取 val 上 NDCG@10 最优的 checkpoint 的 test 结果。
5.3 实现细节¶
- Semantic encoder:OpenAI text-embedding-3-large(沿用 Hou et al. [8]),$d = 3072$;
- MHQ 设置:量化后 $D = 512$,$\lambda_{\text{bal}} = 0.01$,$\lambda_{\text{reg}} = 0.01$,$\gamma = 0.99$,learning rate 0.001,50 epoch;
- AsymRec 设置:$E = 3$ 个专家,Transformer decoder $L_T = 2$ 层,$d_m = 448$;100 epoch,batch 256,lr 0.003。早停:val NDCG@10 在 20 epoch 内未改善则停;
- 超参搜索:$M \in \{8, 16, 32\}$,$L \in \{2, 3\}$,$K \in \{256, 512, 1024\}$;
- 冲突处理:Beauty 12,101 个 item 中产生 12,099 个 unique code,无需额外冲突消歧;
- 算力:单卡 RTX 3090 一小时即可在 Beauty 上完成。
六、主要实验结果¶
6.1 RQ1 — Overall Performance¶
Table 2 报告 AsymRec 与两类基线(Item ID-based 与 Semantic ID-based)在 4 个数据集上的表现:
| Model | Sports R@5 | Sports N@5 | Sports R@10 | Sports N@10 | Beauty R@5 | Beauty N@5 | Beauty R@10 | Beauty N@10 | Toys R@5 | Toys N@5 | Toys R@10 | Toys N@10 | CDs R@5 | CDs N@5 | CDs R@10 | CDs N@10 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Item ID-based | ||||||||||||||||
| Caser | 0.0116 | 0.0072 | 0.0194 | 0.0097 | 0.0205 | 0.0131 | 0.0347 | 0.0176 | 0.0166 | 0.0107 | 0.0270 | 0.0141 | 0.0116 | 0.0073 | 0.0205 | 0.0101 |
| GRU4Rec | 0.0129 | 0.0086 | 0.0204 | 0.0110 | 0.0164 | 0.0099 | 0.0283 | 0.0137 | 0.0097 | 0.0059 | 0.0176 | 0.0084 | 0.0195 | 0.0120 | 0.0353 | 0.0171 |
| HGN | 0.0189 | 0.0120 | 0.0313 | 0.0159 | 0.0325 | 0.0206 | 0.0512 | 0.0266 | 0.0321 | 0.0221 | 0.0497 | 0.0277 | 0.0259 | 0.0153 | 0.0467 | 0.0220 |
| BERT4Rec | 0.0115 | 0.0075 | 0.0191 | 0.0099 | 0.0203 | 0.0124 | 0.0347 | 0.0170 | 0.0116 | 0.0071 | 0.0203 | 0.0099 | 0.0326 | 0.0201 | 0.0547 | 0.0271 |
| SASRec | 0.0233 | 0.0154 | 0.0350 | 0.0192 | 0.0387 | 0.0249 | 0.0605 | 0.0318 | 0.0463 | 0.0306 | 0.0675 | 0.0374 | 0.0351 | 0.0177 | 0.0619 | 0.0263 |
| FDSA | 0.0182 | 0.0122 | 0.0288 | 0.0156 | 0.0267 | 0.0163 | 0.0407 | 0.0208 | 0.0228 | 0.0140 | 0.0381 | 0.0189 | 0.0226 | 0.0137 | 0.0378 | 0.0186 |
| S³-Rec | 0.0251 | 0.0161 | 0.0385 | 0.0204 | 0.0387 | 0.0244 | 0.0647 | 0.0327 | 0.0443 | 0.0294 | 0.0700 | 0.0376 | 0.0213 | 0.0130 | 0.0375 | 0.0182 |
| Semantic ID-based | ||||||||||||||||
| RecJPQ | 0.0141 | 0.0076 | 0.0220 | 0.0102 | 0.0311 | 0.0167 | 0.0482 | 0.0222 | 0.0331 | 0.0182 | 0.0484 | 0.0231 | 0.0075 | 0.0046 | 0.0138 | 0.0066 |
| VQ-Rec | 0.0208 | 0.0144 | 0.0300 | 0.0173 | 0.0457 | 0.0317 | 0.0664 | 0.0383 | 0.0497 | 0.0346 | 0.0737 | 0.0423 | 0.0352 | 0.0238 | 0.0520 | 0.0292 |
| TIGER | 0.0264 | 0.0181 | 0.0400 | 0.0225 | 0.0454 | 0.0321 | 0.0648 | 0.0384 | 0.0521 | 0.0371 | 0.0712 | 0.0432 | 0.0492 | 0.0329 | 0.0748 | 0.0411 |
| HSTU | 0.0258 | 0.0165 | 0.0414 | 0.0215 | 0.0469 | 0.0314 | 0.0704 | 0.0389 | 0.0433 | 0.0281 | 0.0669 | 0.0357 | 0.0417 | 0.0277 | 0.0638 | 0.0344 |
| RPG | 0.0314 | 0.0216 | 0.0463 | 0.0263 | 0.0550 | 0.0381 | 0.0809 | 0.0464 | 0.0592 | 0.0401 | 0.0869 | 0.0490 | 0.0498 | 0.0338 | 0.0735 | 0.0415 |
| AsymRec | 0.0371 | 0.0250 | 0.0550 | 0.0308 | 0.0618 | 0.0424 | 0.0901 | 0.0516 | 0.0658 | 0.0450 | 0.0971 | 0.0551 | 0.0614 | 0.0415 | 0.0902 | 0.0508 |
结论:AsymRec 在所有 4 个数据集 × 4 个 metric × 总共 16 个 cell 上全部最优;相对最强基线(绝大多数 cell 是 RPG)NDCG@10 平均提升 15.8%。这表明非对称设计在标准公开榜上是稳健且统一的赢家,而非依赖某个数据集的特性。
6.2 RQ2 — Continuous Input 的作用与冷启动泛化¶
6.2.1 Frequency-aware similarity 分析¶
为细看 input 端的影响,作者按物品频次分桶(0-2 / 3-5 / 6-8 / 9-11 / 12-17 / 18-29 / 30+):
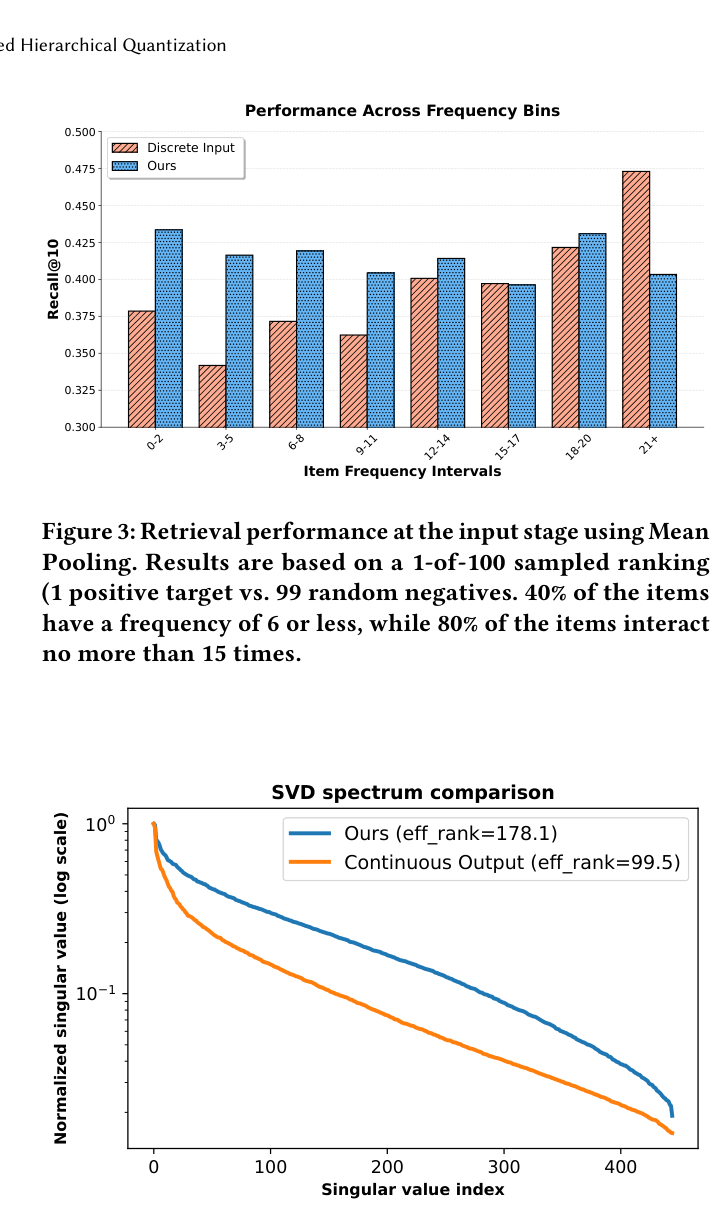
观察:
- Discrete Input baseline(用 SID lookup)在高频段(30+)取得最高 Recall@10,但在低频段(0-2、3-5)严重下滑——典型 popularity bias 形态;
- AsymRec 的 MSP 在低 / 中频段(0-2, 3-5, 6-8, 9-11, 12-17)一致更高,在 18-29 段持平或略低,仅在 30+ 段稍弱;
- 跨频次分布的方差远小于 baseline,说明 MSP 维持了语义拓扑结构、抑制了"训练流量主导更新"的偏置。
这一图实质上是对 input bottleneck 的可视化诊断:连续映射把低频物品从 popularity bias 的阴影中拉了出来。
Reciprocal Rank Fusion 探索:作者还尝试用 RRF 把 discrete-input 与 MSP 的 ranking 融合,NDCG@10 进一步从 0.0516 升到 0.0540——两种 input 路径具有互补性,未来工作可结合。
6.2.2 多专家 vs 单专家 baseline¶
为隔离"MoE 是否真有用"——可能性能提升只来自更大的参数预算?作者引入"single expert with E-times wider projection"作为更强 baseline(Row 3 of Table 3,N@10 = 0.0508)。结果:
- Single expert 已经 substantially 优于 discrete input(0.0491);
- Full MSP(0.0516)仍稍优于 single expert——多专家的复合 facet 表示有边际增益。
核心 take-away:连续 input 是主因(discrete → 任意 continuous 的飞跃最大),而 multi-expert 是 secondary refinement。
6.3 RQ3 — Discrete Output 必要性与 Dimensional Collapse¶
Row 4 of Table 3("w/ continuous embeddings as outputs"):把整套 pipeline 改为全连续——AsymRec 不再预测 SID 而是回归 embedding,N@10 跌到 0.0406,是 ablation 中下滑最严重的一行。原因被 SVD 分析坐实:
具体:
- Effective Rank(Shannon entropy of normalized SVD):continuous 99.5 vs discrete 178.1;
- 连续回归倾向 "lazy mean-vector" 解——预测近似平均的低维向量;
- 离散分类则强制 transformer 在 $M \times L$ 个超球面上保持区分度。
直接论断:在 GR 中直接回归连续输出会触发 dimensional collapse,离散监督是不可替代的正则项——这是 AsymRec 的一个有力理论支撑。
6.4 RQ4 — MHQ vs 标准 PQ 与 $(M, L)$ 扫描¶
Row 5 of Table 3("w/o MHQ" 用标准 PQ 替代)N@10 = 0.0494,远低于 AsymRec 的 0.0516。Figure 5 给出 $(M, L)$ 网格热图:
![Figure 5: NDCG@10 across (M, L) 配置。横轴 M ∈ {4, 8, 16, 32, 64, 128},纵轴 L ∈ {1, 2, 3, 4}。最佳区域在 M ∈ [16, 32], L ∈ [2, 3]。M·L > 128 不再带来增益](figures/fig_04.png)
实验观察:
- $M$ 从 4 增到 32 显著提升 N@10,64+ 时增益消失;
- $L$ 从 1 增到 3 持续改善,再加深度收益递减;
- MHQ 用更少 token 实现更高质量:$M = 8, L = 3$(24 个 token)→ N@10 = 0.0514,超过最优 PQ 配置 $M = 64, L = 1$(64 个 token,N@10 = 0.0494)。
结论:MHQ 不是单纯"堆更多 token",而是 subspace × hierarchical depth 的几何复合带来本质优势——每个 facet 内的层次量化提供 progressive refinement,每个 facet 间的 PQ 切分提供独立的语义维度,二者复合的容量曲线更优。
6.5 RQ5 — 工业 A/B 实验¶
部署于"世界级广告平台之一"的 post-click conversion rate(pCVR)系统。
特征来源(两路 high-dim 嵌入):
- Cross-domain Latent Factor Model:大规模跨域模型产出的通用 user-item embedding;
- Multimodal Alignment Embeddings:基于内部 multimodal LLM 通过 end-to-end 对比学习对齐的多模态特征。
集成方式:MHQ 把两路 embedding 压缩为 SID,再作为 high-level categorical feature 注入下游排序网络。联合训练目标:
$$\mathcal{L}_{\text{total}} = \mathcal{L}_{\text{pCVR}} + \lambda \mathcal{L}_{\text{rec}} \tag{15}$$
其中 $\mathcal{L}_{\text{rec}}$ 是 MHQ 重建损失,保证 SID 仍保留原 embedding 的核心信息。
A/B 结果:1% 流量 × 7 天,相比生产基线:
- 总消耗 +1.4%
- GMV +1.9%
GMV 提升大于消耗提升,说明非对称离散化让模型更精准捕获 high-value conversion 信号——asymmetric encoding 在广告投放量与转化质量的权衡上获得 Pareto 改善。
七、消融实验汇总¶
Table 3(Beauty 数据集 N@10):
| Row | Variant | N@10 |
|---|---|---|
| 1 | AsymRec (full) | 0.0516 |
| 2 | w/ discrete codes as inputs | 0.0491 |
| 3 | w/ only one expert as input | 0.0508 |
| 4 | w/ continuous embeddings as outputs | 0.0406 |
| 5 | w/o MHQ (use standard PQ) | 0.0494 |
逐项分析:
- Row 2 vs 1:去掉连续输入(即换回离散 SID lookup)→ 4.8% 相对下降。验证 MSP 的连续输入是核心增益来源;
- Row 3 vs 1:换成 single-expert(参数量等同 multi-expert)→ 1.5% 相对下降。说明 MoE 的多 facet 分工有额外贡献,但作用次于"continuous vs discrete"的 switch;
- Row 4 vs 1:连续输出 → 21.3% 相对下降。离散输出是必须的——dimensional collapse 严重伤害 ranking 质量;
- Row 5 vs 1:标准 PQ 替代 MHQ → 4.3% 相对下降,证明 hierarchical depth 在 facet 内带来的 progressive refinement 是真的有用。
八、与已归档相关工作的对比¶
CapsID CapsID: Soft-Routed Variable-Length Semantic IDs (—, 2026-05-06)¶
关系:独立并发(本文未引用 CapsID,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇都把 GenRec 的"信息瓶颈"压在 tokenizer/SID 这一步,并都驳斥了"打补丁 + dense 检索旁路"(patch route)的方案——希望靠改造 tokenizer 自身让 SID 同时满足语义充分、预测简洁、解码兼容三条不变式。
- 相近的技术骨架:两者都强调残差量化的硬最近邻是最大瓶颈。CapsID 用 soft capsule routing 在量化前先表达不确定性,把"路由后的加权重构"作为残差更新的真实差量;AsymRec 通过 MHQ 的多视角层次量化 + EMA codebook 缓解了 hard argmax 单残差路径的 entanglement,同时保留"离散输出"作为防 dim collapse 的强正则。
- 本文的差异与推进:CapsID 完全在 SID 离散端做文章(soft routing + 变长 SID + SemanticBPE),输入侧仍是 SID embedding;AsymRec 则把 input/output 完全解耦——MSP 在输入端用 continuous embedding 替代 SID lookup,从根上绕开 input 端的 popularity bias,再用 MHQ 把 output 端的离散保真度做大。这是一种非对称的设计选择,把 "tokenizer 改造" 的传统视角拓宽为 "input-side 投影 + output-side 量化" 的双路解耦。
- 可比的方法 / 实验差异:CapsID 在 Amazon Beauty 上 R@10 改善 8.9-11% vs 单表示 baseline;AsymRec 在 Beauty 取得 R@10 = 0.0901(基线最强 RPG 为 0.0809,提升 ~11.4%)。两者在量级上接近,但 CapsID 还附加了 35M item 工业规模验证 + 2× inference 加速,而 AsymRec 提供了广告 pCVR 系统的 +1.9% GMV A/B 验证。
CARD CARD: Non-Uniform Quantization of Visual Semantic Unit (UESTC, 2026-04-29)¶
关系:独立并发(本文未引用 CARD,两者攻击同一阶段的不同瓶颈)· 已加载对方精读
- 共同关注的问题:两者都聚焦于 GenRec 中"语义嵌入 → 离散 SID"的量化步骤,都意识到标准 RQ-VAE 假设隐空间均匀的隐含偏置会被推荐场景的非均匀分布破坏。CARD 称之为"codeword imbalance + generation bias",AsymRec 没有用同样的术语但 Figure 1 的 popularity bias 和 input bottleneck 描述的是同源现象——热门物品聚簇 + 长尾分散导致 codebook 利用不均。
- 相近的技术骨架:两者都试图在 RQ 路径外引入额外的几何重构:CARD 用可学习可逆非线性变换 $\mathcal{T}/\mathcal{T}^{-1}$ 把非均匀 latent 矫正到近似均匀空间再量化;AsymRec 用 MHQ 的多 subspace 切分 + subspace 能量均衡损失 $\mathcal{L}_{\text{bal}}$ 防止信息聚到少数 facet。前者从分布层面"拉平",后者从子空间层面"配平"——殊途同归。
- 本文的差异与推进:CARD 还引入了卡牌式 visual rendering 解决跨模态融合(这是 AsymRec 不涉及的部分);AsymRec 不做 multimodal rendering,但在量化结构上更激进——叠加 PQ 的 multi-faceted 与 RQ 的 hierarchical,并显式正交正则。一个值得注意的对比是:CARD 把"分布矫正"放在 单条 RQ 路径上;AsymRec 不矫正分布而是切多条独立路径,让每条路径只承担其语义 facet 的能量,从而绕开"全局非均匀"的问题。
- 可比的方法 / 实验差异:两者都在 Amazon 子集上做 leave-one-out 评估,但选用的子集略有差异(CARD 用 Clothing/Food,AsymRec 用 Beauty/Sports/Toys/CDs)。CARD 主打"少监督的多模态融合",AsymRec 主打"非对称表示 + multi-facet 量化",工业部署上一篇侧重 SID 质量,一篇侧重广告 pCVR 落地。
ComeIR ComeIR: Conditional Memory Enhanced Item Representation (CityU HK, 2026-05-12)¶
关系:独立并发(本文未引用 ComeIR,两者在 GenRec pipeline 的不同位置攻击"input-output 不一致")· 已加载对方精读
- 共同关注的问题:两者都明确点名 GenRec 的 input-output 不一致问题。AsymRec 关注的不一致是"input 是离散查表(损失语义)vs output 是离散监督(dim collapse 风险)",从"信息保真度"层面解读;ComeIR 关注的不一致是"input 是 item-level 压缩表征 vs output 是 token-level SID 生成",从"粒度匹配"层面解读。问题陈述虽不完全等同,但都呼吁修补"表征构造与生成预测之间的桥"。
- 相近的技术骨架:两者都意识到必须在 输入侧重新对接到原始信息,而不能只在 output 侧打补丁。ComeIR 用 MM-guided Token Scoring 把 quantizer 的多模态 embedding 重新接回输入;AsymRec 直接用 MSP 把连续 embedding 输给 transformer。两者也都强调 离散输出的不可替代性——ComeIR 维持 SID token-level autoregressive 预测,AsymRec 用 MHQ 的高保真离散监督防止连续输出的 collapse。
- 本文的差异与推进:ComeIR 选择"在表征接口上挂稀疏静态记忆 Engram + Memory-restoring Prediction Head",是一种外挂记忆式的桥;AsymRec 选择结构性非对称——不挂任何记忆,而是直接用 continuous input + multi-faceted discrete output 解耦双端。前者的代价是引入额外的离散 N-gram 哈希表(参数量增加但提供可学的离散先验),后者的代价是 input 端没有任何 SID-derived 离散结构(完全依赖 MoE 投影保留拓扑)。两条路径在精神上互补,未来或可叠加:用 MSP 的连续投影做 base input,再叠 Engram 记忆挂 SID-derived 离散先验。
- 可比的方法 / 实验差异:ComeIR 在 Yelp/Amazon-Industrial/Amazon-Instrument 三个数据集上对比"flatten / TM" baseline;AsymRec 在 Amazon Sports/Beauty/Toys/CDs 上对比 RPG/TIGER/HSTU 等强 GR baseline。两者数据集只在 Amazon 一族上重合(但具体子集不同),无法做严格的 head-to-head,但 ComeIR 报告 H@5 平均提升 7.91-8.06%(vs TM),AsymRec 报告 NDCG@10 平均提升 15.8%(vs SOTA GR baseline)——量级与方向一致。
九、核心贡献总结¶
AsymRec 的最大贡献是把"Semantic ID 是否还要被原原本本地用作输入"这一长期被默认的假设挑了出来,并通过:
- MSP(continuous + MoE projection)解构 input 端的 popularity bias 与 quantization loss;
- MHQ(PQ × RQ × EMA × balance + orthogonality)让 output 端的离散监督保持高维度多样性,避免 representation collapse;
- 4 个公开数据集 NDCG@10 平均 +15.8% 的强一致改进 + 工业广告 pCVR 系统 +1.9% GMV 的线上验证。
这种"input continuous, output discrete"的非对称设计可能对 GenRec 的下一波研究有方法论指导意义——它揭示了"discrete-everywhere"的范式选择本身就是性能瓶颈。
十、讨论与局限性¶
10.1 值得借鉴的设计¶
- Asymmetric continuous-discrete framing 本身就是可迁移的思想:在任何 "encoder→tokenizer→generator" 的级联中,是否可以放弃 tokenizer 在 input 侧的位置?这一思路未必只适合 GenRec——多模态生成、document retrieval 等场景都可能套用;
- MHQ = PQ × RQ × EMA × balance × orthogonality 是当前 SID 工作里少见的结构化复合量化,每一条 regularization 都有针对性(reconstruction 保信息、balance 反塌陷、orthogonality 减冗余、EMA 稳优化),可作为未来 SID 设计的 cookbook;
- 冷热物品的 input 端检验法:把 input 端单独做 mean-pooling + 1-of-100 retrieval 评估,按 frequency bin 切分 Recall(Figure 3 的方法),是一种廉价但有诊断力的工具——可被其他 GR 工作直接采纳。
10.2 局限与争议¶
- 没有完全释放 MSP × Discrete-input 互补性:作者已注意到 RRF 融合可进一步把 N@10 从 0.0516 推到 0.0540,但说"留作未来工作"——这意味着当前 AsymRec 并非 input 端的最终态;
- 工业 A/B 仅在 pCVR / 广告排序场景:MHQ 在 A/B 中是作为辅助 categorical feature 而非主预测目标——这与公开数据集上的 next-item generative retrieval 设定本质不同。即"AsymRec 在生成式推荐的工业落地"还缺少直接证据;
- OpenAI text-embedding 依赖:semantic encoder 用 OpenAI text-embedding-3-large,这在很多场景下(隐私、成本、可控性)不可用。MSP 的连续映射效果是否对 encoder 质量高度敏感?论文没有 ablation 给出答案;
- codebook collision 报告偏乐观:Beauty 数据集 12,101 items → 12,099 unique codes,几乎无 collision 是因为 $M \times L = 24$ × $K = 256$ 提供了远大于 item 数的 code 空间。但工业级 1B 物品场景下 collision 率与冲突解决策略文中并未讨论;
- Code 未开源:abstract 承诺"The code will be released",但截至写本精读时未见开源——复现门槛较高。
10.3 与已有工作的差异 — 总结表¶
| 工作 | Input 端 | Output 端 | 核心 trick |
|---|---|---|---|
| TIGER / HSTU / RPG | Discrete SID (lookup) | Discrete SID | RQ-VAE / parallel codes |
| CapsID | Discrete SID (capsule) | Discrete SID | Soft routing + variable length |
| CARD | Discrete SID | Discrete SID | NU-RQ-VAE (invertible transform) |
| ComeIR | Compressed SID + memory | Discrete SID + memory head | Engram memory bridge |
| AsymRec | Continuous + MoE | Multi-faceted hierarchical SID | Asymmetric continuous-discrete |
可以看到,AsymRec 是这批 2026 春季 GenRec tokenizer/representation 工作里唯一彻底放弃 input-side SID 的——这是它最 distinctive 的设计选择,也是 NDCG@10 +15.8% 的最主要来源。
10.4 后续可能的研究方向¶
- 更强的 input 端融合:MSP + Discrete-SID 双路 RRF 是论文留下的未完成工作,值得系统化;
- 多模态 + 非对称:CARD 的卡牌式渲染 + AsymRec 的非对称设计能否叠加?理论上互补;
- 大规模 SID 空间下的非对称设计:在 $M \times L \gt 100$ 的 industrial scale 上,连续输入是否仍能保持泛化?这是 OneRec 等工业 GR 系统亟需的验证;
- Asymmetric paradigm for non-RecSys generative tasks:DocRetrieval、QA、code generation 等场景是否同样适用?AsymRec 提出的"discrete only where it must be"原则可能有更广的适用边界。