Echoes in Filter Bubble: Diagnosing and Curing Popularity Bias in Generative Recommenders¶
研究动机与背景¶
生成式推荐与"过滤气泡"¶
生成式推荐(Generative Recommenders, GRs)以 SID(Semantic ID)+ LLM 自回归生成的统一框架重塑推荐范式。借助 LLM backbone,TIGER、LETTER、LC-Rec、ED² 等 SOTA GR 系统在 sequential recommendation 上取得了显著收益。但本文指出:当前 GR 仍被严重的流行度偏差(popularity bias)困扰,呈现为典型的"回音壁式 filter bubble"——热门 item 在推荐列表中占据绝大部分曝光,长尾高质量内容被严重边缘化。
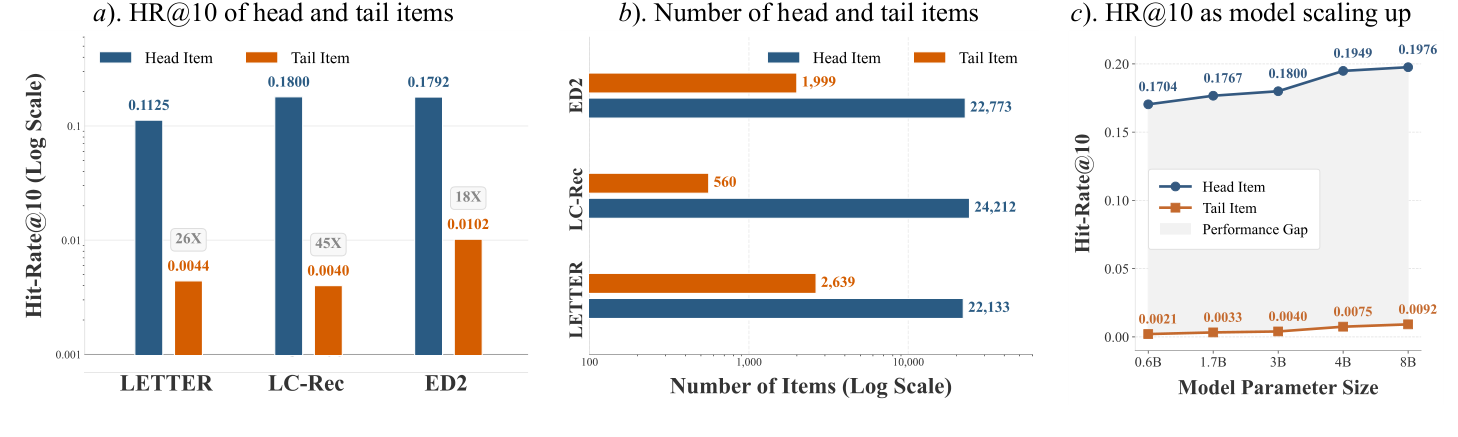
作者在 Instruments、Arts、Games 三个 Amazon 数据集上对三款 SOTA GR(LETTER、LC-Rec、ED²)做了实证度量:
- HR@10 差距悬殊(图 1a):head 与 tail item 的 hit-rate 差距高达 18×–45×,例如 LC-Rec 在 LETTER 设定下 head/tail HR@10 = 0.1800 / 0.0040;
- 推荐列表组成极度失衡(图 1b):超过 97% 的推荐 slot 被 head item 占据,LC-Rec 仅检索到 560 个 tail 而检索 24,212 个 head;
- 模型 scaling 不能自愈(图 1c):将 LC-Rec backbone 从 0.6B 扩到 8B,head/tail 性能差距并未自动收敛——大模型并没有"长出"长尾能力。
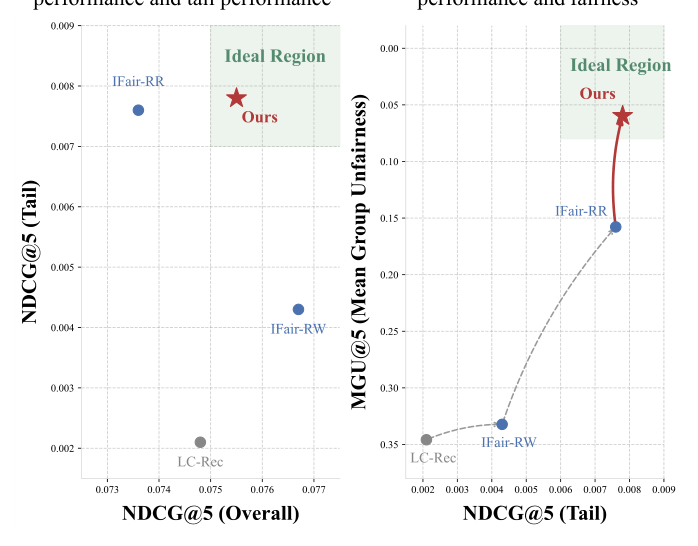
更糟糕的是,传统的 popularity debiasing 方法(IFairLRS-RW、IFairLRS-RR 等)迁移到 GR 上时效果非常有限(图 2):要么 NDCG(Tail)/ NDCG(Overall)的 trade-off 不理想,要么 fairness(MGU)与 performance 难以同时达到 ideal region。这说明GR 上的流行度偏差不能简单照搬 discriminative paradigm 的去偏方案——它有 GR 自身的结构性根因。
两个尚未被解决的"GR-原生"问题¶
GR 与 discriminative recommender 相比有两个独有特征:(i) 端到端的 generative framework(用 MLE 在 SID 序列上做 next-token prediction);(ii) 基于 SID 的 item tokenization(用 RQ-VAE / RQ-KMeans 量化 item 语义 embedding)。本文从这两个特征出发各识别出一个被现有去偏工作完全忽略的"root cause":
- MLE 优化下 tail token 的 Gradient Starvation:在长尾交互分布中,tail item token 几乎永远充当 softmax 的"trivial negative"——它们极少作为 ground-truth target 出现以接收正梯度,反而长期被 softmax 分母里的非自身概率"反向推开"。其 token embedding 被系统性地推离用户偏好空间。
- Undifferentiated Tokenization 下的 Bias Amplification:标准 RQ-VAE / RQ-KMeans 对 head 与 tail item 同等对待——head 与 tail 的 SID 共享前缀的步数完全随机,每个 GR 在自回归生成 tail item SID 时都要在多个不可预测的 branching point 上与 head item 候选 token 竞争。每次竞争都被 head dominance 几何放大一次,整段生成过程中的 bias 被 multi-step 累积。
作者把这两个洞察拧在一起,提出 Ghost = Generative recommender with asymmetric unlikelihood optimization and skeleton-founded tokenization。"Ghost" 既是模型名缩写,也呼应"过滤气泡里的回响"这一标题意象。
主要贡献¶
- 诊断:首次从理论上提出"GR 上流行度偏差的两个根因"——MLE gradient starvation + undifferentiated tokenization 的 bias amplification,并给出 4 个引理的严格证明;
- 方法:提出 Ghost,由 AUO(Asymmetric Unlikelihood Optimization)与 SKT(Skeleton-Founded Tokenization)两个组件组成,前者通过 unlikelihood 惩罚 rescue tail token gradient,后者通过 head/tail 异步分配 SID 把多个 branching point 折叠成单一可预测 step;
- 实证:在 3 个 Amazon 数据集上对比 7 个 baseline,Tail HR/NDCG 平均提升 63.91% / 70.66%(最高 +57.24%),MGU 平均降低 55.76%,CNS 平均增益 16.81%(最高 +22.06%),同时 Overall HR/NDCG 仅下降 7.46% / 6.34%。
形式化 Preliminary¶
问题设定¶
序列推荐:$K$ 个 item $\{v_k\}_{k=1}^K$ 与 $J$ 个用户 $\{u_j\}_{j=1}^J$,用户 $u_j$ 的历史为 $h_{u_j} = [v_{k_1}, \ldots, v_{k_l}]$,目标是预测下一个 item。
SID-Based GR Pipeline¶
对每个 item $v$,用 textual encoder 得到表示 $X_v$,再用 RQ-VAE 等向量量化把 $X_v$ 映射为 $L$ 层 SID $\Omega_v = (c_v^{(1)}, c_v^{(2)}, \ldots, c_v^{(L)})$:
$$ c_v^{(i)} = \arg\min_{n \in \{1,2,\ldots,N\}} \|r_v^{(i)} - \mu_n^{(i)}\|_2^2, \quad r_v^{(i+1)} = r_v^{(i)} - \mu_{c_v^{(i)}}^{(i)}, \quad i = 1, \ldots, L \tag{1} $$
其中 $\{\mu_n^{(i)}\}_{n=1}^N$ 是第 $i$ 层 codebook,$r_v^{(1)} = X_v$。Recommendation 任务被改写为 SID 序列生成,标准 MLE/NLL 损失:
$$ \mathcal{L}_{\text{NLL}} = -\sum_i \log \mathcal{P}_\theta(c_v^{(i)} \mid h_u, c_v^{\lt i}) \tag{2} $$
Popularity Bias 与 Pareto Optimality¶
按 [16,27] 的惯例,把交互频次 top 20% 的 item 划为 head set,其余 80% 为 tail set。Popularity bias 指算法系统性地偏向 head item。多目标 trade-off 用 Pareto optimality 形式化:若不存在严格支配解 $s'$ 使得 $\forall m, f_m(s) \le f_m(s')$ 且至少一个不等式严格成立,则 $s$ 为 Pareto optimal。Ghost 的目标是同时优化 overall performance、tail performance、fairness 三个相互冲突的指标,逼近 ideal region。
诊断:GR 流行度偏差的两个根因¶
A. MLE 优化的 Gradient Starvation¶
在 inner-product softmax 下,$\mathcal{L}_{\text{NLL}}$ 对任意候选 token embedding $e_c$ 的梯度为:
$$ \frac{\partial \mathcal{L}_{\text{NLL}}^{(i)}}{\partial e_c} = \left( \mathcal{P}_\theta(c \mid h_u, c_v^{\lt i}) - \mathbb{I}\{c = c_v^{(i)}\} \right) X_{h_u} \tag{25} $$
对整个训练分布 $\mathcal{D}$ 取期望,得到 LEMMA 1:
LEMMA 1(MLE 下的 Gradient Starvation). 对任意 SID token $c$,
$$ \mathbb{E}_{\mathcal{D}}[\Delta e_c] \propto \mathbb{E}_{\mathcal{D}}\left[ \sum_i \left( \mathbb{I}\{c = c_v^{(i)}\} \cdot (1 - \mathcal{P}_\theta(c \mid h_u, c_v^{\lt i})) - \mathbb{I}\{c \neq c_v^{(i)}\} \cdot \mathcal{P}_\theta(c \mid h_u, c_v^{\lt i}) \right) X_{h_u} \right] \tag{3} $$
而对于 tail-specific token $c_{\text{tail}}$,因为它在训练分布中作为 ground-truth target 的概率几乎为零($\mathbb{P}_{\mathcal{D}}(c_{\text{tail}} = c_v^{(i)}) \approx 0$),指示函数项几乎不激活,导致:
$$ \mathbb{E}_{\mathcal{D}}\big[\langle \Delta e_{c_{\text{tail}}}, X_{h_u} \rangle\big] \approx -\mathbb{E}_{\mathcal{D}}\left[ \sum_i \mathcal{P}_\theta(c_{\text{tail}} \mid h_u, c_v^{\lt i}) \cdot \|X_{h_u}\|_2^2 \right] \le 0 \tag{4} $$
结论:tail token 的 embedding 与用户偏好向量 $X_{h_u}$ 的内积期望被持续推向负方向——它们沦为 softmax 分母里的"reviewer",从未获得有意义的正向梯度。这就是经典的 Gradient Starvation [31] 现象在 GR 上的具体形态。
B. Undifferentiated Tokenization 下的 Bias Amplification¶
LEMMA 1 揭示了单一 token 上的 unfair update;但 GR 是 multi-token 自回归生成,因此还需要分析这种 token-level bias 如何在生成路径上传播。
COROLLARY 1(Branching Point 处的 Head Token Dominance). 在第 $i$ 步若 head token $c_{\text{head}}^{(i)}$ 与 tail token $c_{\text{tail}}^{(i)}$ 同时作为候选竞争(branching point),
$$ \frac{\mathcal{P}_\theta(c_{\text{head}}^{(i)} \mid h_u, c^{\lt i})}{\mathcal{P}_\theta(c_{\text{tail}}^{(i)} \mid h_u, c^{\lt i})} = \gamma_i \cdot \frac{\mathcal{P}_d(c_{\text{head}}^{(i)} \mid h_u, c^{\lt i})}{\mathcal{P}_d(c_{\text{tail}}^{(i)} \mid h_u, c^{\lt i})}, \quad \gamma_i \gt 1 \tag{5} $$
即生成概率比相对真实数据分布 $\mathcal{P}_d$ 偏离一个 $\gamma_i \gt 1$ 的 local amplification factor。
更关键的是:在 undifferentiated tokenization 下,tail item SID 与多个 head item SID 共享长度不一的前缀,因此在生成 tail SID 的过程中会遇到一连串这种 branching point。
LEMMA 2(Bias Amplification via Undifferentiated Tokenization). 设 $\mathcal{Z}$($|\mathcal{Z}| = z \le L$)为 tail item $v_{\text{tail}}$ 生成过程中与 head candidate 竞争的所有 branching step 集合,则
$$ \mathcal{P}_\theta(v_{\text{tail}} \mid h_u) = \prod_j \mathcal{P}_\theta(c_{\text{tail}}^{(j)} \mid h_u, c^{\lt j}) \le (\gamma_{\min})^{-z} \prod_j \mathcal{P}_d(c_{\text{tail}}^{(j)} \mid h_u, c^{\lt j}) \tag{6} $$
其中 $\gamma_{\min} = \min_{j \in \mathcal{Z}}(\gamma_j) \gt 1$。
结论:tail item 的整体生成概率相对真实数据分布被几何压制 $\mathcal{O}(\gamma_{\min}^{-z})$——单 step 的 bias 在自回归生成中被 multi-step 几何累积。Bias amplification 来自两个相乘项:(i) token-level 的 $\gamma$(LEMMA 1);(ii) 多步累积的 $z$(undifferentiated tokenization 制造的混乱 branching)。这正是 Ghost 要从两端同时治理的对象。
核心方法 / 模型架构¶
Ghost 由两个核心组件组成:Skeleton-Founded Tokenization (SKT) 治理 $z$,Asymmetric Unlikelihood Optimization (AUO) 治理 $\gamma$。整体架构:
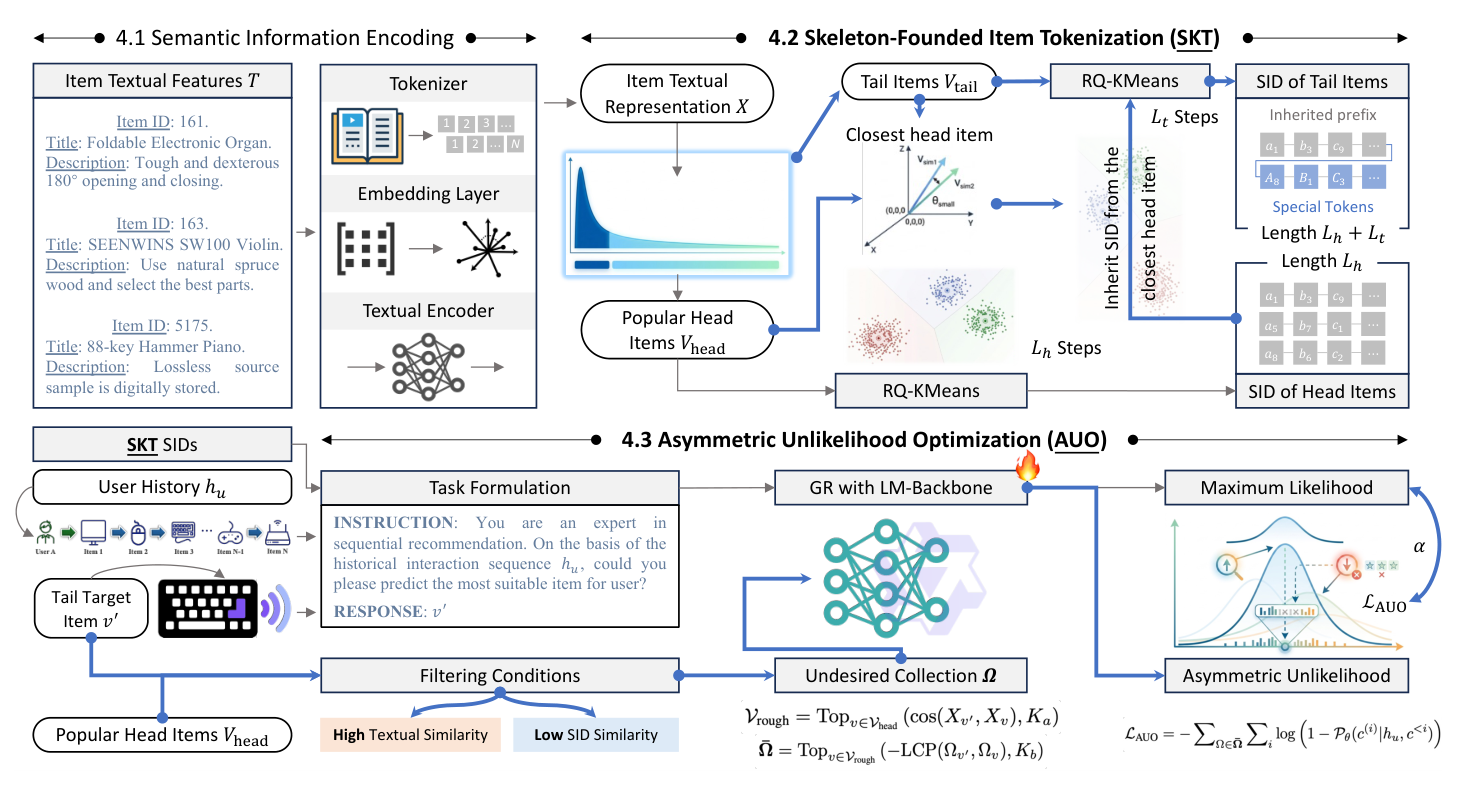
A. Skeleton-Founded Tokenization (SKT)¶
核心思想:把 head item 的 SID 当作整个 SID 空间的"骨架",让 tail item 强制继承 其最近 head item 的前缀,再额外生成 tail-specific 的尾部 token。这样 head/tail 的 branching point 被收缩到唯一可预测的一步。
Step 1 — Head SIDs:对 head item 集合 $\mathcal{V}_{\text{head}}$,应用标准 RQ-KMeans 生成 $L^h$ 长 SID:
$$ c_v^{(i)} = \arg\min_{n \in \{1, \ldots, N\}} \|r_v^{(i)} - \mu_n^{(i)}\|_2^2, \quad r_v^{(i+1)} = r_v^{(i)} - \mu_{c_v^{(i)}}^{(i)}, \quad i = 1, \ldots, L^h \tag{7} $$
得到 $\Omega_v = (c_v^{(1)}, \ldots, c_v^{(L^h)})$,$r_v^{(1)} = X_v$。
Step 2 — Tail 继承:对 tail item $v' \in \mathcal{V}_{\text{tail}}$,找到与其表征 $X_{v'}$ 余弦相似度最高的 head item $v^*$:
$$ v^* = \arg\max_{v \in \mathcal{V}_{\text{head}}} \cos(X_{v'}, X_v) $$
Tail item $v'$ 直接继承 $v^*$ 的 $L^h$ 个 SID token:$(c_{v^*}^{(1)}, \ldots, c_{v^*}^{(L^h)})$ 作为 prefix。
Step 3 — Tail 特异 token:基于继承的 prefix,再额外生成 $L^t$ 个 tail-specific token:
$$ c_{v'}^{(j)} = \arg\min_{n \in \{1, \ldots, N\}} \|r_{v'}^{(j)} - \mu_n^{(j)}\|_2^2, \quad r_{v'}^{(j+1)} = r_{v'}^{(j)} - \mu_{c_{v'}^{(j)}}^{(j)}, \quad j = 1, \ldots, L^t \tag{8} $$
但残差初始化与 head SID 不同——这里 $r_{v'}^{(1)} = X_{v'} - \sum_i \mu_{c_{v^*}^{(i)}}^{(i)}$(即先扣掉 $v^*$ 已经"消化"的量化残差)。
最终 tail item 的 SID 长度为 $L^h + L^t$:
$$ \Omega_{v'} = (c_{v^*}^{(1)}, \ldots, c_{v^*}^{(L^h)}, c_{v'}^{(1)}, \ldots, c_{v'}^{(L^t)}) $$
注:head item SID 长度为 $L^h$,tail item SID 长度为 $L^h + L^t$。head item 在第 $L^h+1$ 位输出 EOS(end-of-sequence)token,tail item 在第 $L^h+1$ 位输出其第一个 tail-specific token。整个 head/tail 区分被收缩到这一个 step 上。
理论保证(LEMMA 3 — Mitigation of Bias Amplification):在 SKT 下,tail item $v'$ 与最近 head item $v^*$ 共享前 $L^h$ 个 token,没有 branching;branching 唯一发生在第 $L^h+1$ 位(tail token vs head 的 EOS token)。LEMMA 2 中的 $z$ 被压到 1:
$$ \mathcal{P}_\theta(v' \mid h_u) = \prod_{j=1}^{L^h + L^t} \mathcal{P}_\theta(c_{v'}^{(j)} \mid h_u, c^{\lt j}) \approx (\gamma_{\text{EOS}})^{-1} \prod_{j=1}^{L^h + L^t} \mathcal{P}_d(c_{v'}^{(j)} \mid h_u, c^{\lt j}) \tag{12} $$
即 multi-step 的几何压制 $\mathcal{O}(\gamma_{\min}^{-z})$ 被坍缩为 single-step 的常数偏离 $\mathcal{O}(\gamma_{\text{EOS}})$。
设计直觉:把 head item 的 SID 空间视为"骨骼",tail item 在骨骼旁边长出"血肉" $L^t$ token——既维持了"语义相近的 item 应共享 SID 前缀"这一 SID-based GR 基本原则,也极大减少了 head/tail 的混乱竞争。同时通过 $L^t$ 个 tail-specific token 注入足够容量来表达 tail item 相对其 head anchor 的细粒度差异。
B. Asymmetric Unlikelihood Optimization (AUO)¶
SKT 解决了 $z$,但单点 $\gamma$ 还在。AUO 用 unlikelihood training [32,33] 的思想给 tail token 主动注入正向梯度。
关键设计:标准 unlikelihood 是对称的(对所有生成 token 都加惩罚);AUO 是 asymmetric 的——只对 head item 的某些 token 加惩罚,从而通过 softmax 的耦合效应把"被压低的 head 概率质量"转移到 tail token 上。
Undesired Collection 构造:对每个 tail target $v'$,构造头条干扰集 $\bar{\Omega}_{v'}$,其元素是与 $v'$ 高文本相似度但 SID 路径完全分叉的 head item——它们是模型最容易"误推荐"的 popular distractor:
$$ \mathcal{V}_{\text{rough}} = \text{Top}_{v \in \mathcal{V}_{\text{head}}}\bigl(\cos(X_{v'}, X_v), K_a\bigr) \tag{10a} $$
$$ \bar{\Omega}_{v'} = \text{Top}_{v \in \mathcal{V}_{\text{rough}}}\bigl(-\text{LCP}(\Omega_{v'}, \Omega_v), K_b\bigr) \tag{10b} $$
其中 LCP 是 Longest Common Prefix。先从 head 池里按文本相似度挑出 $K_a$ 个候选,再从候选里挑出 SID 前缀差异最大的 $K_b$ 个作为"危险的语义相似但 SID 路径不一致"的 head distractor。论文默认 $K_a = 200$,$K_b = 5$。
AUO Loss:对 $\bar{\Omega}_{v'}$ 中所有 head item 的 SID token 施加 unlikelihood 惩罚:
$$ \mathcal{L}_{\text{AUO}} = -\sum_{\Omega \in \bar{\Omega}} \sum_i \log\bigl(1 - \mathcal{P}_\theta(c^{(i)} \mid h_u, c^{\lt i})\bigr) \tag{9} $$
总目标:
$$ \mathcal{L}_{\text{All}} = \mathcal{L}_{\text{NLL}} + \alpha \cdot \mathcal{L}_{\text{AUO}} \tag{11} $$
$\alpha$ 是 AUO 权重,论文最优值 0.1。
Gradient Rescue 机制(LEMMA 4):AUO 通过 softmax 的 Jacobian 把"对 head token 的惩罚"转换为"对其他 token(包括 tail target)的正向梯度提升"。
对 false positive head token $c_{\text{head}}^- \in \bar{\Omega}$:
$$ \Delta e_{c_{\text{head}}^-} \propto -\underbrace{(1+\alpha)\mathcal{P}_\theta(c_{\text{head}}^-) X_{h_u}}_{\text{Targeted Repulsion}} + \alpha \sum_{c_j \in \bar{\Omega} \setminus \{c_{\text{head}}^-\}} \underbrace{\frac{\mathcal{P}_\theta(c_j)\mathcal{P}_\theta(c_{\text{head}}^-)}{1 - \mathcal{P}_\theta(c_j)} X_{h_u}}_{\text{Cross-Penalization Offset}} \tag{13} $$
对 target tail token $c_{\text{tail}}$(不在 $\bar{\Omega}$ 内):
$$ \Delta e_{c_{\text{tail}}} \propto \underbrace{-\mathcal{P}_\theta(c_{\text{tail}}) X_{h_u}}_{\text{MLE Push (negative)}} + \alpha \sum_{c_j \in \bar{\Omega}} \underbrace{\frac{\mathcal{P}_\theta(c_j)\mathcal{P}_\theta(c_{\text{tail}})}{1 - \mathcal{P}_\theta(c_j)} X_{h_u}}_{\text{AUO Rescue (positive)}} \tag{14} $$
直觉:AUO 在 head distractor 上"按下"概率,但 softmax 是归一化操作——按下一处必抬起别处。Tail token 因为不在被惩罚集合里,得到了纯净的正向 rescue gradient,从而 escape gradient starvation。同时 head distractor 被显式 repulsion 压低,避免了 over-recommendation。这就是"asymmetric"的精髓——unlikelihood 只施加给 head,让其概率被让出来分给 tail。
附记:AUO 不是"用 unlikelihood 替代 MLE",而是 "MLE + Asymmetric Unlikelihood 双驱"。两者通过 softmax 耦合实现协同——MLE 学习正向 target,AUO 主动施压 popular distractor,两端共同把 tail token 拉离 starvation trap。
关键技术细节¶
- Textual encoder:item title + description 通过预训练 textual encoder → embedding $X_v$;series of linear layers
[4096, 2048, 1024, 512, 256, 128, 64]将 Qwen 表征降到 32 维供 RQ-KMeans 使用; - RQ-KMeans codebook:每层 256 个 cluster,head 与 tail 共享相同的 codebook size 设置;
- SID 长度:$L^h \in \{3, 4, 5\}$、$L^t \in \{1, 2, 3\}$,head SID 长度 $L^h$,tail 长度 $L^h + L^t$。论文默认 $L^h = 3$、$L^t = 2$;
- Undesired collection:$K_a = 200$(rough candidates),$K_b = 5$(final undesired set),collection 静态预计算(不在训练中动态更新——见 Limitations);
- Backbone:Qwen2.5-3B(hidden dim 2048)作为主实验 backbone;scaling 用 Qwen3 系列(0.6B / 1.7B / 4B / 8B);
- Optimizer:AdamW,learning rate $3 \times 10^{-5}$,4 epoch;
- AUO 权重:$\alpha = 0.1$;
- 硬件:8× NVIDIA A100 80GB。
实验设置¶
数据集¶
来自 Amazon Product Review,包含 Musical Instruments (Ins)、Arts/Crafts/Sewing (Arts)、Video Games (Games) 三个 category。Inactive user/item 5-core 过滤,时序顺序 split。统计:
| Dataset | #User | #Item | #Interaction | Sparsity | Avg.L |
|---|---|---|---|---|---|
| Instruments | 24,772 | 9,922 | 206,153 | 99.92% | 8.32 |
| Games | 50,546 | 16,859 | 452,989 | 99.95% | 8.96 |
| Arts | 45,141 | 20,956 | 390,832 | 99.96% | 8.66 |
三者均呈严重 long-tail 分布。
Baseline¶
- 标准 GR:LETTER、LC-Rec、ED²
- Popularity debiasing:
- Augmentation:把热门 item 在序列中按概率 $p=0.375$ 替换为最相似的 tail item,并把替换后的序列追加到训练集(保留原序列);
- Substitution:同样替换但覆盖原序列;
- IFairLRS-RW:reweighting;
- IFairLRS-RR:re-ranking
评估指标¶
-
HR@K(Hit-Rate): $$ \text{HR}@K = \frac{1}{|U_{\text{test}}|} \sum_{u \in U_{\text{test}}} \mathbb{I}(\mathcal{V}_u \cap L_u^{(K)} \ne \emptyset) \tag{16} $$
-
NDCG@K: $$ \text{NDCG}@K = \frac{1}{|U_{\text{test}}|} \sum_u \frac{\text{DCG}_u@K}{\text{IDCG}_u@K}, \quad \text{DCG}_u@K = \sum_{i=1}^{K} \frac{r_{u,i}}{\log_2(i+1)} \tag{17, 18} $$
-
MGU(Mean Group Unfairness): $$ \text{MGU} = \frac{\text{GU}_{\text{head}} + \text{GU}_{\text{tail}}}{2}, \quad \text{GU}_G = \text{GR}_G - \text{GH}_G \tag{19} $$
-
ARP(Average Recommendation Popularity):推荐 item 在训练集中的平均出现次数;
- CNS(Comprehensively Normalized Score):综合得分,Min-Max 归一化后取均值 $$ \text{CNS} = \bigl(\overline{\text{HR}}_{\text{All}} + \overline{\text{HR}}_{\text{Tail}} + \overline{\text{NDCG}}_{\text{All}} + \overline{\text{NDCG}}_{\text{Tail}} + \overline{\text{MGU}} + \overline{\text{ARP}}\bigr)/6 \tag{15} $$ 所有 HR/NDCG 报告 Overall 与 Tail 两套(Tail 指 ground-truth 是 tail item 的子集)。
主要实验结果¶
A. Main Results (Table I)¶
| Dataset | Model | HR@5 All / Tail | HR@10 All / Tail | NDCG@5 All / Tail | NDCG@10 All / Tail | MGU@5 / @10 | ARP@5 / @10 | CNS@5 / @10 |
|---|---|---|---|---|---|---|---|---|
| Ins | LETTER | 0.0593 / 0.0025 | 0.0662 / 0.0044 | 0.0530 / 0.0016 | 0.0553 / 0.0023 | 0.1965 / 0.1442 | 181.2628 / 151.7149 | 0.2457 / 0.2714 |
| Ins | LC-Rec | 0.0870 / 0.0027 | 0.1046 / 0.0044 | 0.0748 / 0.0021 | 0.0804 / 0.0027 | 0.3458 / 0.3380 | 365.4217 / 338.5304 | 0.3214 / 0.3134 |
| Ins | ED² | 0.0898 / 0.0058 | 0.1068 / 0.0102 | 0.0765 / 0.0048 | 0.0820 / 0.0055 | 0.2326 / 0.2305 | 279.8572 / 237.9431 | 0.6067 / 0.6217 |
| Ins | Augmentation | 0.0875 / 0.0071 | 0.1039 / 0.0105 | 0.0759 / 0.0051 | 0.0812 / 0.0061 | 0.2383 / 0.2049 | 271.1657 / 242.7466 | 0.6327 / 0.6323 |
| Ins | Substitution | 0.0578 / 0.0058 | 0.0734 / 0.0084 | 0.0445 / 0.0049 | 0.0489 / 0.0064 | 0.1014 / 0.0310 | 269.3299 / 229.5070 | 0.5714 / 0.5601 |
| Ins | IFairLRS-RW | 0.0888 / 0.0078 | 0.1072 / 0.0081 | 0.0767 / 0.0043 | 0.0826 / 0.0055 | 0.3322 / 0.3226 | 328.5940 / 299.5196 | 0.5007 / 0.4887 |
| Ins | IFairLRS-RR | 0.0853 / 0.0100 | 0.1053 / 0.0110 | 0.0744 / 0.0078 | 0.0801 / 0.0081 | 0.1578 / 0.1334 | 301.2252 / 286.9023 | 0.7462 / 0.6286 |
| Ins | Ghost (Ours) | 0.0864 / 0.0117 | 0.1017 / 0.0173 | 0.0755 / 0.0078 | 0.0805 / 0.0097 | 0.0596 / 0.0958 | 248.8179 / 209.8877 | 0.8974 / 0.8694 |
(其他两个数据集 Arts、Games 趋势完全一致;ED² 系列与 Ghost 在 Overall 的差距 ≤ 9%。)
三大结论: 1. Tail 表现大幅提升:Ghost 在三数据集上 Tail HR / Tail NDCG 平均比标准 GR(LETTER/LC-Rec/ED²)高 63.91% / 70.66%,最高 +57.24%。 2. MGU 显著降低:Ghost MGU 平均比标准 GR 降低 55.76%,比最强公平 baseline IFairLRS-RR 进一步降低 16.68%(最高 66.60%)。 3. Overall 性能代价可接受:与最强 baseline LC-Rec 相比,Overall HR/NDCG 仅下降 7.46% / 6.34%(同时所有 popularity debiasing baselines 的 Overall 下降范围在 2.46%–18.90%(HR)/ 2.24%–21.28%(NDCG)之间,Ghost 没有 outlier 化)。 4. CNS 综合最优:Ghost CNS 平均提升 16.81%(最高 22.06%),直接证明它在 multi-objective 空间最接近 Pareto front。
B. Head/Tail 推荐列表组成(Fig. 5 左)¶
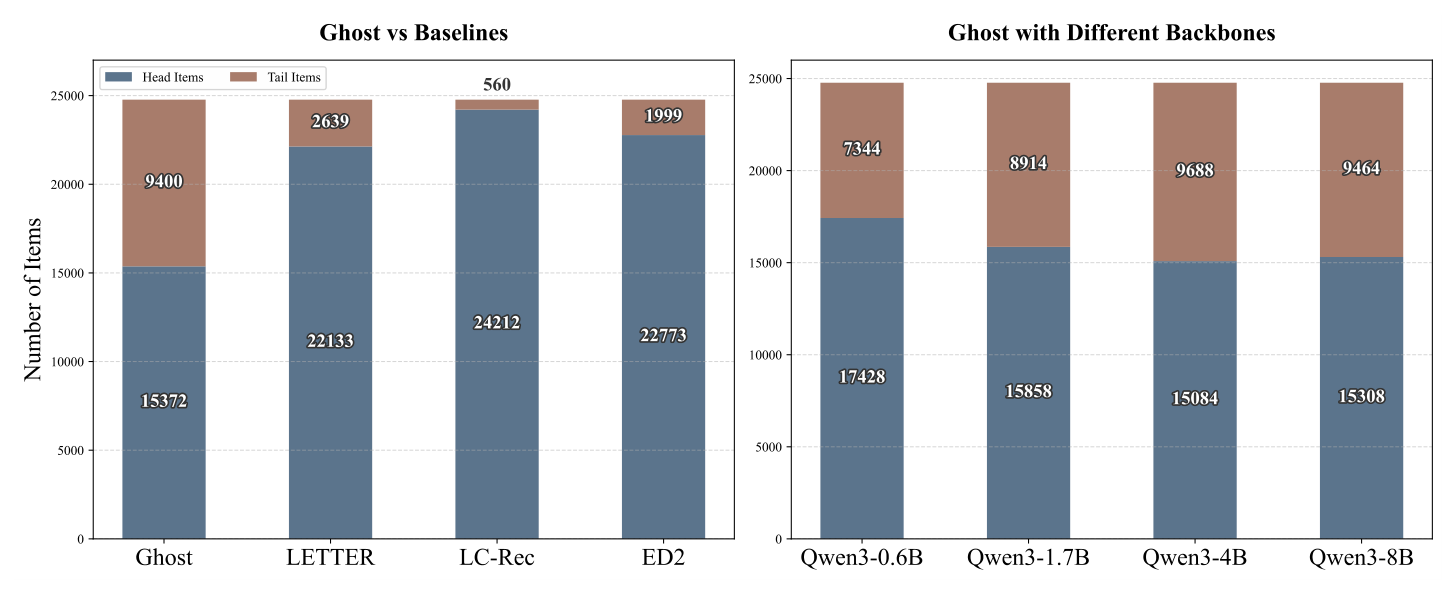
Ghost:head 15,372 / tail 9,400 → head/tail ≈ 1.6 : 1(接近真实 8:2 的"反向"——直接覆盖更多 tail) LETTER:head 22,133 / tail 2,639 LC-Rec:head 24,212 / tail 560(典型的 filter bubble) ED²:head 22,773 / tail 1,999
Ghost 把 LC-Rec 的"560 tail"放大到 9,400 tail,提升 16.8×。"Echoes in filter bubble"——过滤气泡被实质性打破。
消融与分析¶
A. Ablation Study (Table II, Ins 数据集)¶
| Model | HR@5 All / Tail | HR@10 All / Tail | NDCG@5 All / Tail | NDCG@10 All / Tail | MGU@5 / @10 | ARP@5 / @10 |
|---|---|---|---|---|---|---|
| Ghost | 0.0864 / 0.0117 | 0.1017 / 0.0173 | 0.0755 / 0.0078 | 0.0805 / 0.0097 | 0.0596 / 0.0958 | 248.8179 / 209.8877 |
| w/o AUO | 0.0849 / 0.0111 | 0.1003 / 0.0161 | 0.0733 / 0.0075 | 0.0782 / 0.0091 | 0.0035 / 0.0112 | 270.4236 / 235.9759 |
| w/o SKT | 0.0920 / 0.0060 | 0.1102 / 0.0095 | 0.0798 / 0.0047 | 0.0856 / 0.0058 | 0.3211 / 0.3056 | 357.0114 / 357.7677 |
| RQK-4 | 0.0929 / 0.0059 | 0.1116 / 0.0095 | 0.0796 / 0.0042 | 0.0856 / 0.0054 | 0.3037 / 0.2885 | 304.3177 / 267.9522 |
| RQK-6 | 0.0932 / 0.0052 | 0.1133 / 0.0088 | 0.0797 / 0.0038 | 0.0826 / 0.0049 | 0.3073 / 0.2902 | 303.1651 / 269.7153 |
| RQK-4-6 | 0.0883 / 0.0070 | 0.1080 / 0.0095 | 0.0762 / 0.0049 | 0.0826 / 0.0057 | 0.2268 / 0.2468 | 320.2727 / 288.6501 |
- RQK-4 / RQK-6:LC-Rec backbone + 4 或 6 层 RQ-KMeans(无 SKT,无 AUO);
- RQK-4-6:head 4 层 + tail 6 层 RQ-KMeans,但不做 prefix 继承(即 SKT 的"骨架"部分被去掉)。
两条核心结论:
- SKT 是更关键的组件:w/o SKT 时 Tail HR@10 从 0.0173 暴跌到 0.0095(-45%),MGU@10 从 0.0958 飙升到 0.3056(×3.2)。RQK-4-6(变长但无 inheritance)虽然给 tail 更多 token 容量,但 head/tail token 仍会在多个 branching point 上无序竞争,Tail HR@10 仅 0.0095。仅靠"给 tail 更长 SID"是不够的,必须强制 prefix inheritance 来消除混乱 branching。
- AUO 必须有 SKT 作为前置:w/o AUO 仍保持较高 tail 表现(0.0161)——这是因为 SKT 单独已经把 multi-step 几何压制坍缩到单步。但 ARP/MGU 表现波动很大(MGU@10 = 0.0112 极低但 HR@5 整体偏低)。AUO 的"gradient rescue"必须借由 SKT 提供的 tail-specific token 来"接收",否则梯度无处吸收。
B. SID Length Analysis (Fig. 4)¶
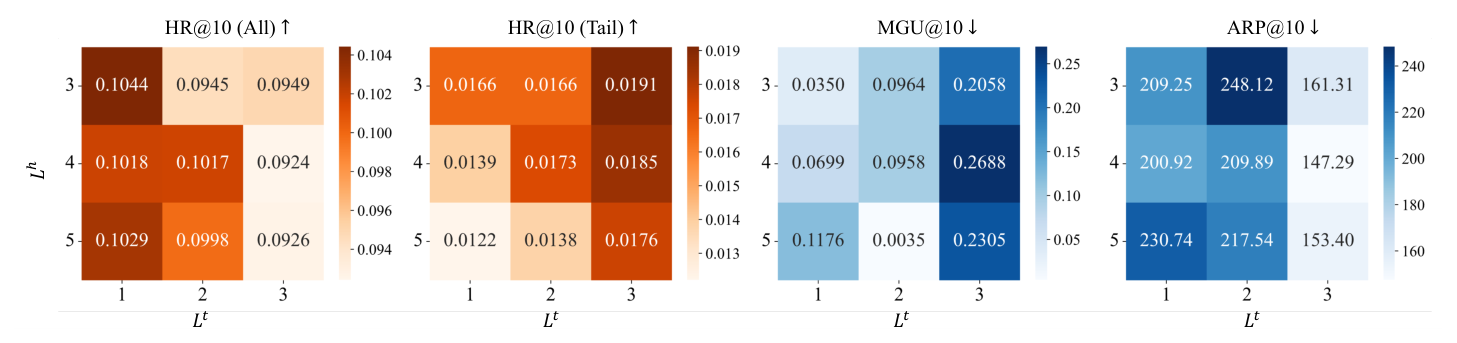
热图揭示 trade-off:
- 增大 $L^t$(tail-specific length)→ Tail HR@10 / Tail NDCG@10 上升、ARP@10 下降;
- 但同时 Overall HR@10 / NDCG@10 略降(因为 head SID 容量没变,整体序列变长引入噪声);
- 最佳 trade-off:$L^h=4, L^t=3$ 时 Tail HR@10 取得 0.0185;$L^h=3, L^t=3$ 时 ARP@10 最低 161.31;
- 论文默认 $L^h=3, L^t=2$ 是 balanced 选择。
C. Scaling Pattern Analysis (Table III)¶
将 Ghost backbone 从 Qwen3-0.6B 扩到 Qwen3-8B:
| Scale | Model | HR@5 Tail | HR@10 Tail | NDCG@5 Tail | NDCG@10 Tail | MGU@10 | ARP@10 |
|---|---|---|---|---|---|---|---|
| 0.6B | LC-Rec | 0.0015 | 0.0021 | 0.0010 | 0.0011 | 0.3550 | 404.2913 |
| 0.6B | Ghost | 0.0101 | 0.0148 | 0.0069 | 0.0084 | 0.0208 | 209.8331 |
| 1.7B | LC-Rec | 0.0027 | 0.0033 | 0.0022 | 0.0024 | 0.3512 | 386.3999 |
| 1.7B | Ghost | 0.0110 | 0.0174 | 0.0081 | 0.0102 | 0.0508 | 224.2784 |
| 4B | LC-Rec | 0.0057 | 0.0074 | 0.0047 | 0.0053 | 0.3301 | 404.2913 |
| 4B | Ghost | 0.0136 | 0.0190 | 0.0101 | 0.0118 | 0.0211 | 215.0566 |
| 8B | LC-Rec | 0.0062 | 0.0092 | 0.0047 | 0.0056 | 0.3142 | 268.9937 |
| 8B | Ghost | 0.0150 | 0.0228 | 0.0106 | 0.0131 | 0.0410 | 181.4011 |
关键观察:
- Ghost 在所有规模下 Tail HR@10 都领先 LC-Rec 接近 2-7 倍;
- 随规模增大,Ghost 进一步收紧 ARP@10(209.83 → 181.40),证明大模型在 SKT/AUO 框架下能"长出"额外的长尾能力——这正是标准 GR 做不到的;
- Tail HR@10 从 0.0101(0.6B)单调上升到 0.0228(8B),+126%。
Ghost 0.6B → 4B → 8B 时 tail 数量从 7,344 → 9,688 → 9,464——大模型直接转化为更均衡的推荐列表,无 overfitting 到主流内容的迹象。
D. Hyper-parameter Sensitivity¶
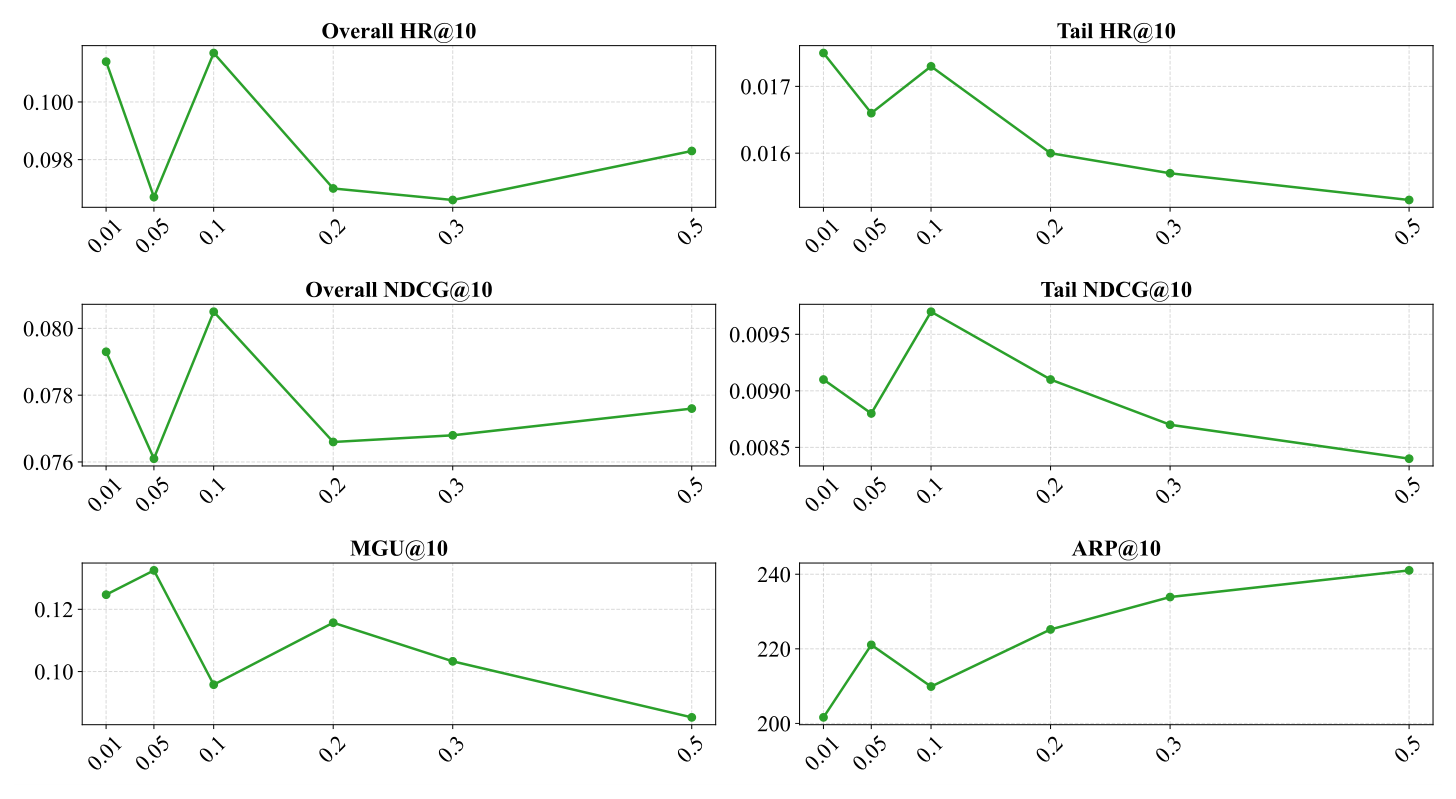
AUO 权重 $\alpha$(Fig. 6): $\alpha \in \{0.01, 0.05, 0.1, 0.2, 0.3, 0.5\}$,0.1 是最优点——在此处 Overall NDCG@10、Tail NDCG@10 都最高,且 ARP@10 局部最低。$\alpha \gt 0.1$(0.2-0.5)时所有指标急剧恶化,因为过度惩罚 head 反而导致整体性能崩溃,主流 item 被过度压制最终诱发模型退化。
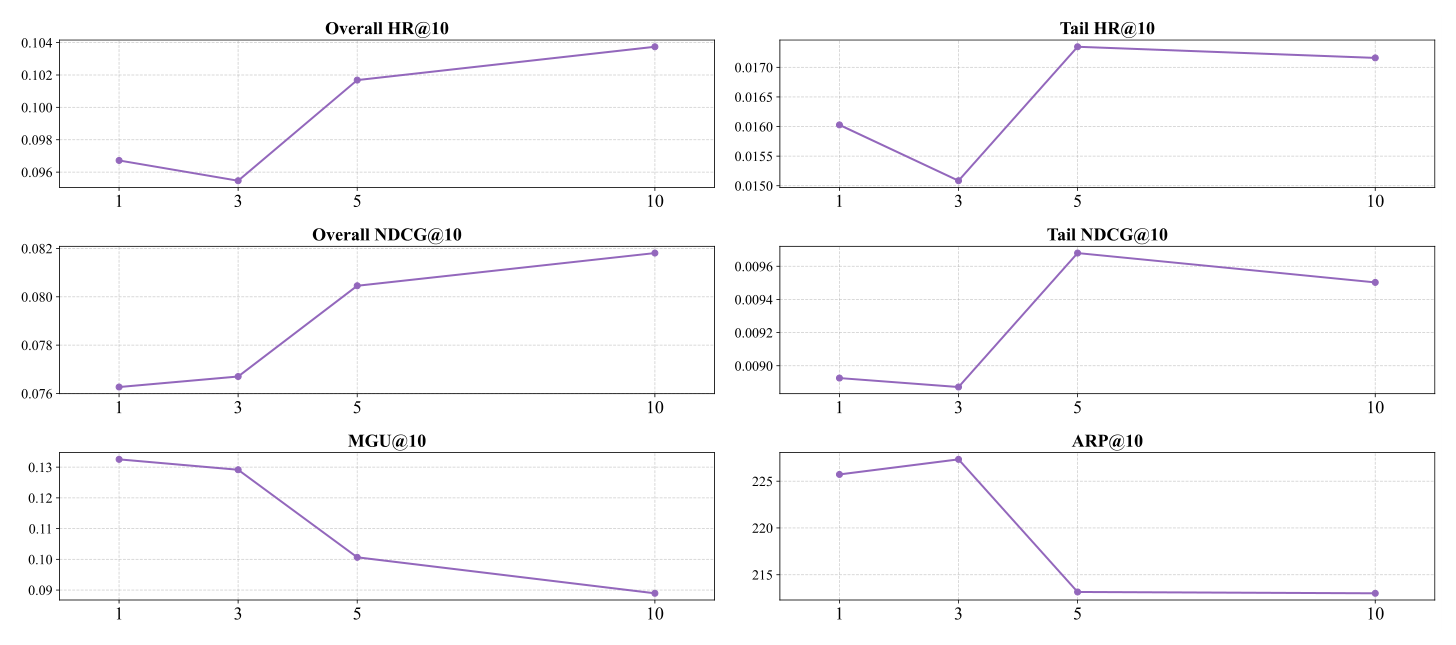
Undesired Collection 大小 $K_b$(Fig. 7): $K_b \in \{1, 3, 5, 10\}$,5 是最优:Tail HR@10、Tail NDCG@10 在此处取得峰值,ARP@10 也急剧下降。$K_b = 10$ 时 tail 指标轻微退化、user coverage 下降——过大的 undesired set 会引入噪声,干扰 tail item 的检索多样性。
Learning rate(Fig. 11):$3 \times 10^{-5}$ 最优;$5 \times 10^{-4}$ 时整个去偏机制崩溃。
Epoch(Fig. 12,Games 数据集):epoch 4 最优,6–8 epoch 开始 overfit,所有指标系统性退化。
E. Equal-Sized Popularity Grouping (Appendix D, Fig. 10)¶
把 item 按 popularity 等分 5 组(0-20, 20-40, ..., 80-100)做 fine-grained 评估:
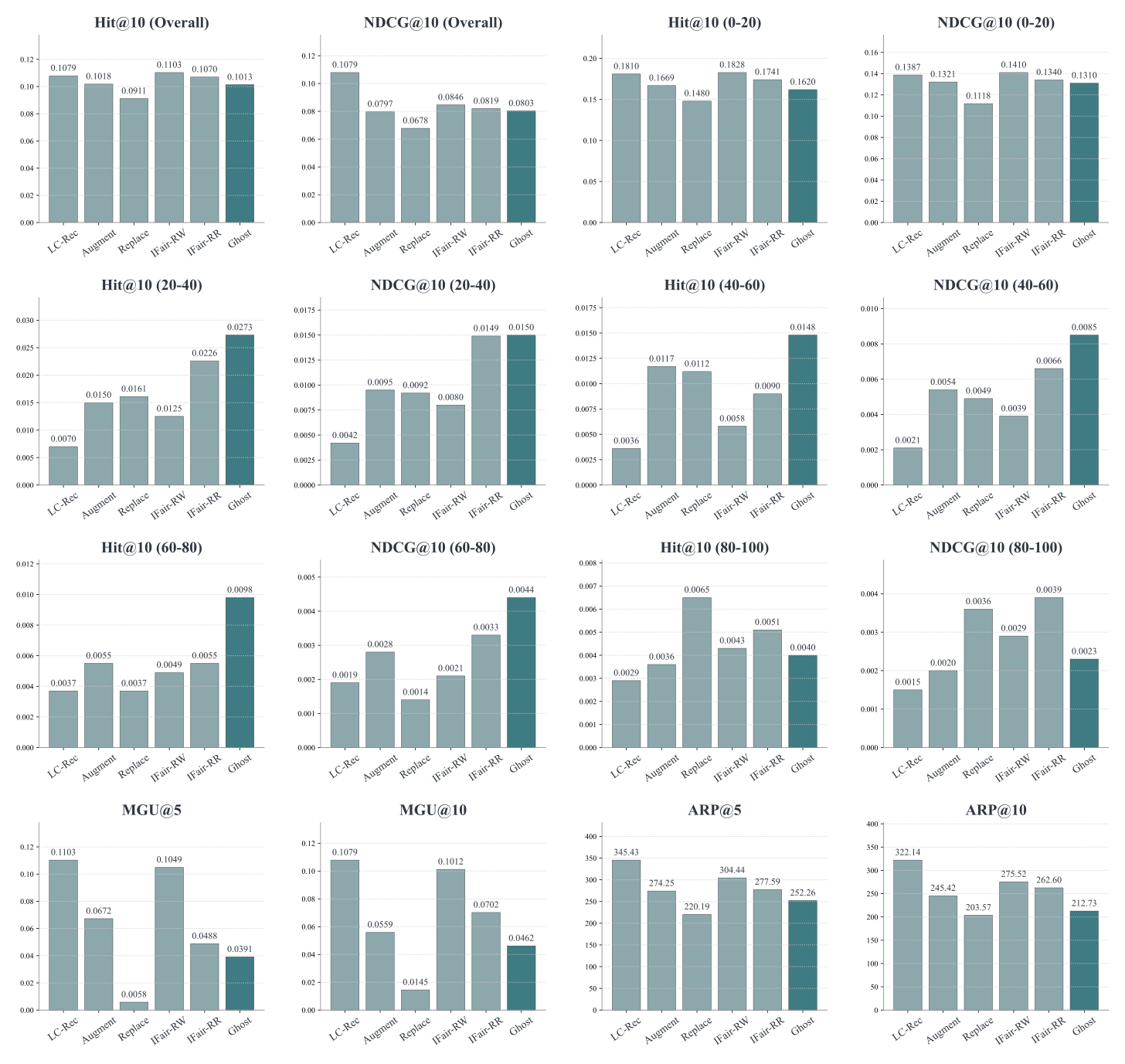
- 20-40 / 40-60 / 60-80 组:Ghost 一骑绝尘——例如 20-40 组 Hit@10 = 0.0273(vs LC-Rec 0.0070 / IFair-RR 0.0226),证明 Ghost 真正激活了被忽视的"中长尾"段;
- 0-20 组(最热门):Ghost 略低于 LC-Rec(0.1626 vs 0.1879),但保持竞争力——它没有"为长尾牺牲全部头部";
- MGU、ARP 全面降至最低。
F. Tail Prefix Inheritance Distribution (Fig. 9)¶
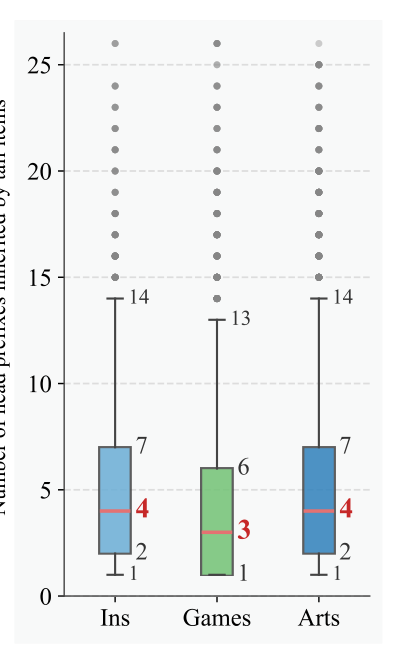
每个 head item 平均被 3-4 个 tail item 继承前缀,中位数 4(Ins, Arts),3(Games)。IQR 在 2-7 之间。说明 SKT 的"骨架"是被高效复用的——head SID 空间确实是 tail item 的 reusable substrate。
核心贡献总结¶
- 诊断:从 token-level(LEMMA 1: Gradient Starvation)和 sequence-level(LEMMA 2: Bias Amplification via Undifferentiated Tokenization)两个角度严格证明了 GR 流行度偏差的两个 root cause,并量化为 $\mathcal{O}(\gamma_{\min}^{-z})$ 的几何压制。
- 方法:Ghost = SKT (治理 $z$) + AUO (治理 $\gamma$)。SKT 通过"head 骨架 + tail 继承前缀 + 额外 tail-specific token"把多步混乱 branching 收缩到单步;AUO 通过对"高文本相似度但 SID 路径分叉"的 head distractor 施加 unlikelihood 惩罚,借 softmax 耦合反向 rescue tail token gradient(LEMMA 4)。
- 实证:在 3 个 Amazon 数据集 × 7 个 baseline 上系统验证;Tail 性能 +63.91%/+70.66%,MGU -55.76%,CNS +16.81%;Scaling 0.6B → 8B 时 Ghost 持续受益,head/tail 比例从 LC-Rec 的 43:1 收紧到 1.6:1,filter bubble 被实质性打破。
与已归档相关工作的对比¶
VarLenRec VarLenRec: Learning Variable-Length Tokenization for Generative Recommendation (East China Normal University, 2026-05-18)¶
关系:独立并发(本文未引用 VarLenRec,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两篇论文同时识别出"GR 中 head 与 tail item 不应共享同等长度的 SID"——这是当前 RQ-VAE / RQ-KMeans tokenization 的核心结构性缺陷。VarLenRec 把它命名为"Popularity-Length Paradox"(head 越短越好、tail 越长越好),Ghost 则把它表述为"Bias Amplification via Undifferentiated Tokenization"(多个 unpredictable branching point 几何压制 tail)。两者从不同角度逼近同一 root cause:单一 SID 长度配置无法同时服务 head 与 tail 的不同信息需求。
- 相近的技术骨架:两者最终都给出了"head SID 短、tail SID 长"的变长方案。Ghost 通过 SKT 显式实现:head 用 $L^h$ 长度,tail 用 $L^h + L^t$ 长度,且 tail 强制继承最近 head 的 $L^h$ 前缀。VarLenRec 通过 PIBA 的闭式定理推导出 $L_i^* \propto p_i^{-\alpha/\gamma}$ 的连续长度律,再用 rank-based quantile 离散化。两者都打破了 TIGER / LETTER 所遵循的"all items same length"假设。
- 本文的差异与推进:VarLenRec 的视角是"信息预算"(rate-distortion,体积容量),Ghost 的视角是"梯度动力学"(gradient starvation + branching point amplification)。VarLenRec 需要引入 Poincaré ball / hyperbolic RQ / soft length controller 等大量几何机器,并要解决 collision 与 length bias 等下游集成问题;Ghost 选了一条工程上更轻的路径——保留欧氏 RQ-KMeans,只用"prefix inheritance + 额外尾部 token"实现变长,head 与 tail 共享同一 codebook,几乎不改 RQ-KMeans 的实现。
- 可比的方法 / 实验差异:VarLenRec 在 Beauty / Sports / Toys / Yelp 4 个数据集上验证;Ghost 在 Ins / Arts / Games 3 个 Amazon 数据集上验证。两者都报告对 TIGER/LETTER/LC-Rec 系列的 NDCG / HR 提升。Ghost 独有的轴是 AUO(unlikelihood 训练),这是 VarLenRec 完全没触及的——VarLenRec 只在 tokenization 端做手术,Ghost 同时从 tokenization (SKT) + optimization (AUO) 两端联合调治。两者在工程难度、理论优雅度、模型规模可扩展性上互为镜像,是同一问题的两种代表性解法。
CRAB CRAB: Codebook Rebalancing for Bias Mitigation in Generative Recommendation (Walmart Global Tech, 2026-04-06)¶
关系:独立并发(本文未引用 CRAB,两者殊途同归)· 已加载对方精读
- 共同关注的问题:两者同步指出"GR 流行度偏差的根因在于 tokenizer 构造出的 codebook 本身——RQ-KMeans / RQ-VAE 没有 frequency awareness,热门 item 会被聚到 over-popular token 上"。CRAB 在 token-level 量化为 "$G_{\text{pop}} = 0.42$(MOR)比 SASRec 高 1.8×";Ghost 在 sequence-level 形式化为"$z$ 个不可预测 branching point 的几何累积压制"。两者都把焦点从"模型损失重加权"转回"tokenizer 自身的不公平",跳出了传统 IPW / propensity scoring 的去偏框架。
- 相近的技术骨架:两者都试图打破"head 与 tail 共享相同 token 空间"的对称性。CRAB 通过 post-hoc 拆分 over-popular token(regularized K-means 把热门 token 拆为 $M$ 个子 token,并在 LLM embedding 上加 Hierarchical Semantic Alignment 正则)来减弱热门 token 的曝光垄断。Ghost 通过 SKT 在 pre-training tokenizer 阶段就 enforce head/tail 异步处理。两者都意识到"语义层次结构必须保留"——CRAB 通过 sibling-mean alignment,Ghost 通过强制 tail 继承最近 head 的前缀。
- 本文的差异与推进:CRAB 是 post-hoc(先训好 GR,再修 codebook,再 LoRA 微调),Ghost 是 end-to-end(tokenization 与 training 联合优化)。CRAB 只动 codebook,不动 loss;Ghost 在 codebook(SKT)和 loss(AUO)两端同时干预。CRAB 的 token 拆分必须满足"同一子 token 下的 item 不能被拆开"这一硬约束(避免破坏更深层语义),而 Ghost 通过"骨架继承"天然规避了这个问题——它从不拆 head SID,只把它们用作 tail 的 prefix。Ghost 提供的 AUO 还能用 unlikelihood 主动 rescue tail token 的梯度,这是 CRAB 的 HSA 正则做不到的(HSA 只是为新 token 提供合理初始化,无法对训练动力学施加结构性纠偏力)。
- 可比的方法 / 实验差异:CRAB 在 Industrial + Office 数据集报告 DGU@10 -16.5%,需要额外 LoRA 微调阶段;Ghost 在 3 个 Amazon 数据集报告 MGU 平均 -55.76%、Tail HR/NDCG +60% 量级,端到端无后处理。两者都用 MGU/GU 类 fairness metric,但 Ghost 增加了 ARP、CNS 等度量;Ghost 还做了 LLM backbone scaling(0.6B → 8B)实验,证明方法对 LLM 规模的鲁棒性,而 CRAB 仅基于 MOR / TIGER 单一 backbone。
讨论与局限性¶
优雅之处¶
- 理论与方法的精准对应:LEMMA 1 的 starvation 对应 AUO;LEMMA 2 的 amplification 对应 SKT;LEMMA 3 (Mitigation) + LEMMA 4 (Rescue) 分别构成 SKT 与 AUO 的工作原理证明。这种"诊断-处方"逐项闭环在 GR 去偏文献中相当罕见。
- SKT 的"骨架"隐喻:把 head item 当作整个 SID 空间的 substrate,强制 tail item 沿骨架长出"血肉"——既维持了"语义相近共享前缀"的 SID 基本原则,也消除了 head/tail 混乱竞争。这是一种很优雅的设计选择。
- AUO 的非对称设计:传统 unlikelihood 是对称的(所有生成位置都加惩罚),Ghost 把它做成 head-only。借 softmax 归一化的耦合效应实现"按下 head → 抬起 tail",让 unlikelihood 训练从"全局正则"变成"定向救援"。
工业落地视角¶
- 论文没有报告任何工业 A/B 实验,方法严格停留在 academic benchmark 上;
- 数据规模较小(最大 Games 仅 5w 用户 / 1.7w item),与 OneRec / OneSearch 等工业级生成式推荐百万-千万级 item 规模相比仍有 gap;
- 训练成本不可忽视:每个 tail target 都需要预先构造 $\bar{\Omega}_{v'}$(top $K_a$ 候选 + LCP 排序得 $K_b$)。$K_a = 200$ 在十万级 item 上还可接受,但要扩展到亿级 item 库时 retrieval 开销将主导整体训练成本,需要 ANN 索引加速。
局限性(论文自陈 + 个人补充)¶
- 仅限于 SFT 范式(论文 Appendix G):理论分析基于 MLE 损失,AUO 是 MLE 的扩展。不知 RL(GRPO / Reasoning-based GR)下 popularity bias 是否仍呈相同 starvation 形态,方法是否仍有效。
- Undesired collection 静态预计算(论文 Appendix G):$\bar{\Omega}_{v'}$ 在训练开始前固定,没有随训练动态更新。理论上 dynamic 更新能提供更精准的负监督,但代价是显著 training overhead。
- 个人补充:
- SKT 的 head/tail 切分基于 fixed 20%/80% 阈值,没有 explore 分布自适应或 quantile-based 切分;
- 文本相似度(cosine on textual encoder embedding)作为 head/tail anchor 的唯一 selection criterion,没有引入协同信号——理论上协同信号能进一步矫正"语义相似但用户行为分叉"的边缘情况;
- SKT 假设每个 tail item 都能找到一个"合理"的 head anchor,但若 tail item 是真正 niche(语义上和所有 head item 都很远),强行继承前缀可能注入噪声;
- AUO 损失中 $\alpha = 0.1$ 是 dataset-specific 调出来的,sensitivity 实验显示 $\alpha \gt 0.2$ 时性能急剧崩溃——参数稳定性窗口较窄;
- 没有讨论 head/tail 边界附近的"中尾"item 表现是否仍稳定(Fig. 10 的等分组分析部分回答了这一问题,但分组本身仍依赖排序 popularity)。
与现有 GR 去偏文献的本质差异¶
- 传统 IFairLRS / IPW / re-ranking 在 GR 上效果有限,因为它们假设"模型本身没问题,只需调整训练样本权重或后处理排序"——但 Ghost 揭示了 GR 的 root cause 是 tokenizer + optimizer 自身的结构性偏差。
- CRAB / VarLenRec 已经把焦点从 model-level 转到 tokenizer-level,但 CRAB 是 post-hoc,VarLenRec 只动 tokenization;Ghost 同时动 tokenization (SKT) 和 optimization (AUO),是首个在 GR 框架内系统性地从两端联合治理 popularity bias 的工作。