Efficient Generative Retrieval for E-commerce Search with Semantic Cluster IDs and Expert-Guided RL¶
研究动机与背景¶
现代电商搜索引擎普遍采用多级漏斗(multi-stage funnel)架构,依序由 query understanding、recall、coarse ranking、fine ranking、re-ranking 五个阶段组成。其中 recall 阶段负责从亿级商品库中快速召回数百到数千个候选,对延迟最敏感且对最终业务指标(GMV、UCTVR)影响最直接。传统召回手段分两条路线:
- 稀疏检索(BM25 / 倒排索引):成熟稳定,但在语义匹配上极弱;
- 稠密检索(embedding ANN):召回语义匹配能力强,但需要持续维护索引、推理与训练分布差距导致 embedding gap。
近年来 生成式检索(generative retrieval, GR) 提供了第三条路线:用一个端到端的 seq-to-seq 模型直接生成代表 doc/item 的 identifier,把"index → retrieve"两步合并到一个可微模型里。开山工作 DSI [17] 证明了 transformer 完全可以记忆并准确生成 doc id;NCI [19]、SEAL [1]、TIGER [13] 沿此推进。但作者明确指出,这套范式在 工业电商搜索落地仍然远未成熟,主要面临三大挑战:
Challenge 1:端到端可行性。 已有工业方案(如 Kuaishou OneModel 系列 [2, 5])主张完全替代多级漏斗,由生成式模型一次完成召回到排序的全部工作。但电商搜索(不同于推荐)对精确性、相关性要求极高,亿级商品库直接生成会带来覆盖率坍塌、长尾缺失,并放大"马太效应"(极少数热门商品垄断生成概率)。
Challenge 2:Semantic ID 的设计权衡。 现有 SID 工作 [13, 17] 默认追求 one-item-one-ID(碰撞最小化)。但在工业级亿级商品上,过细的标识符意味着模型需要更长训练、更多数据;推理时为了召回足够多的不同商品,beam size 必须开得很大(通常数百),直接撑爆 latency 预算。
Challenge 3:与下游排序的对齐。 召回模型传统上用 click → MLE 训练,仅学到"用户曾点击的",但漏斗下游的 fine ranking 需要更广更高质量的候选作为输入。一个理想的召回模型应该不只生成"用户点过的",还要生成"高曝光、高购买"等下游可利用的高质量候选。把强化学习引入召回-排序对齐是一条自然路径,但 GRPO [15] 在生成式检索的离散结构化输出空间上常常因为奖励稀疏(每条 query 命中数极少)出现高方差和模式坍塌,亟需稳定化设计。
针对以上三点,本文把生成式检索定位为召回阶段的补充而非端到端替代,提出 CQ-SID + EG-GRPO + 渐进式四阶段训练的整体方案,部署在阿里 TmallAPP 移动电商搜索的生产链路里。当前该生成式召回链路贡献了全平台 50.25% 的曝光、58.96% 的点击、72.63% 的购买,离线 hitrate 相对 RQ-VAE 基线提升 26.76% / 11.11%(语义/个性化),同时把 beam size 减半以上;线上 A/B 两周 GMV +1.15%、UCTVR +0.40%。
核心方法:三阶段流水线总览¶
整体架构由三个核心模块串联(图 1):
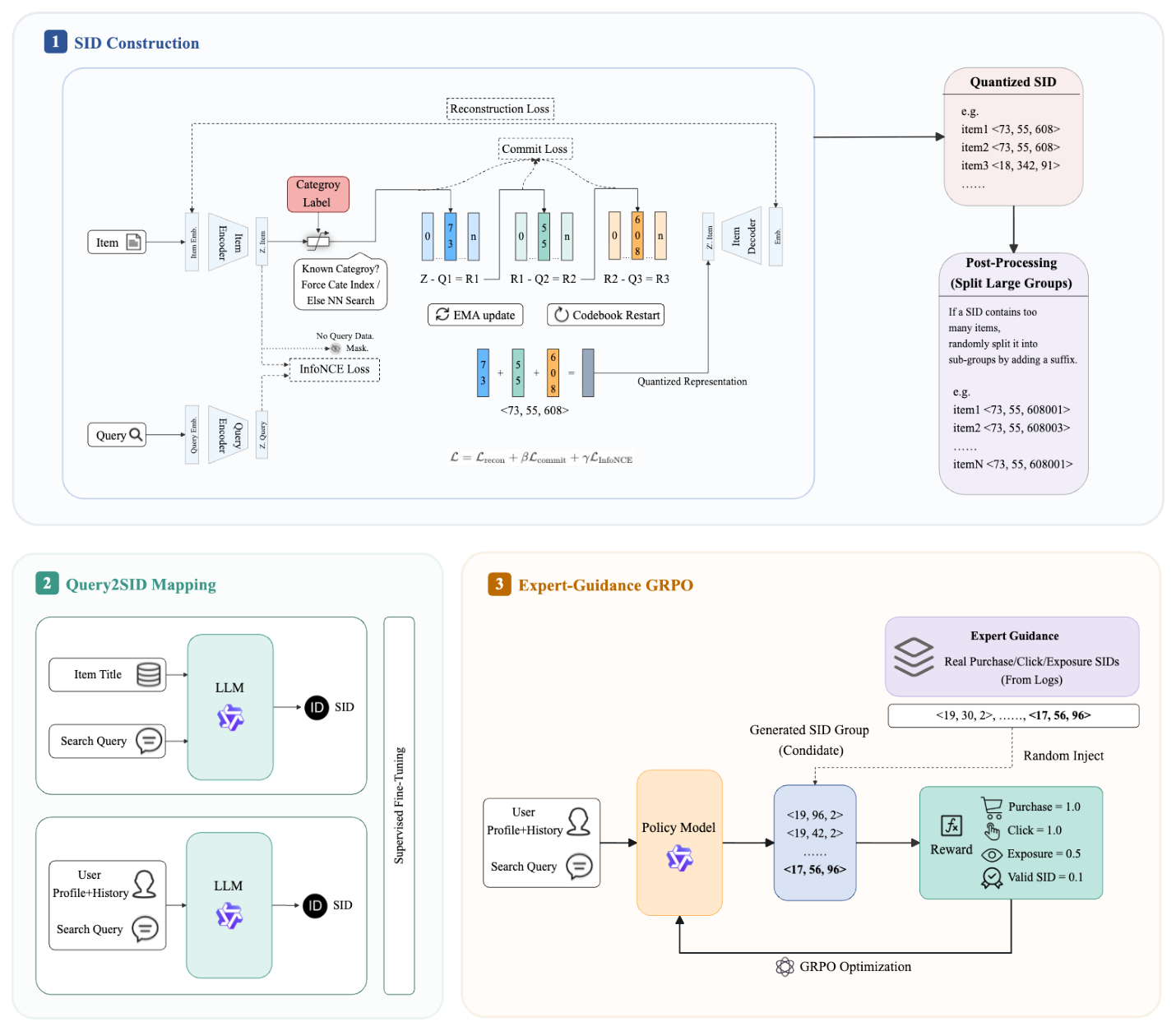
- CQ-SID 物品语义 ID 构造(§3.1):基于 RQ-VAE 改造,引入类目约束的第一层量化 + query-item 双向对比学习,构造出"语义簇 ID"——多个语义/属性相似的 item 共享同一 SID,主动放弃唯一性以换取 beam search 效率;
- 渐进式 Query-to-SID 训练(§3.2):基于 Qwen2.5-0.5B 走 4 阶段 SFT —— Item2SID(建立 item → SID 基础)→ Query2SID(query → 多 SID 桥接)→ User+Query2SID(注入个性化)→ EG-GRPO(与排序对齐);
- Expert-Guided GRPO(§3.3):在策略梯度的 group 中主动注入 K 条 ground-truth SID 作为伪生成响应,缓解稀疏奖励下标准 GRPO 的 click-exposure trade-off 坍塌,同时同时优化点击与曝光多目标。
下面分别展开。
3.1 通过 CQ-SID 构造物品语义 ID¶
3.1.1 设计动机与三性质¶
不同于已有工作追求 one-item-one-ID,作者提出 CQ-SID 应满足三条性质:
- Semantic aggregation(语义聚合):语义/属性相近的 item 应该映射到同一 SID,且每个 SID 下的 item 数被显式控制;
- Inter-cluster discriminability(簇间区分性):不同语义的 item 必须落入不同 SID;
- Hierarchical structure(层级结构):相似 item 共享 SID 前缀,从而 beam search 沿层级剪枝时能高效收敛。
第一性的关键判断是:"碰撞"在亿级电商库中并非缺陷,而是必须的设计选择——它把召回 beam search 复杂度从 $O(\text{N}_\text{items})$ 降到 $O(\text{N}_\text{clusters})$,同时通过聚合天然解决长尾覆盖问题。
3.1.2 模型架构¶
CQ-SID 在标准 RQ-VAE [13, 24] 基础上做三处关键改造,三层 codebook 大小为 $K_1 \times K_2 \times K_3 = 2048 \times 1024 \times 1024$。
(1) Category-Guided Residual Quantization。 第一层 codebook 不再用最近邻量化,而是按类目体系强制对齐——电商类目体系本身就是天然的层级语义先验。第一层共构造 1711 个 category bin。对已知类目的 item,第一层索引由类目决定;对未知类目的 item 退化为最近邻:
$$ k_i^{(1)} = \begin{cases} \text{CategoryID}(i), & \text{if } i \in \mathcal{I}_{\text{known}}, \\ \arg\min_{j \in \{1,\ldots,K_1\}} \|\mathbf{r}_i^{(0)} - \mathbf{e}_j\|_2^2, & \text{otherwise.} \end{cases} \tag{1} $$
其中 $\mathbf{r}_i^{(0)}$ 是 item encoder 输出 embedding,$\mathbf{e}_j$ 是 codebook 第 $j$ 个码字。
第二、第三层 codebook 沿用标准最近邻量化。所有 codebook 通过 EMA 更新,并配合 Codebook Restart [18] 防止 codebook collapse。第 $l$ 层 codebook 中第 $j$ 个码字的 EMA 更新:
$$\mathbf{e}_j^{(l)} \leftarrow \lambda\,\mathbf{e}_j^{(l)} + (1-\lambda)\,\mathbf{m}_j^{(l)}, \tag{2}$$
$$\mathbf{m}_j^{(l)} = \frac{1}{n_j^{(l)}} \sum_{i \in \mathcal{B}} \mathbb{I}[k_i^{(l)} = j]\,\mathbf{r}_i^{(l-1)}, \tag{3}$$
其中 $\mathbf{r}_i^{(l-1)}$ 与 $k_i^{(l)}$ 是第 $i$ 样本第 $l$ 层量化前残差和分配索引,$n_j^{(l)} = \sum_{i \in \mathcal{B}} \mathbb{I}[k_i^{(l)} = j]$ 为该码字本 batch 命中次数,$\lambda \in (0, 1)$ 为衰减因子。
(2) Query-Item Contrastive Learning。 CQ-SID 在 codebook 训练时同步引入 query encoder:高置信度 query-item pair(来自用户的 search-click-purchase 行为)通过双向 InfoNCE [10] 约束,让 query 与 item 的 latent 空间对齐:
$$ \mathcal{L}_{\text{Bi-InfoNCE}} = \frac{1}{2}\left[ -\log \frac{\exp(\text{sim}(\mathbf{e}_i, \mathbf{e}_q)/\tau)}{\sum_{q' \in \mathcal{Q}} \exp(\text{sim}(\mathbf{e}_i, \mathbf{e}_{q'})/\tau)} - \log \frac{\exp(\text{sim}(\mathbf{e}_q, \mathbf{e}_i)/\tau)}{\sum_{i' \in \mathcal{I}} \exp(\text{sim}(\mathbf{e}_q, \mathbf{e}_{i'})/\tau)} \right], \tag{4} $$
其中 $\mathcal{Q}$、$\mathcal{I}$ 是同 batch 内的 query 与 item 集合,$\text{sim}(\cdot, \cdot)$ 是 cosine similarity,$\tau$ 是温度。无 query 关联的 item 该项掩码忽略。
(3) Joint Training Objective。 总损失:
$$\mathcal{L}_{\text{recon}} = \|x - \hat{x}\|_2^2, \tag{5}$$
$$\mathcal{L}_{\text{commit}} = \sum_{l=1}^{3} \|\mathbf{z}_l - \text{sg}[\hat{\mathbf{z}}_l]\|_2^2, \tag{6}$$
$$\mathcal{L} = \mathcal{L}_{\text{recon}} + \beta \mathcal{L}_{\text{commit}} + \gamma \mathcal{L}_{\text{InfoNCE}}, \tag{7}$$
其中 $x$ 是输入特征、$\hat{x}$ 是重建、$\mathbf{z}_l$ 是 quantizer 输入、$\hat{\mathbf{z}}_l$ 是量化向量、$\text{sg}[\cdot]$ 是 stop-gradient,$\beta=1.0$、$\gamma=0.001$。
3.1.3 SID 后处理:过大簇的随机切分¶
得到三层 SID 之后,为了控制每个 SID 对应的 item 数不无限膨胀(防止单一热门簇主导召回),作者增加一道后处理切分:
Algorithm 1(SID Grouping) 输入:SID 集合 $S$,阈值 $T_{\max}=50$,最大子组数 $G_{\max}=100$。 对每个 SID $s = \langle s_1, s_2, s_3 \rangle \in S$: 计 $c$ = 该 SID 关联的 item 数。若 $c \gt T_{\max}$,则 $G \leftarrow \min(\lceil c / T_{\max}\rceil, G_{\max})$,把 item 随机切成 $G$ 个子组;对每个子组 $g \in [1, G]$ 用 4 位 base + 3 位组号格式化,把第三层索引扩展为 $s_3' \leftarrow \text{format}(s_3, \text{004d}) \oplus \text{format}(g, \text{003d})$;构造新 SID $\langle s_1, s_2, s_3' \rangle$。
例:原 SID $\langle s_1^{(73)}, s_2^{(55)}, s_3^{(608)} \rangle$ 的过大簇被拆为 $\langle s_1^{(73)}, s_2^{(55)}, s_3^{(0608001)}\rangle, \langle s_1^{(73)}, s_2^{(55)}, s_3^{(0608002)}\rangle, \ldots$。
这一步保留 SID 前缀的层级结构——只在最末层做扩展,从而 beam search 仍可以沿层级剪枝;同时防止单一爆款簇主宰召回。
3.2 渐进式 Query-to-SID 学习¶
LLM backbone 选择 Qwen2.5-0.5B [11],理由是参数量和延迟可接受、足以覆盖商品语义。训练分四阶段,每阶段都建立在上一阶段权重之上:
Stage 1(Item2SID Mapping):构造 (item title, SID) 对做 SFT。让模型把商品文本描述与对应 SID 建立基础映射,为后续 query → SID 打基础。这个阶段相当于教 LLM 学会"读懂 SID"。
Stage 2(Query2SID Mapping):构造 (query, SID) 对。每条 query 对应若干个曾被点击/购买的 item,从中随机采样 $N=3$ 个 item 的 SID 作为 target。教模型把搜索意图映射到产品语义簇。
Stage 3(Personalized User+Query2SID Mapping):把 query 增广为 (user features, recent click sequence, query) 输入,target 仍为 SID。引入用户性别、年龄段、近期相关品类点击行为,让同一 query 在不同用户下生成不同的 SID 列表(个性化召回)。
Stage 4(Ranking-Aligned Refinement via EG-GRPO):前三阶段都最大化 click-likelihood,只学到了"用户点过的"。而下游排序需要更广更高质量的候选,因此第四阶段引入 RL 强化召回与排序对齐——具体为 §3.3 的 EG-GRPO。
3.3 Expert-Guided GRPO¶
3.3.1 多目标奖励¶
对每条 query $\mathbf{x}$,模型生成 $G$ 条 SID 输出 $\{o_1, \ldots, o_G\}$。每条输出按其与 ground-truth 用户行为的关系赋予奖励:
$$ R(o) = \begin{cases} 1.0, & \text{if } o \in \mathcal{P}_{\text{pay}}(x), \\ 1.0, & \text{else if } o \in \mathcal{P}_{\text{clk}}(x), \\ 0.5, & \text{else if } o \in \mathcal{P}_{\text{exp}}(x), \\ 0.1, & \text{else if } o \in \mathcal{S}_{\text{valid}}, \\ 0.0, & \text{otherwise.} \end{cases} \tag{8} $$
其中 $\mathcal{P}_{\text{pay}}, \mathcal{P}_{\text{clk}}, \mathcal{P}_{\text{exp}}$ 分别是被购买、点击、曝光的 item 对应 SID 集合,$\mathcal{S}_{\text{valid}}$ 是合法(存在于 lookup 表中)的 SID 集合。这把召回质量从二值(命中/不命中)推广到层级,让模型不仅追求点击命中、也兼顾曝光覆盖(下游排序可用的候选池广度)。
advantage 通过 group 内归一化:
$$A(o_i) = \frac{R(o_i) - \text{mean}(\{R(o_j)\}_{j=1}^G)}{\text{std}(\{R(o_j)\}_{j=1}^G)}. \tag{9}$$
标准 GRPO 目标(带 PPO clip):
$$\mathcal{L}_{\text{GRPO}}(\theta) = -\frac{1}{G}\sum_{i=1}^G \min\left(\frac{\pi_\theta(o_i \mid x)}{\pi_{\theta_\text{old}}(o_i \mid x)} A(o_i),\ \text{clip}\left(\frac{\pi_\theta(o_i \mid x)}{\pi_{\theta_\text{old}}(o_i \mid x)}, 1-\epsilon_{\text{clip}}, 1+\epsilon_{\text{clip}}\right) A(o_i)\right). \tag{10}$$
3.3.2 Expert Injection(核心创新)¶
作者观察到,在搜索日志中 click 与 purchase 信号极其稀疏,标准 GRPO 经常出现整个 group 全是 0 reward 的情况,使 advantage 全为 0、梯度无信号;少数命中又带来高方差更新。
EG-GRPO 的关键改造:在每个 group 内,从 ground-truth $\mathcal{P}_{\text{clk}}(x_b) \cup \mathcal{P}_{\text{exp}}(x_b)$ 中随机采样 $K$ 条 SID 作为伪生成响应注入策略组:
$$\mathcal{G}^{(b)} = \mathcal{G}_{\text{sampled}}^{(b)} \cup \mathcal{G}_{\text{expert}}^{(b)}, \quad \mathcal{G}_{\text{sampled}}^{(b)} \sim \pi_{\theta_\text{old}}, \quad \mathcal{G}_{\text{expert}}^{(b)} \sim \mathcal{P}_{\text{clk}}(x_b) \cup \mathcal{P}_{\text{exp}}(x_b).$$
扩展后的 group $\mathcal{G}^{(b)}$ 同时进入 reward 计算和梯度更新,相当于在每个 batch 都喂给策略一些"标准答案"作为 high-quality positive exemplars。
Algorithm 2(EG-GRPO) 输入:预训练模型 $M$,训练集 $\mathcal{D}_{\text{RL}}$,group size $G$,专家样本数 $K$; 初始化 $\pi_\theta \leftarrow M$; 对每个 epoch、每个 batch $\{x_1, \ldots, x_B\} \subset \mathcal{D}_{\text{RL}}$: 1. 对每个 $b$:从 $\pi_{\theta_\text{old}}$ 采样 $G$ 条 $\mathcal{G}_{\text{sampled}}^{(b)}$;从 $\mathcal{P}_{\text{clk}}(x_b) \cup \mathcal{P}_{\text{exp}}(x_b)$ 采样 $K$ 条 $\mathcal{G}_{\text{expert}}^{(b)}$; 2. $\mathcal{G}^{(b)} \leftarrow \mathcal{G}_{\text{sampled}}^{(b)} \cup \mathcal{G}_{\text{expert}}^{(b)}$; 3. 用公式 (8) 算 $R(o)$,公式 (9) 算 advantage; 4. 计算 $\mathcal{L}_{\text{GRPO}}$,更新 $\theta$。
直觉上 expert injection 起到三重作用:
- 梯度去稀疏化:每个 group 现在保证至少有 $K$ 条非零 reward,policy 总能拿到有效更新方向;
- 方差抑制:高质量 positives 锚定 group 均值,降低 advantage 估计的高方差;
- 隐式课程学习:expert 样本作为"软上限"持续给 policy 展示什么样的输出值得被强化。
3.4 在线推理与 Item 过滤¶
线上服务流程:(1) 拼接 user feature 与 query feature;(2) 模型 beam search 生成 top-K SID;(3) 通过预建 SID-to-Items lookup 表把 SID 还原为具体 item。
为保证质量,作者把全量亿级商品过滤成约 2100 万 条 high-efficiency subset 作为生成式召回池,每天滚动更新——新增的高质量 item 通过 CQ-SID 做推理后挂到对应语义簇下。
实验设置¶
数据集:来自一个大型移动电商平台的真实搜索日志。
- CQ-SID 训练:37.5M 样本(21.1M query-item pair + 16.4M item-only);
- LLM 渐进训练:Item2SID 21.0M / Query2SID 90.3M / UQ2SID 73.7M;
- 测试:Query2SID 201k、UQ2SID 170k。
评估指标:主指标 Hitrate(在召回列表中命中至少一条 ground-truth click 的比例)。由于不同 SID 体系对应的"每 SID 下的 item 数量"差异极大,在同 beam size 下比较不公平,作者从两个维度评估: 1. Same beam size:固定 beam size,衡量 inference-efficiency-adjusted quality; 2. Top-1K truncation:按 product-efficiency score 截断到 1K item,模拟真实漏斗的截断逻辑。
Baselines:标准 RQ-VAE [13, 24],并对 CQ-SID 做两个消融——w/o Cate(去类目约束)和 w/o QI(去 query-item 对比学习)。所有 LLM-based 方法均用 Qwen2.5-0.5B [11]。
实现细节:CQ-SID 用 codebook size $[2048, 1024, 1024]$,4 张 GPU 训练 10 epochs,batch size 4096,cosine LR $10^{-3}$,loss 权重 $\beta=1.0$、$\gamma=0.001$、温度 $\tau=0.1$、对比 sample size $b=128$。LLM 在 64 GPU 上训练:I2SID batch 128、LR $10^{-4}$、2k steps;Q2SID batch 256、LR $4\times 10^{-5}$、2.5k steps;UQ2SID batch 64、LR $4\times 10^{-5}$、5k steps;EG-GRPO rollout batch 512、group size 8、KL 权重 1.0、LR $10^{-6}$、1k steps。
主要实验结果¶
4.1 语义生成式召回(Same Beam Size)¶
Table 1: 同 beam size 下 click hitrate。
| Method | beam@1 | beam@10 | beam@100 |
|---|---|---|---|
| RQ-VAE | 0.0598 | 0.2579 | 0.5199 |
| CQ-SID (w/o Cate) | 0.0680 (+13.71%) | 0.2870 (+11.28%) | 0.5578 (+7.29%) |
| CQ-SID (w/o QI) | 0.0596 (-0.33%) | 0.2691 (+4.34%) | 0.5652 (+8.71%) |
| CQ-SID | 0.0758 (+26.76%) | 0.3161 (+22.57%) | 0.6181 (+18.89%) |
结论:在 beam@1 上 CQ-SID 相对 RQ-VAE 提升 26.76%,beam@100 仍提升 18.89%。两条消融揭示——类目约束(w/o Cate 去除后只剩 +13.71%)与 query-item 对比(w/o QI 去除后只剩 -0.33%)有强互补性,二者协同贡献了主要增益。Q-I 对比单独效果有限,说明它真正的作用是给 codebook 学到"语义相关"以外的"用户搜索意图相关"信号。
4.2 Top-1K Truncation 比较¶
Table 2: top-1K 截断下 click hitrate。
| Method | b@25 | b@30 | b@35 | b@60 | b@65 | b@70 |
|---|---|---|---|---|---|---|
| RQ-VAE | 0.3675 | 0.3870 | 0.4016 | 0.4272 | 0.4275 | 0.4272 |
| CQ-SID | 0.4370 | 0.4422 | 0.4403 | 0.4001 | 0.3911 | 0.3825 |
结论:RQ-VAE 在 beam@65 达峰 0.4275,CQ-SID 在 beam@30 即达 0.4422,相对提升 +3.44%、同时 beam size 减少 53.85%。这是工业落地的关键——更小 beam 直接转化为更低 latency 与计算成本。
更值得注意的是 CQ-SID 在 beam>60 之后 hitrate 反而下降。作者解释:CQ-SID 由于聚类机制,高置信度 SID 已经在前几个 beam 内覆盖了大部分相关 item;继续加大 beam 反而引入低置信度 candidates 稀释 1K 截断池,下游 ranking 能力可能不足以再过滤——召回宽度必须与下游 ranking 能力匹配。
4.3 个性化生成式召回¶
Table 3: 个性化场景 click hitrate。
| Same Beam Size | beam@1 | beam@10 | beam@50 | beam@100 |
|---|---|---|---|---|
| RQ-VAE | 0.1359 | 0.4787 | 0.6912 | 0.7513 |
| CQ-SID | 0.1510 (+11.11%) | 0.5206 (+8.75%) | 0.7431 (+7.51%) | 0.8062 (+7.31%) |
| Top-1K Truncation | beam@155 | beam@160 | beam@190 | beam@195 |
|---|---|---|---|---|
| RQ-VAE | 0.7567 | 0.7575 | 0.7604 | 0.7607 |
| CQ-SID | 0.7983 | 0.7984 | 0.7977 | 0.7975 |
个性化场景下 CQ-SID 在 beam@160 达 0.7984,相对 RQ-VAE 峰值(beam@195 的 0.7607)+4.96%,beam size 减少 17.95%。
4.4 EG-GRPO Ranking 对齐¶
Table 4: EG-GRPO 对 ranking 对齐的影响。
| Method | clk@1 | clk@10 | exp@1 | exp@10 | pvr@10 |
|---|---|---|---|---|---|
| CQ-SID | 0.1510 | 0.5206 | 0.5056 | 0.8693 | 0.4371 |
| + GRPO (K=0) | 0.1519 | 0.5196 | 0.5077 | 0.8702 | 0.4360 |
| + EG-GRPO (K=2) | 0.1524 | 0.5221 | 0.5091 | 0.8703 | 0.4377 |
| + EG-GRPO (K=4) | 0.1523 | 0.5219 | 0.5087 | 0.8711 | 0.4378 |
其中 clk = click hitrate,exp = exposure hitrate(曝光召回),pvr = average exposure coverage ratio。$K$ 是注入 group 的 expert SID 数量。
关键发现:
- 标准 GRPO(K=0)暴露非对称坍塌:clk@1 微涨但 clk@10 退化,pvr 也下降。这是稀疏奖励下 GRPO 把概率质量集中到少数高置信 SID(top-1 sharpening)的副产物——虽然 top-1 命中率提升了,但 top-10 多样性垮了,曝光覆盖也下降;本质上是从 exploration 滑向纯 exploitation。
- K=2 / K=4 expert 注入全面改善:clk、exp、pvr 都同步上升,证明 expert injection 缓解了 variance-induced collapse。K 增大时 click 类指标会饱和、exposure 出现 beam@1 vs beam@10 的"翘翘板",但全部仍优于无 expert 基线。
- 改善幅度看起来不大——但作者强调这是质变而非量变:(1) 三阶段 SFT 已经把 query-to-SID mapping 推到了局部最优附近,RL 顶上空间天花板很低;(2) hitrate 是二值指标,只要 target SID 已在 beam 里再优化也无意义;(3) EG-GRPO 同时在 click 与 exposure 两个相互冲突的目标上做 Pareto 改进——standard GRPO(K=0)已经显示 trade-off 真实存在,能做到三个指标同步正向是更难的目标。
4.5 在线 A/B 测试¶
部署在 TmallAPP 移动电商搜索:8 GPU、~200 QPS,dynamic beam@{20, 50, 100},serving availability 99.9%、端到端延迟约 40ms。两周 A/B 实验显示多渠道召回阶段稳定提升:
- GMV +1.15%
- UCTVR +0.40%
更重要的是部署后该生成式召回单链路贡献了:
- 全平台 50.25% 的曝光、
- 58.96% 的点击、
- 72.63% 的购买。
与已归档相关工作的对比¶
ReCast ReCast (Huawei, 2026-04-24)¶
关系:独立并发(本文未引用 ReCast,两者殊途同归)· 已加载对方精读
- 共同关注的问题:生成式推荐 RL 阶段的"稀疏命中下 GRPO 信号坍塌"。ReCast 在 OpenOneRec 设置下定量观察到训练 20K 步后 ~85% 的 group 仍是 all-zero、~96% 的样本仍是 zero-reward;本文同样指出 click/purchase 信号"极其稀疏",标准 GRPO 在 (Table 4 K=0) 出现 mode-concentration 与 pvr 退化的非对称坍塌。两者把根因都归结到"sampled group 已经是 usable learning unit"这条隐含假设的破裂。
- 相近的技术骨架:两者的解法骨架几乎可以一句话概括——用 ground-truth 派生的高质量正例显式注入 policy group,把 group 从"无可学边界"拉到"至少有正例可学"的状态。本文 EG-GRPO 注入 $K$ 条来自 $\mathcal{P}_{\text{clk}} \cup \mathcal{P}_{\text{exp}}$ 的 SID(等同于 ReCast 的 $R^{\text{anc}}$ derived from $R^\star$),随后照常做 within-group reward 归一化更新。
- 本文的差异与推进:(1) ReCast 仅在 group 整组为 0 时才触发 anchor 注入并替换"最不 informative"的那条样本;本文是无条件注入,所有 group 都加 $K$ 条 expert,相当于让 expert 持续作为 high-quality exemplar 拉高 group baseline;(2) ReCast 注入后做 boundary contrastive update(只挑 top-1 positive + hardest near-miss 一对样本赋 advantage);本文保留全组 reward normalization,让 expert 与 sampled outputs 同台竞争;(3) 本文给出 $K=2 / K=4$ 实验,发现 click 类指标饱和而 exposure 出现 seesaw(与 ReCast 没有展开 multi-K 消融形成对比)。
- 可比的方法 / 实验差异:ReCast 进一步把"search width"与"actor update width"解耦($W_{\text{update}} = O(1)$)以省 actor-side 计算;本文没有这一系统层优化,但也没必要——其 group size 默认 $G=8$,actor 端开销本就小,且 $K \le 4$ 完全在可承受范围。
DIG DIG (Meituan, 2026-05-14)¶
关系:独立并发(同日 arXiv,两者未互相引用)· 已加载对方精读
- 共同关注的问题:把"召回的生成式范式"与"排序的判别式范式"对齐到同一个 SID/token 表示上。DIG 把根因归结为"existing SIDs are severely under-personalized"——SID 由 reconstruction/contrastive 损失驱动,与下游排序的判别梯度毫无连接。本文的对应表述是 Challenge 3:召回模型只学"用户点过的",无法生成下游 ranking 真正可用的高质量候选。
- 相近的技术骨架:两者都意识到 SID 必须承担两重角色——既是召回 beam search 的语义簇接口,又是 ranking 的 personalization-aware 接口;都拒绝把 tokenization 与 ranking 当作独立 stage。
- 本文的差异与推进:(1) 解决路径完全相反——DIG 是"架构层耦合":把 RQ tokenizer 嵌入 DIN+DCNv2+MoE ranker 内部,让 ranking BCE loss 直接驱动 codebook 构造;本文是"训练课程层耦合":codebook 还是独立的 RQ-VAE(加 category 约束 + Q-I 对比),但通过四阶段 progressive SFT + EG-GRPO 让 LLM 端学到 ranking-aligned generation。(2) 个性化注入位置不同——DIG 通过 u2t 蒸馏在推理时注入 user-token cross feature;本文在 Stage 3 把 user feature 直接拼进 LLM input,让同一 query 在不同用户下产生不同 SID。(3) DIG 在公开 benchmark 上报 +52%~+220% R@10 提升;本文报 +26.76% click hitrate 与 +1.15% GMV。两者都自称 SOTA,反映出 e-commerce 生成式召回这个方向尚未收敛到统一评测范式。
- 可比的方法 / 实验差异:DIG 测的是 GR 召回-排序联合 metric,本文只测召回 hitrate;DIG 没有 RL 阶段,本文有 EG-GRPO;DIG 的 codebook 与 ranker 反向梯度联动比本文的 progressive SFT 更激进,但工程复杂度也更高(需要解决 STE 与 BCE loss 的稳定性问题)——本文走的是生产部署友好的折中路径。
AdaSID AdaSID (UESTC + Kuaishou, 2026-04-26)¶
关系:独立并发(本文未引用 AdaSID)· 已加载对方精读
- 共同关注的问题:处理 SID 在亿级 item 库下的"碰撞"问题。AdaSID 把 collision 当作"既有有害也有良性"的混合信号;本文同样承认 collision-free 在工业场景不可达。
- 相近的技术骨架:两者都不再追求 absolute one-item-one-ID,而是承认 SID 必须容忍某种程度的 item 共享——但这个表面相似下藏着一个截然相反的设计哲学。
- 本文的差异与推进:AdaSID 走的是"有差别的抑制"——SeAR 阶段判断每个 overlap 是否仍应被推开,LAS+PAR 阶段对剩余 overlaps 自适应调节排斥强度;目标仍然是"最终让有意义的 item 落到不同 SID"。本文走的是"主动拥抱 collision"——CQ-SID 显式把同类目 item 强制合并到同一第一层 codebook bin(公式 1),并让 query-item 对比对齐进一步把语义相关的 item 聚合;后处理 Algorithm 1 只在簇过大时才做随机切分(保层级前缀)。两者方向完全相反:AdaSID 把 collision 视作要消除的现象(哪怕做得更精细),本文把 collision 视作要保留的设计选择(簇 ID 而非唯一 ID)。
- 可比的方法 / 实验差异:AdaSID 在 Amazon Toys/Beauty 公开 benchmark 上 NDCG/Recall 平均提升 ~4.5%,并在快手电商 +0.98% GMV;本文在 TmallAPP 真实搜索日志 +26.76% click hitrate、beam size -53.85%、+1.15% GMV。两者都做了工业 A/B,但 AdaSID 的目标是"提升判别质量",本文是"在保留召回质量的同时压低 latency"——这正好对应了 collision 处理两种哲学的不同价值取向。
讨论与局限性¶
核心贡献。 本文把生成式检索从"端到端替代漏斗"的乌托邦设想拉回到"作为漏斗中召回阶段的强化补充"的工程现实。三个设计选择都极具落地价值: 1. CQ-SID 的"簇 ID"设计:用 category 强约束 + Q-I 对比把 codebook 训练成"语义+意图"双重对齐的语义簇,主动放弃唯一性以换取 inference 效率。这是对 TIGER/RQ-VAE 范式的一次深度反思——唯一性是不必要的,工业可用性是必要的。 2. Progressive 4-stage 训练:从 Item2SID 到 Q2SID 再到 personalized 再到 RL 对齐,每一步都建立在前一步基础上,避免了 LLM 直接被 RL 撕坏;这种 SFT-curriculum-then-RL 的范式与 InstructGPT / DeepSeek 的训练流水线哲学一致。 3. EG-GRPO 的 expert injection:用最小的代码改动解决了稀疏奖励 GRPO 的最棘手问题,是对 GRPO family 在生成式检索这个特殊 domain 的一次本质适配。
值得借鉴的设计。 类目约束的第一层 codebook 公式 (1) 把"业务体系(taxonomy)"作为 quantization 的 hard constraint,是把 domain knowledge 注入 representation learning 的优雅范例——以后做工业 SID 时,这种"用现成业务体系充当首层离散结构"的思路应该是默认选项。后处理 Algorithm 1 的"保前缀的末层切分"也很巧妙:它隔离了"控制簇大小"与"破坏层级结构"两件原本耦合的事情。
局限与争议。
- K 选择缺乏理论指导:EG-GRPO 的 expert injection 数量 $K$ 在论文中只展示了 K=2/4,更大 K 会不会反过来吞噬 exploration(因为 expert 总能赢得 reward 比较)?文中未给出系统消融。
- 第一层强制类目约束的代价:Eq. (1) 假设 known category 的 item 直接用 CategoryID 作 first-level index,但当电商类目本身有歧义、有 noise(同一商品挂在多个类目下)时,这种硬约束会引入 mis-clustering。论文未讨论。
- 2100 万 high-efficiency subset 的过滤策略:从亿级 item 池筛到 21M 是关键的工程决策,但论文几乎没说怎么筛、按什么标准。这部分在线推理之前的过滤管线对最终业务指标的贡献可能不亚于 CQ-SID/EG-GRPO 本身。
- 与 OneSearch / OneSearch-V2 的定位差异未充分对比:作者只在 §1 提了一句 Kuaishou OneModel 系列追求端到端、本文走 recall supplement 路线,但缺乏数据级对比(同样规模 item 库下,端到端 vs 召回补充哪种 GMV/latency trade-off 更优?)。
工业部署亮点。 一周 A/B 后该生成式召回单链路贡献了平台 50.25% 曝光 / 58.96% 点击 / 72.63% 购买——这意味着它已经成为 TmallAPP 搜索召回主链路之一,而不是"实验性 channel"。同时端到端延迟仅 40ms,证明 CQ-SID 的 cluster-style 设计确实把 GR 推到了延迟敏感生产场景的可部署区间。从 GR 的工业落地视角看,这篇是少数把"让 GR 在亿级电商搜索真正跑起来"的工程要素全部讲清楚的论文,其方法和经验对其他工业 SID-based 召回系统具有直接借鉴价值。