TwiSTAR: Think Fast, Think Slow, Then Act — Generative Recommendation with Adaptive Reasoning¶
作者:Shiteng Cao, Kaian Jiang, Yunlong Gong, Zhiheng Li 机构:清华大学深圳国际研究生院 (Tsinghua Shenzhen International Graduate School) ArXiv:2605.11553 · 2026-05-12 · Preprint
1. 研究动机与背景¶
基于 Semantic ID 的生成式推荐(Generative Recommendation with SIDs)近年来成为继 ID-embedding 范式之后的主流方向:每个 item 经过 RQ-VAE 残差量化后压缩为一组 hierarchical SID token,加入 LLM 词表后,推荐被改造为"给定历史 SID 序列、自回归预测下一个 SID"的语言建模任务。TIGER、HSTU、LC-Rec、PLUM、TS-Rec 等工作沿这一路线推进。
两种推断模式已经在工业部署中并存:
- Fast thinking(直接生成):直接在 SID 词汇上 beam search 预测下一个 item,单步前向延迟低,适合规律性、常见的浏览模式。但在长尾、模糊、多兴趣冲突的复杂用户历史上经常掉点(论文称为 hard / sparse / ambiguous 样本)。
- Slow reasoning(CoT 推理):先输出一段 chain-of-thought(解释为什么要推荐某 item),再生成 SID。OneRec-Think、SIDReasoner、GREAM 等近期工作显示对长尾样本有显著提升、可解释性也更好;但 CoT token 生成一次约 1.6 s,相对 SID 解码的 0.16 s 慢一个数量级,在线服务无法接受。
作者归纳的核心 gap:现有方法采用"固定推断策略"——要么全量 fast,要么全量 slow,要么是预先约定的多模式但开关方式是启发式(如 OxygenRec),没有一个工作让推荐器学会根据用户历史的难度自适应选择推理强度。这带来双重损失:
- fast-only 系统在 hard 样本上欠拟合:长尾、新兴趣、罕见组合的预测准确率显著下降;
- slow-only 系统在 easy 样本上既浪费算力又可能掉点:在简单/高频样本上引入冗长 CoT 反而引入生成噪声,干扰直接的协同匹配。
由此提出本文的核心问题:Can a generative recommender learn when to think fast and when to think slow? 灵感来自双系统认知(System 1/System 2)与近期 LLM 的自适应推断(Qwen3, Phi-4-reasoning, Claude 3.7)。
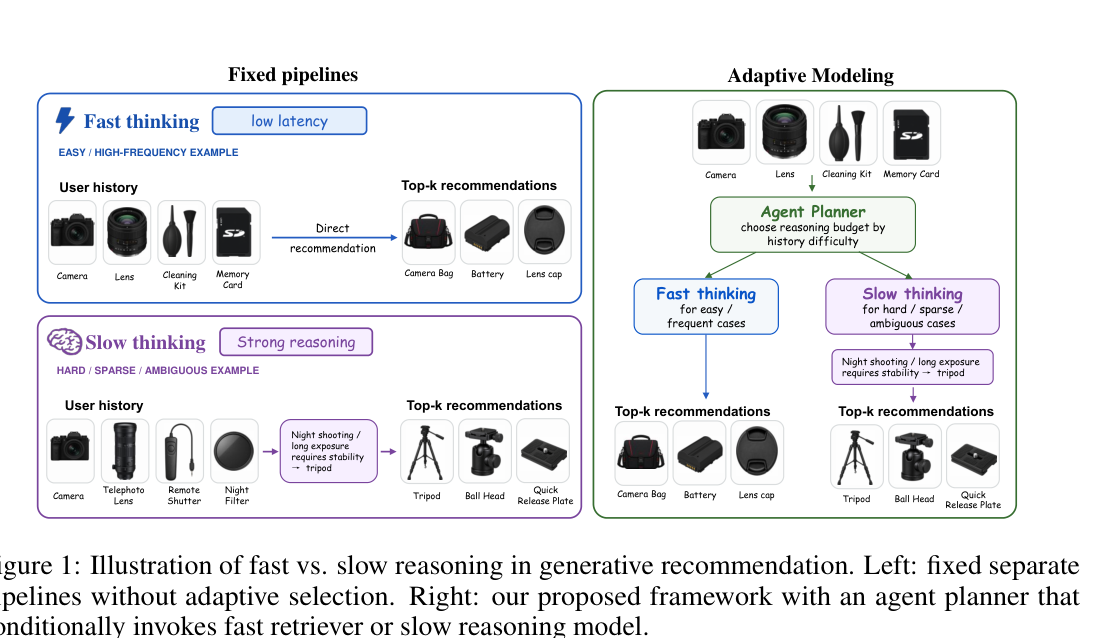
TwiSTAR(Two-mode thinking, Slow and fast Thinking, then Act with tools to Recommend)由此提出,其核心思想是把整个推荐系统重构为一个 agentic 系统,由一个 learned planner 在三种工具(fast retriever、rank tool、slow think-and-rec)之间动态调度。三个主要贡献:
- 一种把 LLM-based 推荐里隐式协同信号显式语言化的方法:把 I2I 共现关系转写为自然语言解释,作为推理增强训练数据;
- 一套两阶段训练流程(监督模仿 + agentic RL),教会 planner 选择性调用 slow reasoning,统一 fast SID 生成、slow 推理与 adaptive routing 在单个 agentic 系统里——据作者声称这是首个在生成式推荐里学习何时调用推理的工作;
- 在三个公开数据集(Beauty / Toys / Sports)上的广泛实验,显示同时在排序精度和推理效率上都优于强 baseline(包括 OneRec-Think)。
2. Related Work 的两条线¶
2.1 LLM as Recommender¶
LLM 用于推荐分两支:
- 基于原生文本词表:M6-Rec、TALLRec、LLMTreeRec、Bi-step Tuning、On-softmax DPO、InteraRec、P5、RLP 等用 product description / instruction prompting / hierarchical attribute / multimodal item / language formulation 把 item 嵌入 LLM 的 native vocabulary,灵活、可解释,但对大规模目录而言效率不足且无法 grounded 到唯一 catalog item。
- 基于 Semantic ID:TIGER 引入 RQ-VAE 量化的 hierarchical SID 后,LC-Rec、PLUM、TS-Rec 等讨论了 SID-token 与语言语义的对齐;OneRec-Think、SIDReasoner 把显式推理引入 SID 生成;OxygenRec、PLUM、Spotify 部署、Snowflake/Tencent NewsRec-Chat 验证了 LLM-based SID recommender 的工业可行性。
作者批评所有现有方法都"applying the same inference strategy regardless of query difficulty"——更严重的是,当 fast 模型已经能处理大量 easy 样本时,强行用 slow 推理反而会让 slow 模型表现下降(论文 6.4 节实证)。
2.2 Agent for Recommender¶
近期 agentic 推荐工作有 AMEM4Rec(cross-user evolving memory)、RecGPT-V2(hierarchical multi-agent for industrial intent reasoning)、RecBot、TalkPlay(interactive natural-language requests),它们关注 process-level 决策但只 optimize 推荐过程的某一方面,且未解决 SID-based 生成式推荐在异构用户历史下应该联合分配 inference behavior 的问题。TwiSTAR 把生成式推荐重构为 agentic inference problem:模型不仅要决定 what to recommend,还要决定 how to recommend(fast、rank、slow)。
3. Preliminaries:Semantic ID 与自回归生成式推荐¶
每个 item $i \in \mathcal{I}$ 经文本编码器映射为连续嵌入:
$$\mathbf{e}_i = \text{Encoder}(t_i). \tag{1}$$
随后用 residual k-means(注:TIGER 用 RQ-VAE,本文略简化为 k-means,但结构等价)做 $L$ 层量化,codebook 每层大小 $K$。从 $\mathbf{r}_{i,0}=\mathbf{e}_i$ 开始迭代:
$$c_{i,j} = \arg\min_{k \in \{1,\dots,K\}} \|\mathbf{r}_{i,j-1} - \mathbf{v}_{j,k}\|_2^2, \quad \mathbf{r}_{i,j} = \mathbf{r}_{i,j-1} - \mathbf{v}_{j,c_{i,j}}, \tag{2}$$
得到 Semantic ID:
$$\text{SID}(i) = [c_{i,1}, c_{i,2}, \dots, c_{i,L}]. \tag{3}$$
实验配置 $L=3, K=256$,共 $3 \times 256 = 768$ 个 SID token 加入 LLM 词表。
对用户 $u$,把历史交互 $\mathcal{H}_u = [i_1, \dots, i_{T-1}]$ 每个 item 替换为 SID 后,sequential recommendation 改写为条件自回归生成:
$$p(\text{SID}(i_T) \mid \text{SID}(i_{\lt T})) = \prod_{j=1}^L p(c_{i_T,j} \mid c_{i_T,\lt j}, \text{SID}(i_{\lt T})). \tag{4}$$
beam search + prefix trie 约束保证生成的 SID 在合法目录内。
4. 方法¶
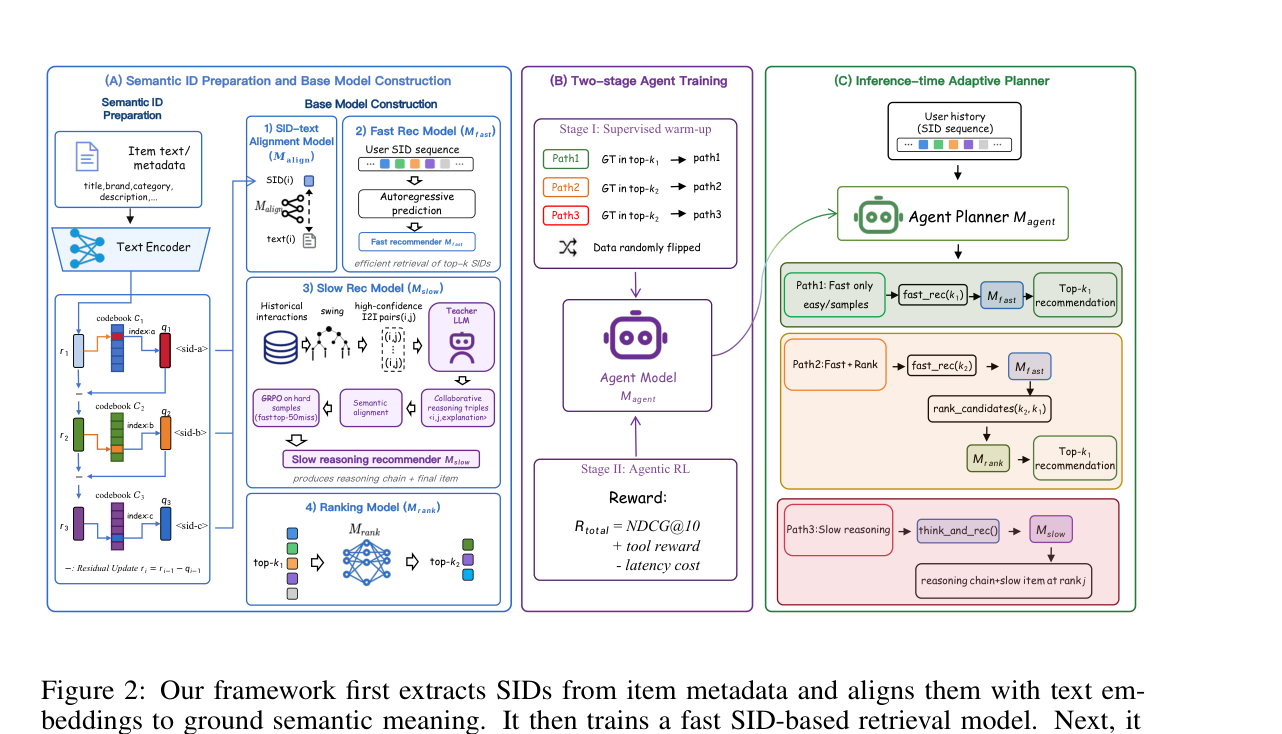
TwiSTAR 包含四个 sub-model 加一个 planner agent:
- $\mathcal{M}_\text{align}$:把 SID token 与文本语义打通的对齐基模型;
- $\mathcal{M}_\text{fast}$:在 $\mathcal{M}_\text{align}$ 之上 fine-tune 的 fast SID retrieval model;
- $\mathcal{M}_\text{rank}$:基于 Deep Interest Network 的判别式重排器;
- $\mathcal{M}_\text{slow}$:注入了 collaborative commonsense + GRPO 训练得到的 think-then-recommend 模型;
- $\mathcal{M}_\text{agent}$:决定每次请求调用哪个工具的 planner。
4.1 Aligned Base Model $\mathcal{M}_\text{align}$¶
核心挑战:通过 residual k-means 得到的 SID 是没有任何语言学含义的全新离散符号,预训练 LLM 无法直接解释这些 token 来做 next-item 预测。TwiSTAR 把每个 item 的 SID 与其文本元数据(标题、品类、其他属性)拼接成对齐序列,喂入预训练 causal LM,按标准 next-token loss 优化:
$$\mathcal{L}_\text{align} = -\sum_{i \in \mathcal{I}} \sum_{m=1}^{|x_i|} \log p_\theta(x_{i,m} \mid x_{i,\lt m}). \tag{5}$$
注意此时保留 LLM 主体参数不冻结,仅微调让 SID token 嵌入与文本语义共享空间(Implementation Details 中说明只 freeze 文本词表 embedding,所有其他参数微调 3 epoch、lr=2e-5、cosine decay、batch=64、max_len=512)。对齐后,SID token 不再是不透明符号,而是带有语义锚定的 item 表示,作为后续 fast/slow/agent 三件组件的共同基座。
4.2 Fast Rec Model $\mathcal{M}_\text{fast}$ 与 Ranker $\mathcal{M}_\text{rank}$¶
Fast Rec Model¶
在 $\mathcal{M}_\text{align}$ 之上,把训练样本按时间截断成"历史 SID → 目标 SID"对,按 SID 顺序自回归预测目标 SID:
$$\mathcal{L}_\text{rec} = -\sum_u \sum_t \sum_{\ell=1}^L \log p_{\mathcal{M}_\text{fast}}(c_{t,\ell} \mid c_{t,\lt \ell}, \text{SID}(i_{\lt t})). \tag{6}$$
推理时用 prefix-trie-constrained beam search(width $k=50$,length penalty $1.0$)得到 top-$K$ 候选,作为 fast 路径的输出。LR=1e-5, batch=128, 5 epoch。
Ranking Model¶
$\mathcal{M}_\text{rank}$ 是基于 Deep Interest Network (DIN) 的判别式重排器:对历史序列与候选 item 之间做 local activation。训练样本构造:每个 user 用 $\mathcal{M}_\text{fast}$ 检索 $K_2$ 个候选;若 ground-truth 出现在该 set 内则它直接是正样本,否则把 GT 强插入 set 作为正样本,并从剩余检索结果里采样 $K_1 - 1$ 个负样本。AUC on val set 用于 early stopping。$K_2=50, K_1=10$。
4.3 Slow Rec Model $\mathcal{M}_\text{slow}$:Collaborative Reasoning as Language Injection¶
这是 TwiSTAR 的核心 novelty 之一。问题动因:直接对 LLM 做"为什么用户会点击 next item"的 explanation 监督 fine-tune 很容易幻觉——next item 只是众多可能的一种,模型会过拟合到偶然的序列共现而非稳定的统计模式。而 I2I 共现统计跨大量用户聚合,提供更密集、更可靠的信号;让模型从 I2I 解释中学习,等于让它内化稳定共现规律而非记忆脆弱序列。
步骤 1:从 I2I 关系蒸馏自然语言解释¶
对每对相关 item $(i, j)$(在同 session 或序列内共现),用 teacher LLM(Qwen3.5-397B-A17B)回答 prompt:
"In collaborative filtering, item $i$ and item $j$ are highly correlated. Please explain why users who purchase $i$ also tend to purchase $j$?"
经过低质量过滤(长度 $\lt 30$ token 等),得到 $\langle i, j, \text{explanation}\rangle$ 三元组。Beauty 数据集最终保留 ~20k 高质量三元组。
把这些三元组与原对齐数据按 1:1 混合,对 $\mathcal{M}_\text{align}$ 继续 fine-tune 2 个 epoch、LR=1e-6。结果是一个具备 collaborative commonsense 的模型 $\mathcal{M}_\text{base}^\text{slow}$——它不再死记 I2I table,而是学会用自然语言阐述协同过滤逻辑,从而具备零样本泛化未见对的能力。
步骤 2:think model 的 GRPO 训练¶
挑选 $\mathcal{M}_\text{fast}$ HitRate@50 落榜的 hard 样本作为训练子集,用 GRPO(DeepSeekMath, Shao 2024)训练 $\mathcal{M}_\text{slow}$ 产出 chain-of-thought + SID 答案。只用 hard 样本是关键——RQ4 实证显示,在 full data 上训 think model 会让其在 hard 样本上比 fast 模型还差(见 4.4 RQ4)。
奖励函数(详见附录 A):
$$R_\text{slow} = \lambda_\text{think} r_\text{think} + \lambda_\text{sid} r_\text{sid} + \lambda_\text{hit} r_\text{hit}. \tag{8}$$
三个分量:
-
Reasoning Presence $r_\text{think}$:检查
<think>...</think>标签存在且字符长度 $\geq 20$: $$r_\text{think} = \begin{cases} +1 & \text{if `\lt think\gt ...\lt /think\gt ` exists and len} \geq 20, \\ -1 & \text{otherwise.} \end{cases} \tag{9}$$ -
SID Format Correctness $r_\text{sid}$:严格匹配
<|sid_begin|><s_a_#><s_b_#><s_c_#><|sid_end|>格式给 +1,软匹配(resembling)给 +0.2,无效给 -1: $$r_\text{sid} = \begin{cases} +1 & \text{strict format matched,} \\ +0.2 & \text{soft SID pattern matched,} \\ -1 & \text{no valid SID found.} \end{cases} \tag{10}$$ -
Hierarchical Hit Reward $r_\text{hit}$:把 SID 解析为三层 $(a,b,c)$,按最长匹配前缀分级打分: $$r_\text{hit} = \begin{cases} 0 & \text{no prefix match,} \\ 1.0 & \text{only $a$ matches,} \\ 2.0 & \text{$a, b$ match,} \\ 5.0 & \text{$a, b, c$ match.} \end{cases} \tag{11}$$
权重 $\lambda_\text{hit}=5.0, \lambda_\text{format}=1.0$(论文 E.1.3)。max generation length = 256 tokens。Hierarchical reward shaping 的设计动机:当模型不能完全命中目标 SID 时,匹配高一级前缀(即落入正确品类/子品类)仍然给予逐级密集信号,避免 0/1 reward 在生成式推荐里的稀疏性问题。
4.4 Planner Agent $\mathcal{M}_\text{agent}$:Two-Stage Training¶
冻结 $\mathcal{M}_\text{fast}, \mathcal{M}_\text{slow}, \mathcal{M}_\text{rank}$ 后,从 $\mathcal{M}_\text{align}$ 初始化一个 agent,让它接收用户 SID 序列、输出工具调用。Tool API:
fast_rec(k):调 $\mathcal{M}_\text{fast}$ beam search 出 $k$ 个 SID;rank_candidates(m, n):先fast_rec(m)拉取候选,再调 $\mathcal{M}_\text{rank}$ 重排取 top-$n$;think_and_rec(j):调 $\mathcal{M}_\text{slow}$ 产出 reasoning chain 后 beam search 出 $j$ 个 SID 作为最终结果。
Stage 1:Supervised Warm-up(监督模仿三条 Path)¶
为每条 user sequence 离线产生伪标签 path:先用 $\mathcal{M}_\text{fast}$ 检索 $K_2=50$ 个候选,再判定:
- Path 1(fast only):若 ground-truth 已在 fast 检索结果的小 candidate set($K_1$)内,agent 调用
fast_rec(K_1),$K_1=10$; - Path 2(fast + ranking):用 $K_2=50$ 检索一个更大集合;若 GT 在其中作为正样本,否则强插入 GT 并从检索结果采样负样本;agent 调用
rank_candidates(50, 10); - Path 3(slow reasoning):调用
think_and_rec(K_1)让 $\mathcal{M}_\text{slow}$ 产生 reasoning chain 后 beam search 出 $K_1$ 个 SID 作为 top-$K_1$。
为了增加探索性,随机以 20% 概率把原本属于 Path 1 的样本翻转到 Path 2 或 3——这一关键正则防止 supervised warm-up 退化为"什么都用 fast"的退化解。
监督 loss 是 cross-entropy on tool call token sequence。生成 100k 用户序列伪标签,训练 3 epoch、LR=1e-5、batch=32。Tool call 用 JSON 结构化输出。
Stage 2:Agentic RL¶
继续用 GRPO 或 PPO 微调 $\mathcal{M}_\text{agent}$ 2 epoch,奖励函数:
$$R_\text{total} = \underbrace{\text{NDCG@10}(\text{final ranked list})}_\text{outcome reward} + \underbrace{\eta \cdot \mathbb{I}[\text{valid tool sequence}]}_\text{process reward} - \beta \cdot \text{latency cost}. \tag{7}$$
这条奖励信号体现三件事:
- Outcome reward:最终 top-$K$ 排序的 NDCG@10——任何路径,只要最终结果好,给奖励;
- Process reward:工具调用序列合法(参数、顺序、JSON 格式)给 $\eta$ 奖励,防止 agent 退化为乱调用;
- Latency cost:调用
think_and_rec远比fast_rec慢,因此用 $\beta$ 惩罚总推断延迟,激励 agent 只在必要时调慢路径。
Algorithm 1 Planner Agent Training (paper Appendix B)
Input: User sequences U, ground-truth items, base models M_fast, M_slow, ranker M_rank
Stage 1: supervised warm-up
for each user u in U do
candidates_50 ← M_fast(u, k=50)
Determine path (1/2/3) based on hit position of GT
With 20% probability, flip path 1 to 2 or 3
Record required tool call sequence as label
end for
Train M_agent via cross-entropy on tool call sequences
Stage 2: Agentic RL
Freeze M_fast, M_slow, M_rank
Optimize M_agent with GRPO using R_total
return Trained agent M_agent
5. 实验设置¶
数据集:Amazon review 三个公开 benchmark——BEAUTY、TOYS AND GAMES、SPORTS AND OUTDOORS(Julian McAuley 2015 数据)。leave-one-out 划分:每个用户最后一次交互 hold out 做 test,倒数第二做 val,其余训练。评估在全 catalog 上而非 sampled negatives(这是公平 setting,避免 popularity-biased sampling 假象)。
Baselines:
- 传统序列推荐:HGN、GRU4Rec、SASRec;
- 生成式推荐:TIGER(RQ-VAE + 自回归 SID 解码)、HSTU(Meta 工业大模型,重新调整到 Amazon benchmark);
- 推理增强推荐:OneRec-Think(itemic alignment + 多任务预训练 + reasoning activation,最相关竞争者,统一使用相同 reasoning strategy,无 planner)。
实现细节:基座 LLM 是 Qwen3.5-4B;8 张 A100 80GB GPU;$L=3, K=256$(768 个 SID token)。
Metrics:Recall@K 与 NDCG@K,$K \in \{5, 10\}$。
6. 实验结果¶
6.1 RQ1:Overall Performance¶
Table 1: Overall performance comparison on three datasets.
| Dataset | Metric | HGN | GRU4Rec | SASRec | TIGER | HSTU | OneRec-Think | TwiSTAR |
|---|---|---|---|---|---|---|---|---|
| Beauty | R@5 | 0.0325 | 0.0392 | 0.0397 | 0.0409 | 0.0418 | 0.0557 | 0.0609 |
| R@10 | 0.0531 | 0.0585 | 0.0606 | 0.0622 | 0.0648 | 0.0770 | 0.0880 | |
| N@5 | 0.0197 | 0.0263 | 0.0258 | 0.0267 | 0.0280 | 0.0390 | 0.0415 | |
| N@10 | 0.0267 | 0.0325 | 0.0320 | 0.0337 | 0.0352 | 0.0461 | 0.0504 | |
| Sports | R@5 | 0.0188 | 0.0190 | 0.0199 | 0.0219 | 0.0263 | 0.0281 | 0.0324 |
| R@10 | 0.0316 | 0.0312 | 0.0306 | 0.0342 | 0.0348 | 0.0401 | 0.0476 | |
| N@5 | 0.0114 | 0.0122 | 0.0107 | 0.0137 | 0.0168 | 0.0188 | 0.0214 | |
| N@10 | 0.0155 | 0.0157 | 0.0146 | 0.0179 | 0.0221 | 0.0228 | 0.0257 | |
| Toys | R@5 | 0.0327 | 0.0330 | 0.0447 | 0.0338 | 0.0365 | 0.0553 | 0.0594 |
| R@10 | 0.0522 | 0.0491 | 0.0621 | 0.0546 | 0.0561 | 0.0774 | 0.0828 | |
| N@5 | 0.0193 | 0.0223 | 0.0300 | 0.0210 | 0.0244 | 0.0389 | 0.0425 | |
| N@10 | 0.0255 | 0.0279 | 0.0357 | 0.0277 | 0.0308 | 0.0461 | 0.0505 |
分析:
- TwiSTAR 在 12 个 metric-dataset 组合上全部取得最优,OneRec-Think 全部第二。说明把 reasoning 引入生成式推荐确实带来质变,且进一步把推理调度交给 learned planner比一刀切 reasoning 还能再涨 5-15%(NDCG@10:Beauty 0.0461 → 0.0504,相对 +9.3%;Sports +12.7%;Toys +9.5%)。
- HSTU 是非 LLM-based 但有 generative 框架的强 baseline,落后于 OneRec-Think 与 TwiSTAR,但显著强于纯判别 SASRec/GRU4Rec/HGN,再次确认 LLM-based generative 范式的优势。
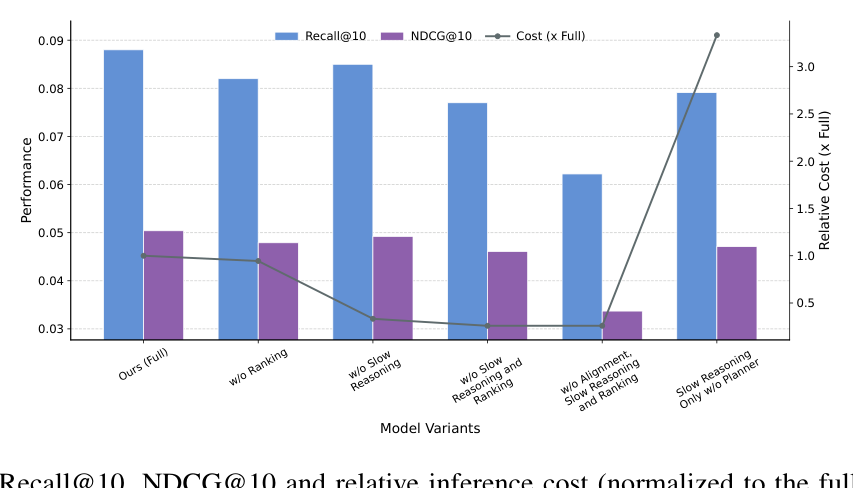
6.2 RQ2:Ablation Study(Beauty 数据集)¶
五种变体:
- w/o Ranking:去掉 ranker 工具;
- w/o Slow Reasoning:去掉 slow 模型;
- w/o Slow Reasoning and Ranking:仅留 fast;
- w/o Alignment, Slow Reasoning and Ranking:连 SID-text alignment 也去掉,使用随机 SID 初始化;
- Slow Reasoning Only w/o Planner:所有 sequence 都强制走 slow 路径,无 planner。
细化结论(论文原文报告):
- 移除 ranker:R@10 0.0880 → 0.0820(−6.8%),N@10 0.0504 → 0.0479(−5%),cost 0.94×。说明 ranker 在 fast 检索结果之上能稳健地补一截精度,且本身开销很小。
- 移除 slow reasoning:精度下降更小,但 cost 也明显下降。说明 slow 模型本身昂贵但在它被调用的子集上确实带来增益,而非所有样本都受益。
- 同时移除 slow 与 ranking:进一步退化,证明三件工具各自不可替代。
- 去掉 alignment 后(变体 4):fast retrieval 大幅恶化,且 reasoning 能力无法被激活——SID-text alignment 是整个框架的基石,因为没有它,slow 模型说不出协同语言。
- uniform slow reasoning (variant 5) 反而比 full model 精度更低、cost 更高。这是一个 counter-intuitive 但很强的实证:因为 $\mathcal{M}_\text{slow}$ 故意只在 hard 样本上训练,把它用于 easy 样本会引入冗长生成噪声而干扰直接协同匹配;同时为所有样本付出 CoT 延迟显然不合算。
这条结论非常关键:slow reasoning 的价值不是 "更强一定更好",而是 "用对地方",因此 learned planner 是把 slow reasoning 的原始能力转化为高效高质量系统的必要组件。
6.3 RQ3:Does Explicit I2I Explanation Work?¶
设计了一个判别式探针任务直接测试模型有没有内化 I2I 语义:
- 从 Beauty 数据集抽 25,438 个共购 pair $(i, j)$,其中 26.25% 一级 SID 编码相同,仅 3.65% 一二级编码都相同——即绝大多数协同关联跨越 SID 层级,无法靠简单 SID 模式匹配。
- 对每个 pair,从 catalog 随机采 9 个 distractor 形成 10-candidate 选项;模型给定 $i$(SID + 元数据),选出与 $i$ 最相关的候选。
- 比较 $\mathcal{M}_\text{align}$ vs $\mathcal{M}_\text{slow}$。
结果:$\mathcal{M}_\text{align}$ 准确率 49%,$\mathcal{M}_\text{slow}$ 跳到 84%。alignment 不足以捕获细粒度协同关系,I2I explanation tuning 才真正注入协同 commonsense。这验证了 4.3 节关于"显式语言化共现"的核心论点。
6.4 RQ4:Why Does Thinking Need Hard Samples?¶
挑战默认假设"think 模型用更多数据训会更强"。把样本按用户历史中出现的不同 second-level 品类数划分:
- easy samples:< 2 个二级品类(约 30%);
- hard samples:≥ 3 个二级品类。
Table 2: Think model trained on full data vs selective samples (Beauty dataset).
| Model | Hard samples (R@10) | Easy samples (R@10) |
|---|---|---|
| Non-think (fast) | 0.0706 | 0.0760 |
| Think (trained on full data) | 0.0692 | 0.0782 |
| Think (trained on hard samples) | 0.0723 | 0.0735 |
关键观察:
- 把 think 模型在所有训练数据上训:在 hard 样本上 R@10 0.0692 < fast 模型的 0.0706——think 模型实际更弱!但在 easy 样本上反超。
- 把 think 模型只在 hard 样本上训:在 hard 样本上 0.0723 > 0.0706,只有这样才能解锁真正的推理能力;代价是 easy 样本上略低。
论文给出的解释(同时也是 RQ2 第 5 个 ablation 的呼应):mix easy 与 hard 训 think 模型,监督被 easy 的浅协同模式稀释,模型学不到 hard 样本所需的多步推理;只在 hard 样本上聚焦,强制模型从"直接匹配失败"的样本中提取深层因果。附录 D 给出一个具体 case study:一位用户购买了多种指甲彩绘印章相关用品(Konad 印章漆、印章+刮刀、25 块图案板),fast 模型只能基于"美甲—彩绘漆"的浅词相关推荐进一步彩绘漆(China Glaze 全息漆),但 hard-sample-trained slow 模型则推理出用户已经进入"印章艺术"子任务、瓶颈是图案板而非颜色,正确推荐 40-pack 印章图案板套装。
6.5 RQ5:Planner Decision Analysis¶
在 Beauty test set 上,planner $\mathcal{M}_\text{agent}$ 的工具选择分布:
fast_rec:62.3%fast_rec + rank:27.1%think_and_rec:10.6%
与 oracle(事后取最高 NDCG@10、相同则选最低延迟者)对比:78.3% 一致。最常见的 mismatch 是 planner 选 fast_rec 而 oracle 偏好 fast_rec+rank(13.4%)——即 planner 低估了 ranker 的价值;planner 极少错误地用 slow 替代 fast(1.7%)。
- 在 planner 选 slow 的 10.6% 样本里,86.2% 的样本 ground-truth 不在 fast 模型 top-50 中——planner 成功识别真正的 hard cases。
- 对比一个启发式 baseline("用户历史中出现的不同品类数超过阈值 → 触发 slow"),learned planner NDCG@10 0.0504 > 启发式 0.0489。
结论:planner 学到的策略比手工规则更精细地对齐查询难度。
6.6 Latency Analysis(Appendix E.2)¶
单 A100 GPU、batch=1、Beauty test:
- fast model baseline:0.39 s/sample;2.56 samples/s 吞吐;
- 调用 slow 时单样本 2.15 s,slow reasoning 净开销 1.76 s/sample,其中 1.60 s 是 CoT 文本生成、0.16 s 是后续 SID 解码(约 10:1 占比);
- planner 实际在测试集 14.8% 样本上调用 slow,平均延迟约 0.65 s/sample,全测试集 ~39 min;
- 对比 uniform slow reasoning:128.7 min(3.3× adaptive 时间);
- 对比 uniform fast reasoning:23.4 min(adaptive 时间的 60%——adaptive 多花的 17 min 来自 slow 调用与 planner 自身决策开销,但换来 12-15% NDCG 提升)。
7. 与已归档相关工作的对比¶
OneRec-Think OneRec-Think (Kuaishou, 2025-10-13)¶
关系:显式引用且原文 Table 1 / Ablation 已充分对比 · 未加载对方精读
OneRec-Think 是 TwiSTAR 文中明确的 most relevant competitor(C.3 节):把显式 CoT 推理引入 itemic-tokenized 生成式推荐,三阶段——itemic alignment(多任务预训练)→ reasoning activation(SFT)→ reasoning enhancement,外加面向工业部署的 "Think-Ahead" 架构(把推理链前两个 itemic token 预先离线生成并缓存)。两者共享的设计:(1) SID/itemic token 与文本语义对齐;(2) 显式 CoT 推理;(3) 三段式 pipeline。TwiSTAR 的核心 differentiator:OneRec-Think 把 reasoning 视作 uniform feature,对所有 user history 都跑一遍 reasoning chain;TwiSTAR 把 reasoning 视作 tool,由 learned planner 仅在必要时调用。原文 Table 1 显示在三个 Amazon dataset 上 TwiSTAR 相对 OneRec-Think 在 NDCG@10 上 +9-13% 同时延迟可控;机制差异见 §6.2 ablation variant 5(uniform slow reasoning 性能更差)。详细精读见 OneRec-Think。
LASAR LASAR (Beihang + Baidu, 2026-05-11)¶
关系:独立并发(仅相差 1 天且互不引用,两者殊途同归)· 已加载对方精读
问题双同构:两篇论文都直接攻击"uniform reasoning depth/strategy 不够好"——同一时期、同一数据集(Amazon Beauty/Sports/Toys/Instruments)、同一基础范式(SID 自回归生成式推荐 + LLM),都识别到"用户历史复杂度差异大,应该按样本自适应分配推理"作为 root cause。
技术骨架相近:
- LASAR:在 prompt 与 answer 之间插入
<s> <t>×N <e>latent token,用 Coconut-style recurrent hidden-state feedback loop 做 latent reasoning;用 Policy Head + REINFORCE 让模型按样本预测推理步数 $N$;SFT 阶段两阶段解耦(SID alignment → latent loop),RL 阶段用 GRPO 调优答案质量 + 用 step penalty 学会少调用。 - TwiSTAR:保留 explicit CoT 文本(
<think>...</think>),但把 reasoning 抽象为一个 tool;用 GRPO agent planner 在 fast/rank/slow 三件工具中按样本选择,奖励函数显式包含-β·latency cost。
两者本质都是 adaptive allocation of reasoning effort——LASAR 在深度维度自适应(每样本几个 latent step),TwiSTAR 在广度维度自适应(每样本选哪种 reasoning strategy)。
本文(TwiSTAR)的差异与推进:
- 显式 CoT 保留了可解释性(文本可读),LASAR 走 Coconut 路线后人无法读懂 latent state——但 LASAR 延迟更低(latent loop 只是 hidden state 重传,比 token-by-token CoT 快 ~20×);
- TwiSTAR 在 reasoning 类型而非深度上自适应(fast vs rank vs slow CoT),系统更模块化但 planner 错误的代价也更大;
- TwiSTAR 显式注入 I2I collaborative commonsense(4.3 节),LASAR 未做此步。
可比的方法 / 实验差异:两者都在 Amazon Beauty/Sports 用 leave-one-out 评估,但 TwiSTAR 基础模型 Qwen3.5-4B(参数量明显大于 LASAR 默认 LLaMA-3.2-3B),单数值对比意义不大。论文应当互引但目前都没有——这是典型的"半月内独立并发"现象。后续工作有机会做深度 × 广度联合自适应:latent reasoning 步数 + 工具选择由同一 planner 决定。
AgenticRec AgenticRec (Xiamen University, 2026-03-23)¶
关系:未引用,但技术骨架高度同构(agentic + tool calls + RL)· 已加载对方精读
问题相近但不完全同构:AgenticRec 关注的是"reasoning 与 ranking reward 的端到端断裂"以及"list-wise 隐式反馈的细粒度学习",而 TwiSTAR 关注"reasoning effort 的自适应分配"。两者都把推荐重构为 agentic 决策过程,但 AgenticRec 的工具是为推理信息收集服务(4 类 query 工具:用户画像、物品信息、行为统计、协同信息),TwiSTAR 的工具是计算路径(fast/rank/slow——每个工具自身完成最终预测)。
相近的技术骨架:
- 都用 ReAct/tool-call 形式做 agent 行为生成;
- 都用 GRPO 优化整条推理 + 工具调用 + 输出轨迹;
- 都通过 list-wise reward(NDCG@K)+ format constraint + tool-use reward 来强约束 agent。
本文(TwiSTAR)的差异:
- AgenticRec 是 ranker(候选集预先给定 $C$),TwiSTAR 是 retriever + ranker(end-to-end,从全 catalog 开始);
- AgenticRec 不区分 "easy/hard",所有 query 都走同一 ReAct 循环;TwiSTAR 的 planner 显式在 fast/slow 之间分流;
- AgenticRec 后续做 Progressive Preference Refinement(双向 hard negative GRPO),TwiSTAR 没有偏好对挖掘。
可比性差异:AgenticRec 评估了 Amazon Books/Movies/CDs,TwiSTAR 评估 Beauty/Sports/Toys,无直接数值对比;但两者代表了 agentic generative recommendation 思潮在不同应用场景中的两种典型实现路径(信息收集型 vs 计算路径选择型)。
8. 讨论与局限性¶
核心贡献:
- 首次在生成式推荐里学习何时调用推理,把 reasoning 从"全开/全关"二元开关变成 learned routing policy;
- 提出 I2I-explanation language injection 训练 slow reasoning 模型,绕开"为什么用户点击 next item"的幻觉陷阱;
- hard-sample-only 训练 slow 模型这一负面学习经验——slow 应该专精于 fast 解不了的样本,否则会被 easy 样本稀释;
- two-stage agent training(supervised warm-up 含 20% path flip 探索 + agentic RL 含 latency cost)的训练范式可复用于其它 fast/slow 双轨系统。
值得借鉴的设计选择:
- Hierarchical hit reward:用层级前缀匹配(1/2/5 分)解决生成式推荐 RL 里 0/1 奖励稀疏的问题;
- 20% path flip during warm-up:防止 supervised warm-up 退化为"什么都用 fast"的多数路径退化解;
- freeze fast/slow/rank, only train planner:把 planner 训练问题与 base recommender 分开,工程上更稳定。
局限性(论文自陈 + 笔者补充):
- slow 路径仍贵:调用一次约 1.76 s 额外延迟,论文未实现 early termination of reasoning chains;
- planner 决策离线:训练完后 routing 策略固定,未支持 bandit feedback 在线持续 adaptation;
- 未在工业 A/B 验证:所有结果均在 Amazon 三个公开 benchmark 上得到——TwiSTAR 的最大潜在价值(fast 服务延迟约束下的 reasoning 注入)需要在线实测;
- planner-oracle gap 仍 21.7%:78.3% 一致率说明 routing 策略还有显著上限空间;
- 三件工具的设计是手工的:未来 tool set 扩展(如 retrieval + multi-hop reasoning + memory)需要重训 planner。
与已有工作的差异(综合上文 7.1-7.3):
- 相比 OneRec-Think(uniform reasoning),TwiSTAR 把 reasoning 工程化为 adaptive resource,得到精度提升的同时控制延迟;
- 相比 LASAR(latent depth adaptation),TwiSTAR 走的是 explicit breadth adaptation 路径,保留 explainability;
- 相比 AgenticRec(agentic ranker),TwiSTAR 让 agent 在 retrieval / ranking / reasoning 三层都参与决策,agent 真正做"系统层"调度。
工业部署意义:尽管论文实验在公开数据集,但其核心思路——"绝大多数请求走廉价 fast,少数复杂请求走昂贵 slow"——正是工业级生成式推荐部署 LLM-based reasoning 的关键瓶颈解。文章总延迟数据(adaptive 0.65 s vs uniform slow 2.15 s)显示有 ~3.3× wall-clock 节省,且精度反而更高。对于像 Kuaishou/Meituan/Taobao 这种 SLA < 200 ms 的场景,未来若能把 fast/rank/slow 三件做成微服务、planner 做轻量边车,TwiSTAR 范式有较强落地可能。